R語言數據分析(五)
文章目錄
- R語言數據分析(五)
- 前言
- 一、什么是整潔的數據
- 二、延長數據
- 2.1 列名中的數據值
- 2.2 `pivot_longer()`的處理原理
- 2.3 列名中包含許多變量的情況
- 2.4 列名同時包含數據和變量
- 三、擴寬數據
- 3.1 `pivot_wider`的處理原理
- 總結
前言
我們學習了數據導入、可視化以及數據轉換的相關知識,那么在數據導入后要進行的就是數據的整理,這是一個將凌亂的數據整理成為整潔數據的過程。只有整潔的數據才能很好的進行數據轉換分析以及可視化。在這一節的學習中我們將會使用一種稱為tidy data的系統在R中組織數據。(注意加載tidyverse包)
一、什么是整潔的數據
數據的呈現方式多種多樣,下面的示例展示了三種不同的方式整理的相同的數據。每個數據都用于顯示一組數據,包括:英雄名稱、版本、攻擊力和防御力數值,但每個數據集組織這些值的方式不同:
# 這里是我自定義的table1、2、3,可以自己去自定義一些tibble順便復習前面的知識了,其實在tidyverse中也有自己的table1、2、3存在,可以自行查看。
table1
#> # A tibble: 6 × 4
#> Hero Version ATK DEF
#> <chr> <dbl> <dbl> <dbl>
#> 1 LMY 1 999 666
#> 2 LMY 2 1000 999
#> 3 NEW 1 99 66
#> 4 NEW 2 100 99
#> 5 Z 1 5 1
#> 6 Z 2 5 0.5table2
#> # A tibble: 12 × 4
#> Hero Version type value
#> <chr> <dbl> <chr> <dbl>
#> 1 LMY 1 ATK 999
#> 2 LMY 1 DEF 666
#> 3 LMY 2 ATK 1000
#> 4 LMY 2 DEF 999
#> 5 NEW 1 ATK 99
#> 6 NEW 1 DEF 100
#> 7 NEW 2 ATK 66
#> 8 NEW 2 DEF 99
#> 9 Z 1 ATK 5
#> 10 Z 1 DEF 5
#> 11 Z 2 ATK 1
#> 12 Z 2 DEF 0.5table3
#> # A tibble: 6 × 3
#> Hero Version rate
#> <chr> <dbl> <dbl>
#> 1 LMY 1 1.5
#> 2 LMY 2 1.00
#> 3 NEW 1 0.99
#> 4 NEW 2 0.667
#> 5 Z 1 1
#> 6 Z 2 2
其中table1是在tidyverse中容易使用的形式,以為它是tidy的。
整潔的數據集需要遵循三個相互關聯的規則:
-
每個變量都是一列,每一列都是一個變量。
-
每個觀測值都是一行,每一行都是一個觀測值。
-
每個值都是一個單元格,每個單元格都是一個值。
保持數據的整潔主要有兩個優點:
-
一致的數據存儲方式有一個普遍的優勢。更易于學習工具,具有底層的一致性
-
變量放在列中有一個特定的優勢,以為它很貼合R的矢量化性質。
tidyverse中所有軟件包都旨在處理整潔的數據,下面是一些小示例:
table1 |> mutate(rate = ATK / DEF)
#> # A tibble: 6 × 5
#> Hero Version ATK DEF rate
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 LMY 1 999 666 1.5
#> 2 LMY 2 1000 999 1.00
#> 3 NEW 1 99 66 1.5
#> 4 NEW 2 100 99 1.01
#> 5 Z 1 5 1 5
#> 6 Z 2 5 0.5 10table1 |> group_by(Version) |> summarize(total_version = sum(ATK))
#> # A tibble: 2 × 2
#> Version total_version
#> <dbl> <dbl>
#> 1 1 1103
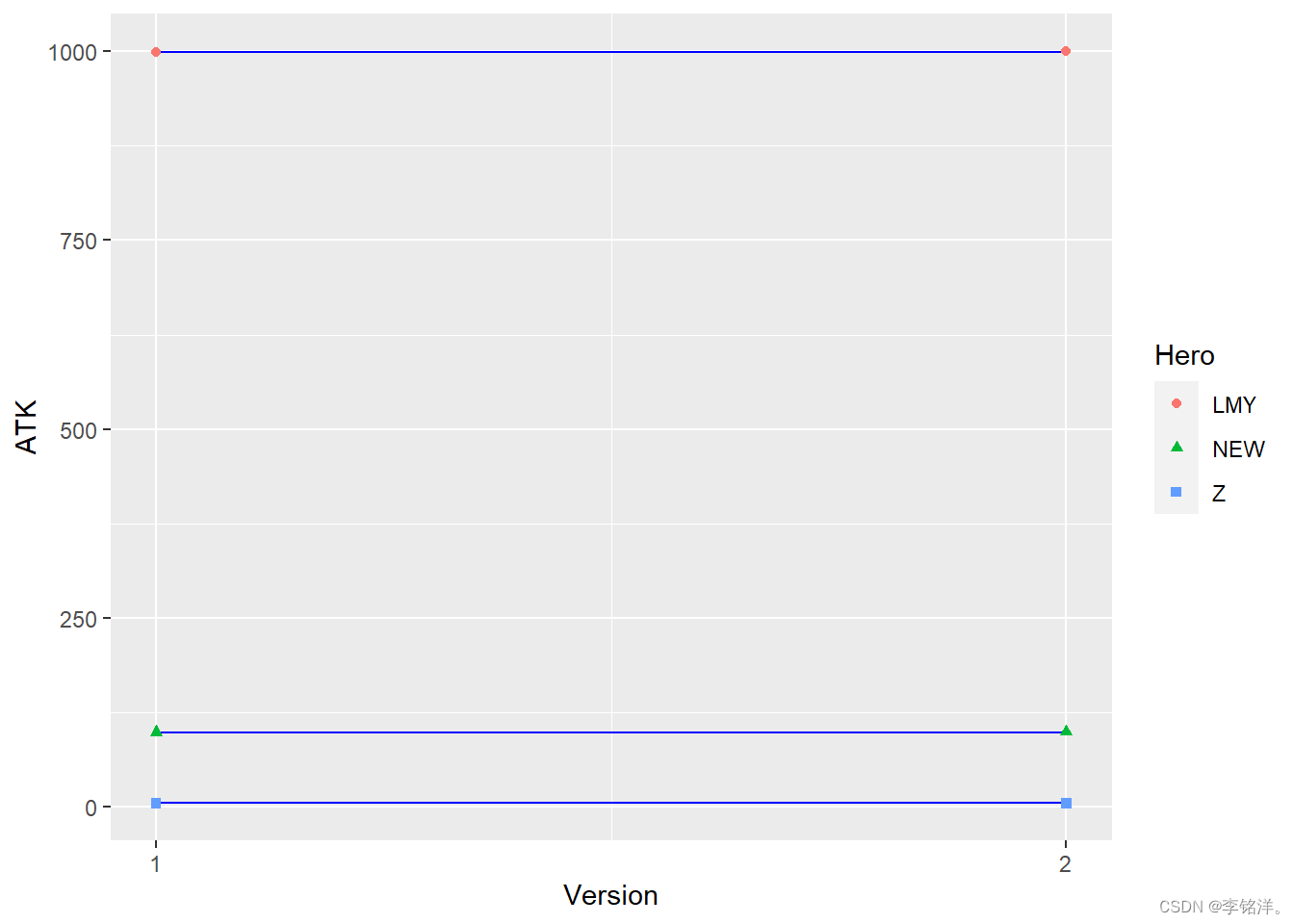
