文章目錄
- MySQL基礎(三)
- 1. 多表查詢
- 1.1 概述
- 1.1.1 數據準備
- 1.1.2 介紹
- 1.1.3 分類
- 1.2 內連接
- 1.3 外連接
- 1.4 子查詢
- 1.4.1 介紹
- 1.4.2 標量子查詢
- 1.4.3 列子查詢
- 1.4.4 行子查詢
- 1.4.5 表子查詢
- 1.5 案例
- 2. 事務
- 2.1 介紹
- 2.2 操作
- 2.3 四大特性
- 3. 索引
- 3.1 介紹
- 3.2 結構
- 3.3 語法
MySQL基礎(三)
1. 多表查詢
1.1 概述
1.1.1 數據準備
SQL腳本:
#建議:創建新的數據庫
create database db04;
use db04;-- 部門表
create table tb_dept
(id int unsigned primary key auto_increment comment '主鍵ID',name varchar(10) not null unique comment '部門名稱',create_time datetime not null comment '創建時間',update_time datetime not null comment '修改時間'
) comment '部門表';
-- 部門表測試
insert into tb_dept (id, name, create_time, update_time)
values (1, '學工部', now(), now()),(2, '教研部', now(), now()),(3, '咨詢部', now(), now()),(4, '就業部', now(), now()),(5, '人事部', now(), now());-- 員工表
create table tb_emp
(id int unsigned primary key auto_increment comment 'ID',username varchar(20) not null unique comment '用戶名',password varchar(32) default '123456' comment '密碼',name varchar(10) not null comment '姓名',gender tinyint unsigned not null comment '性別, 說明: 1 男, 2 女',image varchar(300) comment '圖像',job tinyint unsigned comment '職位, 說明: 1 班主任,2 講師, 3 學工主管, 4 教研主管, 5 咨詢師',entrydate date comment '入職時間',dept_id int unsigned comment '部門ID',create_time datetime not null comment '創建時間',update_time datetime not null comment '修改時間'
) comment '員工表';
-- 員工表測試數據
INSERT INTO tb_emp(id, username, password, name, gender, image, job, entrydate,dept_id, create_time, update_time)
VALUES
(1,'jinyong','123456','金庸',1,'1.jpg',4,'2000-01-01',2,now(),now()),
(2,'zhangwuji','123456','張無忌',1,'2.jpg',2,'2015-01-01',2,now(),now()),
(3,'yangxiao','123456','楊逍',1,'3.jpg',2,'2008-05-01',2,now(),now()),
