- 參考書:
- 《speech and language processing》
- 《統計自然語言處理》 宗成慶
-
語言是思維的載體,自然語言處理相比其他信號較為特別
-
word2vec用到c語言
-
Question
- 預訓練語言模型和其他模型的區別?
預訓練模型是指在大規模數據上進行預訓練的模型,通常使用無監督學習方法。
在預訓練階段,模型通過學習數據的統計特征來捕捉數據的潛在結構和語義信息。
預訓練模型的目標是學習到一個通用的表示,使得該表示可以應用于各種下游任務,如文本分類、命名實體識別等。預訓練模型的優勢在于可以利用大規模數據進行訓練,從而提取出更豐富的特征表示,有助于提高模型的泛化能力和性能。
case:像wordvec2給出所有英文/中文單詞的嵌入式表示,可適用于謠言檢測
其他深度學習模型通常是指從頭開始訓練的模型,也稱為端到端模型。
這些模型需要根據具體任務的特點和數據集的特征進行設計和調整。相比于預訓練模型,
其他深度學習模型需要更多的標注數據和計算資源來進行訓練,并且對于不同的任務需要重新設計網絡結構和調整超參數。
與之相對應的是其他模型,如傳統的機器學習模型或基于規則的模型。
這些模型通常需要手動設計特征或規則,并且需要有標注的數據進行監督學習。
相比之下,預訓練模型不需要手動設計特征,而是通過大規模數據自動學習特征表示。
- 同步的序列到序列 與異步的序列到序列 的區別?
同步的序列到序列和異步的序列到序列是兩種不同的機器翻譯模型架構。
同步的序列到序列模型是指源語言句子和目標語言句子之間的對應關系是一一對應的,即源語言句子中的每個詞都對應目標語言句子中的一個詞。這種模型在訓練和推理過程中都需要同時考慮源語言和目標語言的上下文信息,因此被稱為同步模型。同步模型通常使用編碼器-解碼器結構,其中編碼器將源語言句子編碼為一個固定長度的向量表示,解碼器根據這個向量表示生成目標語言句子。
