AIGC 大模型最火熱的任務之一——基于 Diffusion Model 的圖像編輯(editing)領域的首篇綜述。長達 26 頁,涵蓋 297 篇文獻!本文全面研究圖像編輯前沿方法,并根據技術路線精煉地劃分為 3 個大類、14 個子類,通過表格列明每個方法的類型、條件、可執行任務等信息。此外,本文提出了一個全新 benchmark 以及 LMM Score 指標來對代表性方法進行實驗評估,為研究者提供了便捷的學習參考工具。強烈推薦 AIGC 大模型研究者或愛好者閱讀,緊跟熱點。
-
作者:Yi Huang, Jiancheng Huang, Yifan Liu, Mingfu Yan, Jiaxi Lv, Jianzhuang Liu, Wei Xiong, He Zhang, Liangliang Cao, Shifeng Chen
-
單位: 中科院、Adobe公司、蘋果公司(曹亮亮等)、南科大
-
鏈接:https://arxiv.org/abs/2402.17525
-
https://github.com/SiatMMLab/Awesome-Diffusion-Model-Based-Image-Editing-Methods
摘要
去噪擴散模型已成為各種圖像生成和編輯任務的有力工具,有助于以無條件或輸入條件的方式合成視覺內容。這些模型背后的核心理念是學習如何逆轉逐漸向圖像中添加噪聲的過程,從而從復雜的分布中生成高質量的樣本。
在這份調查報告中,我們詳盡概述了使用擴散模型進行圖像編輯的現有方法,涵蓋了該領域的理論和實踐方面。我們從學習策略、用戶輸入條件和可完成的一系列具體編輯任務等多個角度對這些作品進行了深入分析和分類。此外,我們還特別關注圖像的inpainting和outpainting,并探討了早期的傳統上下文驅動方法和當前的多模態條件方法,對其方法論進行了全面分析。
為了進一步評估文本引導圖像編輯算法的性能,我們提出了一個系統基準 EditEval,其特點是采用了創新指標 LMM Score。最后,我們討論了當前的局限性,并展望了未來研究的一些潛在方向。
附帶的資源庫發布在:https://github.com/SiatMMLab/Awesome-Diffusion-Model-Based-Image-Editing-Methods。
統計圖

基于擴散模型的圖像編輯中研究出版物的統計概述。上圖:學習策略。中:輸入條件。下圖:編輯任務。

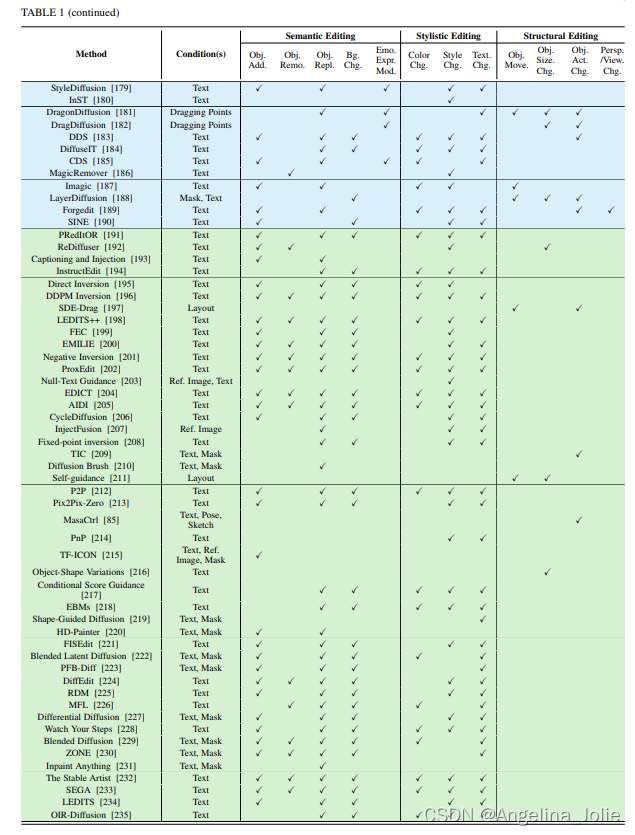
從多角度對基于擴散模型的圖像編輯方法進行了全面地分類。這些方法是根據訓練、微調和免訓練進行顏色渲染的。輸入條件包括文本、類別、參考圖像,分割圖、姿態、蒙版、布局、草圖、拖動點和音頻。打勾表示可以做的任務。
訓練大類的分類屬性圖以及框架圖

?
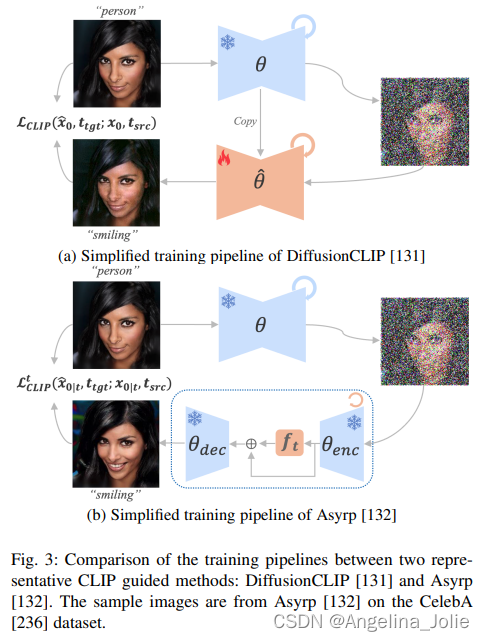
?比較兩種有代表性的CLIP導引方法:DiffusionCLIP 和 Asyrp 的框架圖。樣本圖像來自CelebA數據集上的Asyrp

