(本內容部分來自知乎網等網絡)
Redis 緩存的使用,極大的提升了應用程序的性能和效率,特別是數據查詢方面。但同時,它也帶來了一些問題。其中,最要害的問題,就是數據的一致性問題,從嚴格意義上講,這個問題無解。如果對數據 的一致性要求很高,那么就不能使用緩存。
另外的一些典型問題就是,緩存穿透、緩存雪崩和緩存擊穿。目前,業界也都有比較流行的解決方案。
1. 緩存穿透(數據不存在)
緩存穿透是指查詢請求中的數據在緩存系統和后端數據庫中都不存在的情況。
正常情況下,如果數據不在緩存中,會去數據庫查詢并把結果放入緩存以備后續使用。但如果惡意或者大量請求都是針對不存在的數據,那么這些請求將會繞過緩存直接打到數據庫,導致數據庫承受不必要的壓力。
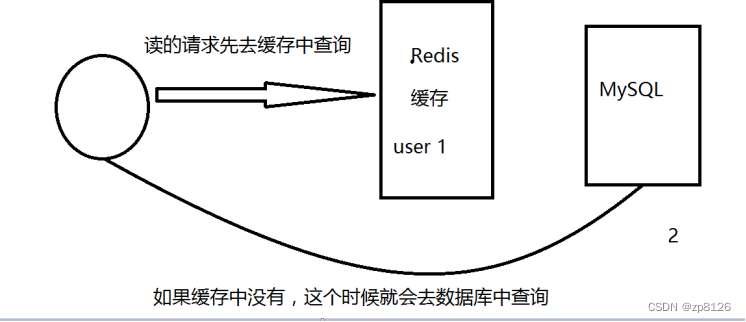
解決方案
- 布隆過濾器(Bloom Filter):可以在查詢緩存之前先通過布隆過濾器判斷該 key 是否可能存在,如果布隆過濾器認為不存在,則直接返回空,避免對數據庫進行查詢。
- 空值緩存:即使從數據庫查不到數據,也把一個特殊值(比如
NULL或FLAG)作為結果緩存起來,設置較短的過期時間,這樣短期內連續針對同樣不存在的數據的請求也能被緩存攔截。
布隆過濾器
布隆過濾器: 是一種數據結構,對所有可能查詢的參數以hash形式存儲,在控制層先進行校驗,不符合則 丟棄,從而避免了對底層存儲系統的查詢壓力;
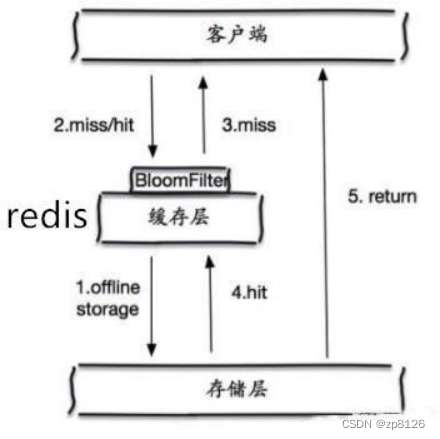
什么是布隆過濾器
本質上布隆過濾器是一種數據結構,比較巧妙的概率型數據結構(probabilistic data structure),特點是高效地插入和查詢,可以用來告訴你?“某樣東西一定不存在或者可能存在”。
相比于傳統的 List、Set、Map 等數據結構,它更高效、占用空間更少,但是缺點是其返回的結果是概率性的,而不是確切的。
什么是布隆過濾器
本質上布隆過濾器是一種數據結構,比較巧妙的概率型數據結構(probabilistic data structure),特點是高效地插入和查詢,可以用來告訴你?“某樣東西一定不存在或者可能存在”。
相比于傳統的 List、Set、Map 等數據結構,它更高效、占用空間更少,但是缺點是其返回的結果是概率性的,而不是確切的。
