目錄
前言
一、GeoHash 的編碼方法
二、Redis 操作GEO類型
前言
我們有一個需求是用戶搜索附近的店鋪,就是所謂的位置信息服務(Location-Based Service,LBS)的應用。這樣的相關服務我們每天都在接觸,用滴滴打車,中午去美團訂外賣等等。當我們用這些服務方便我們的生活的時候,大家有沒有想過是怎么實現的。目前市場上很多軟件比如Es,Redis 都提供了類似的功能,他們底層都是用的GeoHash 編碼,只不過底層的數據結構不同。今天主要講的是Redis 的 Geo 如何實現這個功能
一、GeoHash 的編碼方法
Redis 常用的數據類型有String(字符串)、List(列表)、Hash(哈希)、Set(集合)和 Sorted Set(有序集合)。位置信息存儲一定是key,value,value 就是經緯度。用List、Hash,Set 去存儲,沒有辦法去排序,當然也是不可以的。最接近的數據結構是Sorted Set,可以根據score 排序同時也滿足范圍獲取。又有一個問題是 score 是 float 類型的,經緯度不是的,好像也不可以,能不能用一種編碼把經緯度變成float 類型的,這種編碼就是GeoHash。
為了能高效地對經緯度進行比較,Redis 采用了業界廣泛使用的 GeoHash 編碼方法,這個方法的基本原理就是“二分區間,區間編碼”。當我們用GeoHash編碼時,我們要先對經度和維度分別編碼,然后再把經緯度各自的編碼組合成一個最終編碼。
我們看看經緯度的編碼過程。
對于一個定理信息來說,它的經度范圍是[-180,180],緯度范圍是[-90,90]。GeoHash編碼會把經,緯度做N次二分區操作,其中N是自定義的。
先拿經度來說,范圍是[-180,180]會被分成兩個子區間:【-180,0)和【0,180】(我稱為左右分區)。此時我們要看下經度是落在左右哪個分區上,落在左分區用0表示,又分區用1 表示。第二次在把落在的分區又分成左右兩個分布,在看下經度是落在哪個分區上,落在左分區用0表示,又分區用1 表示。依次類推,只要分成了N份結束了。最終得到的是N bit 的位數,例如10111 這樣的數據。
緯度也是同樣的,只不過,緯度的范圍是【-90,90】。每次也是平均分成左右兩個分區,落在左分區用0表示,又分區用1 表示。最終得到的也是N bit 的位數,例如10110 這樣的數據。
最終得倒的是2個N bit 的位數,最終進行組合。組合規則是第 0 位是經度的第 0 位 1,第 1 位是緯度的第 0 位 1,第 2 位是經度的第 1 位 1,第 3 位是緯度的第 1 位 0。
下面我們會舉一個例子,來闡述算法具體的實現:經度值 116.37,緯度值 39.86, N是5。
經度分區過程 116.37:
| 分區次數 | 左分區 | 右分區 | 經度116.37所在的分區 | 編碼 |
|---|---|---|---|---|
| 1 | 【-180,0) | [0,180] | [0,180] | 1 |
| 2 | [0,90) | [90,180] | [90,180] | 1 |
| 3 | [90,135) | [135,180] | [90,135) | 0 |
| 4 | [90,112.5) | [112.5,135] | [112.5,135] | 1 |
| 5 | [112.5,123.75) | [123.75,135] | [112.5,123.75) | 0 |
