Javaweb
- 數據庫相關概念
- MySQL數據庫
- MySQL數據模型
- SQL
- DDL--操作數據庫
- 圖形化客戶端工具
- DML--操作數據
- DQL
- 數據庫
- 約束
- 數據庫設計
- 多表查詢
- 事務
數據庫相關概念
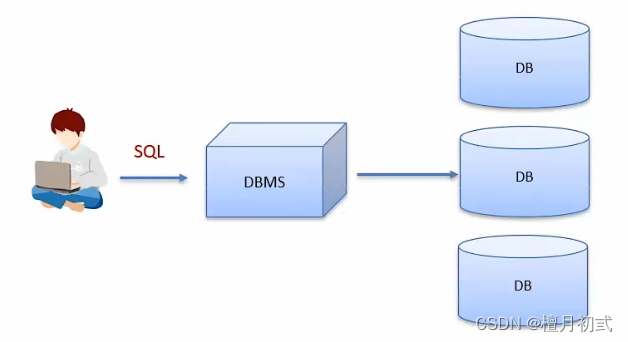
數據庫
存儲數據的倉庫,數據是有組織的進行存儲
英文:DataBase,簡稱DB
數據庫管理系統
管理數據庫的大型軟件
英文:DataBaseManagementSystem,簡稱DBMS
SQL
英文:StructuredQueryLanguage,簡稱SQL,結構化查詢語言
操作關系型數據庫的編程語言
定義操作所有關系型數據庫的統一標準
MySQL數據庫
下載
點開下面的鏈接:
https://downloads.mysql.com/archives/community/

配置環境變量
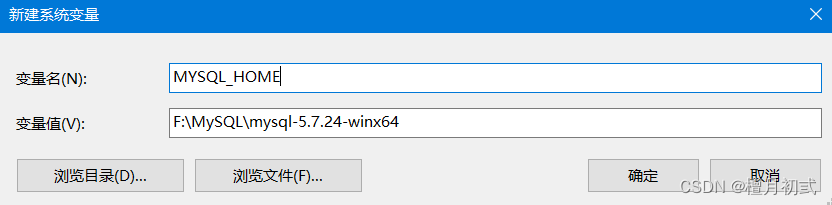
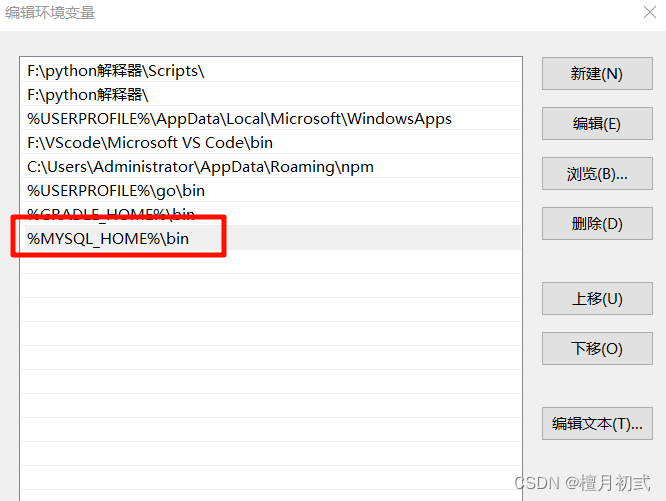
新建配置文件
新建一個文本文件,內容如下:
[mysql]
default-character-set=utf8[mysqld]
character-set-server=utf8
default-storage-engine=innodb
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION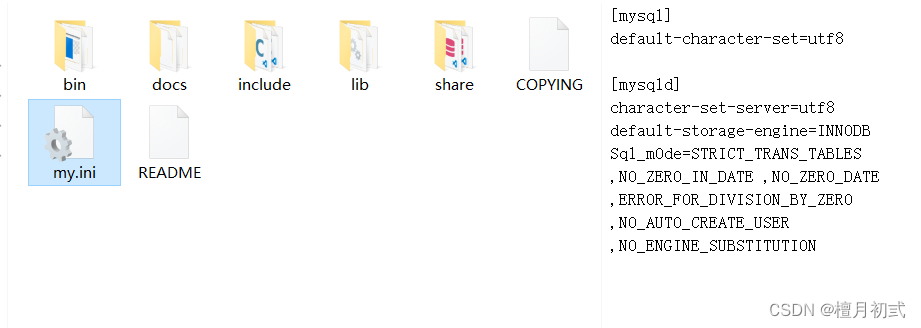
初始化MySQL
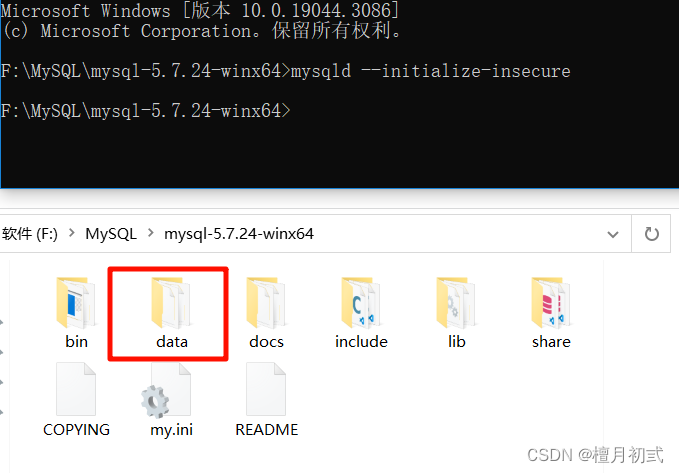
在文件夾cmd中輸入以下命令,出現data文件證明成功
mysqld --initialize-insecure
tips:如果出現如下錯誤

是由于權限不足導致的,去c:\windows\System32下以管理員方式運行cmd.exe
注冊MySQL服務
在黑框里敲入mysqld -install,回車。