#> 2 2 1105ggplot(table1, aes(x = Version, y = ATK)) +geom_line(aes(group = Hero), color = "Blue") + geom_point(aes(color = Hero, shape = Hero)) +scale_x_continuous(breaks = c(1.0, 2.0))
二、延長數據
整潔數據的原則看起來十分簡單,但是在大多數情況下,遇到的數據都是不整潔的。這就意味著大多數實際分析至少需要一點整理。
首先要弄清楚基礎變量和觀察值是什么。接下來,要將數據轉化為整潔的形式,列包含變量,行包含觀測值。
2.1 列名中的數據值
tidyverse中的billboard數據集記錄了2000年歌曲廣告排名:
billboard
#> # A tibble: 317 × 79
#> artist track date.entered wk1 wk2 wk3 wk4 wk5 wk6 wk7 wk8
#> <chr> <chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 2 Pac Baby… 2000-02-26 87 82 72 77 87 94 99 NA
#> 2 2Ge+her The … 2000-09-02 91 87 92 NA NA NA NA NA
#> 3 3 Doors D… Kryp… 2000-04-08 81 70 68 67 66 57 54 53
#> 4 3 Doors D… Loser 2000-10-21 76 76 72 69 67 65 55 59
#> 5 504 Boyz Wobb… 2000-04-15 57 34 25 17 17 31 36 49
#> 6 98^0 Give… 2000-08-19 51 39 34 26 26 19 2 2
#> 7 A*Teens Danc… 2000-07-08 97 97 96 95 100 NA NA NA
#> 8 Aaliyah I Do… 2000-01-29 84 62 51 41 38 35 35 38
#> 9 Aaliyah Try … 2000-03-18 59 53 38 28 21 18 16 14
#> 10 Adams, Yo… Open… 2000-08-26 76 76 74 69 68 67 61 58
#> # ? 307 more rows
#> # ? 68 more variables: wk9 <dbl>, wk10 <dbl>, wk11 <dbl>, wk12 <dbl>,
#> # wk13 <dbl>, wk14 <dbl>, wk15 <dbl>, wk16 <dbl>, wk17 <dbl>, wk18 <dbl>,
#> # wk19 <dbl>, wk20 <dbl>, wk21 <dbl>, wk22 <dbl>, wk23 <dbl>, wk24 <dbl>,
#> # wk25 <dbl>, wk26 <dbl>, wk27 <dbl>, wk28 <dbl>, wk29 <dbl>, wk30 <dbl>,
#> # wk31 <dbl>, wk32 <dbl>, wk33 <dbl>, wk34 <dbl>, wk35 <dbl>, wk36 <dbl>,
#> # wk37 <dbl>, wk38 <dbl>, wk39 <dbl>, wk40 <dbl>, wk41 <dbl>, wk42 <dbl>, …
其中,每個觀測值是一首歌,前三列是歌曲信息,之后有76列來描述歌曲每周的排名。這76列中,列名是一個變量(week),單元格值是另一個變量(week rank)。
為了整理這些數據,我們使用pivot_longer()函數:
billboard |> pivot_longer(cols = starts_with("wk"),names_to = "week",values_to = "rank")
#> # A tibble: 24,092 × 5
#> artist track date.entered week rank
#> <chr> <chr> <date> <chr> <dbl>