異步的序列到序列模型是指源語言句子和目標語言句子之間的對應關系不是一一對應的,即源語言句子中的一個詞可能對應目標語言句子中的多個詞,或者多個詞對應一個詞。這種模型在訓練和推理過程中可以分別處理源語言和目標語言的上下文信息,因此被稱為異步模型。異步模型通常使用多層編碼器和解碼器,其中編碼器將源語言句子編碼為一個序列的向量表示,解碼器根據這個序列的向量表示生成目標語言句子。
總結來說,同步的序列到序列模型要求源語言和目標語言的對應關系是一一對應的,而異步的序列到序列模型允許源語言和目標語言的對應關系是一對多或多對一的。這兩種模型在處理機器翻譯任務時有不同的優勢和適用場景。
- Transformer和Bert的區別
Transformer和BERT都是自然語言處理領域中非常重要的模型,它們都基于Transformer架構,但在一些細節上有所不同。
Transformer是一種用于序列到序列任務的模型架構,最初被提出用于機器翻譯任務。它使用了自注意力機制(self-attention)來捕捉輸入序列中不同位置之間的依賴關系,避免了傳統的循環神經網絡中的順序計算。Transformer由編碼器和解碼器組成,編碼器將輸入序列映射為一系列隱藏表示,解碼器則根據編碼器的輸出生成目標序列。
BERT(Bidirectional Encoder Representations from Transformers)是一種基于Transformer的預訓練語言模型。與傳統的語言模型只使用左側或右側的上下文信息不同,BERT通過使用雙向上下文信息進行預訓練,從而更好地理解詞語的含義。BERT的預訓練過程包括兩個任務:掩碼語言建模(Masked Language Modeling,MLM)和下一句預測(Next Sentence Prediction,NSP)。在預訓練完成后,BERT可以通過微調來適應各種下游任務,如文本分類、命名實體識別等。
