聽課(李宏毅老師的)筆記,方便梳理框架,以作復習之用。本節課主要介紹了什么是機器學習,機器學習的類型和流程,用一個現實中的例子詳細地展示了整個工作流程。
1. 機器學習的定義

2. 不同的函數類型
- 預測數字
- 分類(不僅包括二分類,還有像阿爾法狗下圍棋也是一種分類,不過是更復雜的分類)
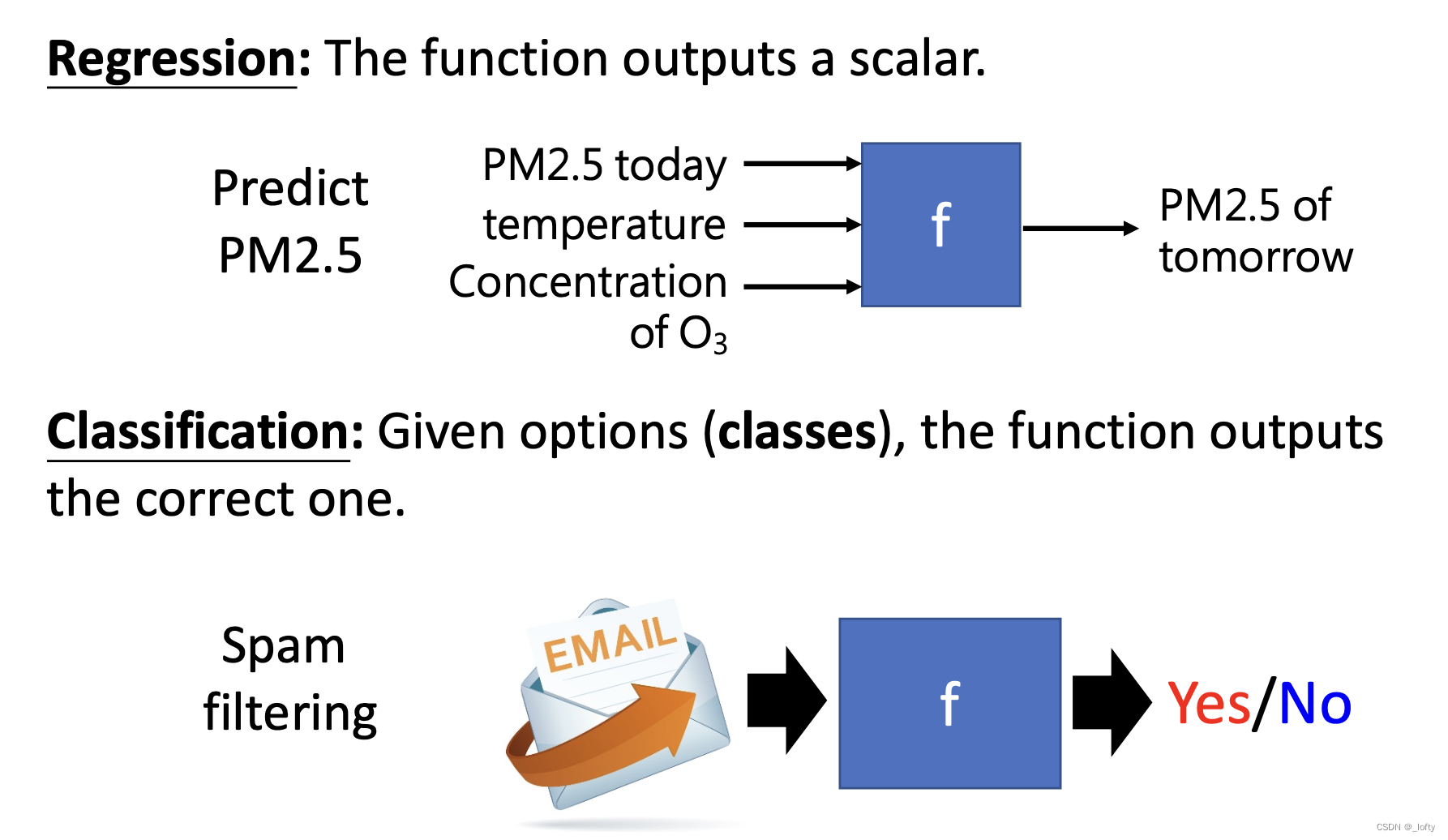