現在你的計算機上已經安裝好了MySQL服務了。
啟動MySQL服務
在黑框里敲入net start mysql,回車。
net start mysql //啟動mysql服務
net stop mysql //停止mysql服務
修改默認賬戶密碼
在黑框里敲入mysqladmin -u root password 1234,這里的1234就是指默認管理員(即root賬戶)的密碼,可以自行修改成你喜歡的。

mysqladmin -u root password 1234
登錄MySQL
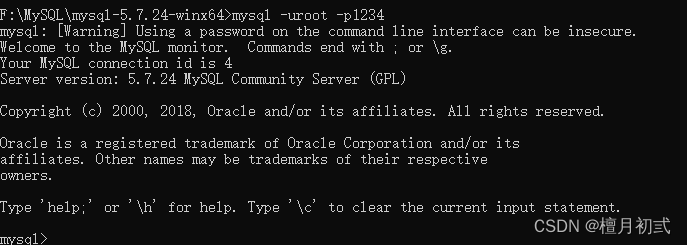
在黑框中輸入,mysql-uroot-p1234,回車,出現下圖且左下角為mysq1>,則登錄成功。
mysql -uroot -p1234
登錄參數:
mysq1-u用戶名-p密碼-h要連接的mysq1服務器的ip地址(默認127.0.0.1)-P端口號(默認3306)
退出mysql
exit
quit
MySQL數據模型
關系型數據庫
關系型數據庫是建立在關系模型基礎上的數據庫,簡單說,關系型數據庫是由多張能互相連接的二維表組成的數據庫
優點
1.都是使用表結構,格式一致,易于維護。
2使用通用的SQL語言操作,使用方便,可用于復雜查詢。
3.數據存儲在磁盤中,安全。

SQL
SQL簡介
英文:StructuredQueryLanguage,簡稱SQL
結構化查詢語言,一門操作關系型數據庫的編程語言
定義操作所有關系型數據庫的統一標準
對于同一個需求,每一種數據庫操作的方式可能會存在一些不一樣的地方,我們稱為“方言"
SQL通用語法
1.SQL語句可以單行或多行書寫,以分號結尾。
2.MySQL數據庫的SQL語句不區分大小寫,關鍵字建議使用大寫。
3.注釋

SQL分類
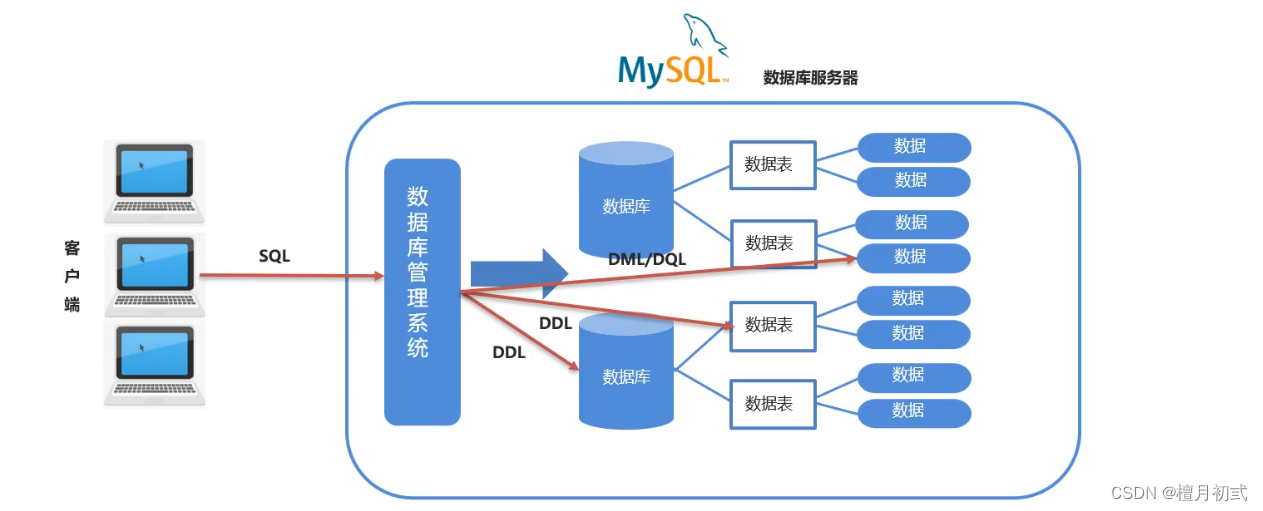
DDL:操作數據庫,表等
DML:對表中的數據進行增刪改
DQL:對表中的數據進行查詢
DCL:對數據庫進行權限控制
DDL–操作數據庫
1.查詢
SHOW DATABASES;
2.創建
創建數據庫
CREATE DATABASE 數據庫名稱;
創建數據庫(判斷,如果不存在則創建)
CREATE DATABASE IF NOT EXISTS 數據庫名稱;
3.刪除
刪除數據庫
DROP DATABASE 數據庫名稱;
刪除數據庫(判斷,如果存在則刪除)
DROP DATABASE IF EXISTS 數據庫名稱;
4.使用數據庫
查看當前使用的數據庫
SELECT DATABASE();
使用數據庫
USE 數據庫名稱;
DDL–操作表
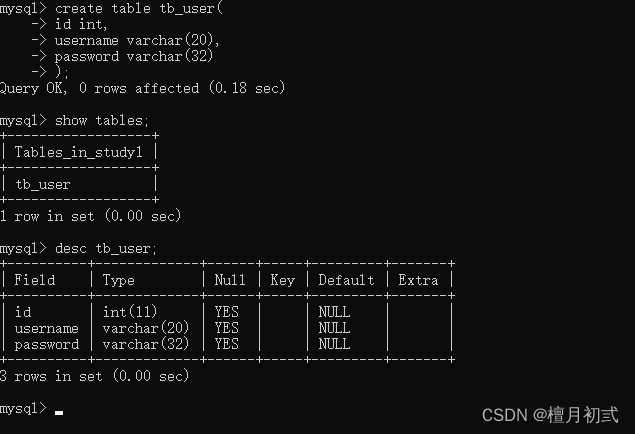
1.查詢表
查詢當前數據庫下所有表名稱
SHOW TABLES;
查詢表結構
DESC 表名稱;
2.創建表

