Sora能力邊界探索

- 最大支持60秒高清視頻生成,以及基于已有短視頻的前后擴展,同時保持人物/場景的高度一致性
- 如奶茶般絲滑過渡的視頻融合能力
- 同一場景的多角度/鏡頭的生成能力
- 具有動態攝像機運動的視頻。隨著攝像機的移動和旋轉,人和其
他場景元素在三維空間中一致地移動 - 支持任意分辨率,寬高比的視頻輸出
- Sora對物理規律的理解仍然十分有限
Sora能力總結
- Text-to-video: 文生視頻
- Image-to-video: 圖生視頻
- Video-to-video: 改變源視頻風格or場景
- Extending video in time: 視頻拓展(前后雙向)
- Create seamless loops: Tiled videos that seem like they never end
- Image generation: 圖片生成 (size最高達到 2048 x 2048)
- Generate video in any format: From 1920 x 1080 to 1080 x 1920 視頻輸出比例自定義
- Simulate virtual worlds: 鏈接虛擬世界,游戲視頻場景生成
- Create a video: 長達60s的視頻并保持人物、場景一致性
Sora模型訓練流程
Video generation models as world simulators
https://openai.com/research/video-generation-models-as-world-simulators
模型訓練流程



模型訓練:擴散模型 DDPM





模型訓練:基于擴散模型的主干 U-Net
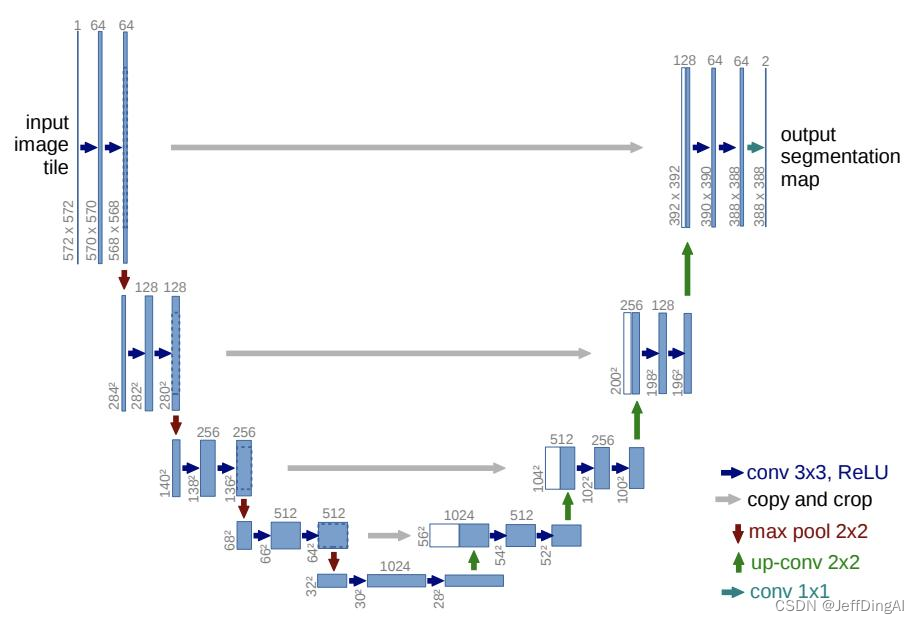
- U-Net 網絡模型結構把模型規模限定;
- SD/SDXL 作為經典網絡只公布了推理和微調;
- 國內主要基于 SD/SDXL 進行二次創作;


Sora關鍵技術拆解
einops是一個用于操作張量的庫,它的出現可以替代我們平時使用的reshape、view、transpose和
permute等操作
einops支持numpy、pytorch、tensorflow等
y = x.transpose(0, 2, 3, 1) 等同
y = rearrange(x, ‘b c h w -> b h w c’)
self.gkv = nn.Linear(self.embed dim, self.head size * self.n heads * 3,bias=False
self.scale=self.head size **-0.5
self.register buffer("tril',torch.tril(torch.ones(self.seg len,self.seg len))
self.attn dropout =nn.Dropout(0.)def forward(self,x):b,t,c=x.shape# q,k,v shape individually: batch size x seg len x embed dim# we know that gk t=gxkt, where g=bxtxhead dim, k t=bxhead timxtq,k,v=self.qkv(x).chunk(3,dim=-1)q=rearrange(q,'bt(h n)->bnt h',n=self.n heads)# h= head sizek=rearrange(v,'b t(h n)->bnth',n=self.n heads)v=rearrange(v,'bt(hn)->bnth',n=self.n heads)qkt=einsum(q,k,'b n tl h, bn t2 h->bn tl t2')* self.scaleweights=qk t.masked fill(m==0,float('-inf'))weights=F.softmax(weights,dim=-1)weights =self.attn dropout(weights)attention =weights @ v# batch xn heads x seg len x head sizeattention=rearrange(attention,'bnth->bt(n h)')return attentionpatches = rearrange(im,'c (h pl)(w p2)->(h w)c pl p2',pl=patch size,p2=patch size)
patches.shape
# torch.Size([196,3,16,16])figure =plt.figure(figsize=(5,5))
for i in range(patches.size(0)):img =patchesli].permute(1,2,0)fiqure.add subplot(14,14,i+1)plt.axis('off')plt.imshow(img)
plt.show()

