Non-local 注意力實現非局部神經網絡,解決長空間和時間數據依賴問題
- 提出背景
- 長距離技術對比
- Non-local Block是怎么設計
- Non-local 神經網絡
- 效果
- 小目標漲點
- YOLO v5 魔改
- YOLO v7 魔改
- YOLO v8 魔改
?
提出背景
論文:https://arxiv.org/pdf/1711.07971.pdf
代碼:https://github.com/facebookresearch/video-nonlocal-net
問題:圖像中的長距離依賴難以捕捉
在圖像識別任務中,圖像的不同部分之間可能存在重要的關聯,即使這些部分在圖像中相距很遠。
例如,在理解一個場景中的物體關系時,遠處的背景可能對識別前景物體至關重要。
傳統解法:深層卷積神經網絡(CNN)
- 子特征1:深層堆疊
- 之所以用這個解法,是因為 通過增加網絡的深度,逐層擴大感受野,希望能間接捕捉到遠處區域的信息。
- 子特征2:重復的局部操作
- 之所以用這個解法,是因為 卷積操作本質上是局部的,需要通過多層重疊來嘗試覆蓋更大的區域。
本文解法:非局部神經網絡
- 子特征1:直接長距離交互
- 之所以使用非局部操作,是因為 它允許網絡在計算某個位置的響應時,直接考慮圖像中所有位置的信息,從而無需依賴于逐步擴大的局部操作。
- 子特征2:效率和靈活性
- 之所以使用非局部操作,是因為 這種方法不僅能更直接地捕獲長距離依賴,還能以較少的層數實現,提高了模型的效率和靈活性。
傳統CNN方法:通過增加網絡深度,逐步增大感受野,希望能捕獲到更遠處物體的信息。
這種方法(卷積+下采樣的池化層)雖然在某種程度上有效,但計算成本高,且當依賴關系跨越很長距離時,效果可能不理想。
非局部神經網絡方法:通過插入非局部操作塊,直接計算圖像中任何兩點之間的關系,無論它們相距多遠。
這種方法能夠更直接有效地捕獲長距離依賴,對于場景理解等復雜任務表現更好,同時保持了較低的計算復雜度。
長距離技術對比
本文的非局部神經網絡及其相關技術主要聚焦于解決深度學習模型中的長距離依賴問題,特別是在圖像處理、視頻分析、自然語言處理等領域。
這些技術通過考慮輸入數據中遠距離元素之間的關系,能夠捕捉和利用這些信息以提高模型的性能。
我們將非局部神經網絡與其他一些流行技術進行對比,以突出其獨特之處和應用場景。
非局部神經網絡 vs. 卷積神經網絡(CNN):
- 局部性原則:CNN通過濾波器在輸入數據上滑動來捕捉局部特征,這意味著每次操作只考慮輸入數據的一個小鄰域。這種方法在圖像識別等任務中非常有效,因為它利用了圖像中的局部空間連續性。
- 長距離依賴:與CNN不同,非局部神經網絡直接計算輸入數據中任意兩點之間的關系,使得模型能夠捕獲長距離依賴。這對于那些需要全局理解輸入數據的任務尤其重要,如視頻分類,其中時間跨度內的動作識別依賴于跨幀的信息。
非局部神經網絡 vs. 循環神經網絡(RNN):
- 序列數據處理:RNN設計用來處理序列數據,通過遞歸地處理序列中的每個元素,并保持一個內部狀態來存儲之前元素的信息,從而理解序列中的時間依賴。
- 效率和長期依賴:雖然RNN能夠處理時間序列數據中的依賴關系,但它們在捕獲長期依賴方面存在困難,并且訓練過程中容易遇到梯度消失或爆炸的問題。非局部神經網絡通過其結構能夠更直接地捕獲長期依賴,且通常更容易訓練。