實現原理
HashMap 的問題
講述布隆過濾器的原理之前,我們先思考一下,通常你判斷某個元素是否存在用的是什么?應該蠻多人回答 HashMap 吧,確實可以將值映射到 HashMap 的 Key,然后可以在 O(1) 的時間復雜度內返回結果,效率奇高。但是 HashMap 的實現也有缺點,例如存儲容量占比高,考慮到負載因子的存在,通常空間是不能被用滿的,而一旦你的值很多例如上億的時候,那 HashMap 占據的內存大小就變得很可觀了。
還比如說你的數據集存儲在遠程服務器上,本地服務接受輸入,而數據集非常大不可能一次性讀進內存構建 HashMap 的時候,也會存在問題。
布隆過濾器數據結構
布隆過濾器是一個 bit 向量或者說 bit 數組,長這樣:
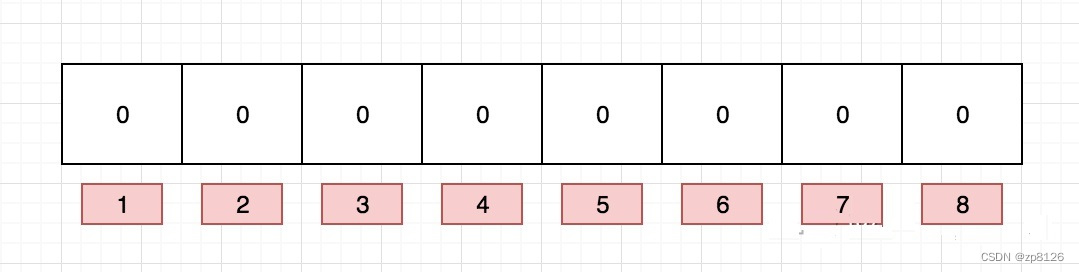
如果我們要映射一個值到布隆過濾器中,我們需要使用多個不同的哈希函數生成多個哈希值,并對每個生成的哈希值指向的 bit 位置 1,例如針對值 “baidu” 和三個不同的哈希函數分別生成了哈希值 1、4、7,則上圖轉變為:
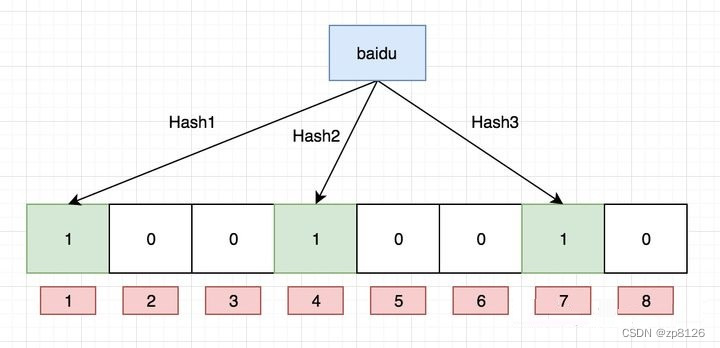
Ok,我們現在再存一個值 “tencent”,如果哈希函數返回 3、4、8 的話,圖繼續變為:
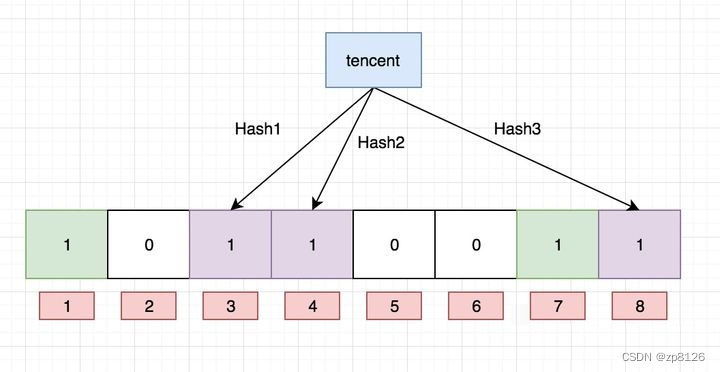
值得注意的是,4 這個 bit 位由于兩個值的哈希函數都返回了這個 bit 位,因此它被覆蓋了。現在我們如果想查詢 “dianping” 這個值是否存在,哈希函數返回了 1、5、8三個值,結果我們發現 5 這個 bit 位上的值為 0,說明沒有任何一個值映射到這個 bit 位上,因此我們可以很確定地說 “dianping” 這個值不存在。而當我們需要查詢 “baidu” 這個值是否存在的話,那么哈希函數必然會返回 1、4、7,然后我們檢查發現這三個 bit 位上的值均為 1,那么我們可以說 “baidu”?存在了么?答案是不可以,只能是 “baidu” 這個值可能存在。
這是為什么呢?答案跟簡單,因為隨著增加的值越來越多,被置為 1 的 bit 位也會越來越多,這樣某個值 “taobao” 即使沒有被存儲過,但是萬一哈希函數返回的三個 bit 位都被其他值置位了 1 ,那么程序還是會判斷 “taobao” 這個值存在。