?指令圖像編輯方法的通用框架。示例圖像來自InstructPix2Pix、InstructAny2Pix和MagicBrush。
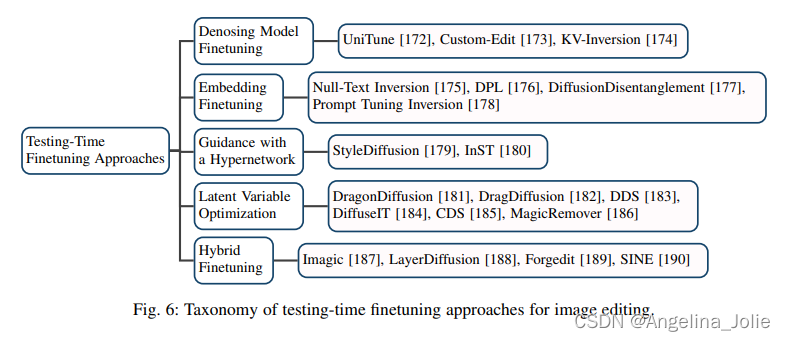
微調大類的分類屬性圖以及框架圖
?
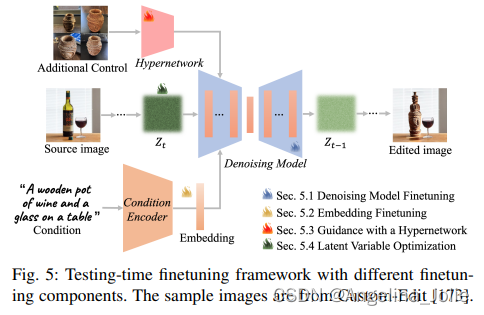
?使用不同微調組件的微調框架。樣本圖像來自Custom-Edit。
免訓練大類的分類屬性圖以及框架圖
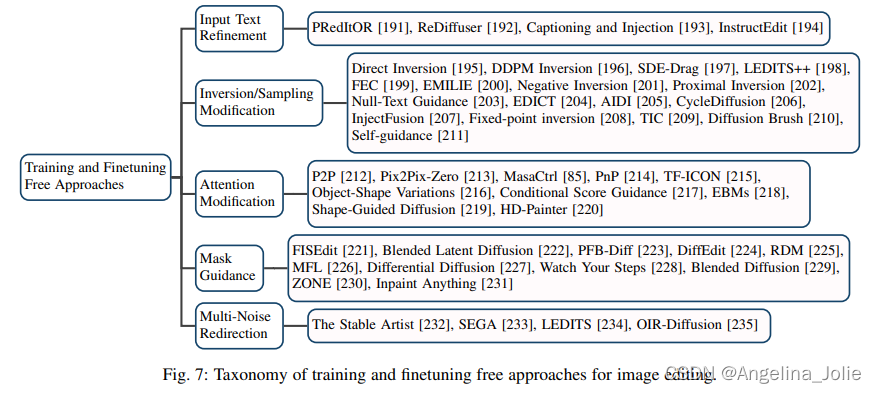
?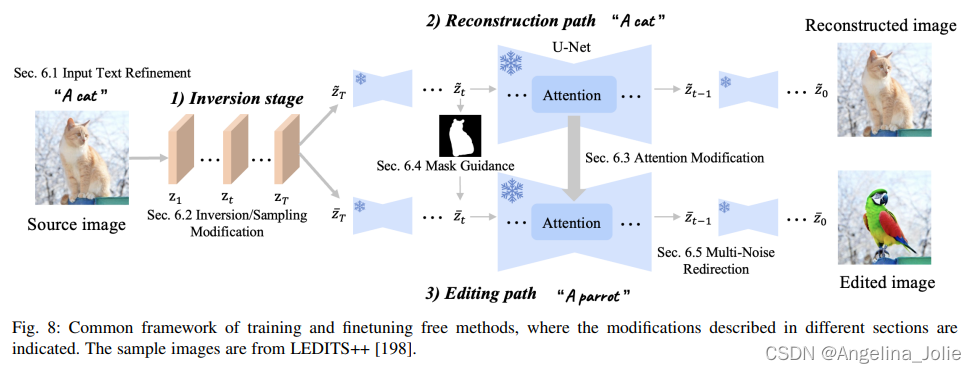
免訓練方法的通用框架,其中指出了不同部分中描述的修改。樣本圖片來自LEDITS++。
Benchmark

?LMM Score與用戶研究的皮爾遜相關系數。

?LMM Score/CLIPScore與用戶研究的皮爾遜相關系數比較。
 對7種選定的編輯類型進行直觀比較。
對7種選定的編輯類型進行直觀比較。

)















)