create table 表名(-> 字段名1 數據類型1,-> 字段名2 數據類型2,-> ...-> 字段名n 數據類型n);
注意:最后一行末尾,不能加逗號
數據類型
MySQL支持多種類型,可以分為三類:
- 數值
- 日期
- 字符串
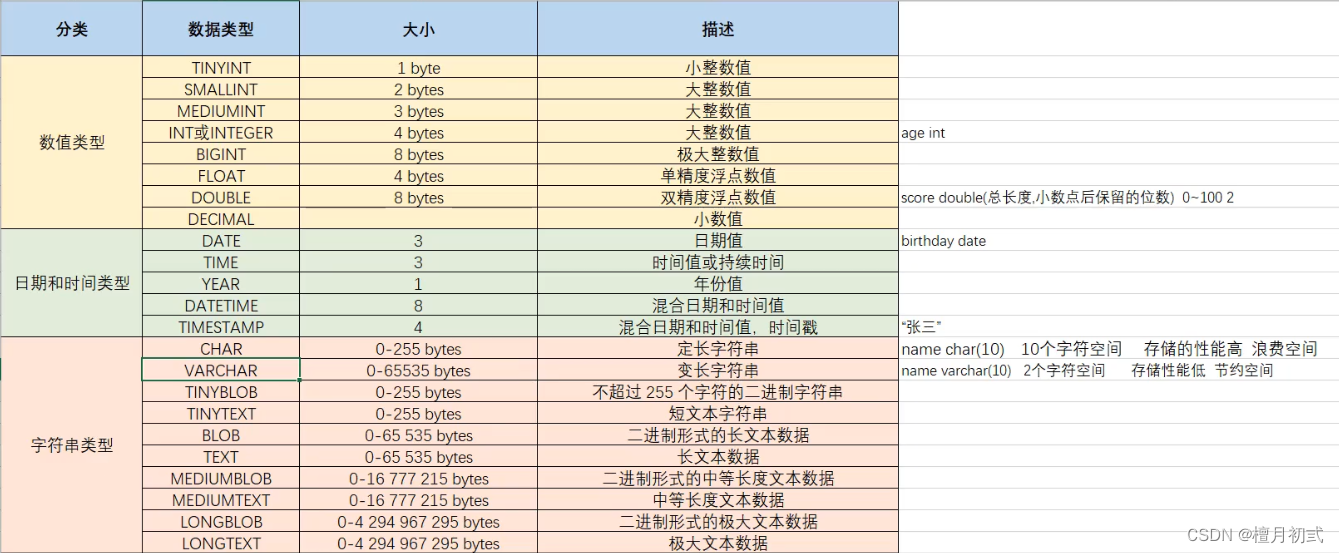
創建案例

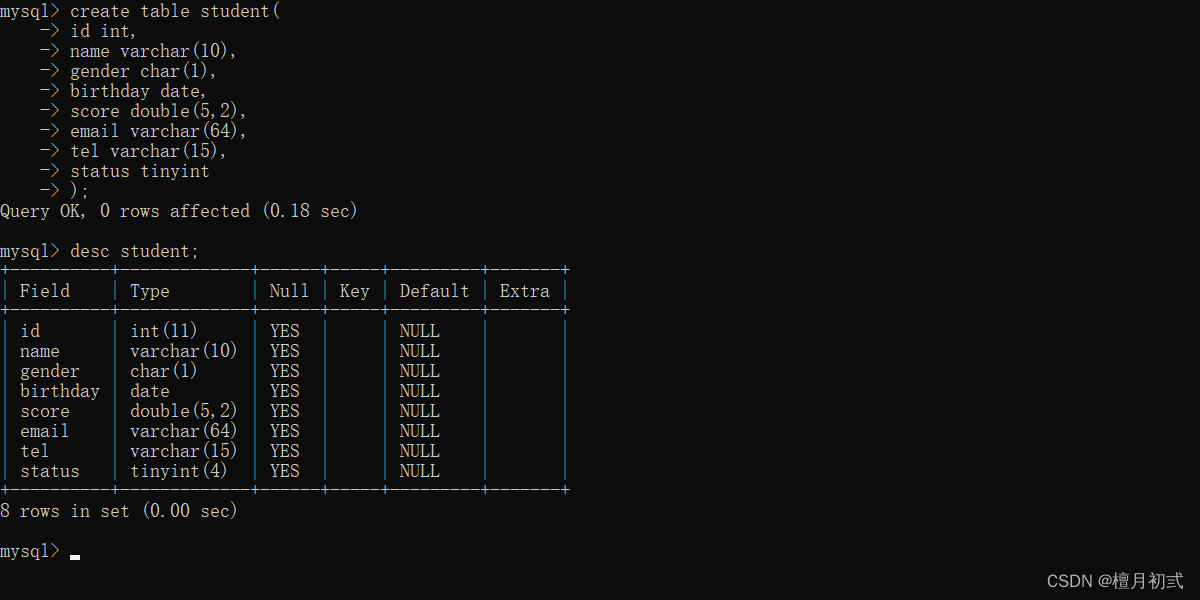
刪除表
1.刪除表
DROP TABLE 表名;
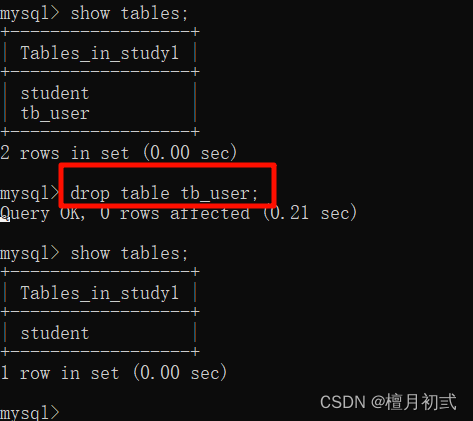
2.刪除表時判斷表是否存在
DROP TABLE IF EXISTS 表名;