如何選擇哈希函數個數和布隆過濾器長度
很顯然,過小的布隆過濾器很快所有的 bit 位均為 1,那么查詢任何值都會返回“可能存在”,起不到過濾的目的了。布隆過濾器的長度會直接影響誤報率,布隆過濾器越長其誤報率越小。
另外,哈希函數的個數也需要權衡,個數越多則布隆過濾器 bit 位置位 1 的速度越快,且布隆過濾器的效率越低;但是如果太少的話,那我們的誤報率會變高。
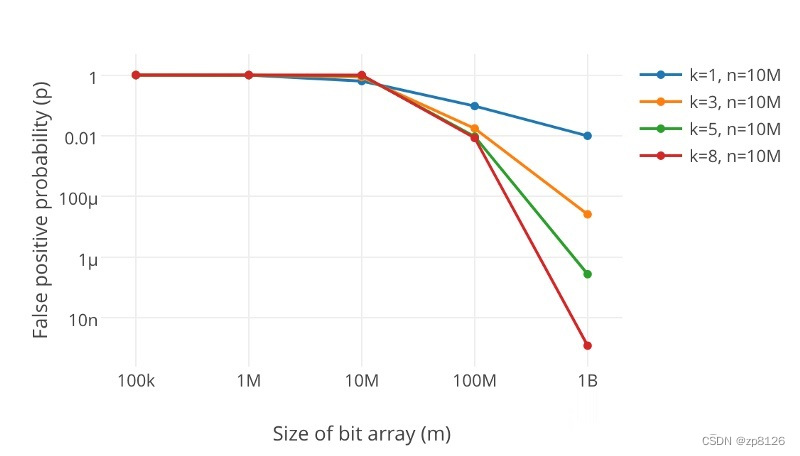
k 為哈希函數個數,m 為布隆過濾器長度,n 為插入的元素個數,p 為誤報率
緩存空對象
當存儲層不命中后,即使返回的空對象也將其緩存起來,同時會設置一個過期時間,之后再訪問這個數 據將會從緩存中獲取,保護了后端數據源;
但是這種方法會存在兩個問題:
1、如果空值能夠被緩存起來,這就意味著緩存需要更多的空間存儲更多的鍵,因為這當中可能會有很多的空值的鍵;
2、即使對空值設置了過期時間,還是會存在緩存層和存儲層的數據會有一段時間窗口的不一致,這對于需要保持一致性的業務會有影響。
2. 緩存擊穿(緩存過期)
定義: 緩存擊穿通常指的是某個熱點數據過期失效后,短時間內有大量的并發請求同時來訪問這個剛剛過期的數據,從而所有請求都會穿透緩存直接到達數據庫,造成數據庫瞬間壓力過大。
解決方法:
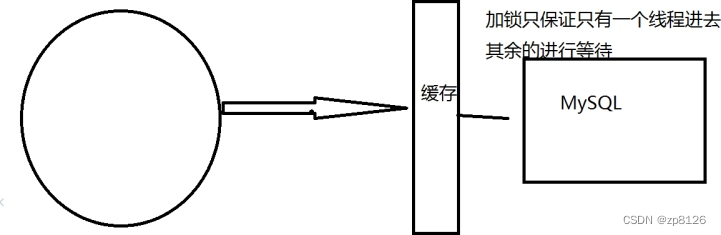
- 互斥鎖(Mutex Lock):對于熱點數據,在緩存失效時采用加鎖策略,使得只有一個線程能持有鎖去數據庫加載數據,其他線程等待鎖釋放后獲取更新后的緩存數據。
- 永不過期:在業務允許的情況下,可以考慮讓熱點數據永不超時,而是通過定時任務或后臺異步刷新的方式更新緩存。
這里需要注意和緩存擊穿的區別,緩存擊穿,是指一個key非常熱點,在不停的扛著大并發,大并發集中 對這一個點進行訪問,當這個key在失效的瞬間,持續的大并發就穿破緩存,直接請求數據庫,就像在一個屏障上鑿開了一個洞。
當某個key在過期的瞬間,有大量的請求并發訪問,這類數據一般是熱點數據,由于緩存過期,會同時訪問數據庫來查詢最新數據,并且回寫緩存,會導使數據庫瞬間壓力過大。