(4,'weiyixiao','123456','韋一笑',1,'4.jpg',2,'2007-01-01',2,now(),now()),
(5,'changyuchun','123456','常遇春',1,'5.jpg',2,'2012-12-05',2,now(),now()),
(6,'xiaozhao','123456','小昭',2,'6.jpg',3,'2013-09-05',1,now(),now()),
(7,'jixiaofu','123456','紀曉芙',2,'7.jpg',1,'2005-08-01',1,now(),now()),
(8,'zhouzhiruo','123456','周芷若',2,'8.jpg',1,'2014-11-09',1,now(),now()),
(9,'dingminjun','123456','丁敏君',2,'9.jpg',1,'2011-03-11',1,now(),now()),
(10,'zhaomin','123456','趙敏',2,'10.jpg',1,'2013-09-05',1,now(),now()),
(11,'luzhangke','123456','鹿杖客',1,'11.jpg',5,'2007-02-01',3,now(),now()),
(12,'hebiweng','123456','鶴筆翁',1,'12.jpg',5,'2008-08-18',3,now(),now()),
(13,'fangdongbai','123456','方東白',1,'13.jpg',5,'2012-11-01',3,now(),now()),
(14,'zhangsanfeng','123456','張三豐',1,'14.jpg',2,'2002-08-01',2,now(),now()),
(15,'yulianzhou','123456','俞蓮舟',1,'15.jpg',2,'2011-05-01',2,now(),now()),
(16,'songyuanqiao','123456','宋遠橋',1,'16.jpg',2,'2007-01-01',2,now(),now()),
(17,'chenyouliang','123456','陳友諒',1,'17.jpg',NULL,'2015-03-21',NULL,now(),now());
1.1.2 介紹
多表查詢:查詢時從多張表中獲取所需數據
單表查詢的SQL語句:select 字段列表 from 表名;
那么要執行多表查詢,只需要使用逗號分隔多張表即可,如: select 字段列表 from 表1, 表2;
查詢用戶表和部門表中的數據:
select * from tb_emp , tb_dept;
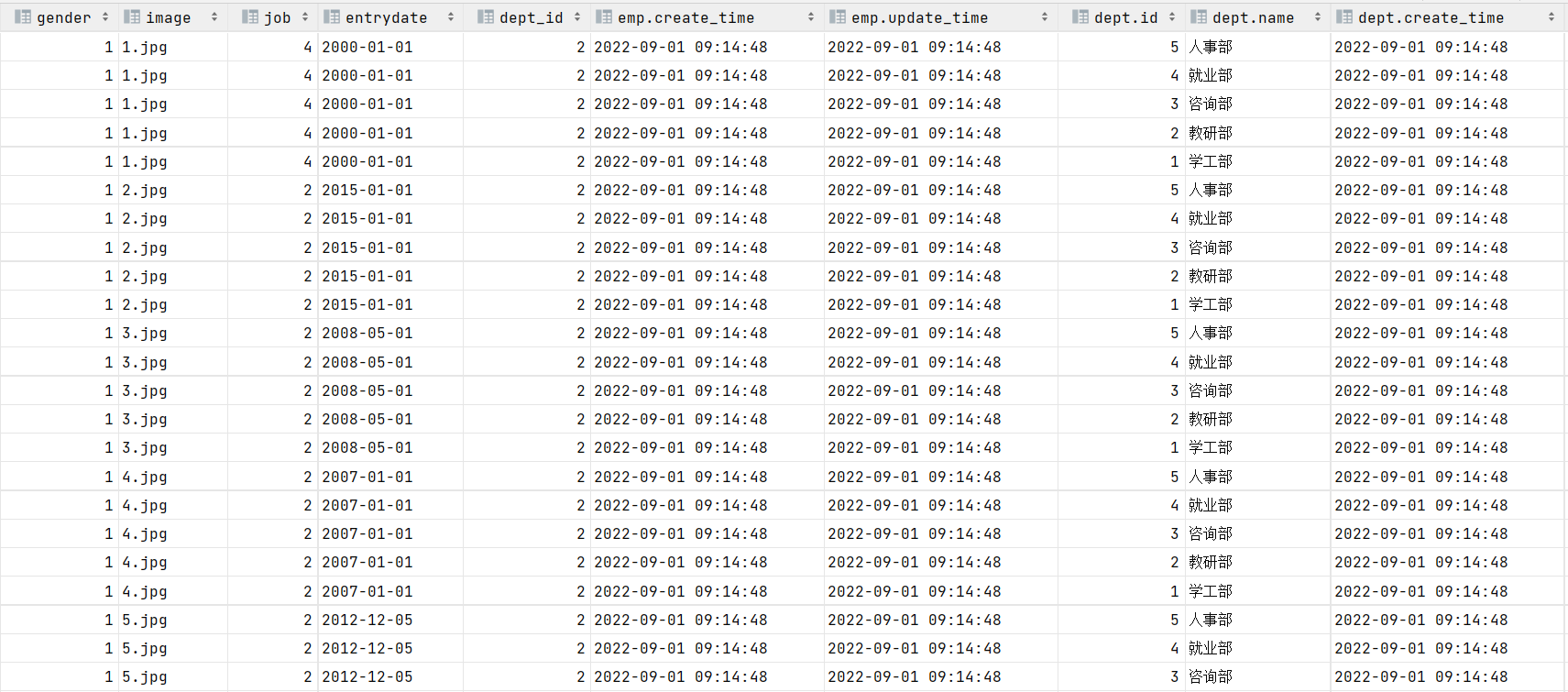
此時,我們看到查詢結果中包含了大量的結果集,總共85條記錄,而這其實就是員工表所有的記錄(17行)與部門表所有記錄(5行)的所有組合情況,這種現象稱之為笛卡爾積。
笛卡爾積:笛卡爾乘積是指在數學中,兩個集合(A集合和B集合)的所有組合情況。
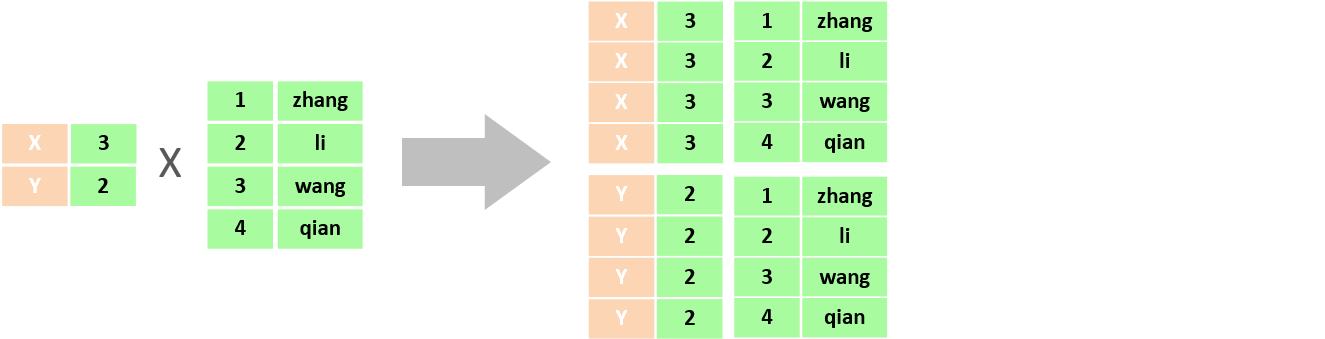
在多表查詢時,需要消除無效的笛卡爾積,只保留表關聯部分的數據
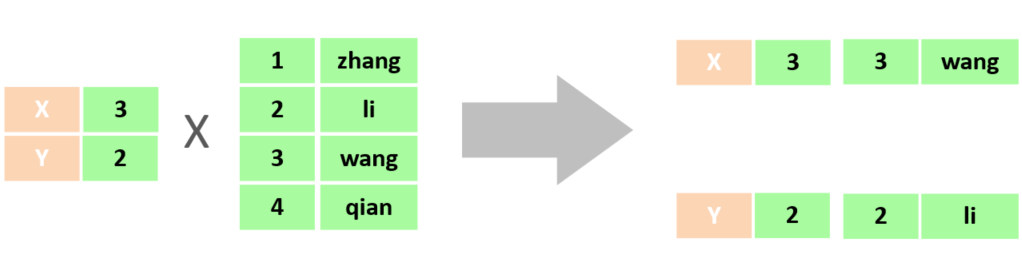
在SQL語句中,如何去除無效的笛卡爾積呢?只需要給多表查詢加上連接查詢的條件即可。
select * from tb_emp , tb_dept where tb_emp.dept_id = tb_dept.id ;
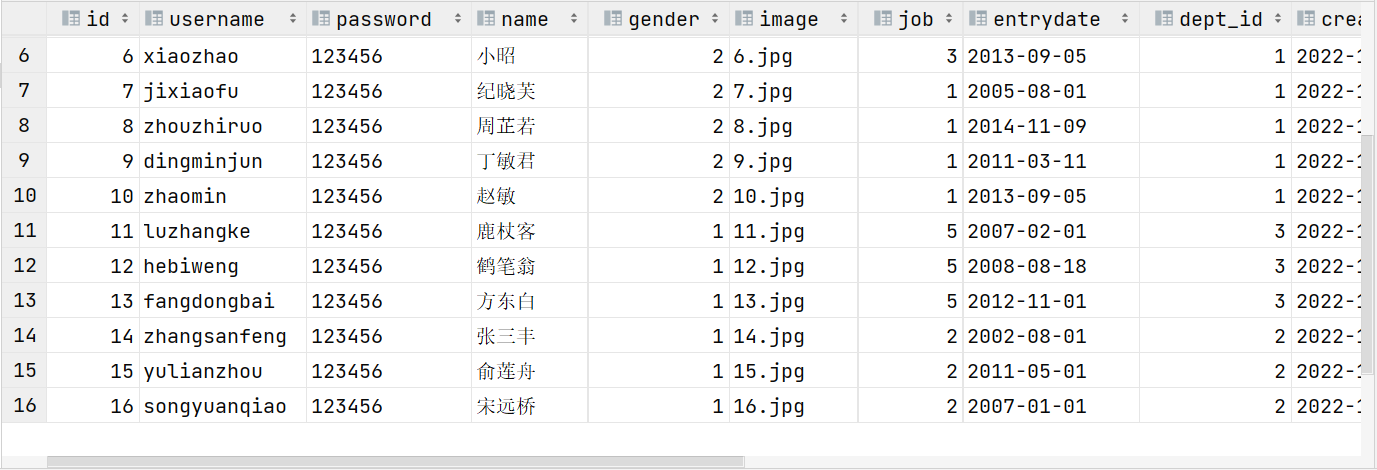