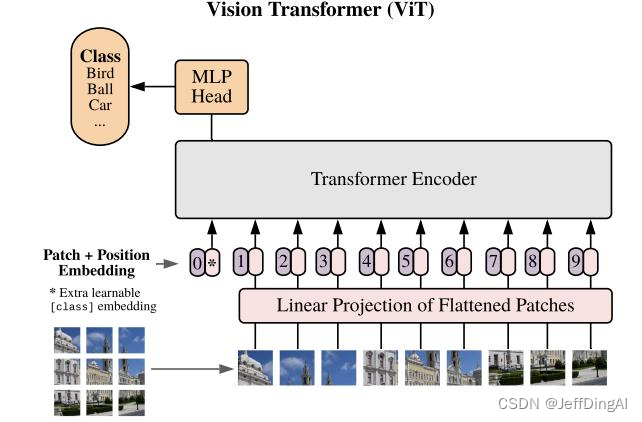
- ViT 嘗試將標準 Transformer 結構直接應用于圖
像; - 圖像被劃分為多個 patch后,將二維 patch 轉換為一維向量作為 Transformer 的輸入;
技術報告分析
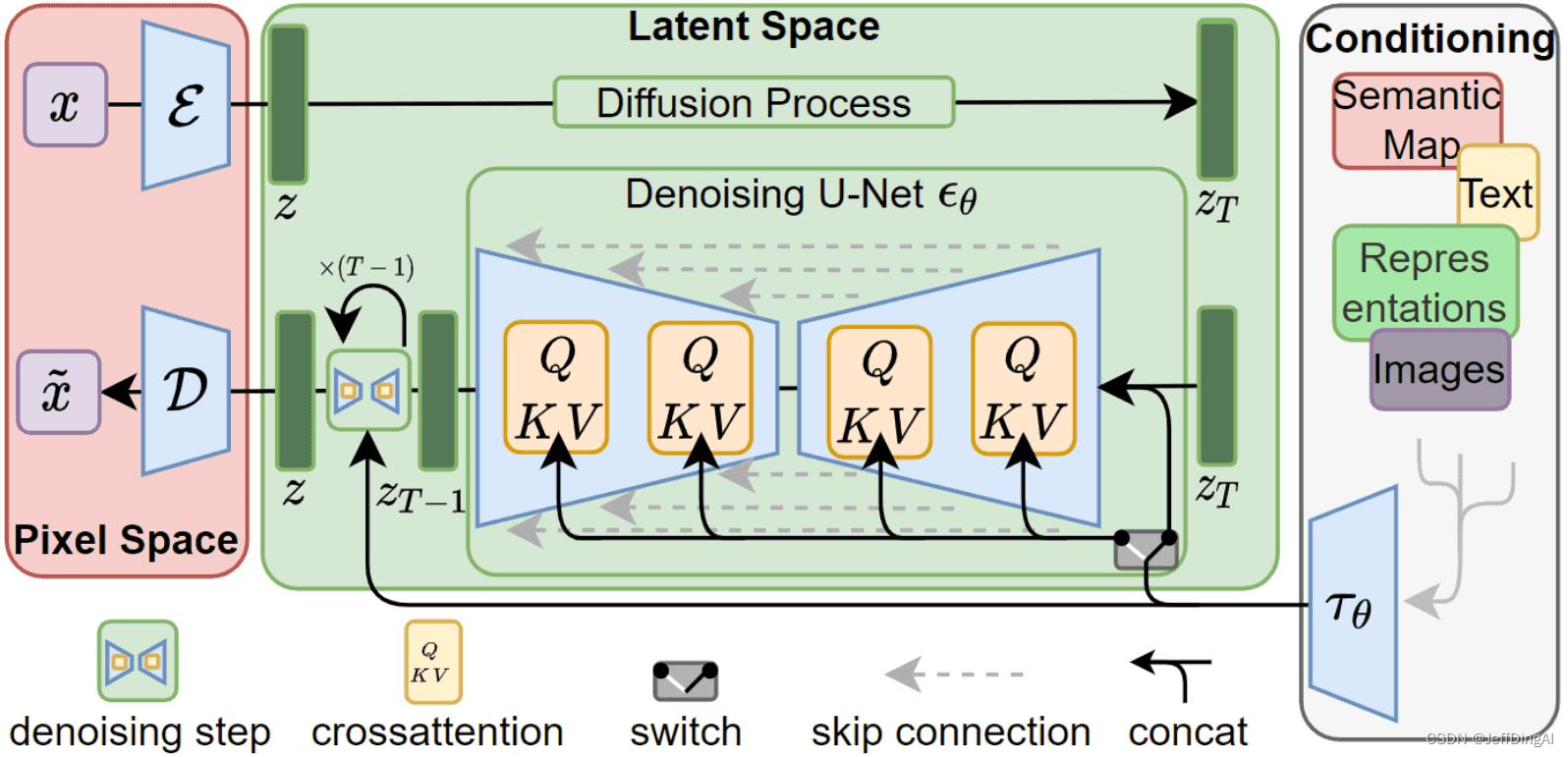
Diffusion Transformer,= VAE encoder + ViT + DDPM + VAE
DiT 利用 transformer 結構探索新的擴散模型,成功用 transformer 替換 U-Net 主干