非局部神經網絡 vs. Transformer:
- 自注意力機制:Transformer模型通過自注意力機制來處理序列數據,允許模型在計算序列中每個元素的表示時考慮到序列中的所有元素。這使得Transformer非常擅長捕獲長距離依賴,特別是在處理自然語言任務時。
- 通用性和特定應用:雖然Transformer和非局部神經網絡都能處理長距離依賴問題,但Transformer尤其在自然語言處理領域表現出色。相比之下,非局部神經網絡更多地被應用于圖像和視頻分析領域,其設計更側重于捕獲這些類型數據中的空間和時空依賴。
采用自注意力機制改進的方法:
- 【YOLO v5 v7 v8 小目標改進】BiFormer:從局部空間特征到高效的全局空間特征
應用場景選擇:
選擇非局部神經網絡還是其他技術,取決于特定任務的需求:
- 對于需要捕獲圖像或視頻數據中的復雜空間和時空依賴的應用,非局部神經網絡提供了一個有效的解決方案。
- 對于序列數據處理,特別是需要理解長文本或進行語言翻譯的任務,Transformer可能是更好的選擇。
- 當任務側重于捕獲局部圖像特征或進行簡單的時間序列預測時,CNN和RNN可能分別是更合適的工具。
結論: 非局部神經網絡及其相關技術在處理長距離依賴方面提供了一個強有力的工具,尤其適用于那些傳統方法難以處理的復雜空間和時間數據依賴問題。
Non-local Block是怎么設計
非局部塊(Non-local Block)是一種設計用于捕捉深度學習模型中長距離依賴關系的結構,可以被集成到各種現有的神經網絡架構中,如卷積神經網絡(CNN)或循環神經網絡(RNN)。
非局部塊的設計靈感來源于非局部均值操作,它通過計算輸入特征圖中任意兩點之間的關系來直接捕捉全局依賴,而不僅僅是局部鄰域的信息。

上圖是,如何通過權重平均所有位置的特征來計算特定位置的響應。
例如,它關聯了第一幀中的足球和最后兩幀中的足球。

?
其實非局部操作可以關聯第一幀中足球的位置與后續幀中足球的位置,即使它們在時間和空間上是分離的。
這種關聯有助于網絡更準確地識別和理解足球運動的整個序列。
非局部塊的工作機制包括以下步驟:
-
成對關系函數 (f): 計算不同幀之間的相似度或關系(如足球在不同幀中的位置),從而實現幀與幀之間的關聯。
-
表示函數 (g): 提取每幀中足球位置的特征表示,這些特征可以是足球的形狀、顏色或其他視覺特征。
-
歸一化函數 (C(x)): 確保計算得到的響應在不同幀間是比例適當的,以避免由于幀數變化帶來的影響。
-
殘差連接: 允許網絡在添加非局部塊的同時保留原始特征,確保新舊信息的有效融合。
-
靈活性: 非局部塊可以插入網絡中任何需要捕捉長距離依賴的層中,提供對全局信息的理解以及對局部特征的敏感性。
通過這種方式,非局部神經網絡在視頻分類任務中實現了對足球動作序列的全局理解,如從起踢到落地的整個運動過程,即使這些動作在視頻中是分散的。
這種全局理解對于復雜動作的準確分類至關重要。
非局部塊的設計細節:
非局部塊的核心是一個基于非局部操作的計算單元,其基本形式可以表示為:
- y i = 1 C ( x ) ∑ ? j f ( x i , x j ) g ( x j ) y_i = \frac{1}{C(x)} \sum_{\forall j} f(x_i, x_j)g(x_j) yi?=C(x)1?∑?j?f(xi?,xj?)g(xj?)