由于id為17的員工,沒有dept_id字段值,所以在多表查詢時,根據連接查詢的條件并沒有查詢到。
1.1.3 分類
多表查詢可以分為:
-
連接查詢
- 內連接:相當于查詢A、B交集部分數據
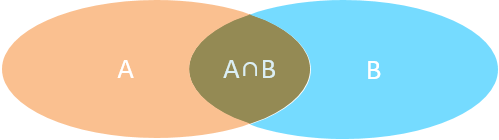
-
外連接
-
左外連接:查詢左表所有數據(包括兩張表交集部分數據)
-
右外連接:查詢右表所有數據(包括兩張表交集部分數據)
-
-
子查詢
1.2 內連接
內連接查詢:查詢兩表或多表中交集部分數據。
內連接從語法上可以分為:
-
隱式內連接
-
顯式內連接
隱式內連接語法:
select 字段列表 from 表1 , 表2 where 條件 ... ;
顯式內連接語法:
select 字段列表 from 表1 [ inner ] join 表2 on 連接條件 ... ;
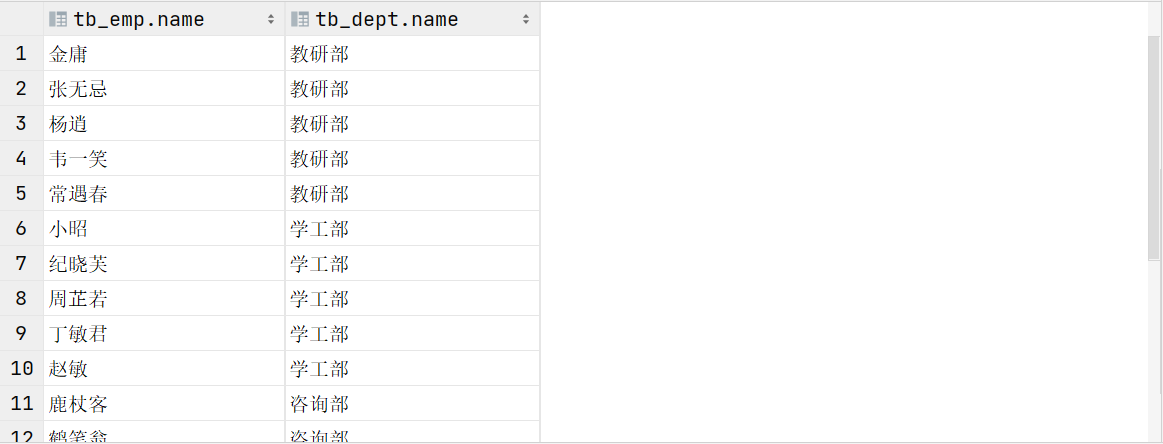
案例:查詢員工的姓名及所屬的部門名稱
- 隱式內連接實現
select tb_emp.name , tb_dept.name -- 分別查詢兩張表中的數據
from tb_emp , tb_dept -- 關聯兩張表
where tb_emp.dept_id = tb_dept.id; -- 消除笛卡爾積
- 顯式內連接實現
select tb_emp.name , tb_dept.name
from tb_emp inner join tb_dept
on tb_emp.dept_id = tb_dept.id;
多表查詢時給表起別名:
-
tableA as 別名1 , tableB as 別名2 ;
-
tableA 別名1 , tableB 別名2 ;

使用了別名的多表查詢:
select emp.name , dept.name
from tb_emp emp inner join tb_dept dept
on emp.dept_id = dept.id;
注意事項:
一旦為表起了別名,就不能再使用表名來指定對應的字段了,此時只能夠使用別名來指定字段。
1.3 外連接
外連接分為兩種:左外連接 和 右外連接。
左外連接語法結構:
select 字段列表 from 表1 left [ outer ] join 表2 on 連接條件 ... ;
左外連接相當于查詢表1(左表)的所有數據,當然也包含表1和表2交集部分的數據。
右外連接語法結構:
select 字段列表 from 表1 right [ outer ] join 表2 on 連接條件 ... ;
右外連接相當于查詢表2(右表)的所有數據,當然也包含表1和表2交集部分的數據。
案例:查詢員工表中所有員工的姓名, 和對應的部門名稱
-- 左外連接:以left join關鍵字左邊的表為主表,查詢主表中所有數據,以及和主表匹配的右邊表中的數據
select emp.name , dept.name
from tb_emp AS emp left join tb_dept AS dept on emp.dept_id = dept.id;
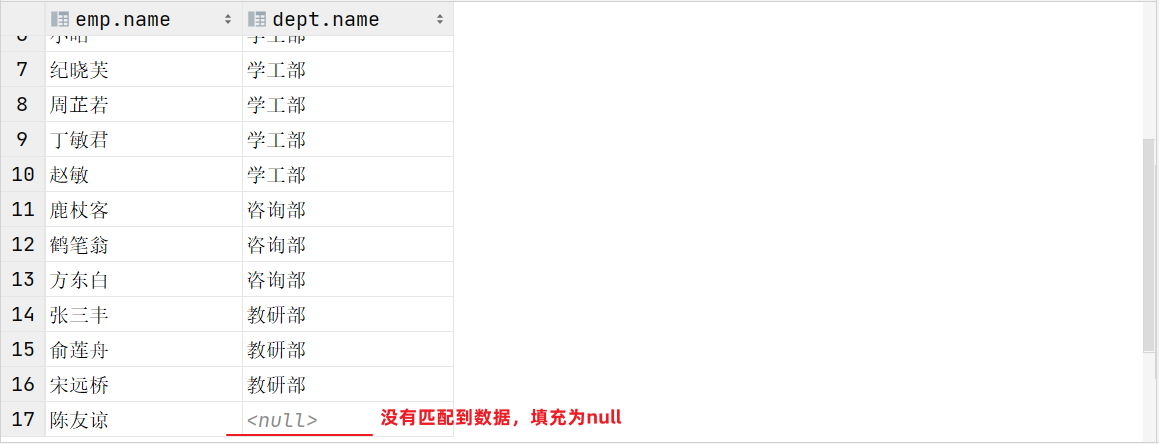
案例:查詢部門表中所有部門的名稱, 和對應的員工名稱
-- 右外連接
select dept.name , emp.name
from tb_emp AS emp right join tb_dept AS depton emp.dept_id = dept.id;

注意事項:
左外連接和右外連接是可以相互替換的,只需要調整連接查詢時SQL語句中表的先后順序就可以了。而我們在日常開發使用時,更偏向于左外連接。
1.4 子查詢
1.4.1 介紹
SQL語句中嵌套select語句,稱為嵌套查詢,又稱子查詢。
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 ... );