修改表
1.修改表名
ALTER TABLE 表名 RENAME TO 新的表名;
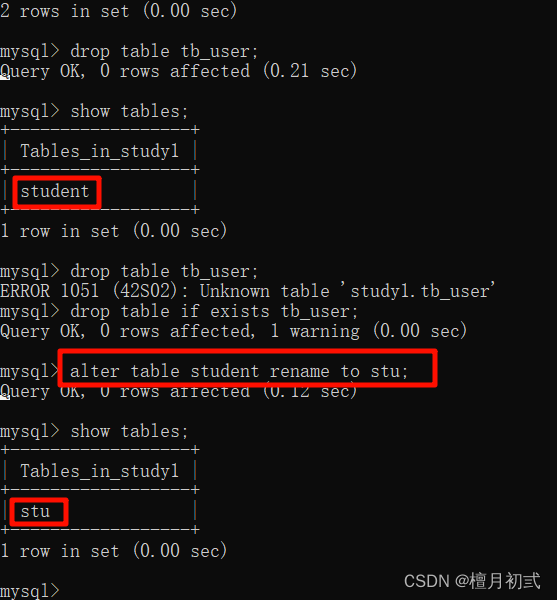
2.添加一列
ALTER TABLE 表名 ADD 列名 數據類型;
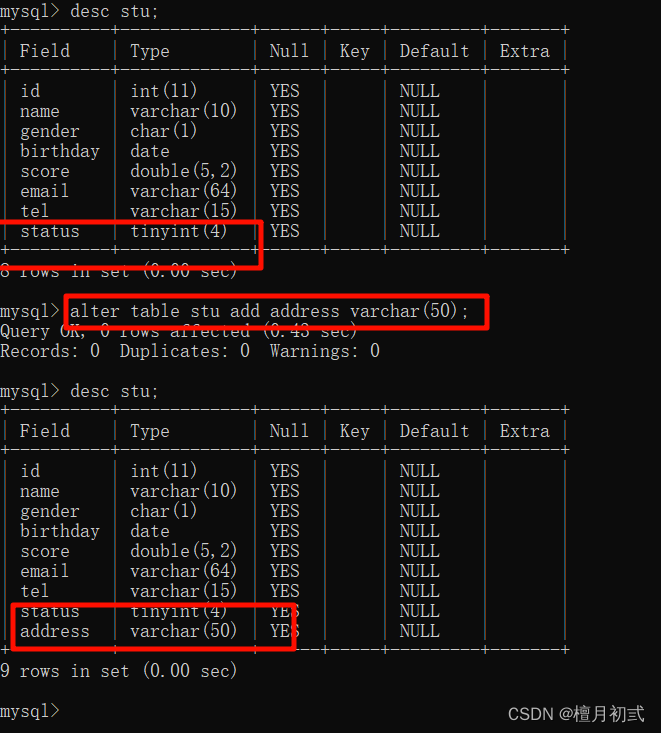
3.修改數據類型
ALTER TABLE 表名 MODIFY 列名 新數據類型;
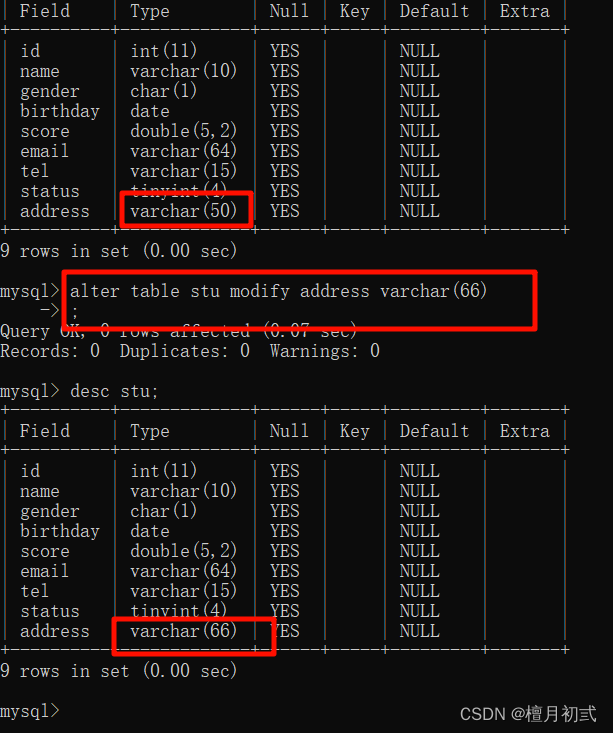
4.修改列名和數據類型
ALTER TABLE 表名 CHANGE 列名 新列名 新數據類型;

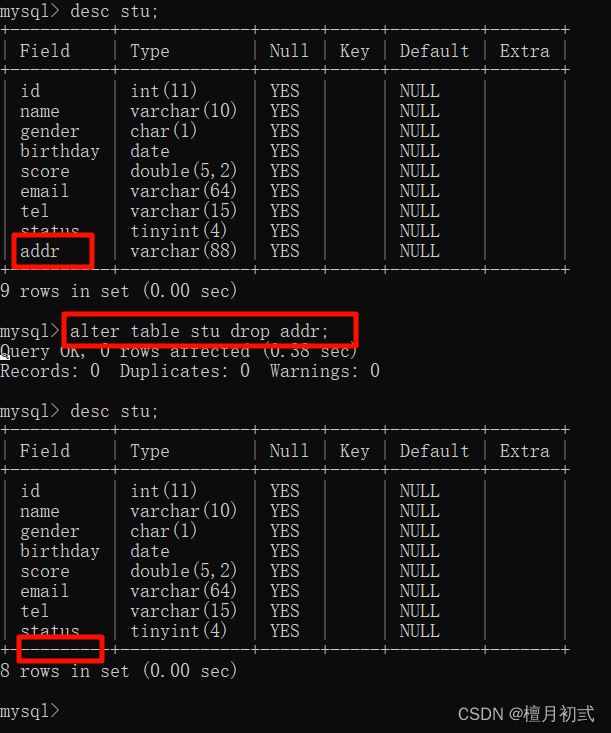
5.刪除列
ALTER TABLE 表名 DROP 列名;
圖形化客戶端工具
Navicat
NavicatforMySQL是管理和開發MySQL或MariaDB的理想解決方案。
這套全面的前端工具為數據庫管理、開發和維護提供了一款直觀而強大的圖形界面。
·官網:http://www.navicat.com.cn

DML–操作數據

添加數據
1.給指定列添加數據
INSERT INTO 表名(列名1,列名2,…)VALUES(值1,值2,..);

2.給全部列添加數據
INSERT INTO 表名 VALUES(值1,值2,.);

3.批量添加數據
INSERT INTO 表名(列名1,列名2,.)VALUES(值1,值2,….),(值1,值2,..),(值1,值2,…..;
INSERT INTO 表名 VALUES(值1,值2,.)),(值1,值2,.),(值1,值2,…..;

修改數據
1.修改表數據
UPDATE 表名 SET 列名1=值1,列名2=值2,….[WHERE 條件];
注意:修改語句中如果不加條件,則將所有數據都修改!