但是除了這兩個類型外還有更復雜的任務——結構學習
就是創造一些有結構的東西,比如圖片和文檔
3. 用一個例子來了解機器學習的過程
3.1 定義一個函數

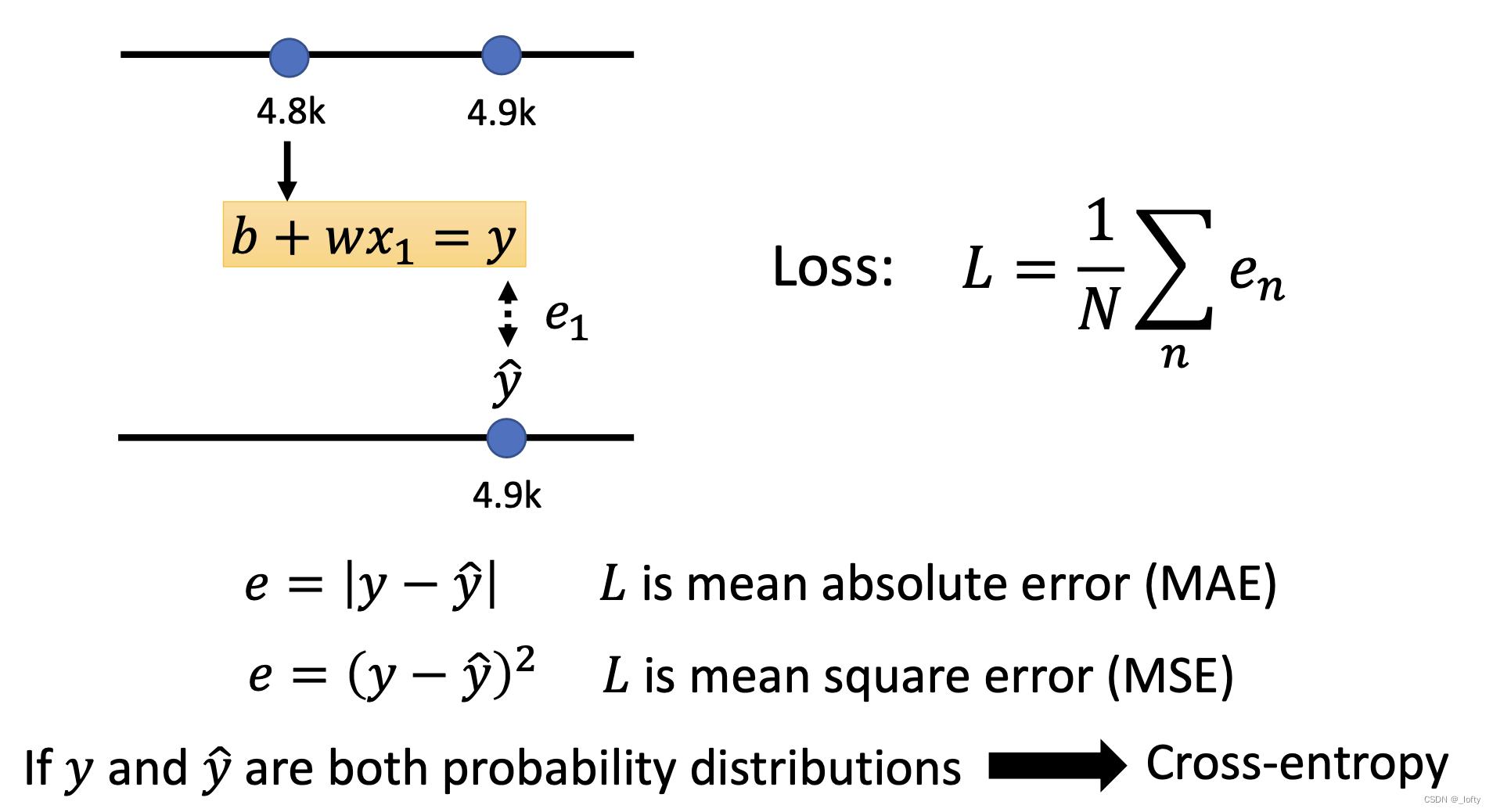
3.2 定義損失函數

總的損失函數值就是把每個真實數據與預測值相減,取絕對值,相加,再除以數據個數。當然這只是一種計算損失函數的方法稱為MAE,還有MSE等。
