1. hbase連接
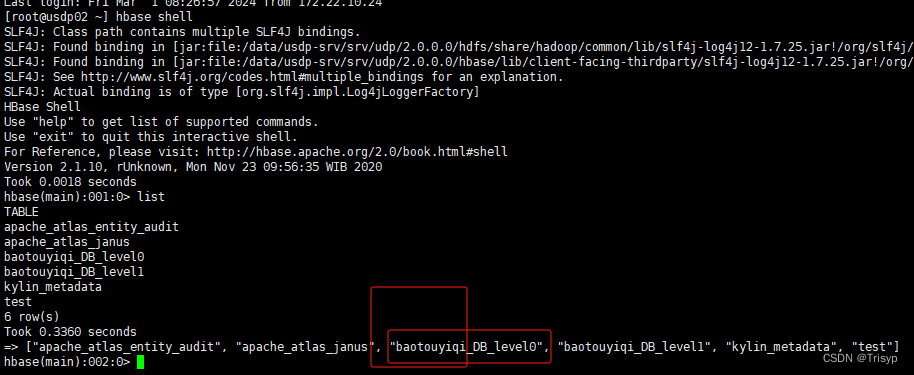
首先用hbase shell 命令來進入到hbase數據庫,然后用list命令來查看hbase下所有表,以其中表“DB_level0”為例,可以看到庫名“baotouyiqi”是拼接的,python代碼訪問時先連接:
def hbase_connection(hbase_master, hbase_port, table_prefix=None):connection = happybase.Connection(host=hbase_master, port=hbase_port, table_prefix=table_prefix)return connection
connection = hbase_connection(hbase_master, hbase_port, table_prefix) # 在連接的時候創建項目空間
table = connection.table(tablename) # 獲取表連接備注:完整代碼在最后,想運行的直接滑倒最后復制即可
2. 按條件讀取hbase數據
然后按照條件來查詢表中想要的數據集,這里只列舉兩個條件:時間區間和指定列。同樣,我們在shell下用scan命令來查看表中的數據結構:
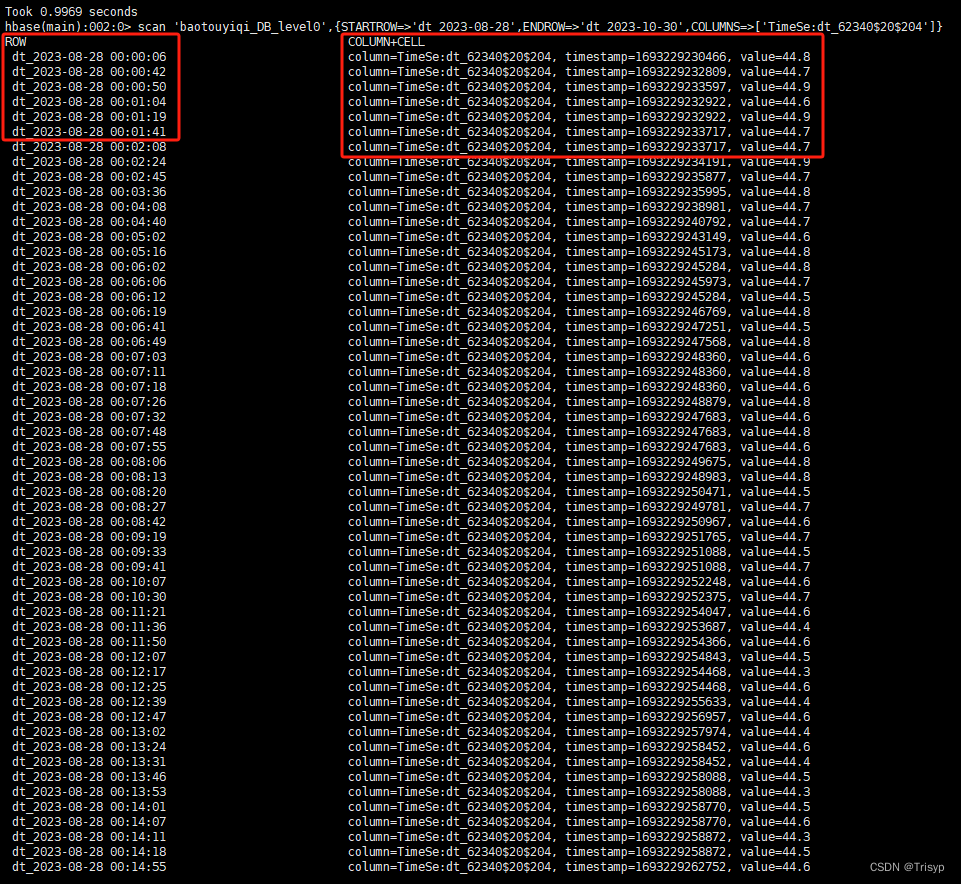
可以看到第一列是ROW,第二列是COLUMN+CELL,python代碼取數據方法差不多:
date_prex_start = bytes('dt_' + starttime, encoding='utf-8') # row_start
date_prex_end = bytes('dt_' + endtime, encoding='utf-8') # row_stop
# 通過設置row key的前綴row_prefix參數來進行局部掃描
outdata = dict(table.scan(row_start=date_prex_start, row_stop=date_prex_end,columns=[onecolumn]))
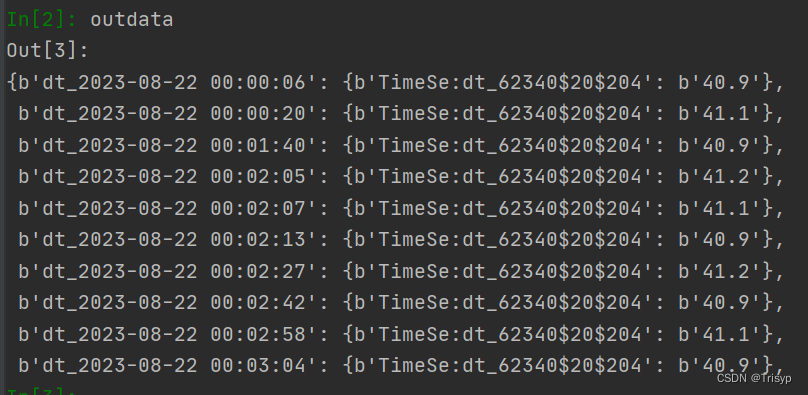
得到的結果如下,是個字典格式:
3. 按格式輸出hbase數據結果
我們希望輸出的結果是dataframe的,而且第一列是time,第二列是value,所以就做個簡單格式處理:
timesep = list(map(lambda x: x.decode('utf-8').replace('dt_', ''), outdata.keys()))
tempdata = list(outdata.values())
valuelist = list(map(lambda x: float(list(x.values())[0]), tempdata))
if len(timesep) > 0:db_data2 = pd.DataFrame({'時間': timesep, onecolumn: valuelist})db_data2.loc[:, '時間2'] = [i[:16] for i in db_data2['時間']]db_data2 = db_data2.drop_duplicates(subset=['時間2'], keep='last') # 一分鐘內多次數值取一個即可
else:db_data2 = pd.DataFrame()
if len(db_data2) < 1:return pd.DataFrame()
db_data2.loc[:, '時間戳'] = [time.mktime(time.strptime(i, "%Y-%m-%d %H:%M:%S")) for i in db_data2['時間']]
db_data2 = db_data2.sort_values(by=['時間戳'], ascending=False) # 將最新的數值放最前面
db_data3 = db_data2.drop(columns=['時間2', '時間戳'])
db_data3.columns = ['time', 'value']
4. 完整代碼(code)
import happybase
import time
import pandas as pd
