常見問題
舉個例子
提交任務命令:
bin/flink run \
-t yarn-per-job \
-d \
-p 5 \ 指定并行度
-Dyarn.application.queue=test \ 指定 yarn 隊列
-Djobmanager.memory.process.size=2048mb \ JM2~4G 足夠
-Dtaskmanager.memory.process.size=4096mb \ 單個 TM2~8G 足夠
-Dtaskmanager.numberOfTaskSlots=2 \ 與容器核數 1core: 1slot 或 2core: 1slot
-c com.atguigu.flink.tuning.UvDemo \
/opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar
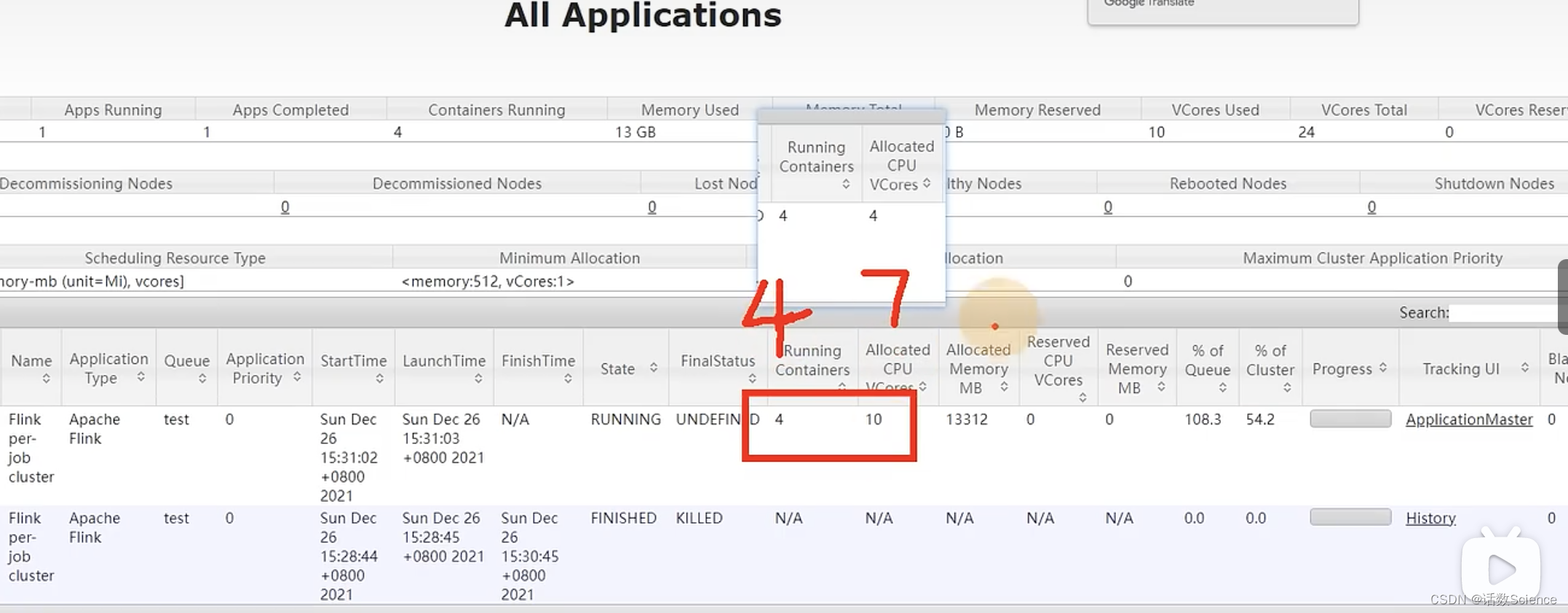
并行度為5,每個任務占用槽數為2,則需要申請3個容器(2*3=6),JobManager需要一個容器,共需要4個容器。6個vcore+JobManager的1個vcore共7個vcore。而實際上是4個容器,4個vcore,這是為什么呢?