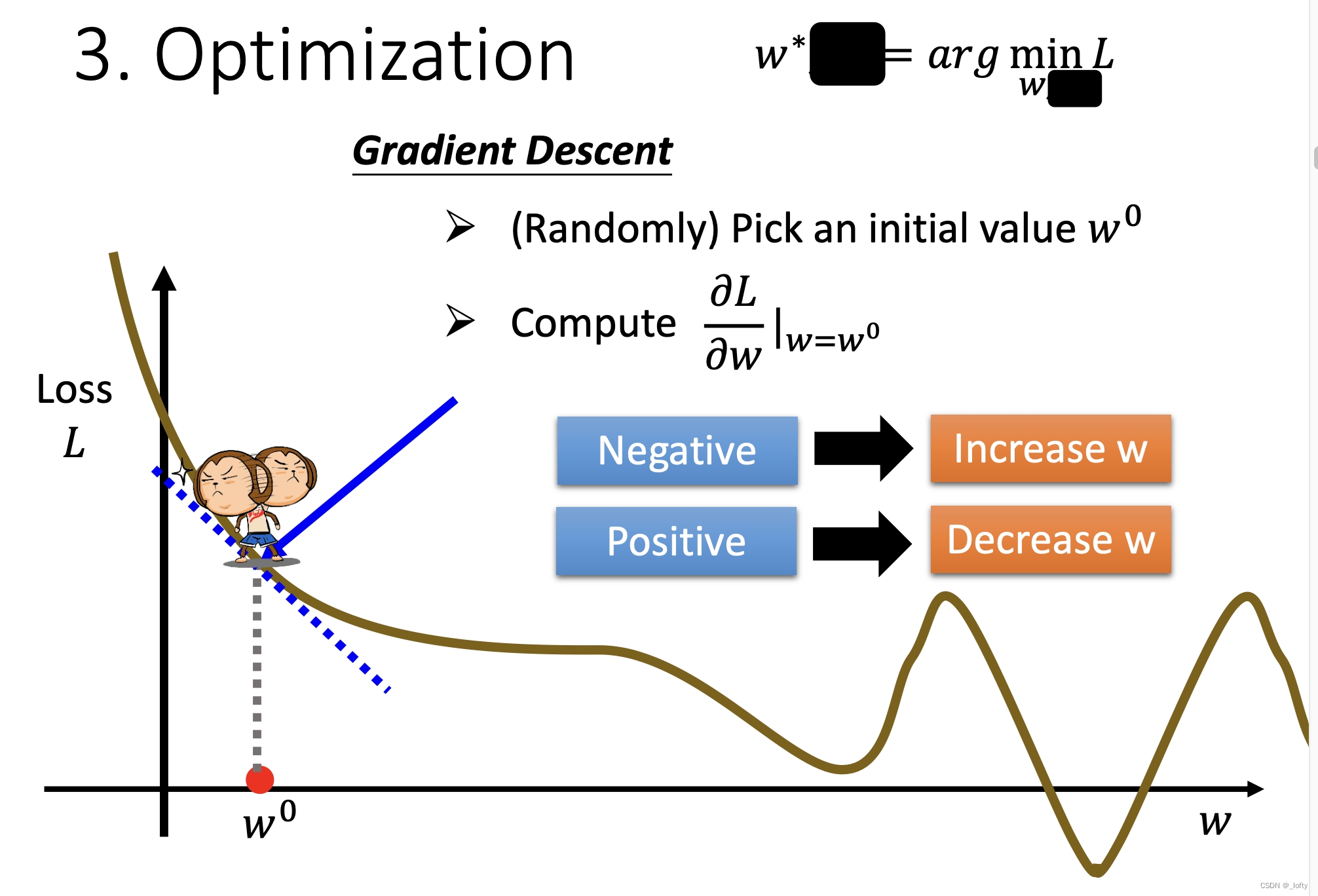
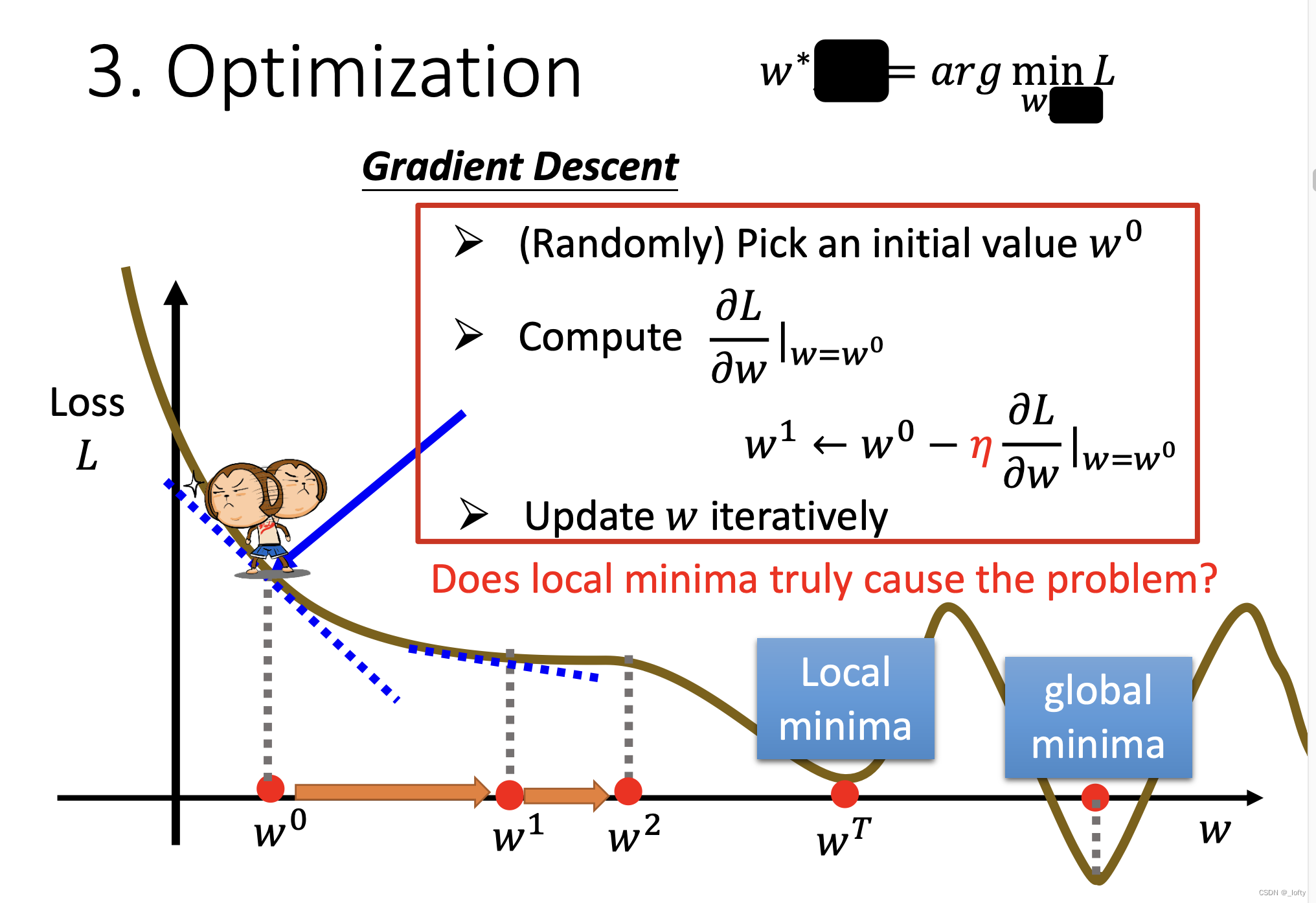
3.3 最優化
優化問題有很多方法,最常用的是梯度下降。
整體計算方法如下圖紅框所示
3.4 總過程小結
一共三步

4. 預測時發現問題并引入數據的周期性