刪除數據
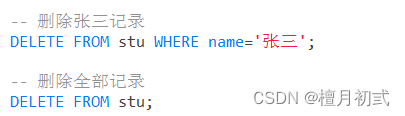
1.刪除數據
DELETE FROM 表名[ WHERE 條件 ];
注意:刪除語句中如果不加條件,則將所有數據都刪除!
DQL
查詢語法
SELECT字段列表
FROM表名列表
WHERE 條件列表
GROUP BY 分組字段
HAVING 分組后條件
ORDER BY 排序字段
LIMIT 分頁限定
基礎查詢
查詢案例
-- 刪除stu表
drop table if exists stu;-- 創建stu表
CREATE TABLE Stu (id int, -- 編號name varchar(20), -- 姓名age int, -- 年齡sex varchar(5), -- 性別address varchar(100), -- 地址math double(5,2), -- 數學成績english double(5,2), -- 英語成績hire_date date -- 入學時間
);-- 添加數據
INSERT INTO stu(id, name, age, sex, address, math, english, hire_date)
VALUES
(1, '馬運', 55, '男', '杭州', 66, 78, '1997-09-01'),
(2, '馬花疼', 45, '女', '深圳', 56, 77, '1998-09-01'),
(3, '馬斯克', 45, '男', '湖南', 20, 87, '1996-09-01'),
(4, '小明', 45, '女', '香港', 96, 65, '1991-09-01'),
(5, '小紅', 57, '男', '香港', 98, 65, '1992-09-01'),
(6, '魯迅', 20, '女', '湖南', 99, 99, '1993-09-01'),
(7, '周樹人', 22, '男', '湖南', 86, NULL, '1994-09-01'),
(8, '陌生人', 18, '女', '南京', 99, 99, '1995-09-01');-- 查詢數據
SELECT * FROM stu;1.查詢多個字段
SELECT 字段列表 FROM 表名;
SELECT * FROM 表名;--查詢所有數據
2.去除重復記錄
SELECT DISTINCT 字段列表 FROM 表名;
3.起別名
AS:AS也可以省略

條件查詢
1.條件查詢語法
SELECT 字段列表 FROM 表名 WHERE 條件列表;
2.條件


模糊查詢

排序查詢
1.排序查詢語法
SELECT 字段列表 FROM 表名 ORDER BY 排序字段名1[排序方式1],排序字段名2[排序方式2]...;
排序方式:
ASC:升序排列 (默認值)
DESC:降序排列
注意:如果有多個排序條件,當前邊的條件值一樣時,才會根據第二條件進行排序

聚合函數
1. 概念:
將一列數據作為一個整體,進行縱向計算。
2.聚合函數分類:
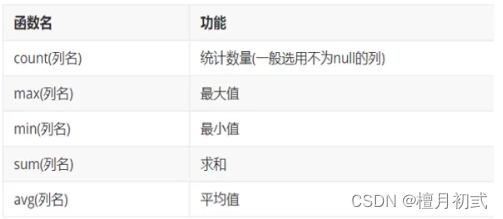
3.聚合函數語法:
SELECT 聚合函數名(列名)FROM 表;
注意:null值不參與所有聚合函數運算

分組查詢
1.分組查詢語法
SELECT 字段列表 FROM 表名 [WHERE 分組前條件限定] GROUP BY 分組字段名[HAVING 分組后條件過濾];
注意:分組之后,查詢的字段為聚合函數和分組字段,查詢其他字段無任何意義
where和having區別:
- 執行時機不一樣:where是分組之前進行限定,不滿足where條件,則不參與分組,而having是分組之后對結果進行過濾。
- 可判斷的條件不一樣:where不能對聚合函數進行判斷,having可以。
執行順序:where>聚合函數>having

分頁查詢
1.分頁查詢語法
SELECT 字段列表 FROM 表名 LIMIT 起始索引 , 查詢條目數;
起始索引:從0開始
計算公式:起始索引 =(當前頁碼-1)*每頁顯示的條數
tips:
- 分頁查詢limit是MySQL數據庫的方言
- Oracle分頁查詢使用rownumber
- SQL Server分頁查詢使用top

數據庫
約束
約束的概念和分類
1.約束的概念
- 約束是作用于表中列上的規則,用于限制加入表的數據
- 約束的存在保證了數據庫中數據的正確性、有效性和完整性
2.約束的分類

Tips:MySQL不支持檢查約束
約束案例
根據需求,為表添加合適的約束

演示:


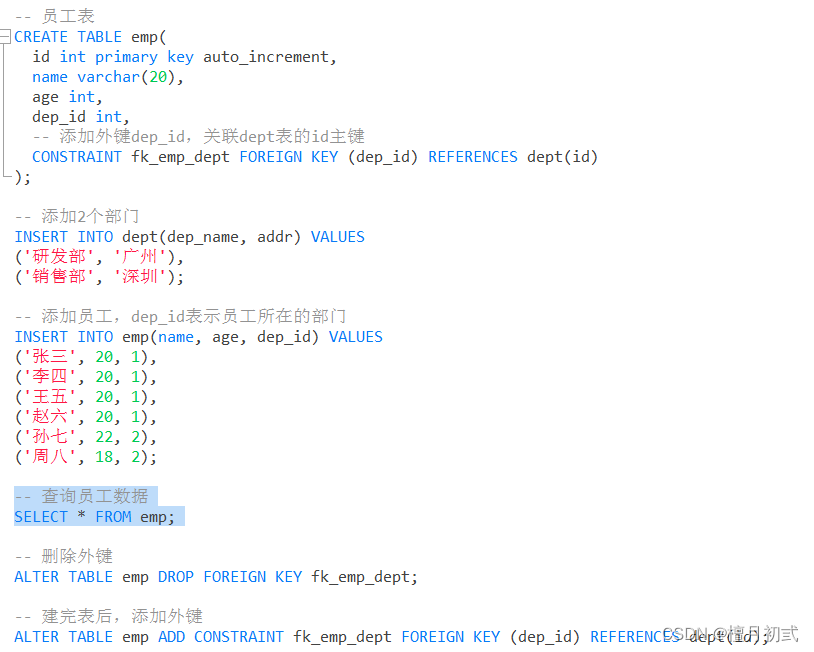
外鍵約束
1.概念
外鍵用來讓兩個表的數據之間建立鏈接,保證數據的一致性和完整性