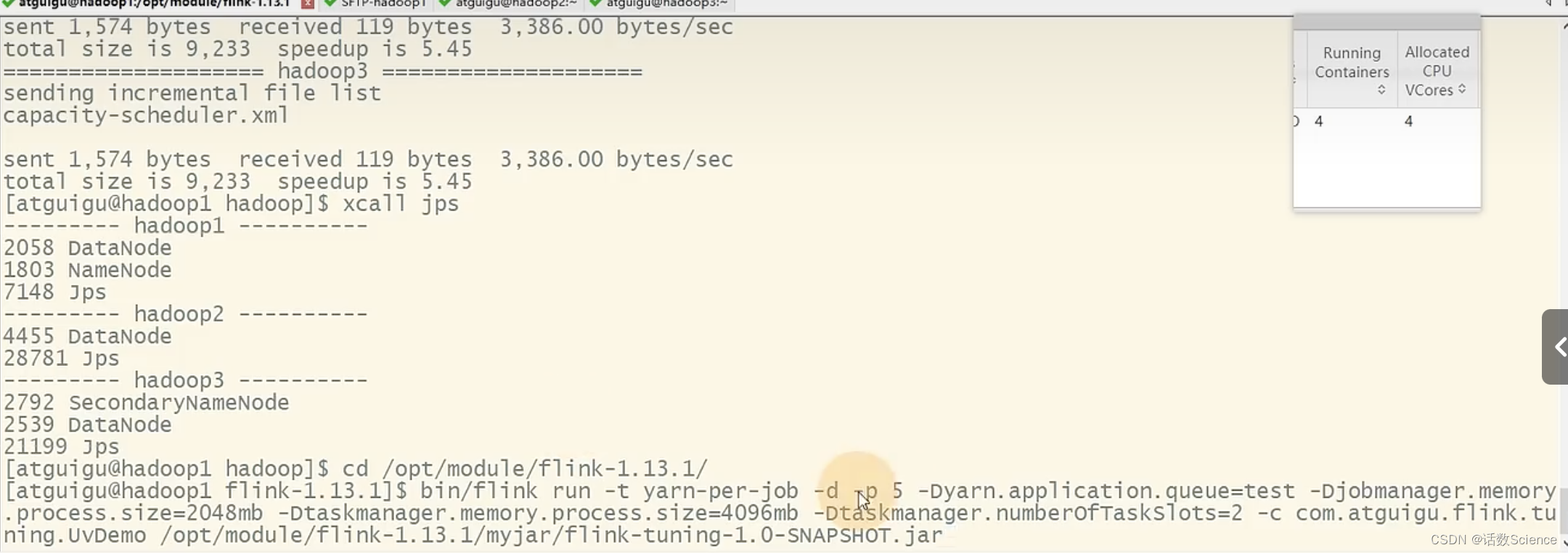
實際運行效果:?
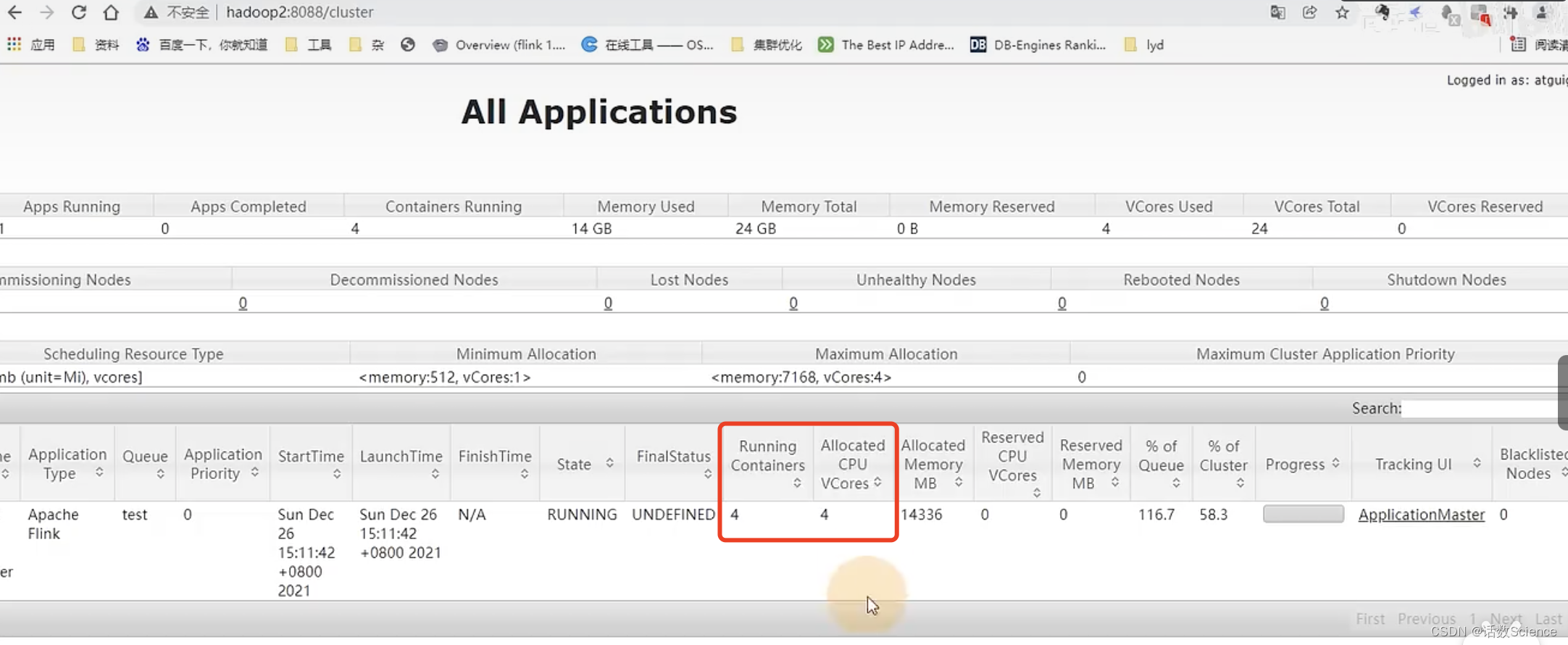
Yarn調度器設置
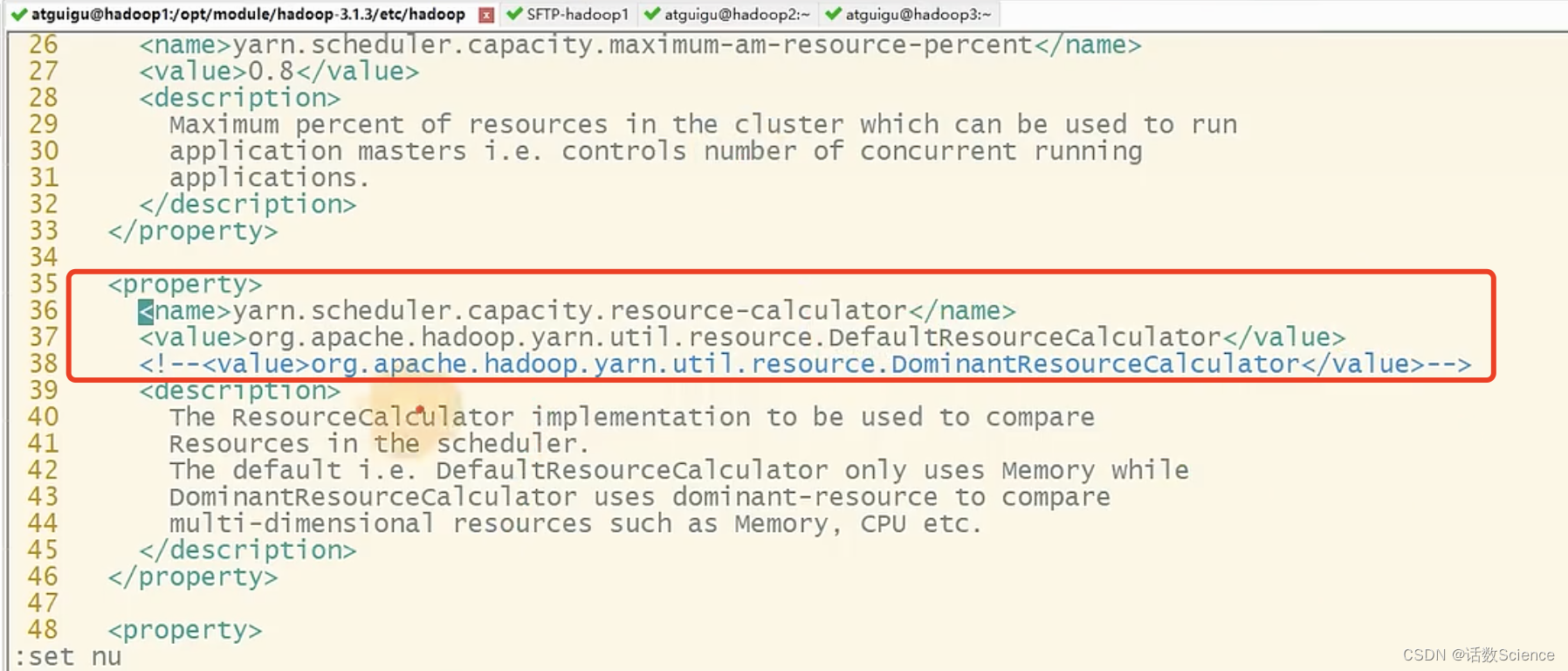
這跟yarn的調度器設置相關,找到capacity-scheduler.xml
- default的方式只會參考內存來申請容器,不會考慮cpu的需求。
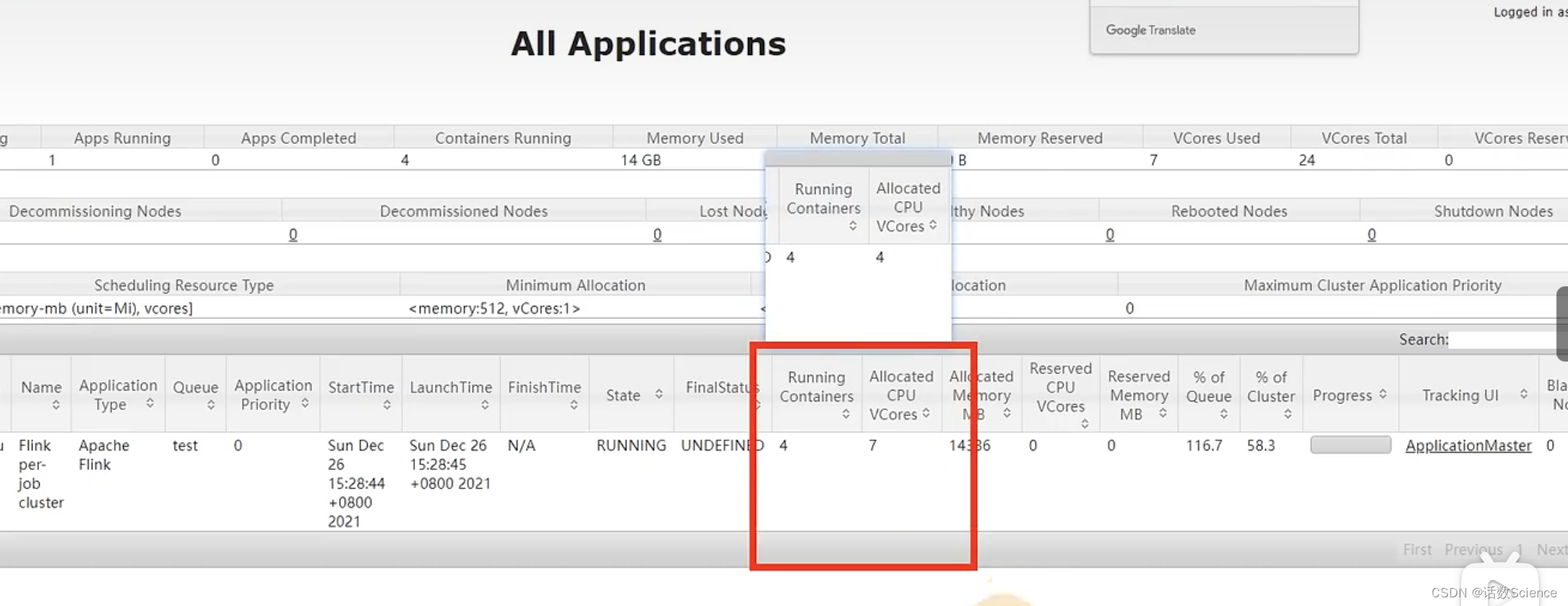
- 調整為下面domian的方式,會綜合考慮內存+CPU的需求來申請資源。
調整后運行效果:

刷新一下
 ?指定容器核心數
?指定容器核心數
bin/flink run \
-t yarn-per-job \
-d \
-p 5 \
-Drest.flamegraph.enabled=true \
-Dyarn.application.queue=test \