#> 1 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk1 87
#> 2 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk2 82
#> 3 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk3 72
#> 4 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk4 77
#> 5 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk5 87
#> 6 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk6 94
#> 7 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk7 99
#> 8 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk8 NA
#> 9 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk9 NA
#> 10 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk10 NA
#> # ? 24,082 more rows
使用此函數需要注意:
-
cols參數用于指定哪些列需要進行整合,這個參數使用的語法與select()相同,因此可以使用!c(artist, track, data.entered)或者starts_with("wk")。 -
names_to參數對存儲在列名中的變量進行命名。 -
values_to參數將存儲在單元格中的變量進行命名。
我們注意到轉化后的數據中有NA值。比如數據的第8行就存在。這是因為這首歌在第8周并未進入前100名所導致的。那么這些NA并不是真正的觀察結果。因此可以使用參數values_drop_na = TRUE來使得pivot_longer()刪除NA。
現在數據就是整潔的了,不過我們可以通過使用mutate()和readr::parse_number()來將字符串變為數字,parse_number()函數將從字符串提取第一個數字,忽略所有其他文本:
billboard_longer <- billboard |> pivot_longer(cols = starts_with("wk"),names_to = "week",values_to = "rank",values_drop_na = TRUE) |> mutate(week = parse_number(week))
billboard_longer
#> # A tibble: 5,307 × 5
#> artist track date.entered week rank
#> <chr> <chr> <date> <dbl> <dbl>
#> 1 2 Pac Baby Don't Cry (Keep... 2000-02-26 1 87
#> 2 2 Pac Baby Don't Cry (Keep... 2000-02-26 2 82
#> 3 2 Pac Baby Don't Cry (Keep... 2000-02-26 3 72
#> 4 2 Pac Baby Don't Cry (Keep... 2000-02-26 4 77
#> 5 2 Pac Baby Don't Cry (Keep... 2000-02-26 5 87
#> 6 2 Pac Baby Don't Cry (Keep... 2000-02-26 6 94
#> 7 2 Pac Baby Don't Cry (Keep... 2000-02-26 7 99
#> 8 2Ge+her The Hardest Part Of ... 2000-09-02 1 91
#> 9 2Ge+her The Hardest Part Of ... 2000-09-02 2 87
#> 10 2Ge+her The Hardest Part Of ... 2000-09-02 3 92