我們之前定義函數的時候,只考慮到了前一天對預測結果的影響,實際上預測出來的效果就像是真實數據向右移動了一天一樣。仔細觀察發現人們觀看該channel的頻次具有周期性,所以建立函數時也應考慮到周期性。
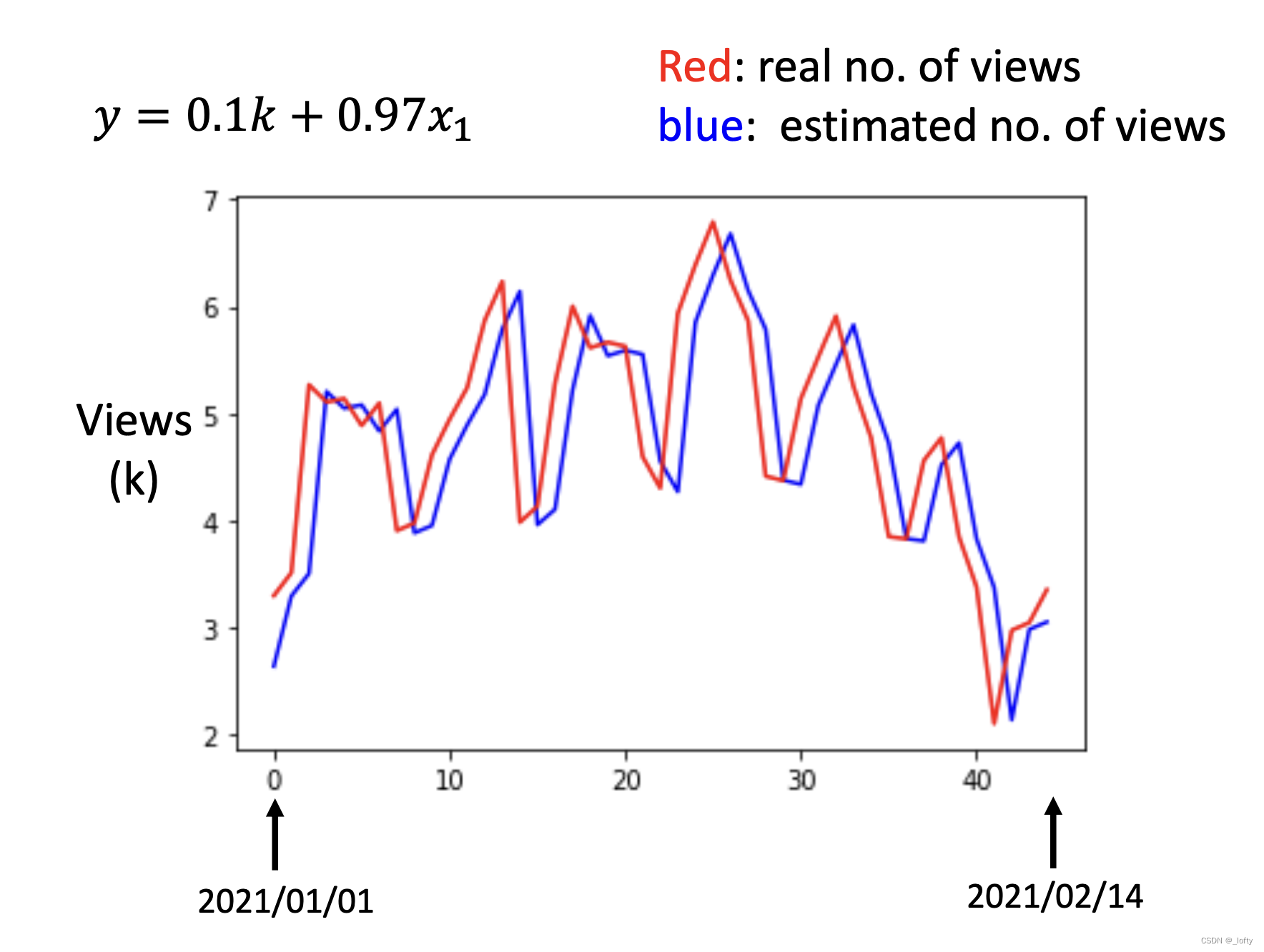
調整函數為:
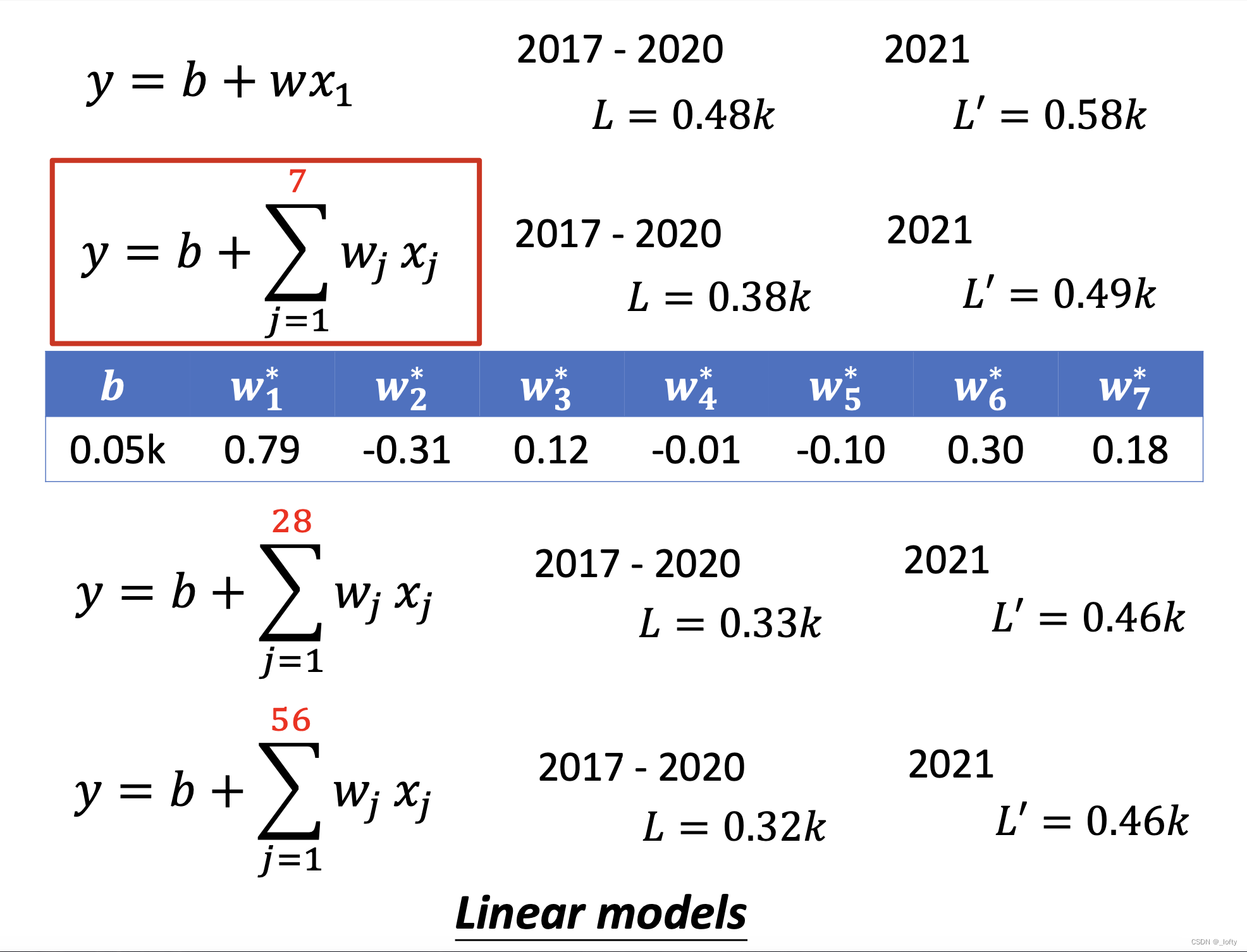
我們也可以如上圖所示以28天、56天為周期