因此,Transformer是一種通用的模型架構,適用于各種序列到序列的任務,而BERT是基于Transformer的預訓練語言模型,可以通過微調適應各種下游任務。
- Bert的輸出是什么
Bert(Bidirectional Encoder Representations from Transformers)是一種預訓練的語言模型,它可以將輸入的文本轉換為向量表示。Bert的輸出是一個表示輸入文本的向量序列,其中每個向量都包含了該位置的詞語的語義信息。
具體來說,Bert模型通過將輸入文本分為多個token,并將每個token轉換為對應的詞向量。這些詞向量經過多層的Transformer編碼器進行處理,得到每個token的上下文相關表示。Bert模型的輸出包括兩個部分:
Token級別的輸出:每個token對應一個向量表示,這些向量可以用于各種下游任務,如文本分類、命名實體識別等。
句子級別的輸出:Bert模型還提供了一個特殊的向量表示,通常被稱為CLS向量(classification vector),它捕捉了整個句子的語義信息。這個CLS向量可以用于句子級別的任務,如句子分類、句子相似度計算等。
需要注意的是,Bert模型是基于無監督預訓練的,它通過大規模的語料庫進行訓練,學習到了豐富的語義信息。在實際應用中,可以將Bert模型作為特征提取器,將其輸出作為輸入傳遞給其他機器學習模型或神經網絡進行下游任務的訓練和推理。
- Bert的過程與作用
-
從訓練過程可以看出,掩碼語言建模 ? \Longrightarrow ?學習上下文單詞間關系;
實現方式:Mask也有特殊嵌入式表示,按多頭自注意力機制,輸出各token的向量序列,掩碼token對應的向量反嵌入轉為單詞