子查詢外部的語句可以是insert / update / delete / select 的任何一個,最常見的是 select。
根據子查詢結果的不同分為:
-
標量子查詢(子查詢結果為單個值[一行一列])
-
列子查詢(子查詢結果為一列,但可以是多行)
-
行子查詢(子查詢結果為一行,但可以是多列)
-
表子查詢(子查詢結果為多行多列[相當于子查詢結果是一張表])
子查詢可以書寫的位置:
- where之后
- from之后
- select之后
1.4.2 標量子查詢
子查詢返回的結果是單個值(數字、字符串、日期等),最簡單的形式,這種子查詢稱為標量子查詢。
常用的操作符: = <> > >= < <=
案例1:查詢"教研部"的所有員工信息
可以將需求分解為兩步:
- 查詢 “教研部” 部門ID
- 根據 “教研部” 部門ID,查詢員工信息
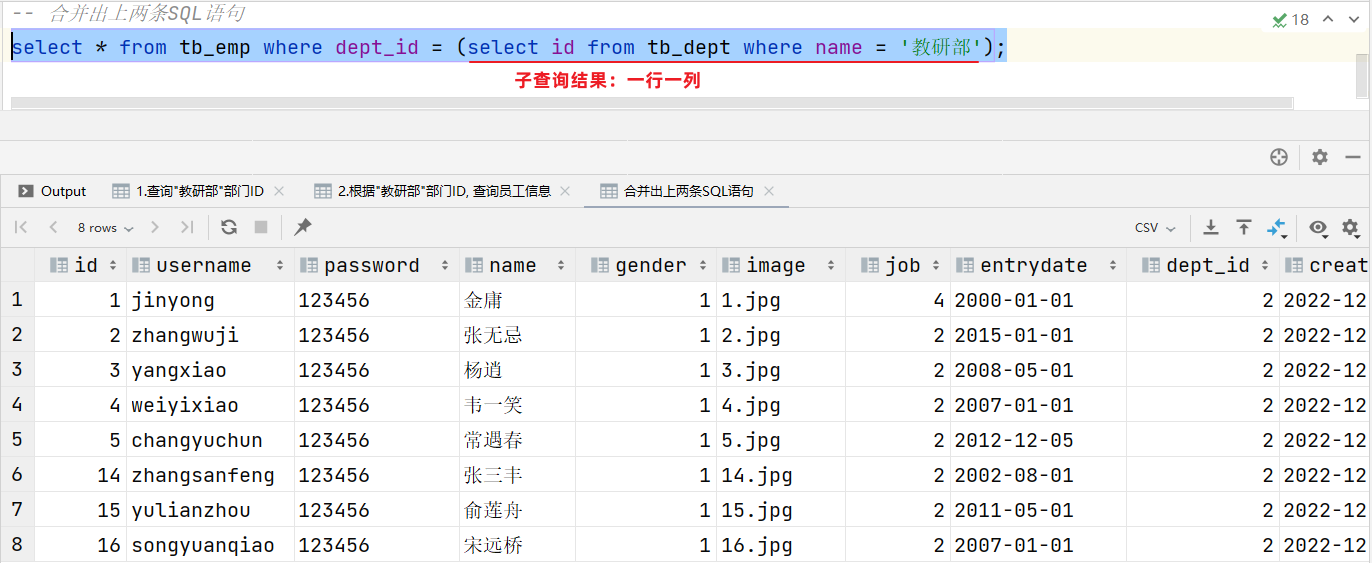
-- 1.查詢"教研部"部門ID
select id from tb_dept where name = '教研部'; #查詢結果:2
-- 2.根據"教研部"部門ID, 查詢員工信息
select * from tb_emp where dept_id = 2;-- 合并出上兩條SQL語句
select * from tb_emp where dept_id = (select id from tb_dept where name = '教研部');
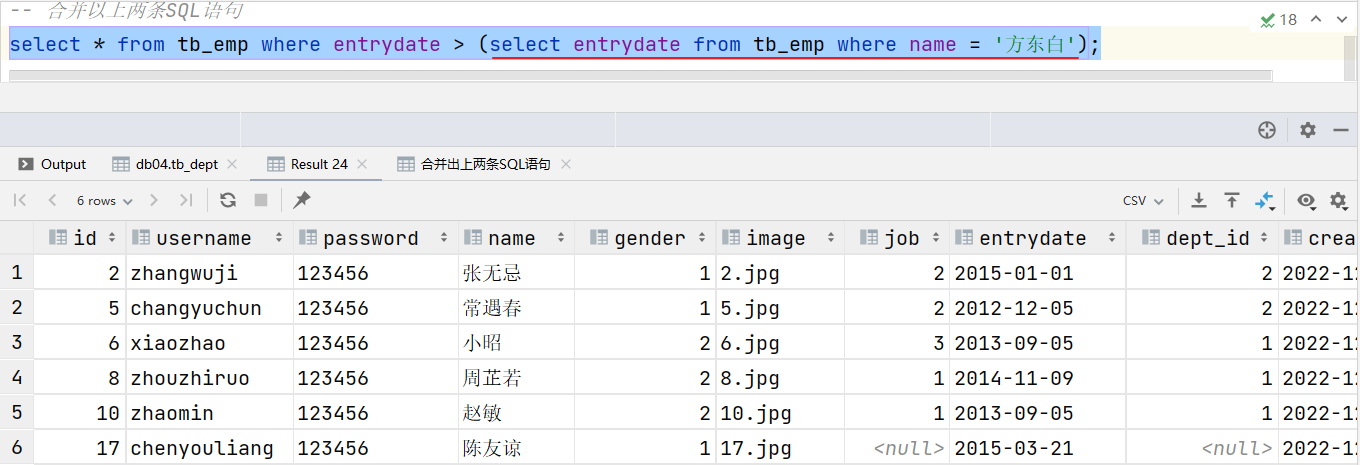
案例2:查詢在 “方東白” 入職之后的員工信息
可以將需求分解為兩步:
- 查詢 方東白 的入職日期
- 查詢 指定入職日期之后入職的員工信息
-- 1.查詢"方東白"的入職日期
select entrydate from tb_emp where name = '方東白'; #查詢結果:2012-11-01
-- 2.查詢指定入職日期之后入職的員工信息
select * from tb_emp where entrydate > '2012-11-01';-- 合并以上兩條SQL語句
select * from tb_emp where entrydate > (select entrydate from tb_emp where name = '方東白');
1.4.3 列子查詢
子查詢返回的結果是一列(可以是多行),這種子查詢稱為列子查詢。
常用的操作符:
| 操作符 | 描述 |
|---|---|
| IN | 在指定的集合范圍之內,多選一 |
| NOT IN | 不在指定的集合范圍之內 |
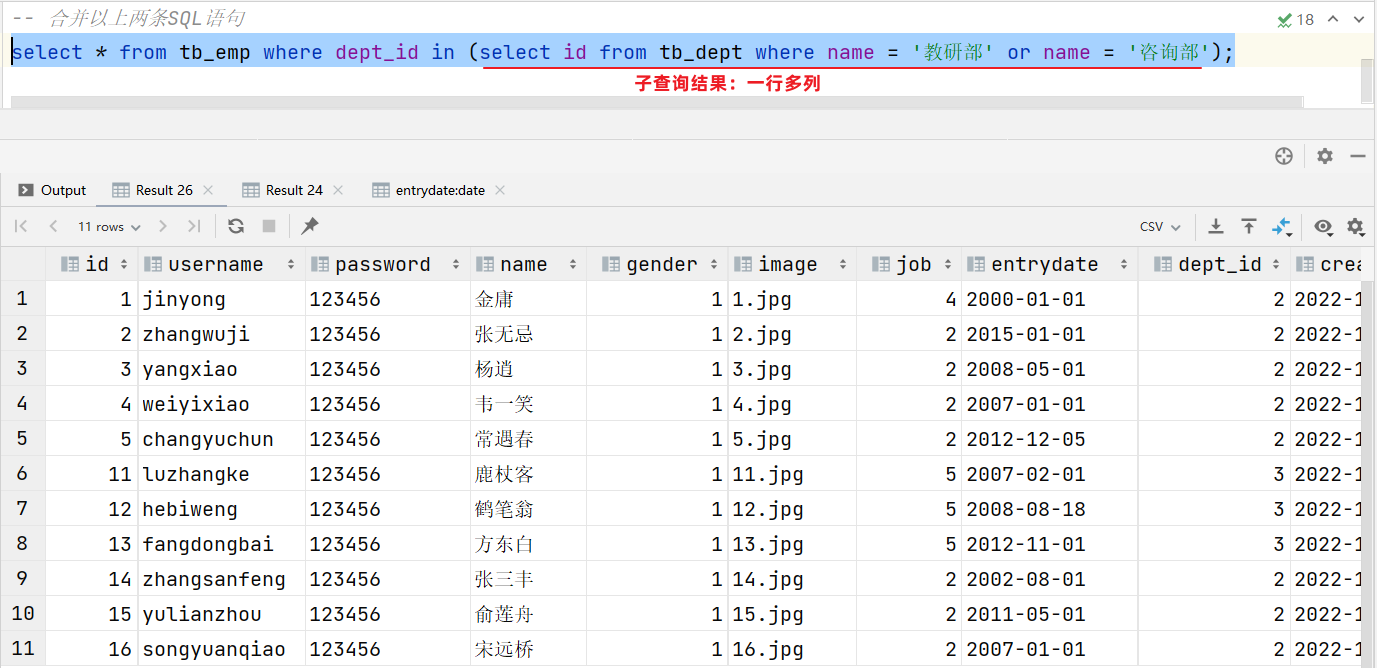
案例:查詢"教研部"和"咨詢部"的所有員工信息
分解為以下兩步:
- 查詢 “銷售部” 和 “市場部” 的部門ID
- 根據部門ID, 查詢員工信息
-- 1.查詢"銷售部"和"市場部"的部門ID
select id from tb_dept where name = '教研部' or name = '咨詢部'; #查詢結果:3,2
-- 2.根據部門ID, 查詢員工信息
select * from tb_emp where dept_id in (3,2);-- 合并以上兩條SQL語句
select * from tb_emp where dept_id in (select id from tb_dept where name = '教研部' or name = '咨詢部');
1.4.4 行子查詢
子查詢返回的結果是一行(可以是多列),這種子查詢稱為行子查詢。
常用的操作符:= 、<> 、IN 、NOT IN
案例:查詢與"韋一笑"的入職日期及職位都相同的員工信息
可以拆解為兩步進行:
- 查詢 “韋一笑” 的入職日期 及 職位
- 查詢與"韋一笑"的入職日期及職位相同的員工信息
-- 查詢"韋一笑"的入職日期 及 職位
select entrydate , job from tb_emp where name = '韋一笑'; #查詢結果: 2007-01-01 , 2
-- 查詢與"韋一笑"的入職日期及職位相同的員工信息
select * from tb_emp where (entrydate,job) = ('2007-01-01',2);-- 合并以上兩條SQL語句
select * from tb_emp where (entrydate,job) = (select entrydate , job from tb_emp where name = '韋一笑');

1.4.5 表子查詢
子查詢返回的結果是多行多列,常作為臨時表,這種子查詢稱為表子查詢。
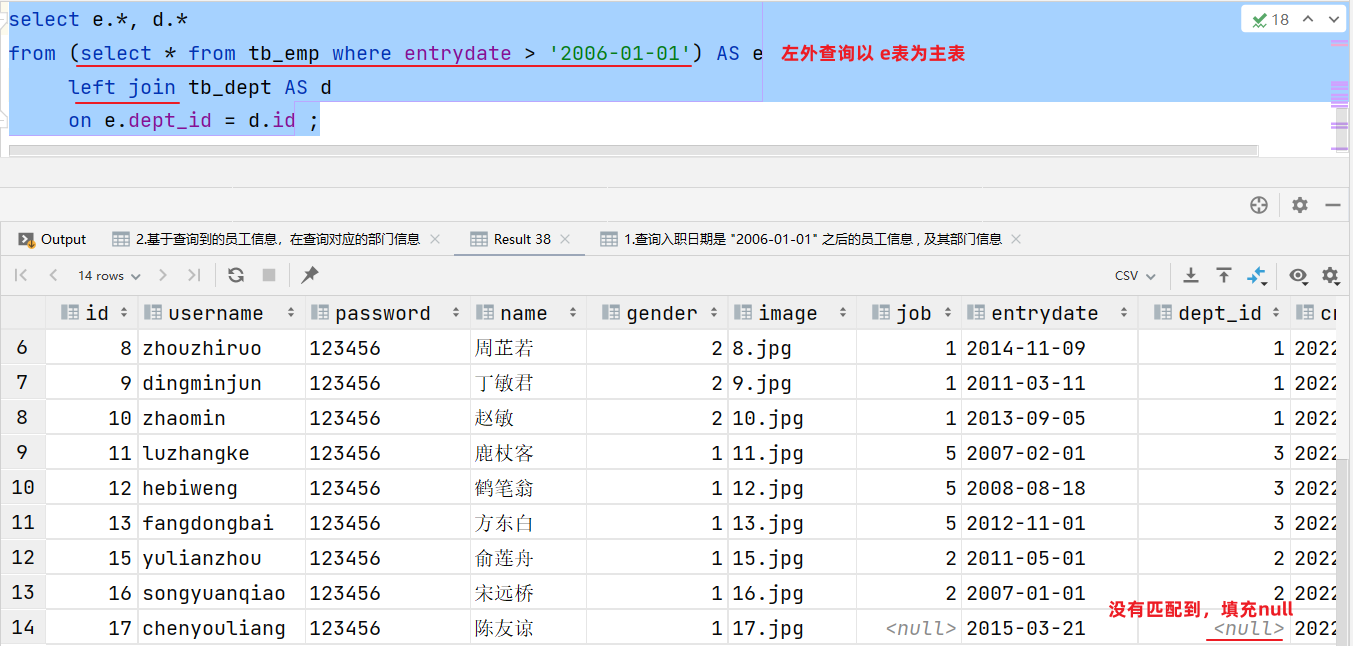
案例:查詢入職日期是 “2006-01-01” 之后的員工信息 , 及其部門信息
分解為兩步執行:
- 查詢入職日期是 “2006-01-01” 之后的員工信息
- 基于查詢到的員工信息,在查詢對應的部門信息
select * from emp where entrydate > '2006-01-01';select e.*, d.* from (select * from emp where entrydate > '2006-01-01') e left join dept d on e.dept_id = d.id ;
1.5 案例
基于之前設計的多表案例的表結構,我們來完成今天的多表查詢案例需求。
準備環境
將資料中準備好的多表查詢的數據準備的SQL腳本導入數據庫中。
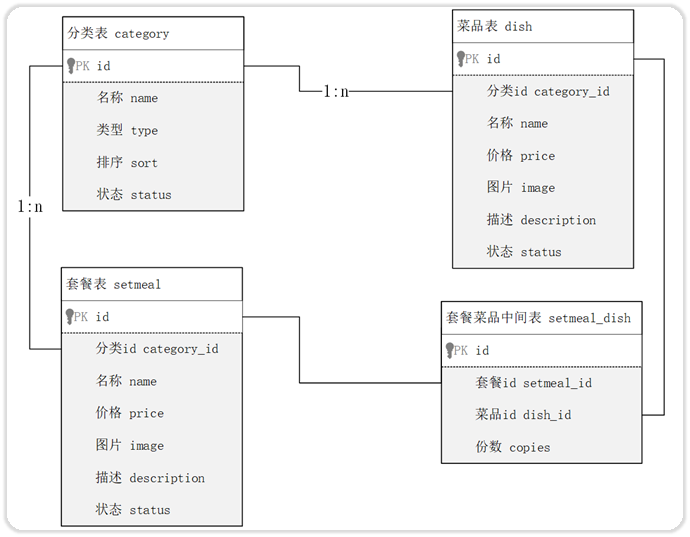
- 分類表:category
- 菜品表:dish
- 套餐表:setmeal
- 套餐菜品關系表:setmeal_dish
需求實現
- 查詢價格低于 10元 的菜品的名稱 、價格 及其 菜品的分類名稱
/*查詢技巧:明確1:查詢需要用到哪些字段菜品名稱、菜品價格 、 菜品分類名明確2:查詢的字段分別歸屬于哪張表菜品表:[菜品名稱、菜品價格]分類表:[分類名]明確3:如查多表,建立表與表之間的關聯菜品表.caategory_id = 分類表.id其他:(其他條件、其他要求)價格 < 10
*/
select d.name , d.price , c.name
from dish AS d , category AS c
where d.category_id = c.idand d.price < 10;

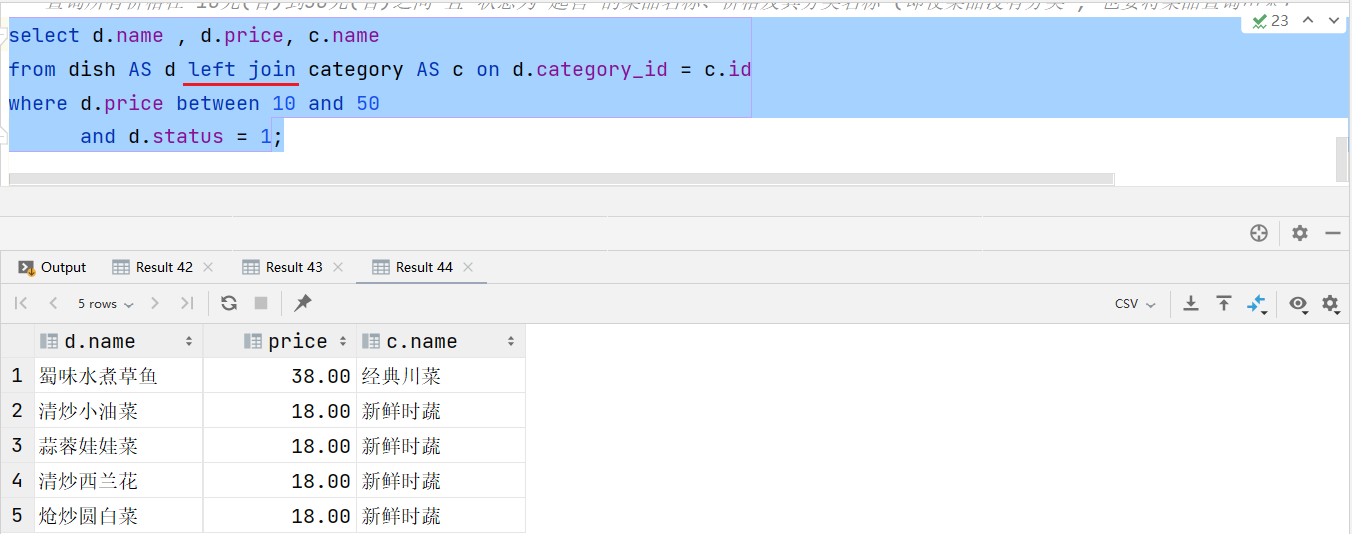
- 查詢所有價格在 10元(含)到50元(含)之間 且 狀態為"起售"的菜品名稱、價格及其分類名稱 (即使菜品沒有分類 , 也要將菜品查詢出來)
select d.name , d.price, c.name
from dish AS d left join category AS c on d.category_id = c.id
where d.price between 10 and 50and d.status = 1;
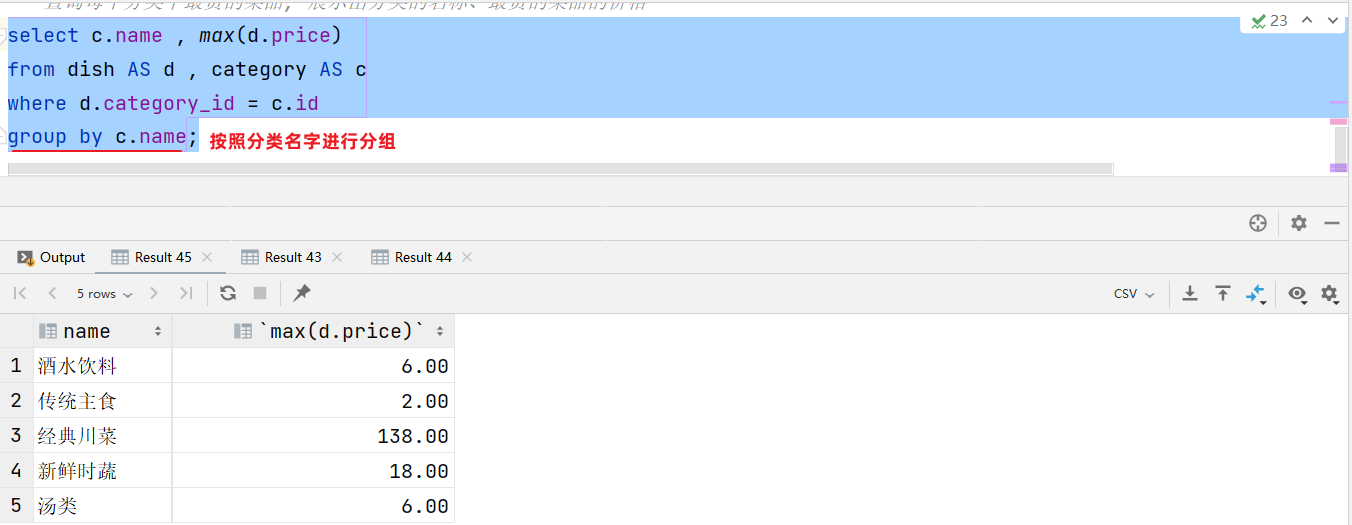
- 查詢每個分類下最貴的菜品, 展示出分類的名稱、最貴的菜品的價格
select c.name , max(d.price)
from dish AS d , category AS c
where d.category_id = c.id
group by c.name;
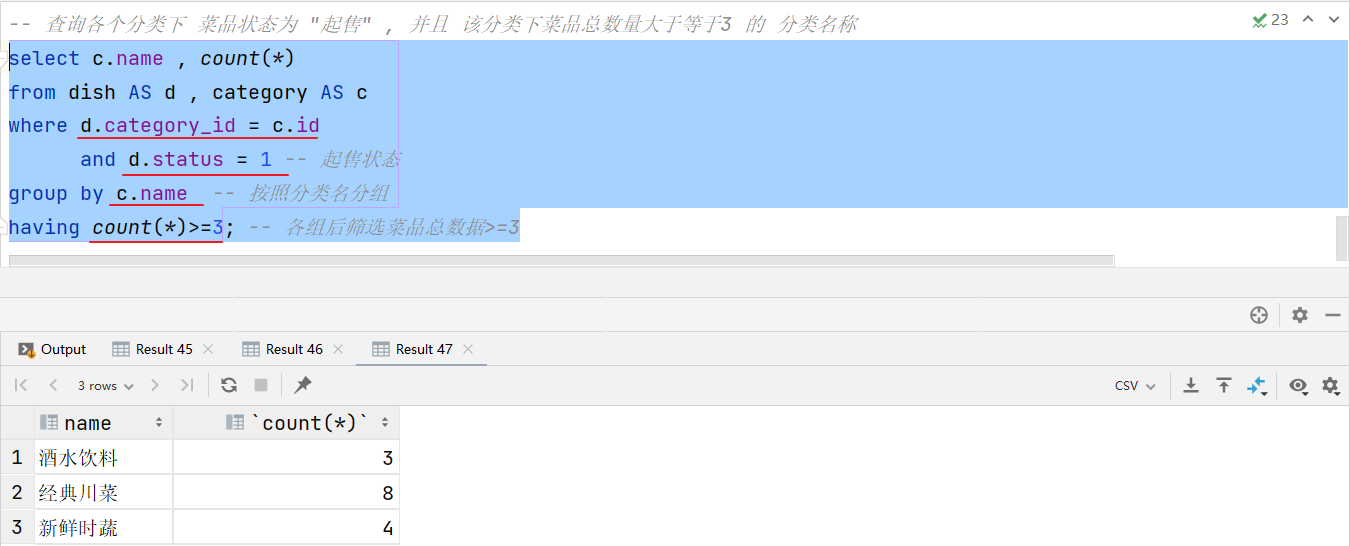