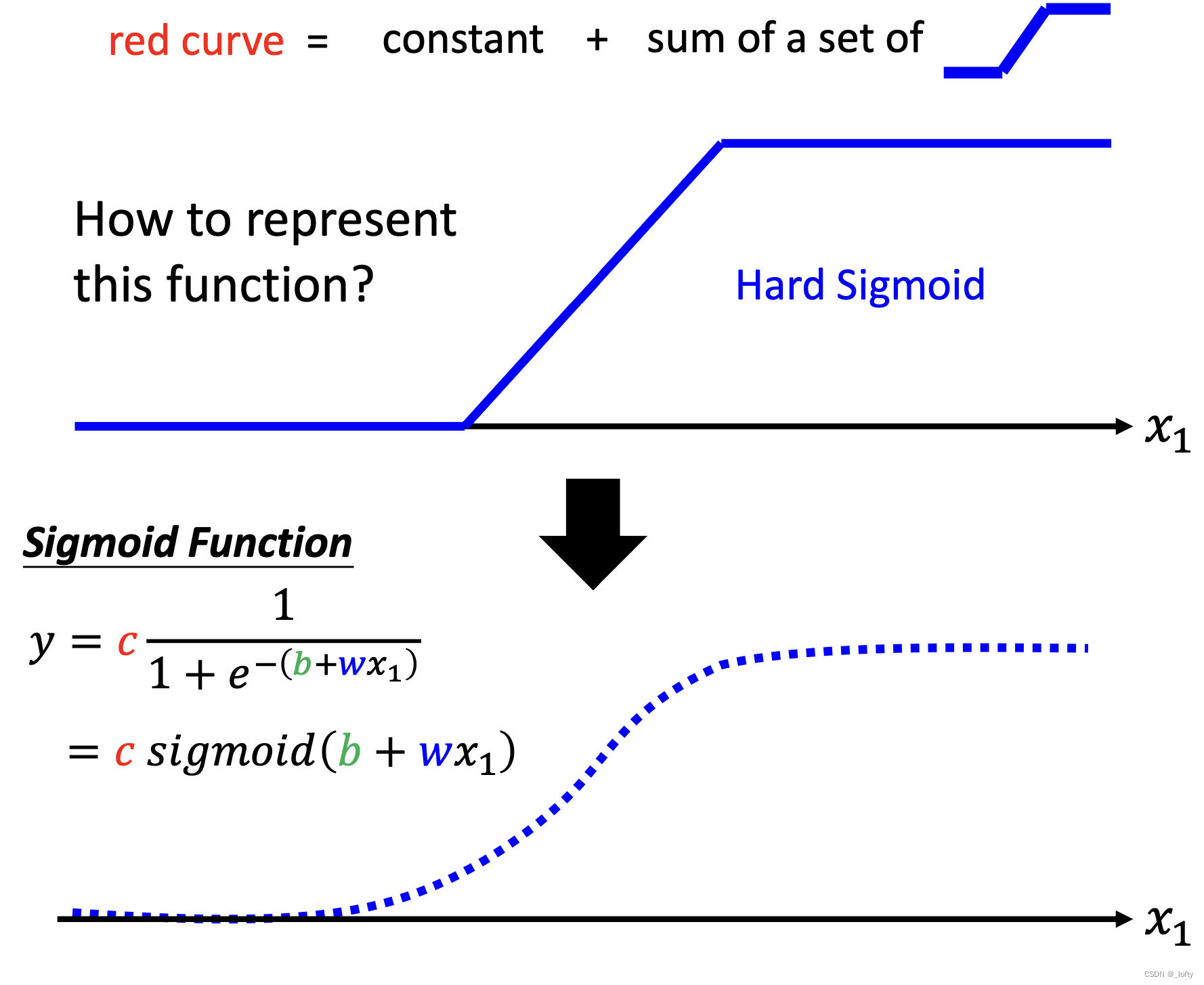
5. 線性模型太簡單,引入激活函數Sigmod函數
前面建立的都是線性模型(Linear models),就算考慮到了周期性,這些模型也是非常簡單的,我們需要考慮到更復雜的模型——sigmod函數。
6. 結合產生新模型:考慮到model bias和周期性