2.語法
(1)添加約束
-- 創建表時添加外鍵約束
CREATE TABLE 表名(列名 數據類型,...[CONSTRAINT] [外鍵名稱] FOREIGN KEY(外鍵列名)REFERENCES 主表(主表列名)
);
-- 建完表后添加外鍵約束
ALTER TABLE 表名 ADD CONSTRAINT 外鍵名稱 FOREIGN KEY(外鍵字段名稱)REFERENCES主表名稱(主表列名稱);
(2)刪除約束
ALTER TABLE 表名 DROP FOREIGN KEY 外鍵名稱;

數據庫設計
1.軟件的研發步驟

2.數據庫設計概念
- 數據庫設計就是根據業務系統的具體需求,結合我們所選用的DBMS,為這個業務系統構造出最優的數據存儲模型。
- 建立數據庫中的表結構以及表與表之間的關聯關系的過程。
- 有哪些表?表里有哪些字段?表和表之間有什么關系?
3.數據庫設計的步驟
- 需求分析(數據是什么?數據具有哪些屬性?數據與屬性的特點是什么)
- 邏輯分析(通過ER圖對數據庫進行邏輯建模,不需要考慮我們所選用的數據庫管理系統)
- 物理設計(根據數據庫自身的特點把邏輯設計轉換為物理設計)
- 維護設計(1.對新的需求進行建表;2.表優化)
表關系
-
一對一:
---- 如:用戶和用戶詳情
---- 一對一關系多用于表拆分,將一個實體中經常使用的字段放一張表,不經常使用的字段放另一張表,用于提升查詢性能
---- 實現方式:在任意一方加入外鍵,關聯另一方主鍵,并且設置外鍵為唯一(UNIQUE) -
一對多(多對一):
---- 如:部門和員工
---- 一個部門對應多個員工,一個員工對應一個部門
---- 實現方式:在多的一方建立外鍵,指向一的一方的主鍵 -
多對多:
---- 如:商品和訂單
---- 一個商品對應多個訂單,一個訂單包含多個商品
---- 實現方式:建立第三張中間表,中間表至少包含兩個外鍵,分別關聯兩方主鍵
多表查詢
簡介
- 笛卡爾積:取A,B集合所有組合情況
- 多表查詢:從多張表查詢數據
- 連接查詢
- 內連接:相當于查詢AB交集數據
- 外連接:
- 左外連接:相當于查詢A表所有數據和交集部分數據
- 右外連接:相當于查詢B表所有數據和交集部分數據
- 子查詢

- 連接查詢

內連接
1.內連接查詢語法
-- 隱式內連接
SELECT 字段列表 FROM 表1,表2... WHERE 條件;-- 顯示內連接
SELECT 字段列表 FROM 表1 [INNER] JOIN 表2 ON 條件;
內連接相當于查詢AB交集數據


外連接
1.外連接查詢語法
-- 左外連接
SELECT 字段列表 FROM 表1 LEFT [OUTER] JOIN 表2 ON 條件;-- 右外連接
SELECT 字段列表 FROM 表1 RIGHT [OUTER] JOIN 表2 ON 條件;
左外連接:相當于查詢A表所有數據和交集部分數據
右外連接:相當于查詢B表所有數據和交集部分數據
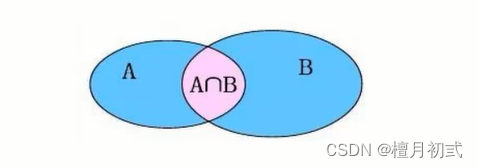

子查詢
1.子查詢概念:
- 查詢中嵌套查詢,稱嵌套查詢為子查詢
2.子查詢根據查詢結果不同,作用不同:
- 單行單列
- 多行單列
- 多行多列
子查詢根據查詢結果不同,作用不同:
- 單行單列:作為條件值,使用=!=><等進行條件判斷
SELECT 字段列表 FROM 表 WHERE 字段名 =(子查詢);
- 多行單列:作為條件值,使用in等關鍵字進行條件判斷
SELECT 字段列表 FROM 表 WHERE 字段名 in(子查詢);
- 多行多列:作為虛擬表
SELECT 字段列表 FROM(子查詢)WHERE 條件;