- 查詢各個分類下 菜品狀態為 “起售” , 并且 該分類下菜品總數量大于等于3 的 分類名稱
/*查詢技巧:明確1:查詢需要用到哪些字段分類名稱、菜品總數量明確2:查詢用到的字段分別歸屬于哪張表分類表:[分類名]菜品表:[菜品狀態]明確3:如查多表,建立表與表之間的關聯菜品表.caategory_id = 分類表.id其他:(其他條件、其他要求)條件:菜品狀態 = 1 (1表示起售)分組:分類名分組后條件: 總數量 >= 3
*/
select c.name , count(*)
from dish AS d , category AS c
where d.category_id = c.idand d.status = 1 -- 起售狀態
group by c.name -- 按照分類名分組
having count(*)>=3; -- 各組后篩選菜品總數據>=3
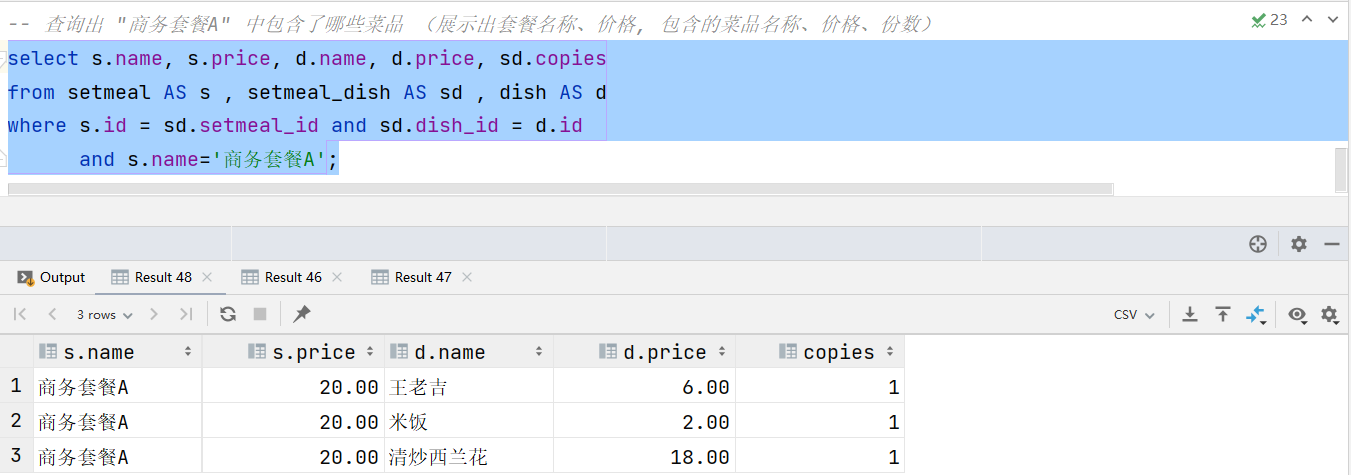
- 查詢出 “商務套餐A” 中包含了哪些菜品 (展示出套餐名稱、價格, 包含的菜品名稱、價格、份數)
select s.name, s.price, d.name, d.price, sd.copies
from setmeal AS s , setmeal_dish AS sd , dish AS d
where s.id = sd.setmeal_id and sd.dish_id = d.idand s.name='商務套餐A';
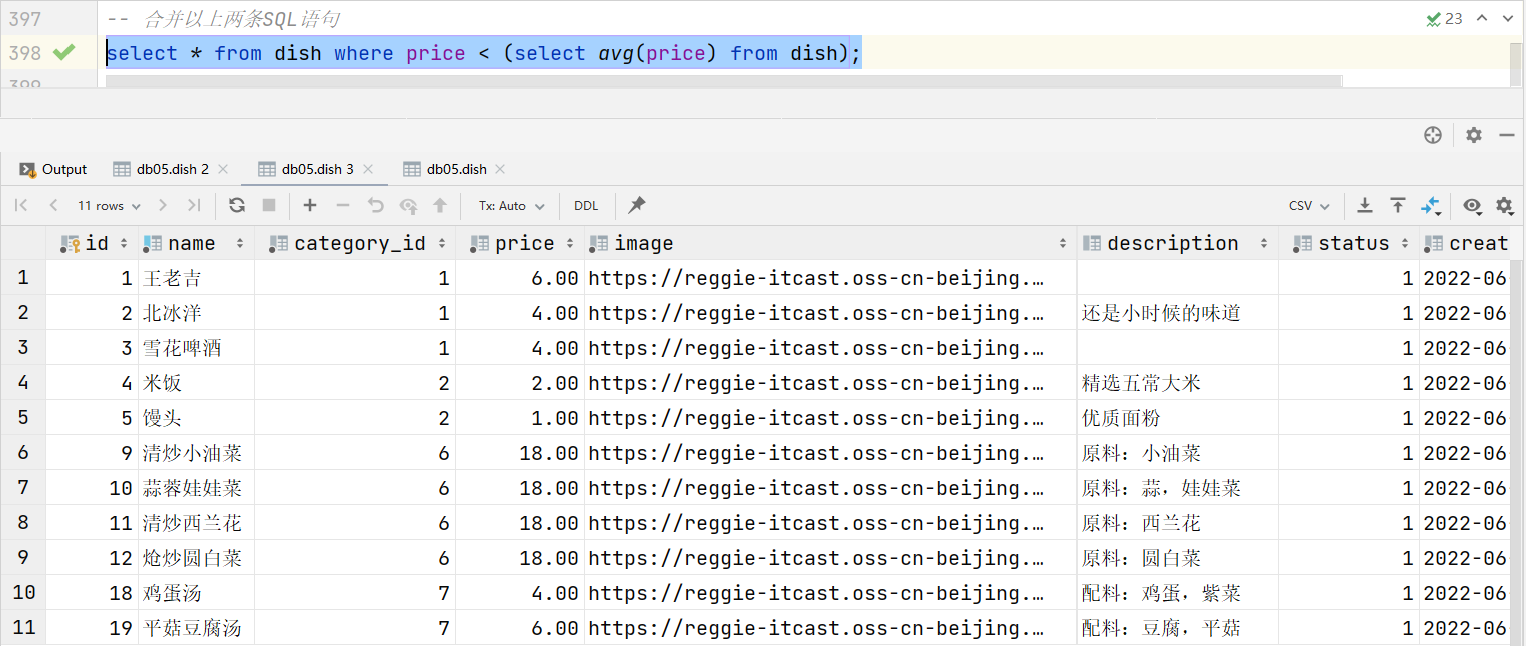
- 查詢出低于菜品平均價格的菜品信息 (展示出菜品名稱、菜品價格)
-- 1.計算菜品平均價格
select avg(price) from dish; -- 查詢結果:37.736842
-- 2.查詢出低于菜品平均價格的菜品信息
select * from dish where price < 37.736842;-- 合并以上兩條SQL語句
select * from dish where price < (select avg(price) from dish);
2. 事務
場景:學工部整個部門解散了,該部門及部門下的員工都需要刪除了。
-
操作:
-- 刪除學工部 delete from dept where id = 1; -- 刪除成功-- 刪除學工部的員工 delete from emp where dept_id = 1; -- 刪除失敗(操作過程中出現錯誤:造成刪除沒有成功) -
問題:如果刪除部門成功了,而刪除該部門的員工時失敗了,此時就造成了數據的不一致。
? 要解決上述的問題,就需要通過數據庫中的事務來解決。
2.1 介紹
在實際的業務開發中,有些業務操作要多次訪問數據庫。一個業務要發送多條SQL語句給數據庫執行。需要將多次訪問數據庫的操作視為一個整體來執行,要么所有的SQL語句全部執行成功。如果其中有一條SQL語句失敗,就進行事務的回滾,所有的SQL語句全部執行失敗。
簡而言之:事務是一組操作的集合,它是一個不可分割的工作單位。事務會把所有的操作作為一個整體一起向系統提交或撤銷操作請求,即這些操作要么同時成功,要么同時失敗。
事務作用:保證在一個事務中多次操作數據庫表中數據時,要么全都成功,要么全都失敗。
2.2 操作
MYSQL中有兩種方式進行事務的操作:
- 自動提交事務:即執行一條sql語句提交一次事務。(默認MySQL的事務是自動提交)
- 手動提交事務:先開啟,再提交
事務操作有關的SQL語句:
| SQL語句 | 描述 |
|---|---|
| start transaction; / begin ; | 開啟手動控制事務 |
| commit; | 提交事務 |
| rollback; | 回滾事務 |
手動提交事務使用步驟:
- 第1種情況:開啟事務 => 執行SQL語句 => 成功 => 提交事務
- 第2種情況:開啟事務 => 執行SQL語句 => 失敗 => 回滾事務
使用事務控制刪除部門和刪除該部門下的員工的操作:
-- 開啟事務
start transaction ;-- 刪除學工部
delete from tb_dept where id = 1;-- 刪除學工部的員工
delete from tb_emp where dept_id = 1;
- 上述的這組SQL語句,如果如果執行成功,則提交事務
-- 提交事務 (成功時執行)
commit ;
- 上述的這組SQL語句,如果如果執行失敗,則回滾事務
-- 回滾事務 (出錯時執行)
rollback ;
2.3 四大特性
面試題:事務有哪些特性?
- 原子性(Atomicity):事務是不可分割的最小單元,要么全部成功,要么全部失敗。
- 一致性(Consistency):事務完成時,必須使所有的數據都保持一致狀態。
- 隔離性(Isolation):數據庫系統提供的隔離機制,保證事務在不受外部并發操作影響的獨立環境下運行。
- 持久性(Durability):事務一旦提交或回滾,它對數據庫中的數據的改變就是永久的。
事務的四大特性簡稱為:ACID
-
原子性(Atomicity) :原子性是指事務包裝的一組sql是一個不可分割的工作單元,事務中的操作要么全部成功,要么全部失敗。
-
一致性(Consistency):一個事務完成之后數據都必須處于一致性狀態。
? 如果事務成功的完成,那么數據庫的所有變化將生效。
? 如果事務執行出現錯誤,那么數據庫的所有變化將會被回滾(撤銷),返回到原始狀態。
- 隔離性(Isolation):多個用戶并發的訪問數據庫時,一個用戶的事務不能被其他用戶的事務干擾,多個并發的事務之間要相互隔離。
? 一個事務的成功或者失敗對于其他的事務是沒有影響。
- 持久性(Durability):一個事務一旦被提交或回滾,它對數據庫的改變將是永久性的,哪怕數據庫發生異常,重啟之后數據亦然存在。
3. 索引
3.1 介紹
索引(index):是幫助數據庫高效獲取數據的數據結構 。
- 簡單來講,就是使用索引可以提高查詢的效率。
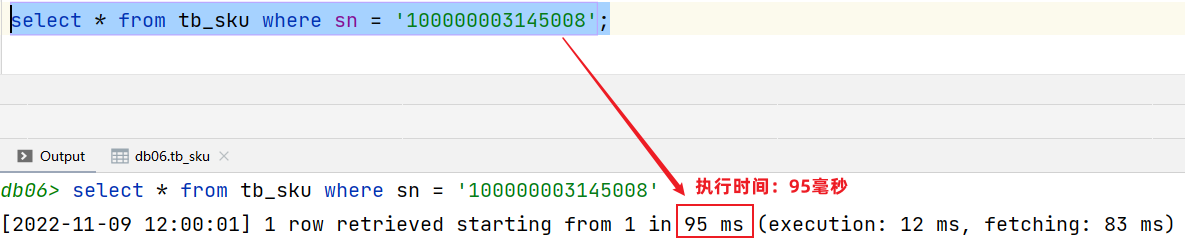
測試沒有使用索引的查詢:

添加索引后查詢:
-- 添加索引
create index idx_sku_sn on tb_sku (sn); #在添加索引時,也需要消耗時間-- 查詢數據(使用了索引)
select * from tb_sku where sn = '100000003145008';
優點:
- 提高數據查詢的效率,降低數據庫的IO成本。
- 通過索引列對數據進行排序,降低數據排序的成本,降低CPU消耗。
缺點:
- 索引會占用存儲空間。
- 索引大大提高了查詢效率,同時卻也降低了insert、update、delete的效率。
3.2 結構
MySQL數據庫支持的索引結構有很多,如:Hash索引、B+Tree索引、Full-Text索引等。
我們平常所說的索引,如果沒有特別指明,都是指默認的 B+Tree 結構組織的索引。
在沒有了解B+Tree結構前,我們先回顧下之前所學習的樹結構:
二叉查找樹:左邊的子節點比父節點小,右邊的子節點比父節點大
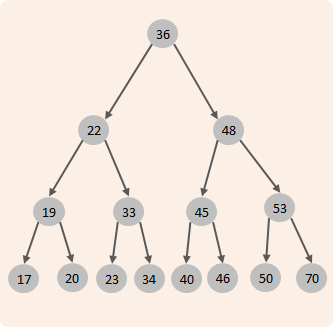
當我們向二叉查找樹保存數據時,是按照從大到小(或從小到大)的順序保存的,此時就會形成一個單向鏈表,搜索性能會打折扣。

可以選擇平衡二叉樹或者是紅黑樹來解決上述問題。(紅黑樹也是一棵平衡的二叉樹)

但是在Mysql數據庫中并沒有使用二叉搜索數或二叉平衡數或紅黑樹來作為索引的結構。
思考:采用二叉搜索樹或者是紅黑樹來作為索引的結構有什么問題?