-Dyarn.containers.vcores=3 \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=4096mb \
-Dtaskmanager.numberOfTaskSlots=2 \
-c com.atguigu.flink.tuning.UvDemo \
/opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar
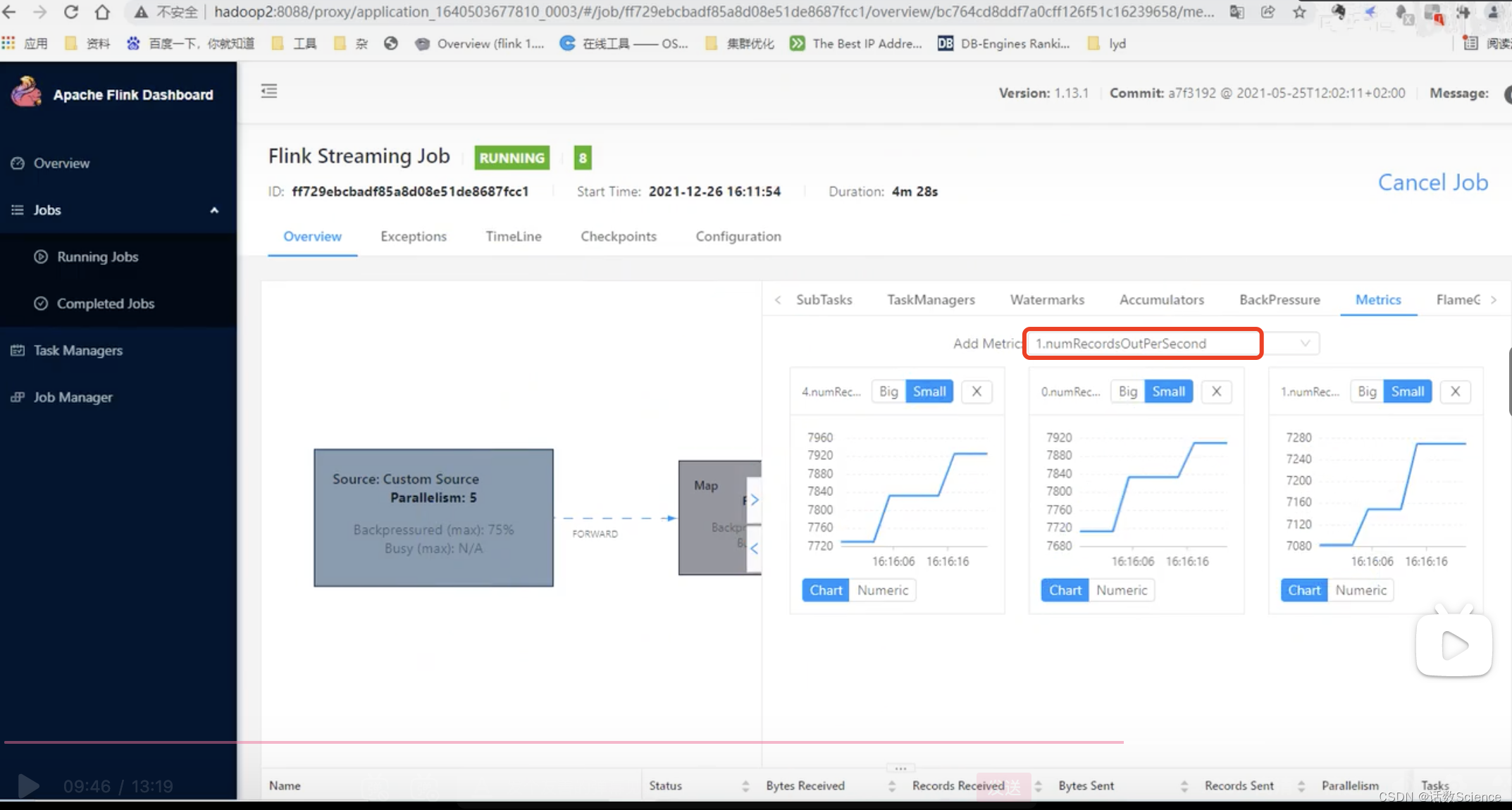
一個容器3個核,2個slot,不是1:1的關系也可以。
slot主要隔離內存,不隔離cpu資源。
solt還有一個共享機制,一個slot可以同時跑多個task,一個solt可以不只使用一個線程。
通常讓系統自動來設置,通常跟solt數1比1
并行度設置
- 配置文件:默認并行度,默認1
- 提交參數:如-p 5
- 代碼env
- 代碼算子
優先級下面的高。
全局并行度計算