設置熱點數據永不過期
從緩存層面來看,沒有設置過期時間,所以不會出現熱點 key 過期后產生的問題。
加互斥鎖
分布式鎖:使用分布式鎖,保證對于每個key同時只有一個線程去查詢后端服務,其他線程沒有獲得分布式鎖的權限,因此只需要等待即可。這種方式將高并發的壓力轉移到了分布式鎖,因此對分布式鎖的考驗很大。
3. 緩存雪崩
定義: 緩存雪崩是指緩存集群在某一時刻大面積地發生緩存失效,例如由于網絡抖動、緩存服務器宕機、或者大量緩存同時達到預設過期時間等導致。此時,原本由緩存承載的大量請求全部涌入數據庫,可能會壓垮數據庫。
緩存雪崩,是指在某一個時間段,緩存集中過期失效。Redis 宕機!
產生雪崩的原因之一,比如在寫本文的時候,馬上就要到雙十二零點,很快就會迎來一波搶購,這波商品時間比較集中的放入了緩存,假設緩存一個小時。那么到了凌晨一點鐘的時候,這批商品的緩存就都過期了。而對這批商品的訪問查詢,都落到了數據庫上,對于數據庫而言,就會產生周期性的壓力波峰。于是所有的請求都會達到存儲層,存儲層的調用量會暴增,造成存儲層也會掛掉的情況。
解決方法:
- 分散失效時間:為緩存設置隨機的過期時間,防止大量緩存在同一時刻失效。
- 多級緩存:使用主從、集群等方式部署緩存,增強緩存系統的可用性。
- 熔斷降級與限流:當數據庫壓力過大時,可以通過熔斷機制暫時停止向數據庫發送請求,并啟動降級策略;同時也可以使用限流措施控制請求流量,保護數據庫不受沖擊。
- 提前預熱:在緩存失效前提前刷新緩存,尤其對于那些即將過期的熱點數據。
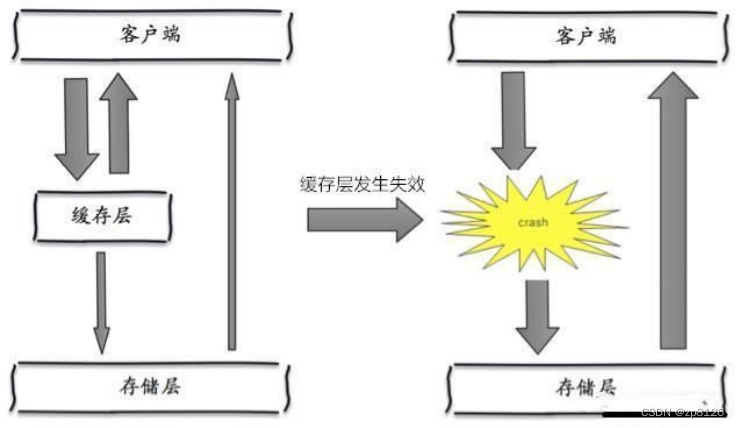
其實集中過期,倒不是非常致命,比較致命的緩存雪崩,是緩存服務器某個節點宕機或斷網。因為自然形成的緩存雪崩,一定是在某個時間段集中創建緩存,這個時候,數據庫也是可以頂住壓力的。無非就是對數據庫產生周期性的壓力而已。而緩存服務節點的宕機,對數據庫服務器造成的壓力是不可預知的,很有可能瞬間就把數據庫壓垮。
綜上所述,要應對這三種情況,需要結合具體的業務場景,合理設計緩存策略,以及利用額外的技術手段來保證系統的穩定性和高可用性。
 E. XOR Tree(啟發式合并+貪心))




)

)


——數組(1))






V2 用戶關注)