這里:
- ( i ) (i) (i) 是要計算響應的輸出位置的索引(可以是空間、時間或時空中的位置)。
- ( j ) (j) (j) 遍歷所有可能的位置。
- ( x ) (x) (x) 是輸入信號(圖像、序列、視頻或它們的特征)。
- ( y ) (y) (y) 是與 (x) 大小相同的輸出信號。
- ( f ) (f) (f) 是一個成對函數,用于計算位置 (i) 和所有 (j) 之間的關系(例如,相似度或親和力)。
- ( g ) (g) (g) 是一個一元函數,用于在位置 (j) 上計算輸入信號的表示。
- C ( x ) C(x) C(x) 是一個歸一化因子。
非局部塊的具體實現步驟包括:
-
成對關系函數 (f):這個函數計算了位置 (i) 與其他所有位置 (j) 之間的關系。
一個常見的選擇是使用嵌入式高斯函數來計算這種相似度。
用于評估任意兩幀之間的相關性。
例如,使用嵌入式高斯函數來計算不同幀之間的相似度,從而捕獲動作的連續性和變化。
-
表示函數 (g):這個函數用于獲取位置 (j) 處的輸入信號的表示,通常通過一個線性變換(例如,權重矩陣 ( W g ) (W_g) (Wg?))來實現。
提取每一幀的特征表示。
通過對每個位置(即每一幀)應用線性變換,提取對理解視頻內容有用的特征。
-
歸一化:通過 C ( x ) C(x) C(x) 實現,確保了整個操作的輸出不會因為特征數量的不同而產生過大的變化。
確保所有幀貢獻的總和被適當標準化,保持響應的穩定性。
-
殘差連接:為了將非局部塊無縫集成到現有網絡中并保持網絡性能,通常會在非局部塊的輸出上添加一個殘差連接,即 z i = W z y i + x i z_i = W_z y_i + x_i zi?=Wz?yi?+xi?,其中 W z W_z Wz? 是可學習的權重矩陣,用于調整非局部操作的輸出,以匹配輸入 x i x_i xi? 的維度,“+” 表示殘差連接。
保證非局部塊可以無縫集成到任何預訓練模型中,增強而不替代原有的特征提取能力。
-
靈活性:非局部塊可以被插入到神經網絡的任意位置,既可以用來捕捉早期特征的全局依賴,也可以用于更深層次的特征。
這種設計使得非局部塊既可以增強模型對全局信息的理解,也保持了對局部特征的敏感性。
非局部塊通過這樣的設計,能夠有效地增強深度學習模型對全局依賴的捕捉能力,這對于處理圖像識別、視頻分類等需要理解復雜空間或時空關系的任務尤為重要。
整合全局信息:
操作:非局部塊通過遍歷視頻中的所有幀,基于成對函數和表示函數計算得到的權重,整合全局信息。
- 每一幀的輸出不僅反映了該幀本身的信息,還包含了與視頻中其他所有幀的關系。
- 這樣,模型就能夠理解視頻中跨越長時間序列的動態變化。
?
Non-local 神經網絡
整篇文章的核心解法是引入非局部神經網絡來增強深度學習模型對視頻內容中長距離時空依賴的捕捉能力,特別是在視頻分類任務中。
這一解法通過幾個關鍵概念和技術構建而成,形成了一個系統的方法來提高模型性能。
非局部塊的詳細結構:
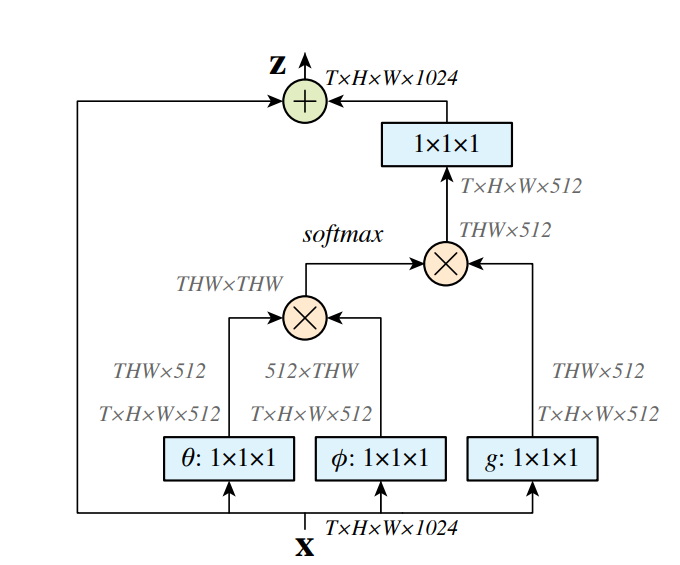
-
輸入特征圖(X): 輸入信號是具有時間(T)、高(H)、寬(W)和通道數(1024)的四維特征圖。
-
變換函數(θ, φ, g):
- θ: 一個1×1×1的卷積操作,用于轉換輸入特征圖X,以便計算相似度。
- φ: 類似于θ,也是一個1×1×1的卷積操作,它與θ配合使用,共同決定特征之間的權重。
- g: 與θ和φ一起工作,1×1×1的卷積操作,用于提取輸入特征的另一個表示,這個表示會與由θ和φ確定的權重結合。
-
計算關系權重: 使用θ和φ變換后的特征計算兩個位置之間的相似度,通常涉及到計算點積并應用softmax函數來獲取歸一化的注意力權重。
-
應用權重: 將計算出的注意力權重應用到由g變換得到的特征上,這通常通過矩陣乘法實現。
-
加權特征組合: 對于每個位置i,將所有位置j的加權特征求和,得到非局部操作的輸出。
-
歸一化因子(C(x)): 通常情況下,為了使非局部操作的輸出與輸入特征圖保持一致的尺度,需要通過歸一化因子C(x)來調整。
-
輸出特征圖(Y): 最終,非局部操作的輸出是通過在輸入特征圖X上加上經過非局部處理的特征圖得到的,這一步通常涉及到殘差連接和一個1×1×1的卷積操作Wz。
-
殘差連接: 為了融入原始特征并防止訓練過程中的性能退化,輸出特征圖Y會與輸入特征圖X進行元素級的相加。
通過這個結構,非局部塊能夠在每個位置捕捉全局依賴,不僅包括空間位置之間的關系,還包括跨時間的動態變化,這對于理解復雜的視頻序列至關重要。
這種設計使得網絡能夠強調重要的特征并抑制不相關的信息,從而提高視頻分類任務的準確性。
?