????????開發完成后,先進行壓測。任務并行度給 10 以下,測試單個并行度的處理上限。然后
總QPS / 單并行度的處理能力 = 并行度
QPS使用高峰期的。
????????開發完 Flink 作業,壓測的方式很簡單,先在 kafka 中積壓數據,之后開啟 Flink 任務,
出現反壓,就是處理瓶頸。相當于水庫先積水,一下子泄洪。
????????不能只從 QPS 去得出并行度,因為有些字段少、邏輯簡單的任務,單并行度一秒處理
幾萬條數據。 而有些數據字段多,處理邏輯復雜, 單并行度一秒只能處理 1000 條數據。
最好根據高峰期的 QPS 壓測, 并行度*1.2 倍,富余一些資源。
查看單個任務的輸出量:numRecordsOutPerSecond,單并行度7000條/秒,生成環境高峰期的qps:30000/s,30000/7000 = 4.x,并行度5,再乘以個冗余1.2 = 6個
如果數據源是kafka,可以按kafka分區數來設置并行度。?
大部分情況下并行度10以下即可。
Source 端并行度的配置
????????數據源端是 Kafka, Source 的并行度設置為 Kafka 對應 Topic 的分區數。
????????如果已經等于 Kafka 的分區數, 消費速度仍跟不上數據生產速度, 考慮下 Kafka 要擴
大分區, 同時調大并行度等于分區數。
????????Flink 的一個并行度可以處理一至多個分區的數據,如果并行度多于 Kafka 的分區數,
那么就會造成有的并行度空閑,浪費資源。
Transform 端并行度的配置
Keyby 之前的算子
一般不會做太重的操作,都是比如 map、 filter、 flatmap 等處理較快的算子,并行度
可以和 source 保持一致。
Keyby 之后的算子
如果并發較大,建議設置并行度為 2 的整數次冪,例如: 128、 256、 512;
小并發任務的并行度不一定需要設置成 2 的整數次冪;
大并發任務如果沒有 KeyBy,并行度也無需設置為 2 的整數次冪;
Sink 端并行度的配置
????????Sink 端是數據流向下游的地方,可以根據 Sink 端的數據量及下游的服務抗壓能力進行評估。 如果 Sink 端是 Kafka,可以設為 Kafka 對應 Topic 的分區數。
????????Sink 端的數據量小, 比較常見的就是監控告警的場景,并行度可以設置的小一些。
????????Source 端的數據量是最小的,拿到 Source 端流過來的數據后做了細粒度的拆分,數據量不斷的增加,到 Sink 端的數據量就非常大。那么在 Sink 到下游的存儲中間件的時候就需要提高并行度。
????????另外 Sink 端要與下游的服務進行交互,并行度還得根據下游的服務抗壓能力來設置,如果在 Flink Sink 這端的數據量過大的話, 且 Sink 處并行度也設置的很大,但下游的服務完全撐不住這么大的并發寫入,可能會造成下游服務直接被寫掛,所以最終還是要在 Sink處的并行度做一定的權衡。
混淆)
)







)




)




-上下文管理器和else塊)