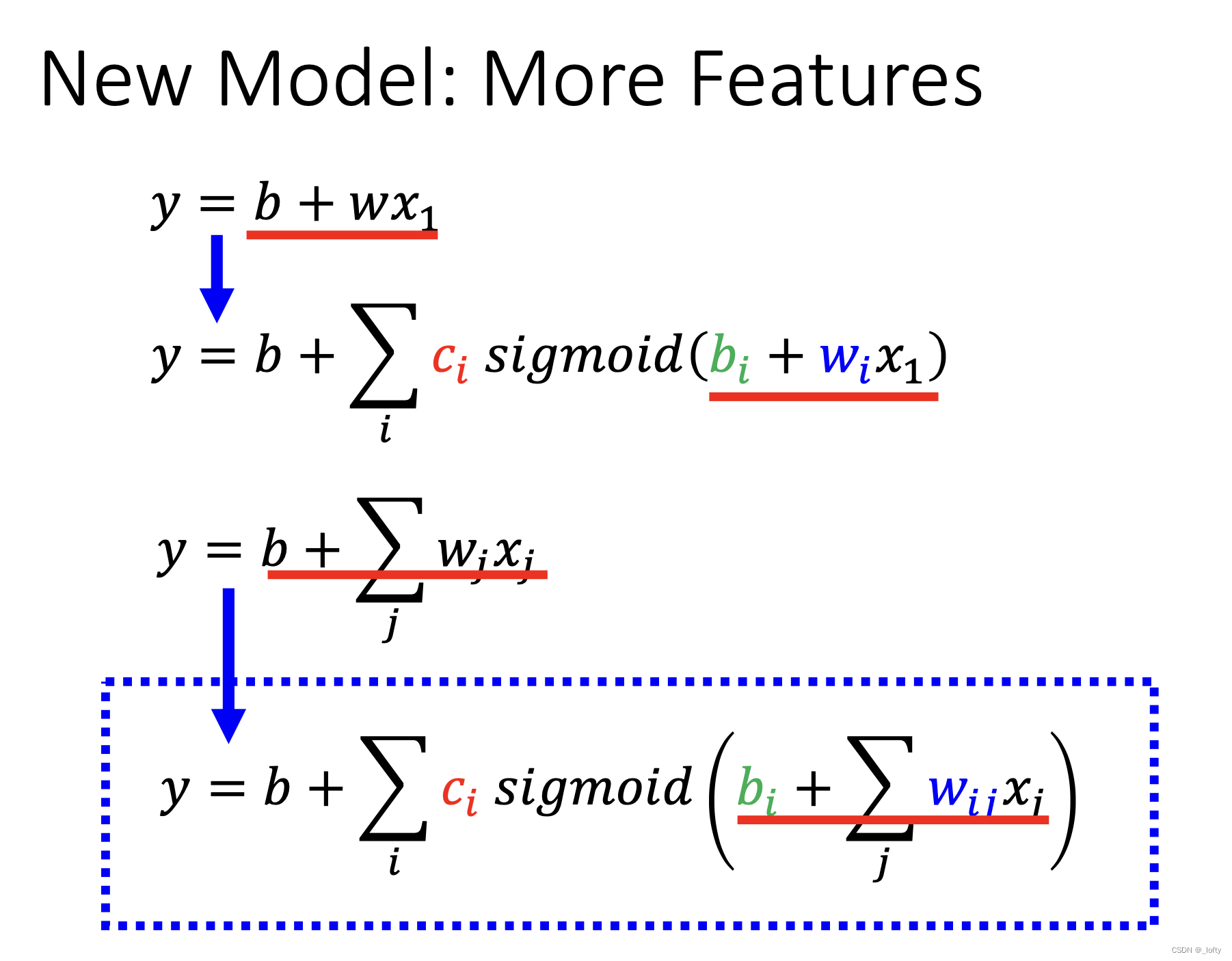
7. Batch與Epoch
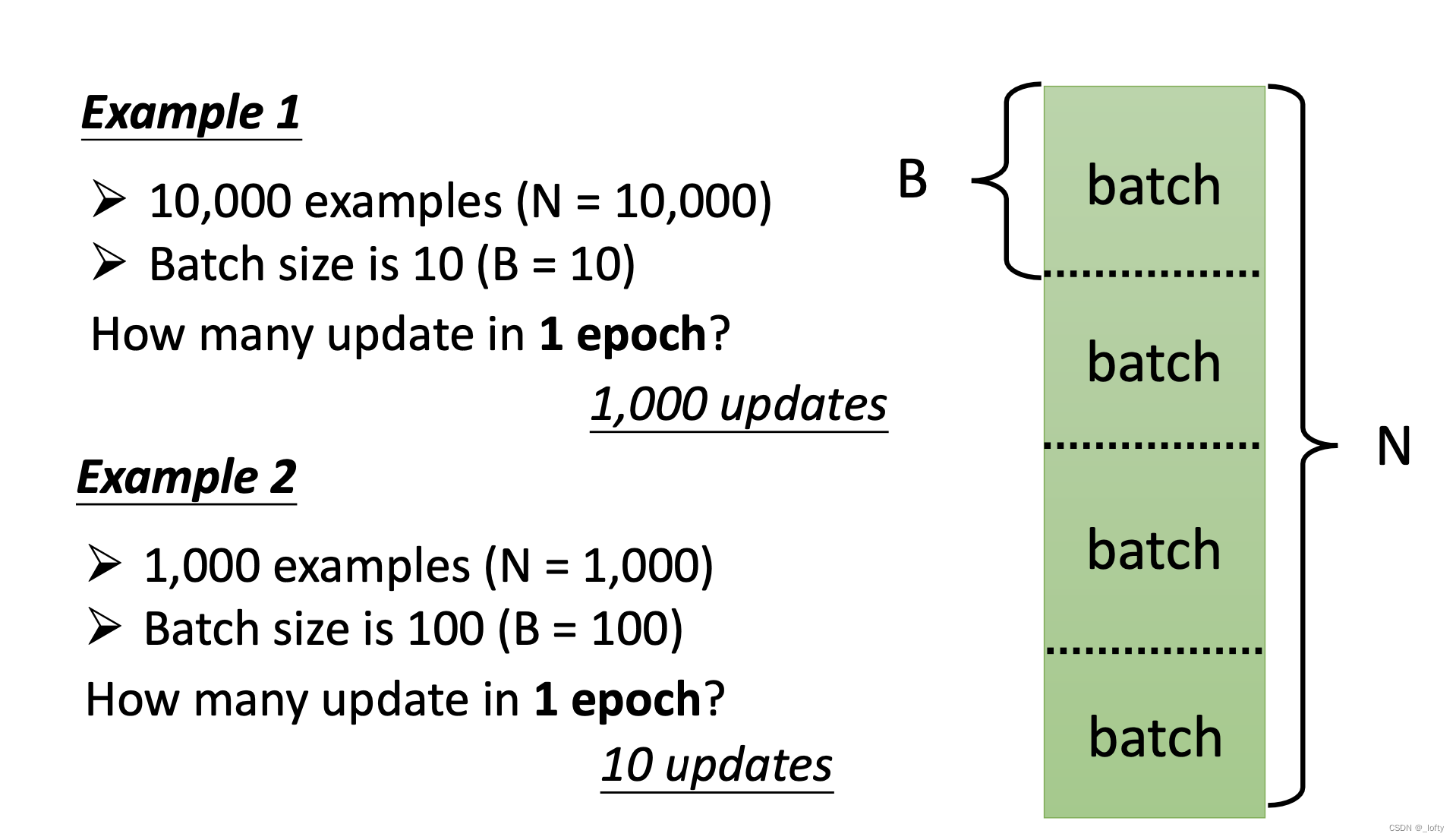
batch有batch size,總的數據除以batch size就是batch 的個數。
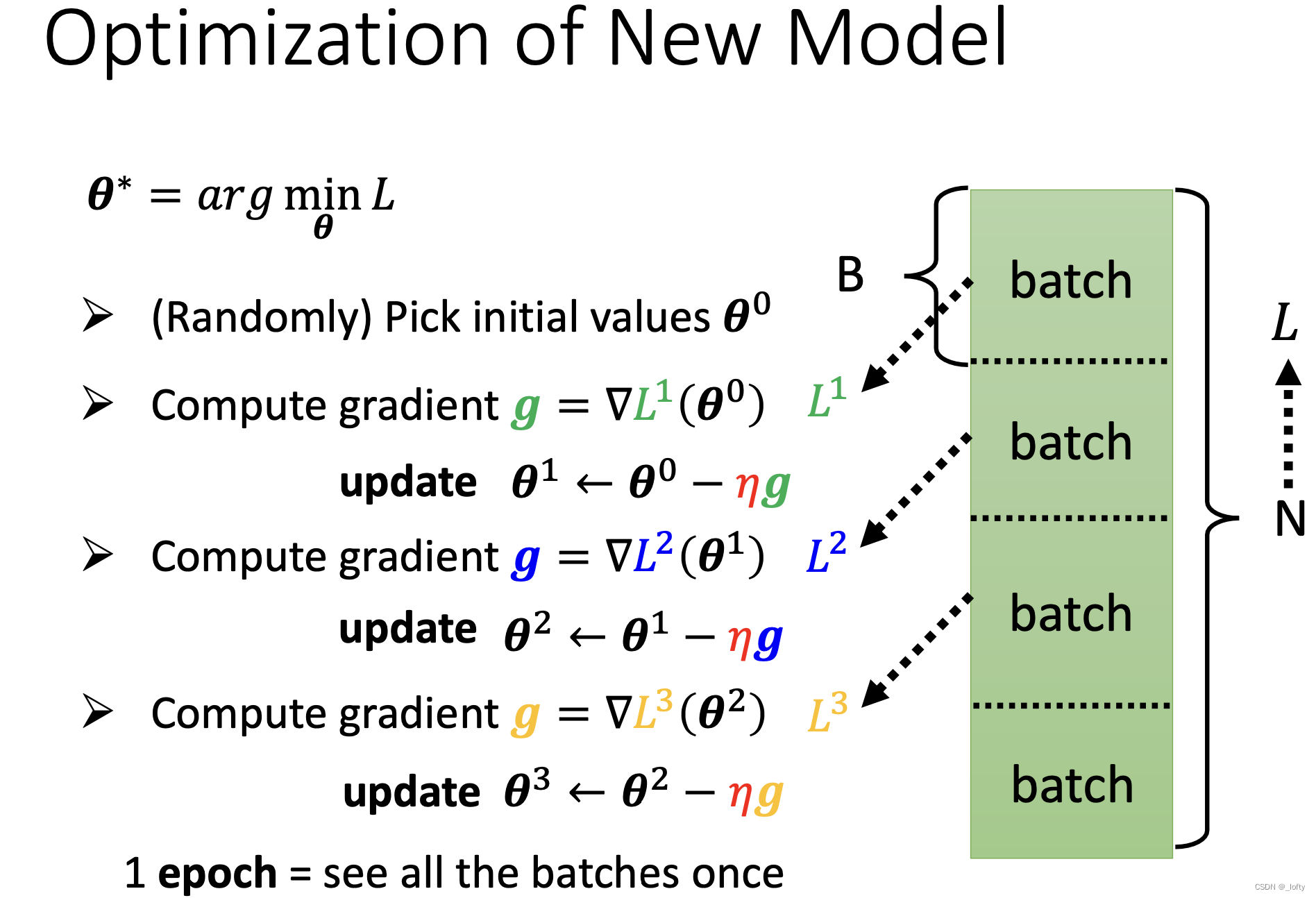
看一次batch后更新一次theta參數。一個Epoch就是把所有batch看過一遍。