#> # ? 5,297 more rows
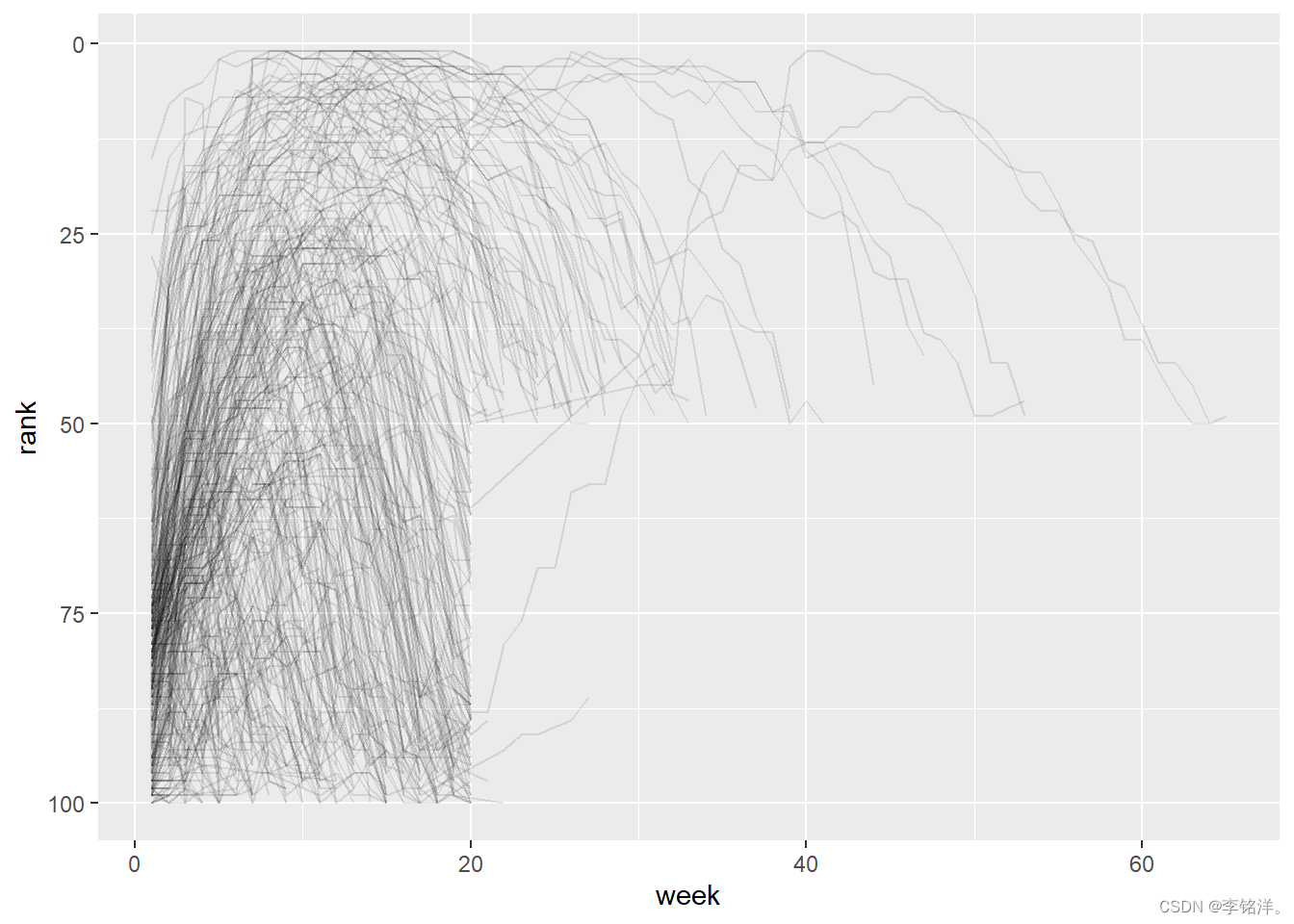
現在我們就可以對這樣的結果進行很好的可視化了
billboard_longer |> ggplot(aes(x = week, y = rank, group = track)) + geom_line(alpha = 0.1) +scale_y_reverse()
2.2 pivot_longer()的處理原理
明白使用函數pivot_longer()處理的原理很重要,這樣我們就能夠在需要使用這些功能的時候能更快的想到該函數。
假設我們有三個小朋友,記為A、B、C。兩年分別測量了兩次身高。我們建立一個tibble表格來記錄數據:
df <- tribble(~id, ~h1, ~h2,"A", 110, 130,"B", 100, 110,"C", 80, 135
)
我們經過處理后得到以下數據集:
df |> pivot_longer(cols = h1:h2,names_to = "year_h",values_to = "value")
#> # A tibble: 6 × 3
#> id year_h value
#> <chr> <chr> <dbl>
#> 1 A h1 110
#> 2 A h2 130
#> 3 B h1 100
#> 4 B h2 110
#> 5 C h1 80
#> 6 C h2 135
函數如何工作的呢?逐列來看,我們發現了其工作模式。如下圖所示:
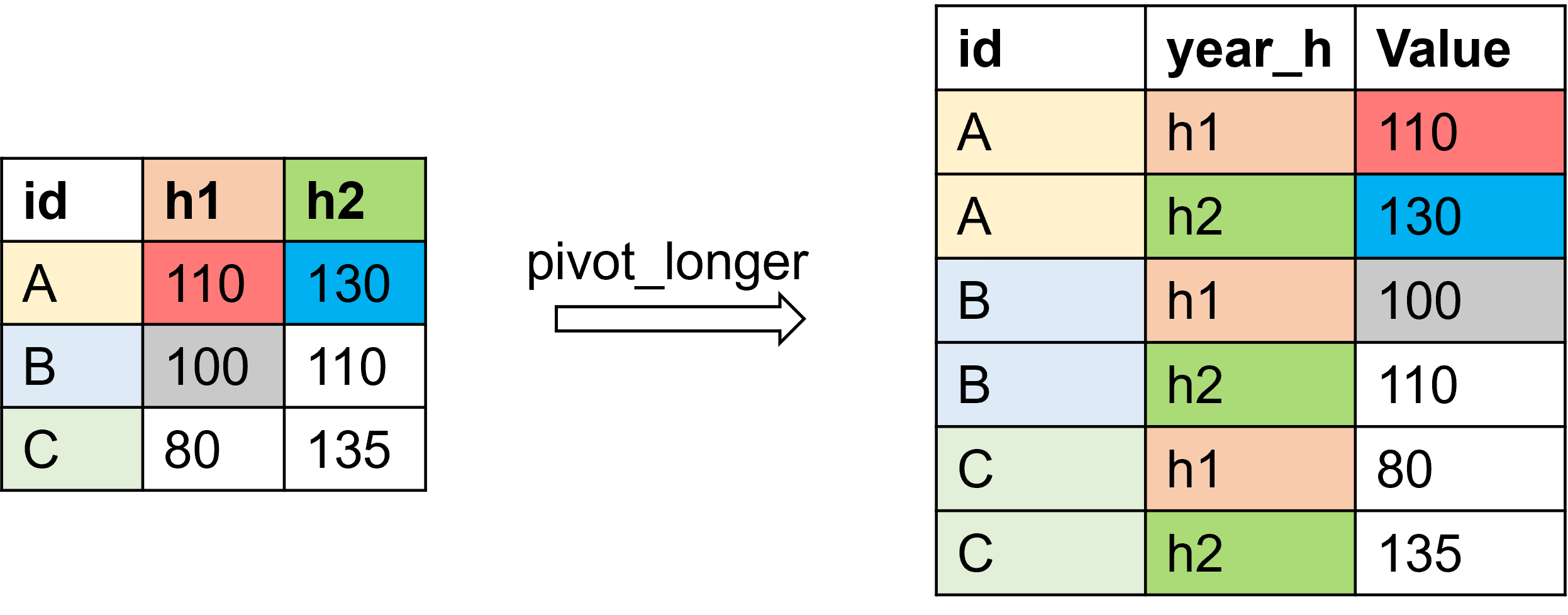
-
已有的列重復了cols參數中列數的次數
-
cols參數中的列名重復了行數的次數
-
cols參數中列的值從上到下從左到右依次進行排列
2.3 列名中包含許多變量的情況
有時列名可能包含許多信息。比如,在who2上可以看到WHO發布的關于結核病診斷的信息:
who2
#> # A tibble: 7,240 × 58
#> country year sp_m_014 sp_m_1524 sp_m_2534 sp_m_3544 sp_m_4554 sp_m_5564
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 Afghanistan 1980 NA NA NA NA NA NA
#> 2 Afghanistan 1981 NA NA NA NA NA NA
#> 3 Afghanistan 1982 NA NA NA NA NA NA
#> 4 Afghanistan 1983 NA NA NA NA NA NA
#> 5 Afghanistan 1984 NA NA NA NA NA NA
#> 6 Afghanistan 1985 NA NA NA NA NA NA
#> 7 Afghanistan 1986 NA NA NA NA NA NA
#> 8 Afghanistan 1987 NA NA NA NA NA NA
#> 9 Afghanistan 1988 NA NA NA NA NA NA
#> 10 Afghanistan 1989 NA NA NA NA NA NA
#> # ? 7,230 more rows
#> # ? 50 more variables: sp_m_65 <dbl>, sp_f_014 <dbl>, sp_f_1524 <dbl>,
#> # sp_f_2534 <dbl>, sp_f_3544 <dbl>, sp_f_4554 <dbl>, sp_f_5564 <dbl>,
#> # sp_f_65 <dbl>, sn_m_014 <dbl>, sn_m_1524 <dbl>, sn_m_2534 <dbl>,
#> # sn_m_3544 <dbl>, sn_m_4554 <dbl>, sn_m_5564 <dbl>, sn_m_65 <dbl>,
#> # sn_f_014 <dbl>, sn_f_1524 <dbl>, sn_f_2534 <dbl>, sn_f_3544 <dbl>,
#> # sn_f_4554 <dbl>, sn_f_5564 <dbl>, sn_f_65 <dbl>, ep_m_014 <dbl>, …