- 例如輸入一張256x256x3的圖片,經過Encoder后得到對應的latent
- 推理時輸入32x32x4的噪聲,得到32x32x4的latent
- 結合當前的 step t , 輸入label y , 經過N個Dit Block通過 MLP 進行輸出
- 得到輸出的噪聲以及對應的協方差矩陣
- 經過T個step采樣,得到32x32x4的降噪后的latent
- 在訓練時,需要使得去躁后的latent和第一步得到的latent盡可能一致
網絡結構:Diffusion Transformer,DiT

- DiT 首先將將每個 patch 空間表示Latent 輸入到第一層網絡,以此將空間輸入轉換為 tokens 序列。
- 將標準基于 ViT 的 Patch 和Position Embedding 應用于所有輸入token,最后將輸入 token 由Transformer 處理。
- DiT 還會處理額外信息,e.g. 時間步長、類別標簽、文本語義等
網絡結構: DALLE 2
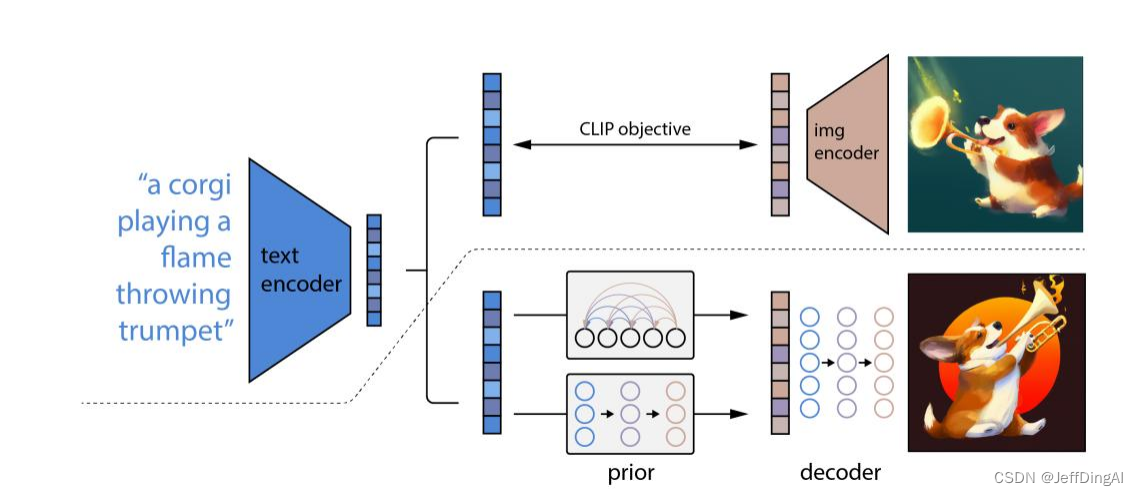
- 將文本提示輸入文本編碼器,該訓練過的編碼器便將文本提示映射到表示空間;
- 先驗模型將文本編碼映射到圖像編碼,圖像編碼捕獲文本編碼中的語義信息;
- 圖像解碼模型隨機生成一幅從視覺上表現該語義信息的圖像;
技術總結
- Scaling Law:模型規模的增大對視頻生成質量的提升具有明確意義,從而很好地解決視
頻一致性、連續性等問題; - Data Engine:數據工程很重要,如何設計視頻的輸入(e.g. 是否截斷、長寬比、像素
優化等)、patches 的輸入方式、文本描述和文本圖像對質量;
AI Infra:AI 系統(AI 框架、AI 編譯器、AI 芯片、大模型)工程化能力是很大的技術
壁壘,決定了 Scaling 的規模。 - LLM:LLM 大語言模型仍然是核心,多模態(文生圖、圖生文)都需要文本語義去牽引和
約束生成的內容,CLIP/BLIP/GLIP 等關聯模型會持續提升能力;
學習資源
DataWhale社區Sora學習資源:
https://datawhaler.feishu.cn/wiki/RKrCw5YY1iNXDHkeYA5cOF4qnkb#KljXdPfWJo62zwxdzYIc7djgnlf
學習視頻:
https://www.bilibili.com/video/BV1wm411f7gf/?spm_id_from=333.1350.jump_directly&vd_source=299ce227a965167d79f374c15b2fddf5





)

)

面經總結!)


)
)
+前后端項目分別部署)




UI)