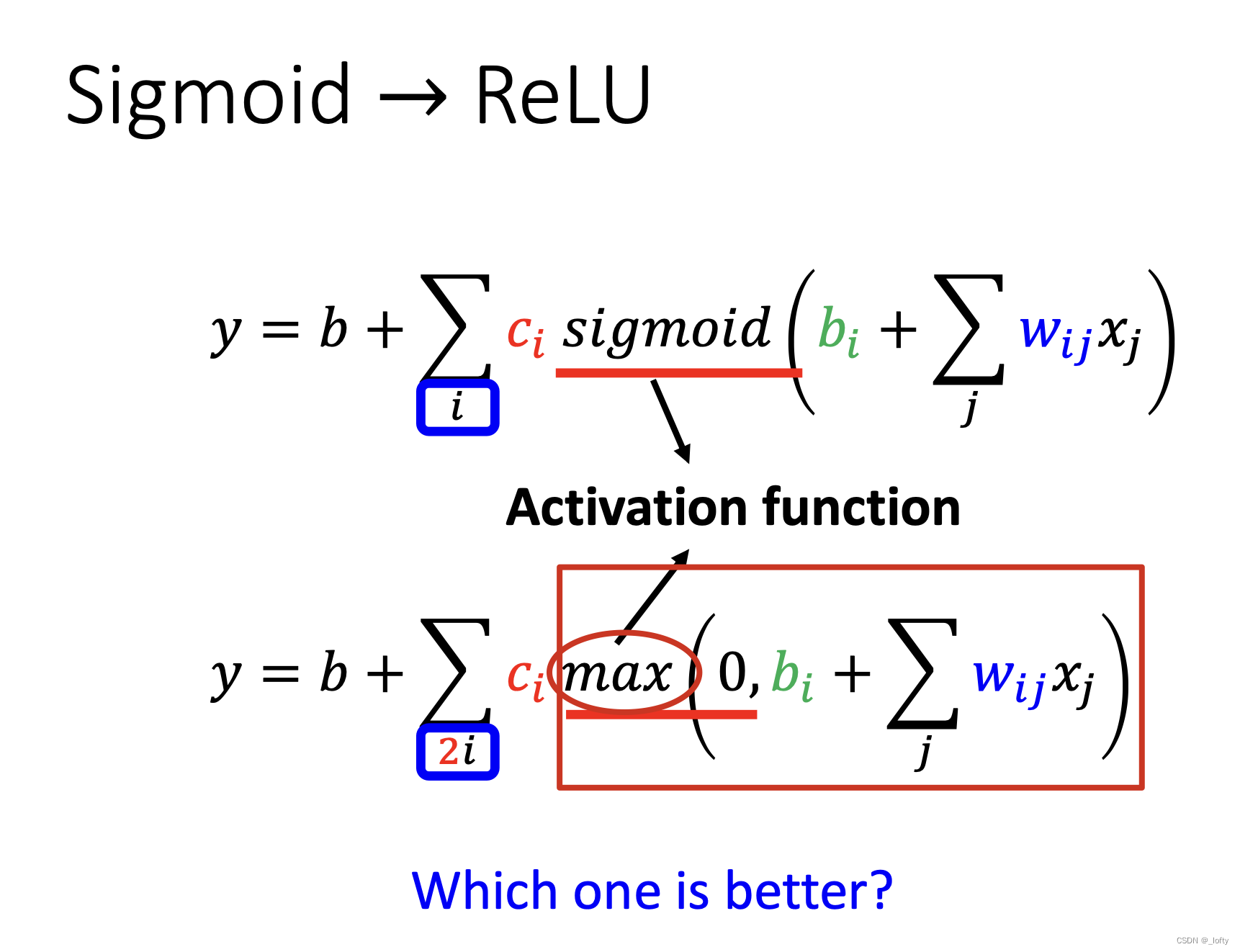
8. 更常見的激活函數ReLU函數
實際上就是跟0比較誰大誰就是輸出,很直接很暴力很簡潔,我喜歡
9. 多來幾次以上流程就是套娃而已
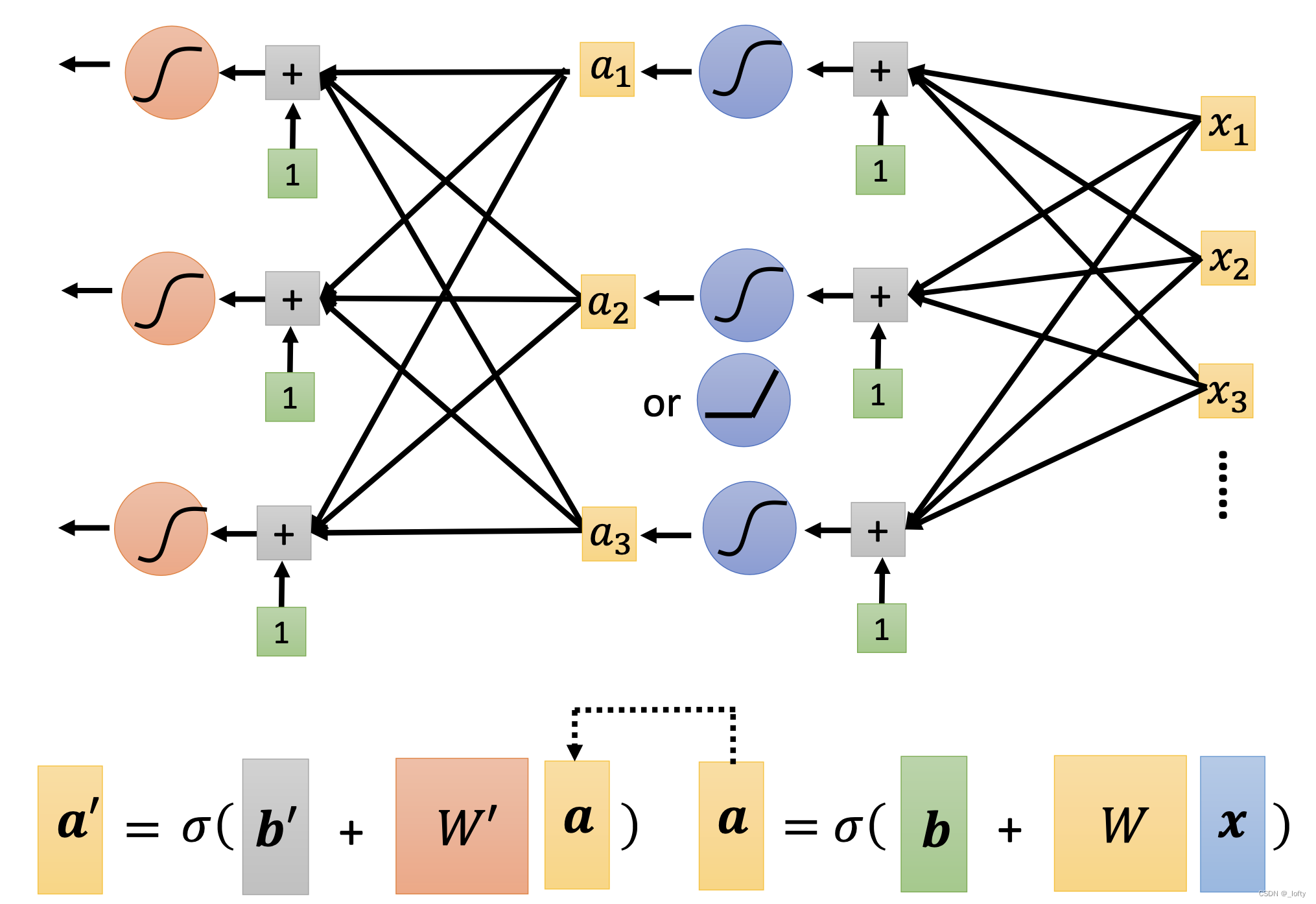
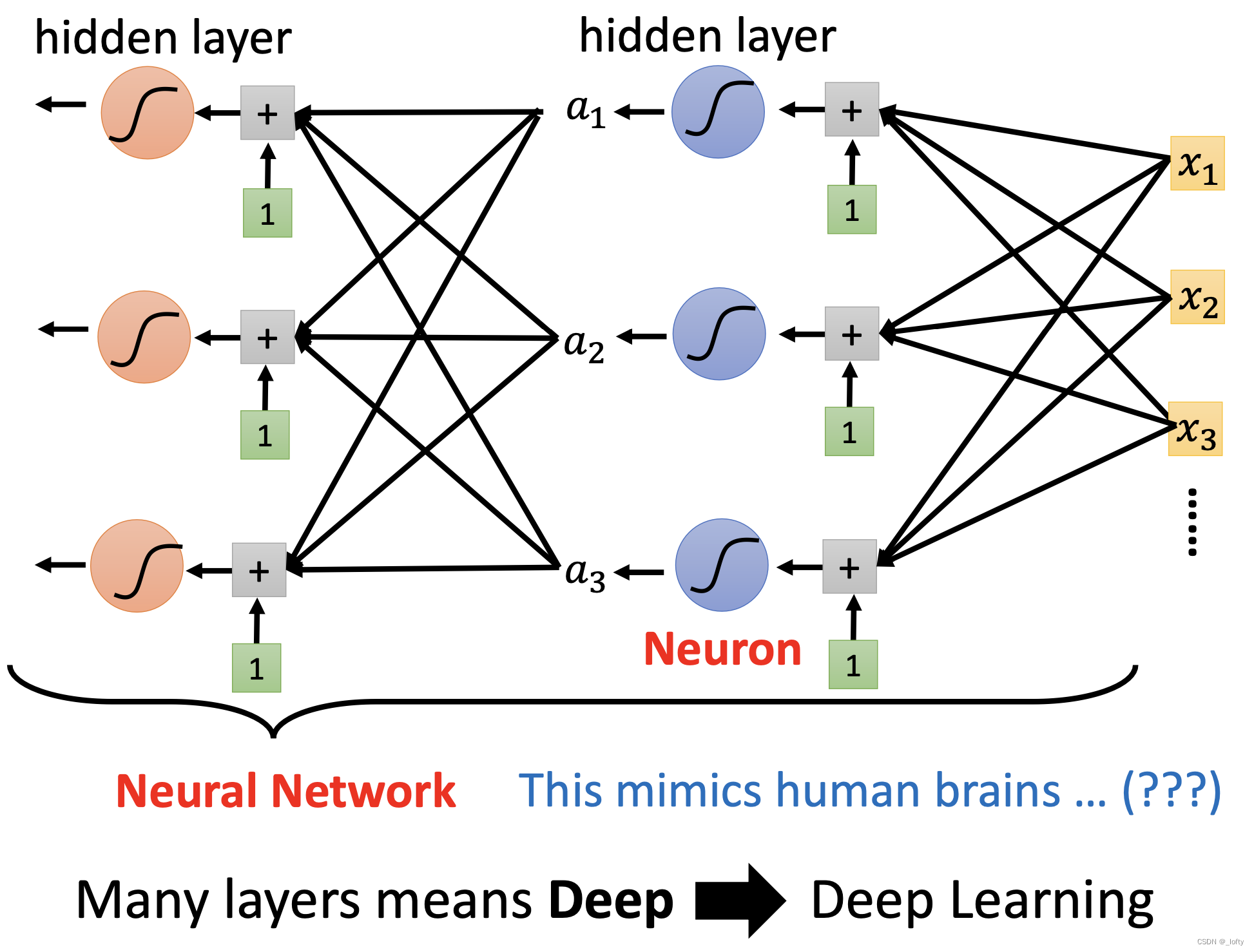