from pathlib import Pathos_file_name = Path(__file__).namedef hbase_connection(hbase_master, hbase_port, table_prefix=None):connection = happybase.Connection(host=hbase_master, port=hbase_port, table_prefix=table_prefix)return connectiondef get_data_by_tum(hbase_master, hbase_port, table_prefix, tablename, columnslist, starttime, endtime):columnsid = '$'.join(columnslist)onecolumn = 'TimeSe:dt_' + columnsid # columnconnection = hbase_connection(hbase_master, hbase_port, table_prefix) # 在連接的時候創建項目空間table = connection.table(tablename) # 獲取表連接date_prex_start = bytes('dt_' + starttime, encoding='utf-8') # row_startdate_prex_end = bytes('dt_' + endtime, encoding='utf-8') # row_stop# 通過設置row key的前綴row_prefix參數來進行局部掃描outdata = dict(table.scan(row_start=date_prex_start, row_stop=date_prex_end,columns=[onecolumn]))timesep = list(map(lambda x: x.decode('utf-8').replace('dt_', ''), outdata.keys()))tempdata = list(outdata.values())valuelist = list(map(lambda x: float(list(x.values())[0]), tempdata))if len(timesep) > 0:db_data2 = pd.DataFrame({'時間': timesep, onecolumn: valuelist})db_data2.loc[:, '時間2'] = [i[:16] for i in db_data2['時間']]db_data2 = db_data2.drop_duplicates(subset=['時間2'], keep='last') # 一分鐘內多次數值取一個即可else:db_data2 = pd.DataFrame()if len(db_data2) < 1:return pd.DataFrame()db_data2.loc[:, '時間戳'] = [time.mktime(time.strptime(i, "%Y-%m-%d %H:%M:%S")) for i in db_data2['時間']]db_data2 = db_data2.sort_values(by=['時間戳'], ascending=False) # 將最新的數值放最前面db_data3 = db_data2.drop(columns=['時間2', '時間戳'])db_data3.columns = ['time', 'value']return db_data3if __name__ == '__main__':begin_time = '2023-08-22 00:00:00'end_time = '2023-08-23 00:00:00'hbase_master = "142.21.8.22"hbase_port = 9097table_prefix = "baotouyiqi"table_name = "DB_level0"onedata = ["62340", "20", "204"]dataget = get_data_by_tum(hbase_master, hbase_port, table_prefix, table_name,onedata, begin_time, end_time)print(dataget)






![[⑥5G NR]: 無線接口協議,信道映射學習](http://pic.xiahunao.cn/[⑥5G NR]: 無線接口協議,信道映射學習)






 E. XOR Tree(啟發式合并+貪心))




)