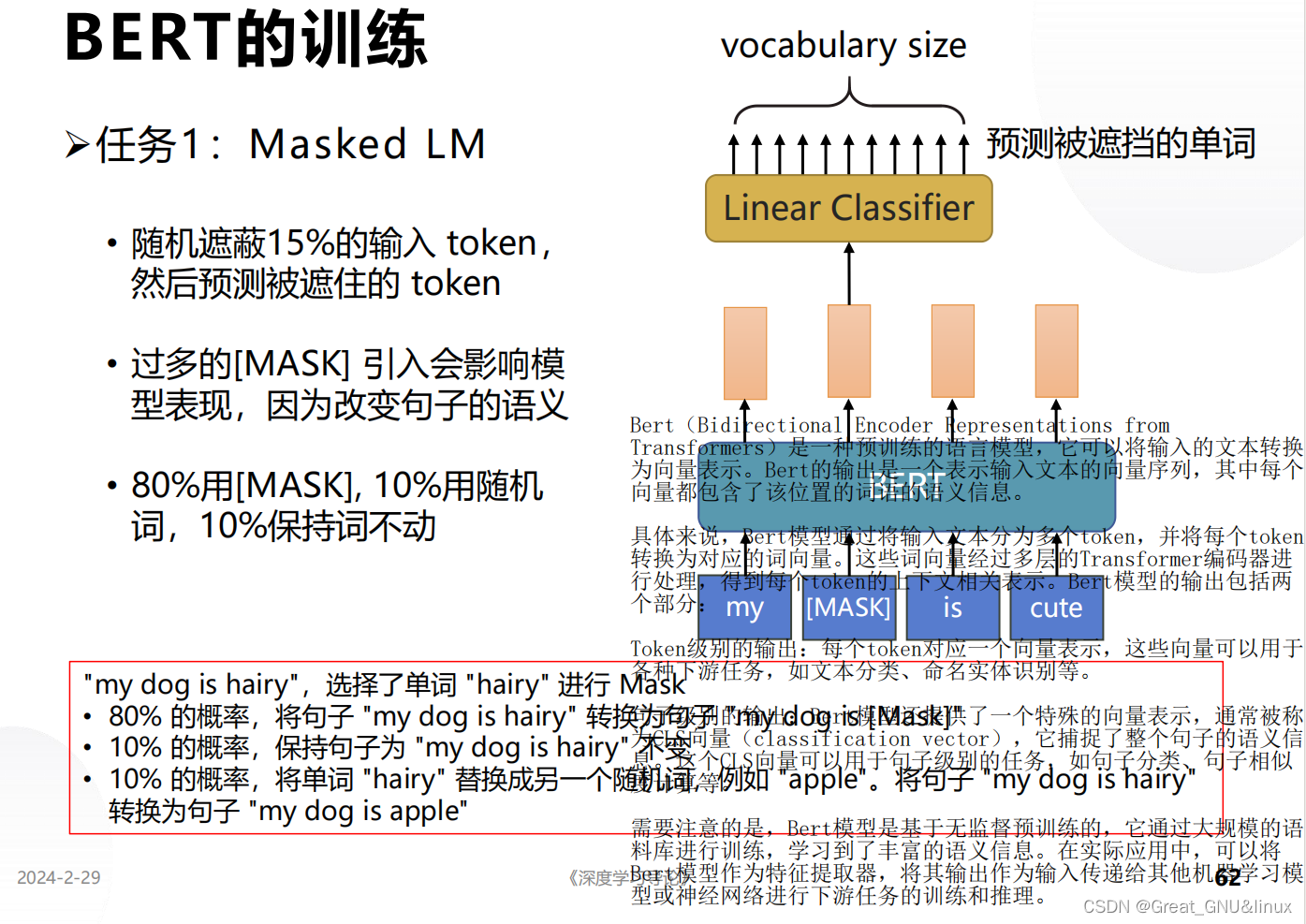
-
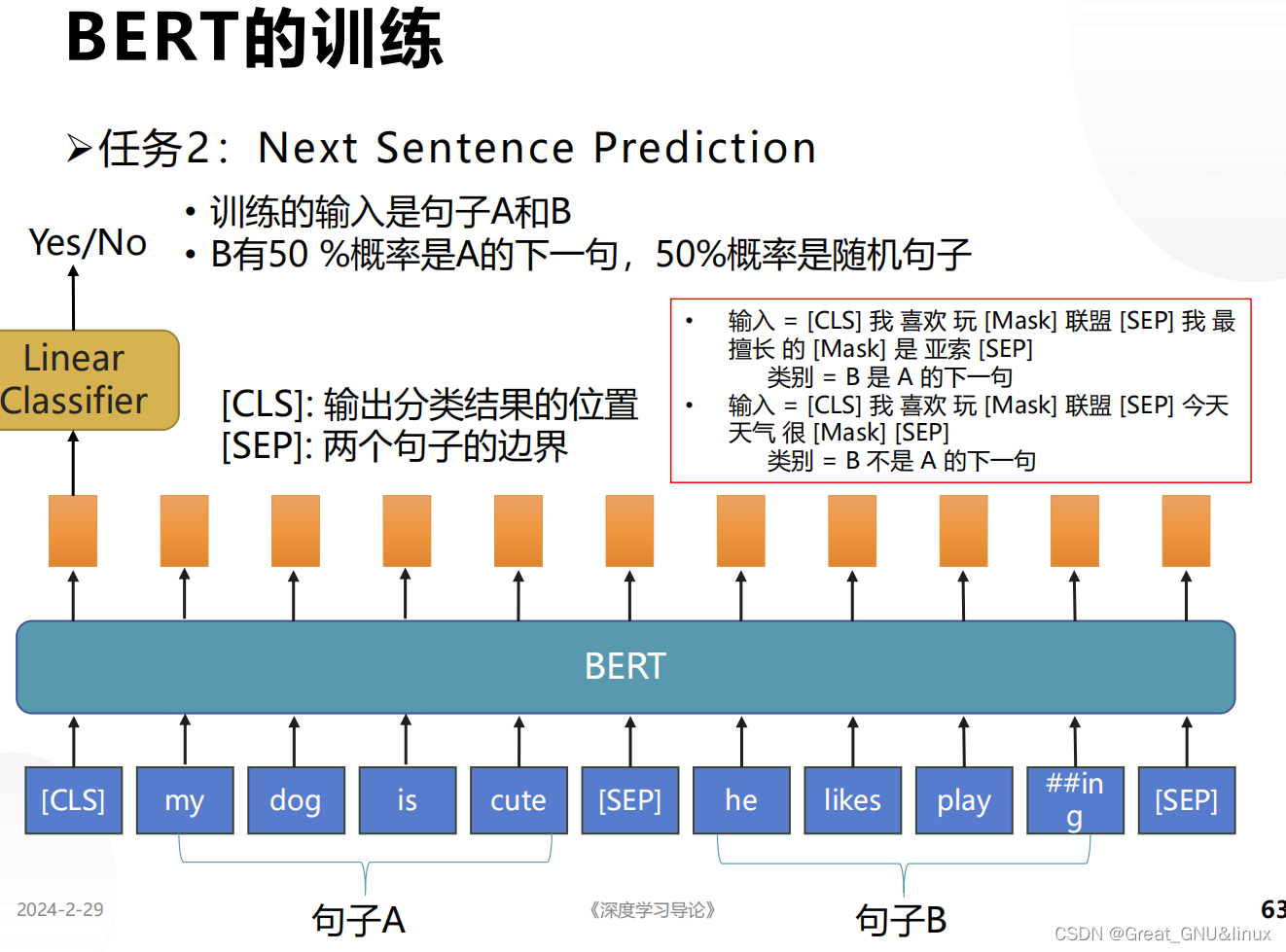
預測下一句是否合理 ? \Longrightarrow ?學習單詞的集合表示 → \rightarrow →句義的上下文關系
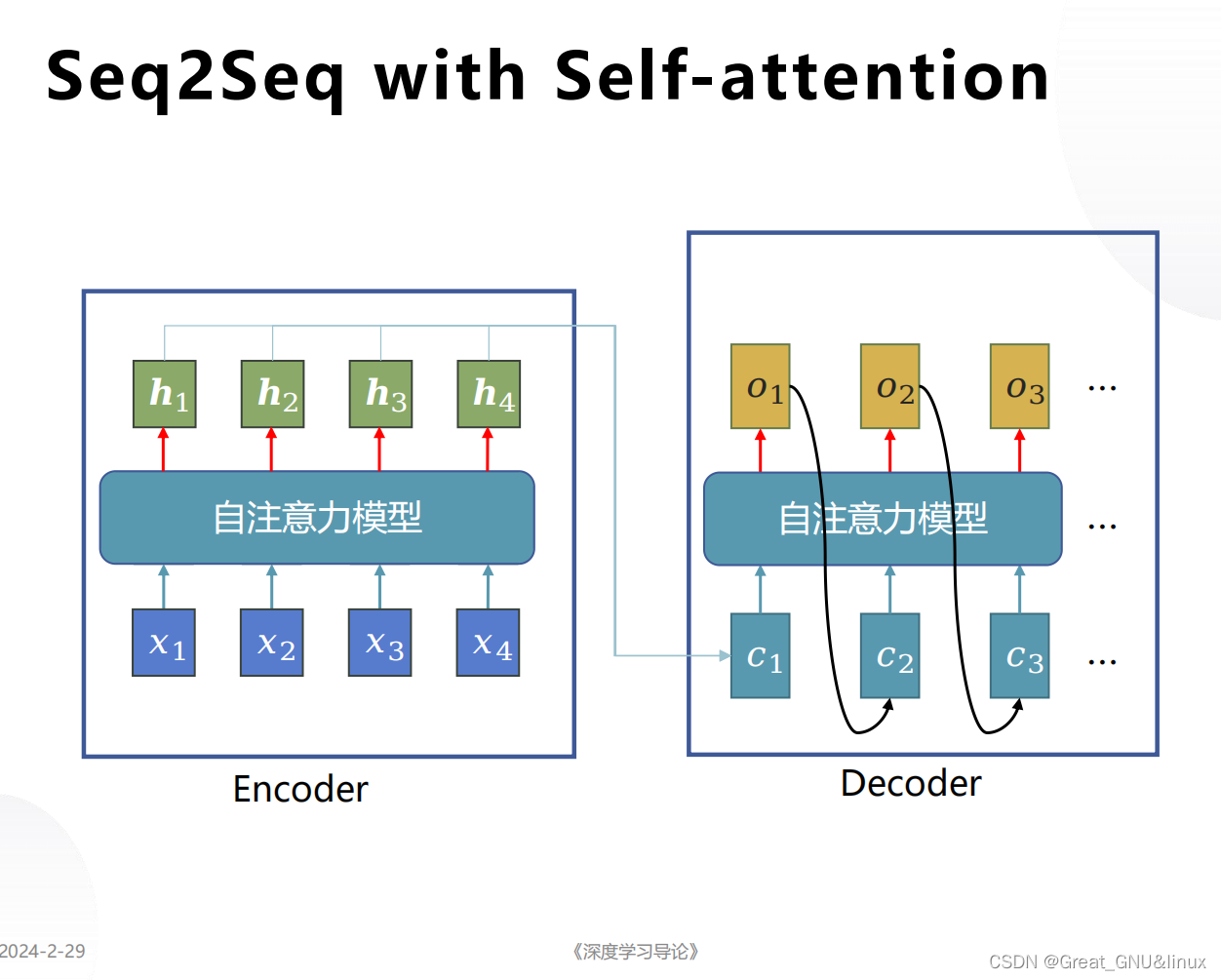
- 多頭自注意力機制用于編碼,可以或用LSTM解碼,這就是Transformer.
- Fourier變換的作用?
Fourier變換是一種數學工具,用于將一個函數從時域(域)轉換到頻域(頻率域)。它可以將一個信號分解成一系列不同頻率的正弦和余弦函數的疊加,從而揭示出信號中包含的各個頻率成分的強度和相位信息。
Fourier變換在信號處理、圖像處理、通信系統、音頻處理等領域中具有廣泛的應用。它可以用于信號濾波、頻譜分析、噪聲去除、圖像壓縮、音頻合成等任務。通過將信號從時域轉換到頻域,我們可以更好地理解信號的頻率特性,從而更好地處理和分析信號。
具體來說,Fourier變換可以將一個連續時間的函數表示為一系列復數的和,每個復數代表了不同頻率的正弦和余弦函數的振幅和相位。這些復數被稱為頻譜,它們描述了信號在不同頻率上的能量分布情況。通過對頻譜進行操作,我們可以實現信號的濾波、頻譜分析和合成等功能。
總結一下,Fourier變換的作用是將一個函數從時域轉換到頻域,揭示出信號中各個頻率成分的強度和相位信息,為信號處理和分析提供了重要的數學工具。
+flink(1.13.6)+dinky(0.6)+iceberg))










![[Flutter]用16進制顏色字符串初始化Color](http://pic.xiahunao.cn/[Flutter]用16進制顏色字符串初始化Color)
(內包含NSGA II優化算法)(二))


)



)