10. 這么好怎么不多來幾層
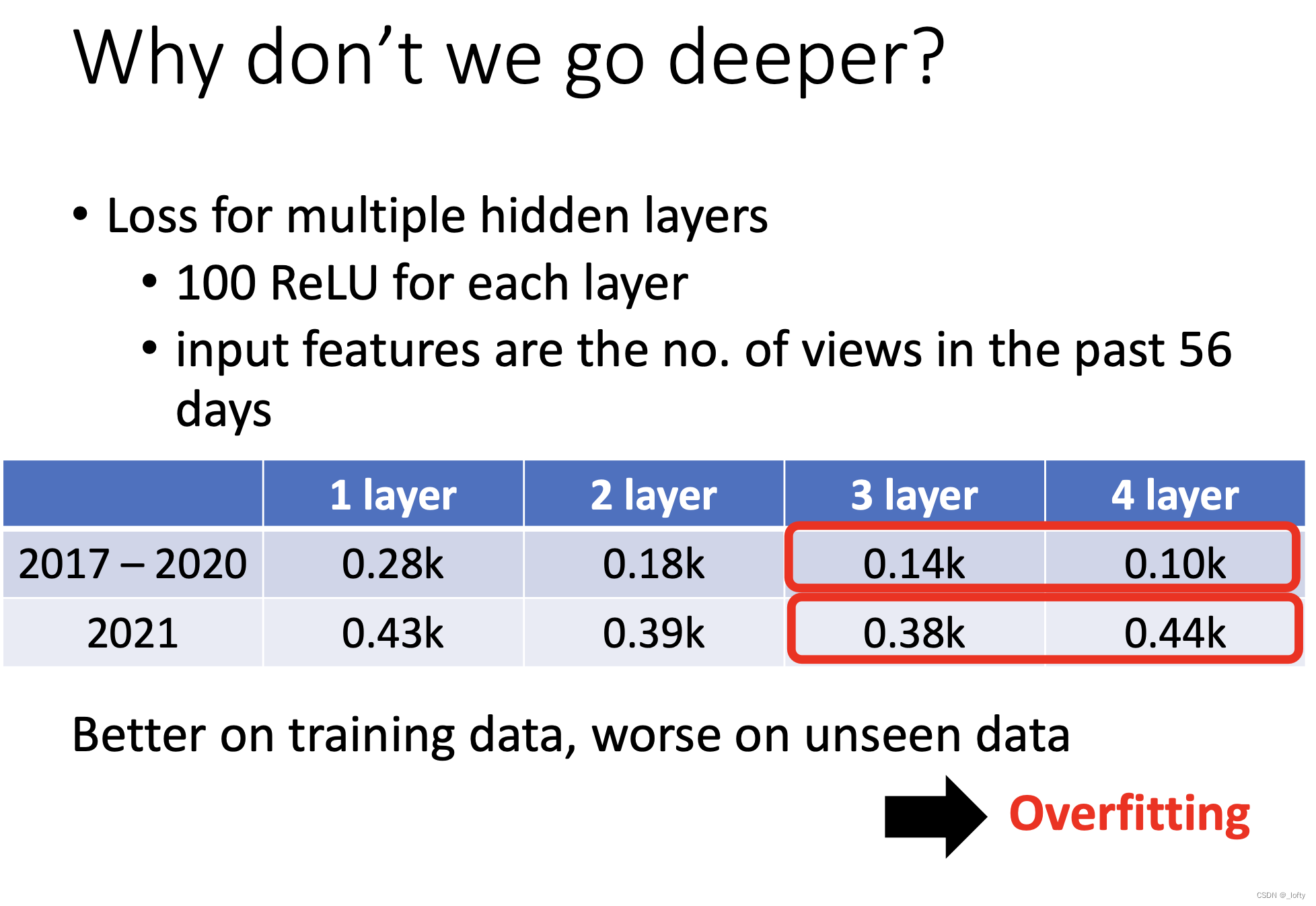
物極必反啊家人們,會出現過擬合現象。模型會在訓練集上訓練過度,超級模仿訓練數據,導致在測試集上表現不好
之 SQL 映射文件)

+three.js(0.161.0)實現3D可視化地圖)

)

)
)


)


)




)