除了country和year列外,剩下56列命名格式統一,由三部分組成分別是診斷方法、性別和年齡范圍,用_分隔。這種情況下記錄了6條消息。我們可以使用pivot_longer將其分開:
who2 |> pivot_longer(cols = !(country:year),names_to = c("diagnosis","gender", "age"),names_sep = "_",values_to = "count")
#> # A tibble: 405,440 × 6
#> country year diagnosis gender age count
#> <chr> <dbl> <chr> <chr> <chr> <dbl>
#> 1 Afghanistan 1980 sp m 014 NA
#> 2 Afghanistan 1980 sp m 1524 NA
#> 3 Afghanistan 1980 sp m 2534 NA
#> 4 Afghanistan 1980 sp m 3544 NA
#> 5 Afghanistan 1980 sp m 4554 NA
#> 6 Afghanistan 1980 sp m 5564 NA
#> 7 Afghanistan 1980 sp m 65 NA
#> 8 Afghanistan 1980 sp f 014 NA
#> 9 Afghanistan 1980 sp f 1524 NA
#> 10 Afghanistan 1980 sp f 2534 NA
#> # ? 405,430 more rows
另外還有一種方法可以替代names_sep就是names_pattern,這需要用到正則表達式來提取變量,我們后續在逐步介紹。
從原理上來看,他是將原來names_to參數使用的列排列完之后,又按照names_sep的規則進行了分列。
2.4 列名同時包含數據和變量
有些更復雜的數據集,其列名同時包含了數據和變量。比如:
household
#> # A tibble: 5 × 5
#> family dob_child1 dob_child2 name_child1 name_child2
#> <int> <date> <date> <chr> <chr>
#> 1 1 1998-11-26 2000-01-29 Susan Jose
#> 2 2 1996-06-22 NA Mark <NA>
#> 3 3 2002-07-11 2004-04-05 Sam Seth
#> 4 4 2004-10-10 2009-08-27 Craig Khai
#> 5 5 2000-12-05 2005-02-28 Parker Gracie
這里記錄了5個家庭數據,其中最多包含兩個孩子的姓名及出生日期。這個數據集的列名中包含了兩個變量的名稱(name和dob),以及另一個變量的值(child的值1或2)。此時想要解決這個問題,names_to會使用特殊的".value"作為值的指示,而不是新列名,這樣會覆蓋掉values_to的參數:
household |> pivot_longer(cols = !family,names_to = c(".value", "child"),names_sep = "_",values_drop_na = TRUE)
#> # A tibble: 9 × 4
#> family child dob name
#> <int> <chr> <date> <chr>
#> 1 1 child1 1998-11-26 Susan
#> 2 1 child2 2000-01-29 Jose
#> 3 2 child1 1996-06-22 Mark
#> 4 3 child1 2002-07-11 Sam
#> 5 3 child2 2004-04-05 Seth
#> 6 4 child1 2004-10-10 Craig
#> 7 4 child2 2009-08-27 Khai
#> 8 5 child1 2000-12-05 Parker
#> 9 5 child2 2005-02-28 Gracie
具體情況就像上面這樣,一目了然。
三、擴寬數據