多表查詢案例
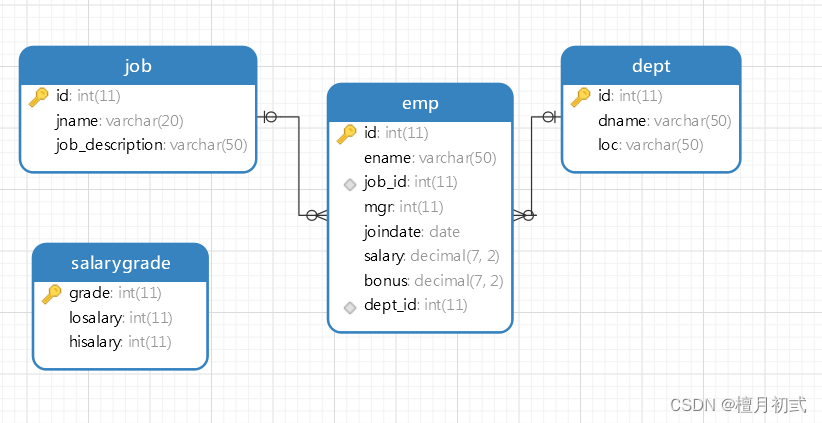
DROP TABLE IF EXISTS emp;
DROP TABLE IF EXISTS dept;
DROP TABLE IF EXISTS job;
DROP TABLE IF EXISTS salarygrade;-- 部門表
CREATE TABLE dept (id INT PRIMARY KEY PRIMARY KEY, -- 部門iddname VARCHAR(50), -- 部門名稱loc VARCHAR(50) -- 部門所在地
);-- 職務表,職務名稱,職務描述
CREATE TABLE job(id INT PRIMARY KEY,jname VARCHAR(20),job_description VARCHAR(50)
);-- 員工表
CREATE TABLE emp(id INT PRIMARY KEY, -- 員工idename VARCHAR(50), -- 員工姓名job_id INT, -- 職務idmgr INT, -- 上級領導joindate DATE, -- 入職日期salary DECIMAL(7,2), -- 工資bonus DECIMAL(7,2), -- 獎金dept_id INT, -- 所在部門編號CONSTRAINT emp_jobid_ref_job_id_fk FOREIGN KEY (job_id) REFERENCES job (id),CONSTRAINT emp_deptid_ref_dept_id_fk FOREIGN KEY (dept_id) REFERENCES dept (id)
);-- 工資等級表
CREATE TABLE salarygrade(grade INT PRIMARY KEY, -- 級別losalary INT, -- 最低工資hisalary INT -- 最高工資
);-- 添加4個部門
INSERT INTO dept(id,dname,loc) VALUES
(10,'教研部','北京'),
(20,'學工部','上海'),
(30,'銷售部','廣州'),
(40,'財務部','深圳');-- 添加4個職務
INSERT INTO job (id, jname, job_description) VALUES
(1,'董事長','管理整個公司,接單'),
(2,'經理','管理部門員工'),
(3,'銷售員','向客人推銷產品'),
(4,'文員','使用辦公軟件');-- 添加員工
INSERT INTO emp(id,ename,job_id,mgr,joindate,salary,bonus,dept_id) VALUES
(1001,'孫悟空',4,1004,'2000-12-17','8000.00',NULL,20),
(1002,'盧俊義',3,1006,'2001-02-20','16000.00','3000.00',30),
(1003,'林沖',3,1006,'2001-02-22','12500.00','5000.00',30),
(1004,'唐僧',2,1009,'2001-04-02','29750.00',NULL,20),
(1005,'李逵',4,1006,'2001-09-28','12500.00','14000.00',30),
(1006,'宋江',2,1009,'2001-05-01','28500.00',NULL,30),
(1007,'劉備',2,1009,'2001-09-01','24500.00',NULL,10),
(1008,'豬八戒',4,1004,'2007-04-19','30000.00',NULL,20),
(1009,'歲貫中',1,NULL,'2001-11-17','50000.00',NULL,10),
(1010,'吳用',3,1006,'2001-09-08','15000.00','0.00',30),
(1011,'沙僧',4,1004,'2007-05-23','11000.00',NULL,20),
(1012,'李達',4,1006,'2001-12-03','9500.00',NULL,30),
(1013,'小白龍',4,1004,'2001-12-03','30000.00',NULL,20),
(1014,'關羽',4,1007,'2002-01-23','13000.00',NULL,10);-- 添加5個工資等級
INSERT INTO salarygrade(grade,losalary,hisalary) VALUES
(1,7000,12000),
(2,12010,14000),
(3,14010,20000),
(4,20010,30000),
(5,30010,99990);
DROP TABLE IF EXISTS emp;
DROP TABLE IF EXISTS dept;
DROP TABLE IF EXISTS job;
DROP TABLE IF EXISTS salarygrade;-- 部門表
CREATE TABLE dept (id INT PRIMARY KEY PRIMARY KEY, -- 部門iddname VARCHAR(50), -- 部門名稱loc VARCHAR(50) -- 部門所在地
);-- 職務表,職務名稱,職務描述
CREATE TABLE job(id INT PRIMARY KEY,jname VARCHAR(20),job_description VARCHAR(50)
);-- 員工表
CREATE TABLE emp(id INT PRIMARY KEY, -- 員工idename VARCHAR(50), -- 員工姓名job_id INT, -- 職務idmgr INT, -- 上級領導joindate DATE, -- 入職日期salary DECIMAL(7,2), -- 工資bonus DECIMAL(7,2), -- 獎金dept_id INT, -- 所在部門編號CONSTRAINT emp_jobid_ref_job_id_fk FOREIGN KEY (job_id) REFERENCES job (id),CONSTRAINT emp_deptid_ref_dept_id_fk FOREIGN KEY (dept_id) REFERENCES dept (id)
);-- 工資等級表
CREATE TABLE salarygrade(grade INT PRIMARY KEY, -- 級別losalary INT, -- 最低工資hisalary INT -- 最高工資
);-- 添加4個部門
INSERT INTO dept(id,dname,loc) VALUES
(10,'教研部','北京'),
(20,'學工部','上海'),
(30,'銷售部','廣州'),
(40,'財務部','深圳');-- 添加4個職務
INSERT INTO job (id, jname, job_description) VALUES
(1,'董事長','管理整個公司,接單'),
(2,'經理','管理部門員工'),
(3,'銷售員','向客人推銷產品'),
(4,'文員','使用辦公軟件');-- 添加員工
INSERT INTO emp(id,ename,job_id,mgr,joindate,salary,bonus,dept_id) VALUES
(1001,'孫悟空',4,1004,'2000-12-17','8000.00',NULL,20),
(1002,'盧俊義',3,1006,'2001-02-20','16000.00','3000.00',30),
(1003,'林沖',3,1006,'2001-02-22','12500.00','5000.00',30),
(1004,'唐僧',2,1009,'2001-04-02','29750.00',NULL,20),
(1005,'李逵',4,1006,'2001-09-28','12500.00','14000.00',30),
(1006,'宋江',2,1009,'2001-05-01','28500.00',NULL,30),
(1007,'劉備',2,1009,'2001-09-01','24500.00',NULL,10),
(1008,'豬八戒',4,1004,'2007-04-19','30000.00',NULL,20),
(1009,'歲貫中',1,NULL,'2001-11-17','50000.00',NULL,10),
(1010,'吳用',3,1006,'2001-09-08','15000.00','0.00',30),