整體關聯圖:
-
2D ConvNet基線(C2D):提供了處理視頻的起點,主要關注于圖像的空間特征,而時間信息通過簡單的池化操作來整合。
這是最基礎的視頻處理模型,主要強調單幀圖像的處理。
-
膨脹的3D ConvNet(I3D):在C2D的基礎上增加了對時間維度的直接處理,通過將2D卷積核“膨脹”成3D形式,使得模型能夠在空間和時間上同時捕捉特征。
這一步提升了模型對視頻中動態內容的理解能力。
-
非局部網絡:在C2D或I3D模型的基礎上進一步增強,通過插入非局部塊來捕捉全局的時空依賴。
非局部網絡不僅關注局部信息,還能夠理解視頻中任意兩點之間的長距離關系,從而全面提升模型對復雜視頻內容的理解。
-
成對關系函數 (f):在非局部塊內部,用于計算視頻幀之間的相似度或關系,是捕捉全局依賴的關鍵。
-
表示函數 (g):用于提取每個位置(視頻幀)的特征表示,與(f)函數配合使用,強化模型對每一幀的理解。
-
歸一化:確保非局部塊的輸出在不同視頻或幀數下保持穩定,通過歸一化處理來平衡各個位置的貢獻。
-
殘差連接:保證非局部塊可以無縫集成到任何預訓練模型中,增強模型性能的同時,避免破壞原有的學習成果。
-
這些概念和技術的關聯圖可以想象為一棵樹:
- 樹根是2D ConvNet基線,它支持整個模型的基礎;
- 樹干是膨脹的3D ConvNet,為模型提供了時間維度上的處理能力;
- 樹枝是非局部網絡,進一步延伸模型的能力,使其能夠捕捉更廣泛和深入的時空依賴;
- 而成對關系函數、表示函數、歸一化和殘差連接等則像是樹葉和果實,為非局部網絡提供了必要的細節和功能,使其能夠有效地工作。
通過這樣的結構,非局部神經網絡能夠有效地增強深度學習模型對視頻內容的全局理解,特別是在處理需要理解長時間跨度內復雜動態的視頻分類任務時。
效果
實驗結果表明,即使在基線C2D模型中添加一個非局部塊也能顯著提高模型的分類性能,表現為在驗證集上的準確率有所提高。
將單個非局部塊添加到ResNet的不同階段的結果表明,無論是在網絡的早期階段還是后期階段添加非局部塊,都能帶來性能的提升,但是添加到空間尺寸較小的res5階段時提升稍小。
這可能是因為在較小的空間尺寸上,模型提供的空間信息不足以進行精確的空間關系分析。
增加更多非局部塊的實驗結果表明,在網絡中添加更多的非局部塊可以進一步提高性能,特別是當這些塊被添加到不同的網絡層級時,它們可以執行長距離多跳通信,幫助模型更有效地捕捉復雜的時空依賴關系。
小目標漲點
更新中…


)




airtest操作)




)