答案 最大的問題就是在數據量大的情況下,樹的層級比較深,會影響檢索速度。因為不管是二叉搜索數還是紅黑數,一個節點下面只能有兩個子節點。此時在數據量大的情況下,就會造成數的高度比較高,樹的高度一旦高了,檢索速度就會降低。說明:如果數據結構是紅黑樹,那么查詢1000萬條數據,根據計算樹的高度大概是23左右,這樣確實比之前的方式快了很多,但是如果高并發訪問,那么一個用戶有可能需要23次磁盤IO,那么100萬用戶,那么會造成效率極其低下。所以為了減少紅黑樹的高度,那么就得增加樹的寬度,就是不再像紅黑樹一樣每個節點只能保存一個數據,可以引入另外一種數據結構,一個節點可以保存多個數據,這樣寬度就會增加從而降低樹的高度。這種數據結構例如BTree就滿足。
下面我們來看看B+Tree(多路平衡搜索樹)結構中如何避免這個問題:
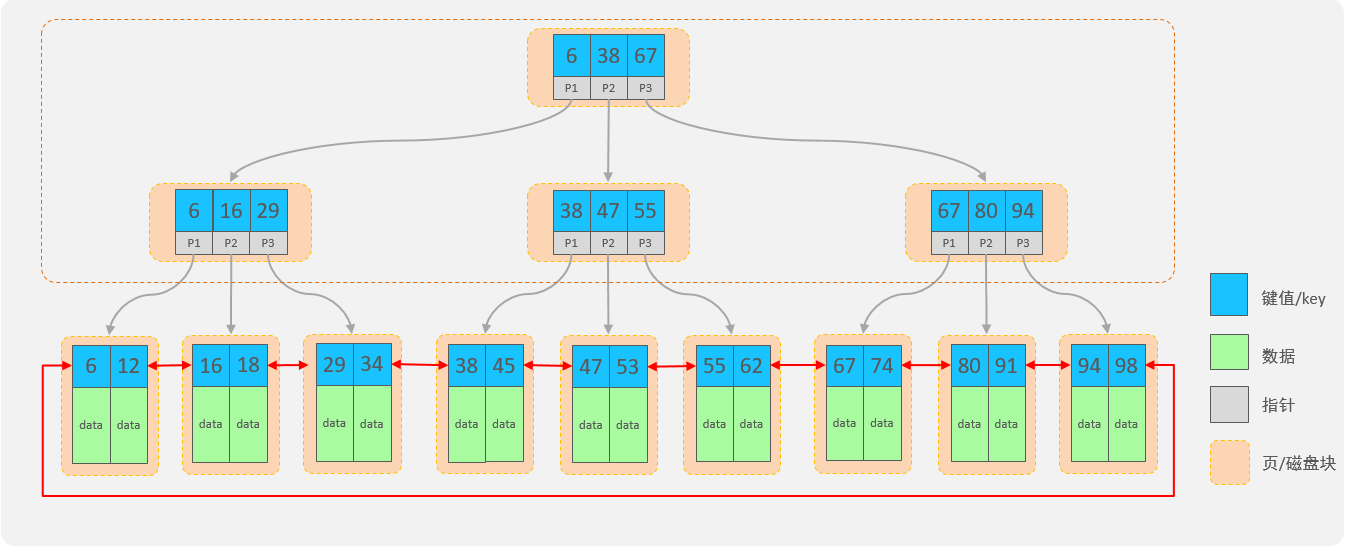
B+Tree結構:
- 每一個節點,可以存儲多個key(有n個key,就有n個指針)
- 節點分為:葉子節點、非葉子節點
- 葉子節點,就是最后一層子節點,所有的數據都存儲在葉子節點上
- 非葉子節點,不是樹結構最下面的節點,用于索引數據,存儲的的是:key+指針
- 為了提高范圍查詢效率,葉子節點形成了一個雙向鏈表,便于數據的排序及區間范圍查詢
拓展:
非葉子節點都是由key+指針域組成的,一個key占8字節,一個指針占6字節,而一個節點總共容量是16KB,那么可以計算出一個節點可以存儲的元素個數:16*1024字節 / (8+6)=1170個元素。
- 查看mysql索引節點大小:show global status like ‘innodb_page_size’; – 節點大小:16384
當根節點中可以存儲1170個元素,那么根據每個元素的地址值又會找到下面的子節點,每個子節點也會存儲1170個元素,那么第二層即第二次IO的時候就會找到數據大概是:1170*1170=135W。也就是說B+Tree數據結構中只需要經歷兩次磁盤IO就可以找到135W條數據。
對于第二層每個元素有指針,那么會找到第三層,第三層由key+數據組成,假設key+數據總大小是1KB,而每個節點一共能存儲16KB,所以一個第三層一個節點大概可以存儲16個元素(即16條記錄)。那么結合第二層每個元素通過指針域找到第三層的節點,第二層一共是135W個元素,那么第三層總元素大小就是:135W*16結果就是2000W+的元素個數。
結合上述分析B+Tree有如下優點:
- 千萬條數據,B+Tree可以控制在小于等于3的高度
- 所有的數據都存儲在葉子節點上,并且底層已經實現了按照索引進行排序,還可以支持范圍查詢,葉子節點是一個雙向鏈表,支持從小到大或者從大到小查找
3.3 語法
創建索引
create [ unique ] index 索引名 on 表名 (字段名,... ) ;
案例:為tb_emp表的name字段建立一個索引
create index idx_emp_name on tb_emp(name);
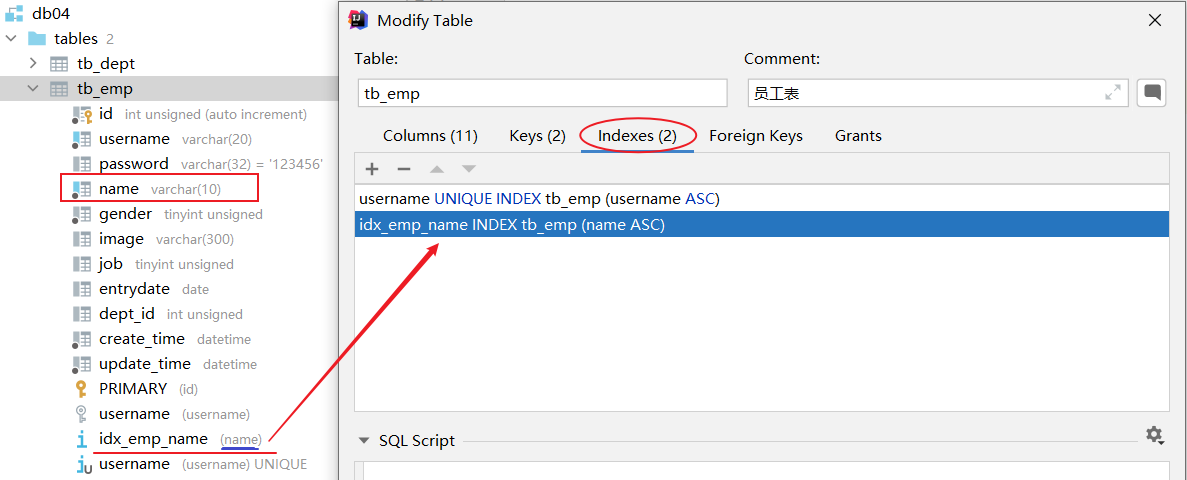
在創建表時,如果添加了主鍵和唯一約束,就會默認創建:主鍵索引、唯一約束

查看索引
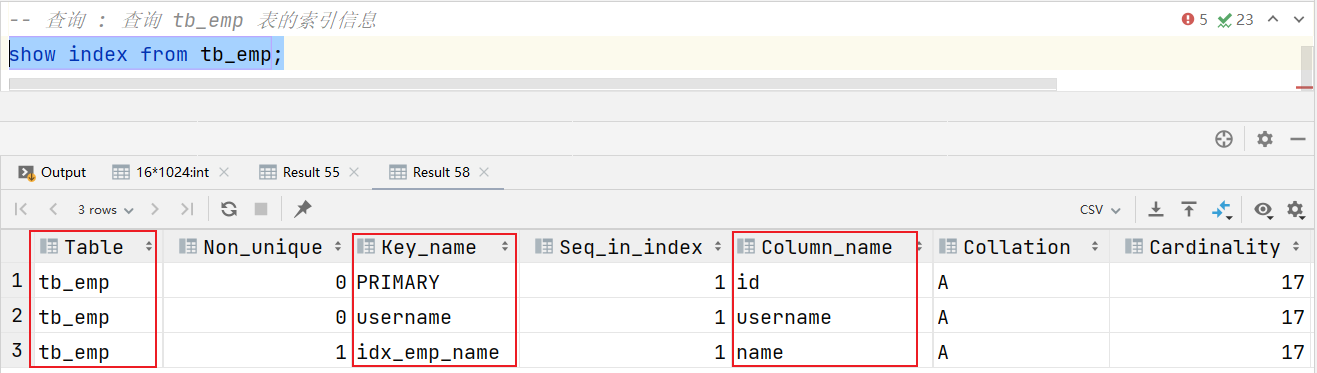
show index from 表名;
案例:查詢 tb_emp 表的索引信息
show index from tb_emp;
刪除索引
drop index 索引名 on 表名;
案例:刪除 tb_emp 表中name字段的索引
drop index idx_emp_name on tb_emp;
注意事項:
主鍵字段,在建表時,會自動創建主鍵索引
添加唯一約束時,數據庫實際上會添加唯一索引




- rigid, fixed anchor, flexible dock)






實現Language C)







)