有時一個觀測值的指標可能分布在多行中,這時我們就可以通過增加列和減少行的方法來擴寬數據集。使用到的函數是pivot_wider。比如下面的數據集:
cms_patient_experience
#> # A tibble: 500 × 5
#> org_pac_id org_nm measure_cd measure_title prf_rate
#> <chr> <chr> <chr> <chr> <dbl>
#> 1 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP… CAHPS for MI… 63
#> 2 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP… CAHPS for MI… 87
#> 3 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP… CAHPS for MI… 86
#> 4 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP… CAHPS for MI… 57
#> 5 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP… CAHPS for MI… 85
#> 6 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP… CAHPS for MI… 24
#> 7 0446162697 ASSOCIATION OF UNIVERSITY PHYSI… CAHPS_GRP… CAHPS for MI… 59
#> 8 0446162697 ASSOCIATION OF UNIVERSITY PHYSI… CAHPS_GRP… CAHPS for MI… 85
#> 9 0446162697 ASSOCIATION OF UNIVERSITY PHYSI… CAHPS_GRP… CAHPS for MI… 83
#> 10 0446162697 ASSOCIATION OF UNIVERSITY PHYSI… CAHPS_GRP… CAHPS for MI… 63
#> # ? 490 more rows
該數據集研究的目標是一個組織,但是每個組織的數據被分布在了6行中,調查組織中的每個測量值各占一行。我們可以看到:
cms_patient_experience |> distinct(measure_cd, measure_title)
#> # A tibble: 6 × 2
#> measure_cd measure_title
#> <chr> <chr>
#> 1 CAHPS_GRP_1 CAHPS for MIPS SSM: Getting Timely Care, Appointments, and Infor…
#> 2 CAHPS_GRP_2 CAHPS for MIPS SSM: How Well Providers Communicate
#> 3 CAHPS_GRP_3 CAHPS for MIPS SSM: Patient's Rating of Provider
#> 4 CAHPS_GRP_5 CAHPS for MIPS SSM: Health Promotion and Education
#> 5 CAHPS_GRP_8 CAHPS for MIPS SSM: Courteous and Helpful Office Staff
#> 6 CAHPS_GRP_12 CAHPS for MIPS SSM: Stewardship of Patient Resources
這兩列都不是很好的變量名,其中measure_cd并沒有按時變量的含義,measure_tittle也只是包含一個長句子。現在,讓我們使用measure_cd列作為我們新列名的源。創建一個新的數據集:
cms_patient_experience |> pivot_wider(names_from = measure_cd,values_from = prf_rate)
#> # A tibble: 500 × 9
#> org_pac_id org_nm measure_title CAHPS_GRP_1 CAHPS_GRP_2 CAHPS_GRP_3