(1011,'沙僧',4,1004,'2007-05-23','11000.00',NULL,20),
(1012,'李達',4,1006,'2001-12-03','9500.00',NULL,30),
(1013,'小白龍',4,1004,'2001-12-03','30000.00',NULL,20),
(1014,'關羽',4,1007,'2002-01-23','13000.00',NULL,10);-- 添加5個工資等級
INSERT INTO salarygrade(grade,losalary,hisalary) VALUES
(1,7000,12000),
(2,12010,14000),
(3,14010,20000),
(4,20010,30000),
(5,30010,99990);-- 1.查詢所有員工信息。查詢員工編號,員工姓名,工資,職務名稱,職務描述
/*分析:1.員工編號,員工姓名,工資信息在emp員工表中2.職務名稱,職務描述信息在job職務表中3.job 職務表 和emp 員工表 是一對多的關系emp.job_id= job.id
*/-- 隱式內連接
select emp.id,emp.ename,emp.salary,job.jname,job.job_description from emp,job where emp.job_id = job.id;select * from emp;
select * from job;
-- 顯式內連接
select emp.id,emp.ename,emp.salary,job.jname,job.job_description from emp inner join job on emp.job_id = job.id;-- 2.查詢員工編號,員工姓名,工資,職務名稱,職務描述,部門名稱,部門位置
/*分析:1.員工編號,員工姓名,工資信息在emp員工表中2.職務名稱,職務描述信息在job職務表中3.job 職務表 和emp 員工表 是一對多的關系emp.job_id= job.id4.部門名稱,部門位置來自于部門表dept5.dept和emp一對多關系dept.id=emp.dept_id
*/-- 隱式內連接
select emp.id,emp.ename,emp.salary,job.jname,job.job_description,dept.dname,dept.loc from emp,job,dept where emp.job_id = job.id and emp.job_id= job.id;-- 顯式內連接
select emp.id,emp.ename,emp.salary,job.jname,job.job_description,dept.dname,dept.loc from emp inner join job on emp.job_id = job.id inner join dept on dept.id = emp.dept_id;-- 3.查詢員工姓名,工資,工資等級
/*分析:1.員工姓名,工資信息在emp員工表中2.工資等級 信息在 salarygrade 工資等級表中3. emp.salary >= salarygrade.losalary and emp.salary <= salarygrade.hisalary*/
select emp.ename,emp.salary,t2.* from emp,salarygrade t2 where emp.salary >= t2.losalary and emp.salary <= t2.hisalary-- 4.查詢員工姓名,工資,職務名稱,職務描述,部門名稱,部門位置,工資等級
/*分析:1.員工編號,員工姓名,工資信息在emp員工表中2.職務名稱,職務描述信息在job職務表中3.job職務表和emp員工表是一對多的關系emp·job_id=job.id4.部門名稱,部門位置來自于部門表 dept5.dept和emp一對多關系dept.id=emp.dept_id6.工資等級信息在 salarygrade工資等級表中7. emp.salary >= salarygrade.losalary and emp.salary <= salarygrade.hisalary
*/
select emp.id,emp.ename,emp.salary,job.jname,job.job_description,dept.dname,dept.loc,t2.grade from emp inner join job on emp.job_id = job.id inner join dept on dept.id = emp.dept_id inner join salarygrade t2 on emp.salary between t2.losalary and t2.hisalary;-- 5.查詢出部門編號、部門名稱、部門位置、部門人數
/*分析:1.部門編號、部門名稱、部門位置來自于部門dept表2.部門人數:在emp表中 按照dept_id進行分組,然后count(*)統計數量3.使用子查詢,讓部門表和分組后的表進行內連接4.
*/
select * from dept;select dept_id, count(*) from emp group by dept_id;select dept.id,dept.dname,dept.loc,t1.count from dept,(select dept_id, count(*) count from emp group by dept_id) t1 where dept.id = t1.dept_id事務
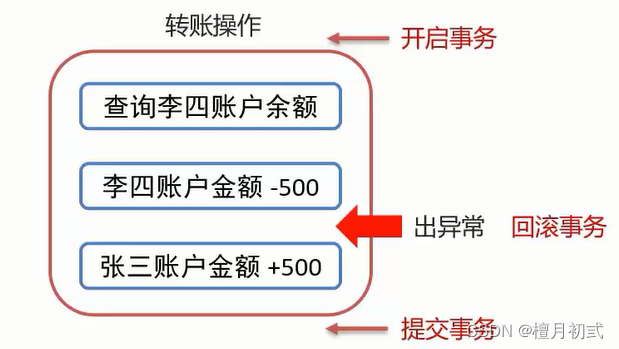
事務簡介
- 數據庫的事務(Transaction)是一種機制、一個操作序列,包含了一組數據庫操作命令
- 事務把所有的命令作為一個整體一起向系統提交或撤銷操作請求,即這一組數據庫命令要么同時成功,要么同時失敗
- 事務是一個不可分割的工作邏輯單元
-- 開啟事務
START TRANSACTION;
或者 BEGIN;
-- 提交事務
COMMIT;
-- 回滾事務
ROLLBACK;
MySQL事務默認自動提交
-- 查看事務的默認提交方式
SELECT @@autocommit;
-- 1 自動提交 θ 手動提交
-- 修改事務提交方式
set @@autocommit = 0;
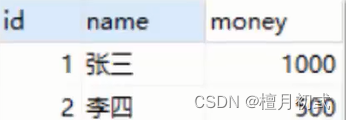
DROP TABLE IF EXISTS aCCount;-- 創建賬戶表CREATE TABLE aCCount(id int PRIMARY KEY auto_increment,name varchar(10),money double(10,2)
);-- 添加數據
INSERT INTO account(name,money) values('張三',1000),('李四',1000);select * from account;
UPDATE account set money = 1000;-- 轉賬操作
-- 開啟事務
BEGIN;
-- 1.查詢李四的余額-- 2.李四金額 -500
UPDATE account set money = money - 500 where name = '李四';-- 出錯了!-- 3.張三金額 +500
UPDATE account set money = money + 500 where name = '張三';-- 提交事務
COMMIT;
-- 回滾事務 :回到開啟事務之前的狀態
ROLLBACK;-- 1.查詢事務的默認提交方式
select @@autocommit;
-- 2.修改事務的提交方式手動提交
set @@autocommit = 0;select * from account;
-- 2.李四金額-500
UPDATE account set money = money - 500 where name = '李四';
-- commit
commit;
事務四大特征
- 原子性(Atomicity):事務是不可分割的最小操作單位,要么同時成功,要么同時失敗
- 一致性(Consistency):事務完成時,必須使所有的數據都保持一致狀態
- 隔離性(lsolation):多個事務之間,操作的可見性
- 持久性(Durability):事務一旦提交或回滾,它對數據庫中的數據的改變就是永久的




)




)




)



中班米羅可兒證書批量生成打印(班級、姓名))