#> <chr> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 0446157747 USC CARE MEDICA… CAHPS for MI… 63 NA NA
#> 2 0446157747 USC CARE MEDICA… CAHPS for MI… NA 87 NA
#> 3 0446157747 USC CARE MEDICA… CAHPS for MI… NA NA 86
#> 4 0446157747 USC CARE MEDICA… CAHPS for MI… NA NA NA
#> 5 0446157747 USC CARE MEDICA… CAHPS for MI… NA NA NA
#> 6 0446157747 USC CARE MEDICA… CAHPS for MI… NA NA NA
#> 7 0446162697 ASSOCIATION OF … CAHPS for MI… 59 NA NA
#> 8 0446162697 ASSOCIATION OF … CAHPS for MI… NA 85 NA
#> 9 0446162697 ASSOCIATION OF … CAHPS for MI… NA NA 83
#> 10 0446162697 ASSOCIATION OF … CAHPS for MI… NA NA NA
#> # ? 490 more rows
#> # ? 3 more variables: CAHPS_GRP_5 <dbl>, CAHPS_GRP_8 <dbl>, CAHPS_GRP_12 <dbl>
不過現在看來,我們依然為每個組織設置了多行,這是因為我們并未給出哪一列具有唯一標識,可以這樣給出:
cms_patient_experience |> pivot_wider(id_cols = starts_with("org"),names_from = measure_cd,values_from = prf_rate)
#> # A tibble: 95 × 8
#> org_pac_id org_nm CAHPS_GRP_1 CAHPS_GRP_2 CAHPS_GRP_3 CAHPS_GRP_5 CAHPS_GRP_8
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 0446157747 USC C… 63 87 86 57 85
#> 2 0446162697 ASSOC… 59 85 83 63 88
#> 3 0547164295 BEAVE… 49 NA 75 44 73
#> 4 0749333730 CAPE … 67 84 85 65 82
#> 5 0840104360 ALLIA… 66 87 87 64 87
#> 6 0840109864 REX H… 73 87 84 67 91
#> 7 0840513552 SCL H… 58 83 76 58 78
#> 8 0941545784 GRITM… 46 86 81 54 NA
#> 9 1052612785 COMMU… 65 84 80 58 87
#> 10 1254237779 OUR L… 61 NA NA 65 NA
#> # ? 85 more rows
#> # ? 1 more variable: CAHPS_GRP_12 <dbl>
3.1 pivot_wider的處理原理
我們還是舉個前面類似的簡單例子來探究處理原理:
df <- tribble(~id, ~year_h, ~value,"A", "h1", 100,"B", "h1", 90,"A", "h2", 130,"B", "h2", 110,"A", "h3", 132
)
使用pivot_wider時將會從value列中獲取值,從year_h列中獲取新列名:
df |>
pivot_wider(names_from = year_h,values_from = value
)
#> # A tibble: 2 × 4
#> id h1 h2 h3
#> <chr> <dbl> <dbl> <dbl>
#> 1 A 100 130 132
#> 2 B 90 110 NA
這個過程是怎么樣的呢?首先pivot_wider()會弄清楚行和列中的內容,新列名就是year_h列中的唯一值:
df |> distinct(year_h) |> pull()
#> [1] "h1" "h2" "h3"
默認情況下,輸出的行由所有不進入新名稱或者值得變量確定,它們會被認作是id.cols,這個數據集只有一列,但通常可以有多列,也可以自行指定。
df |> select(-year_h, -value) |> distinct()
#> # A tibble: 2 × 1
#> id
#> <chr>
#> 1 A
#> 2 B
然后pivot_wider會將這些結果組合起來生成一個用NA填充的空數據:
df |> select(-year_h, -value) |> distinct() |> mutate(h1 = NA, h2 = NA, h3 = NA)
#> # A tibble: 2 × 4
#> id h1 h2 h3
#> <chr> <lgl> <lgl> <lgl>
#> 1 A NA NA NA
#> 2 B NA NA NA
最后,pivot_wider會使用輸入的數據來填充相應的位置。
如果存在多行對應一個輸出的單元格會發生什么情況呢?此時在輸出的數據中將會存在列內列表的結構:
df <- tribble(~id, ~year_h, ~value,"A", "h1", 100,"A", "h1", 90,"A", "h2", 130,"B", "h1", 110,"B", "h2", 132
)df |> pivot_wider(names_from = year_h,values_from = value)
#> Warning: Values from `value` are not uniquely identified; output will contain list-cols.
#> ? Use `values_fn = list` to suppress this warning.
#> ? Use `values_fn = {summary_fun}` to summarise duplicates.
#> ? Use the following dplyr code to identify duplicates.
#> {data} %>%
#> dplyr::group_by(id, year_h) %>%
#> dplyr::summarise(n = dplyr::n(), .groups = "drop") %>%
#> dplyr::filter(n > 1L)
#> # A tibble: 2 × 3
#> id h1 h2
#> <chr> <list> <list>
#> 1 A <dbl [2]> <dbl [1]>
#> 2 B <dbl [1]> <dbl [1]>
可以通過警告信息中的提示來檢查可能存在的問題:
df |> dplyr::group_by(id, year_h) |> dplyr::summarise(n = dplyr::n(), .groups = "drop") |> dplyr::filter(n > 1L)
#> # A tibble: 1 × 3
#> id year_h n
#> <chr> <chr> <int>
#> 1 A h1 2
總結
至此,我們快速學完了數據分析的全過程基礎,已經可以應付很多的數據處理情況了。在這一節的學習中,我們學了數據的整理,這將幫助我們獲得整潔的數據。另外,我們還學到了一些擴充數據的技巧,熟練掌握這些函數的使用將在我們以后實際遇到對應情況時,快速想到相應的解決措施。我們所有學習到的知識都應該在實踐中將他們運用起來。(碎碎念:這幾天雖然還在家房價,但都在幫老板干活,五天開了三次會,真累啊。但是學無止境,每天還是要完成一定的學習任務的。話說老板出差為什么不能帶上我去玩呢?)
這個系列還未結束,后續將會就這些步驟展開更加詳細的進階介紹。


![[云原生] 二進制k8s集群(下)部署高可用master節點](http://pic.xiahunao.cn/[云原生] 二進制k8s集群(下)部署高可用master節點)











)

)