最終編碼是11010
緯度的編碼過程是 39.86
| 分區次數 | 左分區 | 右分區 | 緯度 39.86所在的分區 | 編碼 |
|---|---|---|---|---|
| 1 | 【-90,0) | 【0,90] | 【0,90] | 1 |
| 2 | [0,45) | [45,90] | [45,90] | 0 |
| 3 | [0,22.5) | [22.5,45] | [22.5,45] | 1 |
| 4 | [22.5,33.75) | [33.75,45] | [33.75,45] | 1 |
| 5 | [33.75,39.375) | [39.375.45] | [39.375,45] | 1 |
最終編碼是 10111
GeoHash最終編碼是,回顧編碼規則:組合規則是第 0 位是經度的第 0 位 1,第 1 位是緯度的第 0 位 1,第 2 位是經度的第 1 位 1,第 3 位是緯度的第 1 位 0
| 經度編碼 | 1 | 1 | 0 | 1 | 0 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| 奇偶數(位數) | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 緯度編碼 | 1 | 0 | 1 | 1 | 1 |
經度編碼和緯度編碼合并:一共是10位數, 1110011101,位數不要錯了,這個最終就是 Sorted Set 的 sort 值了。
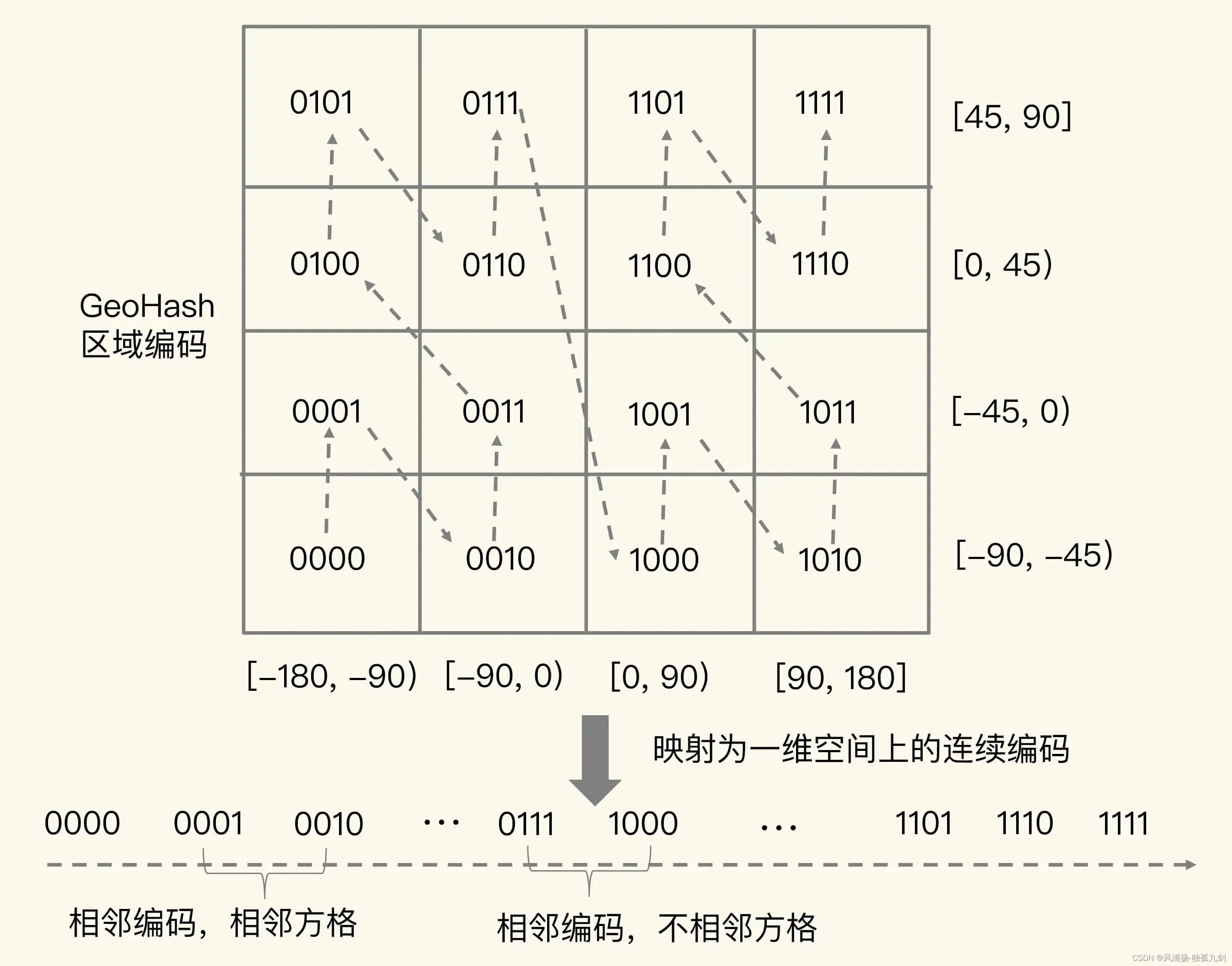
當然,使用 GeoHash 編碼后,我們相當于把整個地理空間劃分成了一個個方格,每個方格對應了 GeoHash 中的一個分區。舉個例子。我們把經度區間[-180,180]做一次二分區,把緯度區間[-90,90]做一次二分區,就會得到 4 個分區。我們來看下它們的經度和緯度范圍以及對應的 GeoHash 組合編碼。分區一:[-180,0) 和[-90,0),編碼 00;分區二:[-180,0) 和[0,90],編碼 01;分區三:[0,180]和[-90,0),編碼 10;分區四:[0,180]和[0,90],編碼 11。
這 4 個分區對應了 4 個方格,每個方格覆蓋了一定范圍內的經緯度值,分區越多,每個方格能覆蓋到的地理空間就越小,也就越精準。我們把所有方格的編碼值映射到一維空間時,相鄰方格的 GeoHash 編碼值基本也是接近的,如下圖所示:

所以,我們使用 Sorted Set 范圍查詢得到的相近編碼值,在實際的地理空間上,也是相鄰的方格,這就可以實現 LBS 應用“搜索附近的人或物”的功能了。不過,我要提醒你一句,有的編碼值雖然在大小上接近,但實際對應的方格卻距離比較遠。例如,我們用 4 位來做 GeoHash 編碼,把經度區間[-180,180]和緯度區間[-90,90]各分成了 4 個分區,一共 16 個分區,對應了 16 個方格。編碼值為 0111 和 1000 的兩個方格就離得比較遠,如下圖所示:
二、Redis 操作GEO類型
在使用 GEO 類型時,我們經常會用到兩個命令,分別是 GEOADD 和 GEORADIUS。
GEOADD 命令:用于把一組經緯度信息和相對應的一個 ID 記錄到 GEO 類型集合中;
GEORADIUS 命令:會根據輸入的經緯度位置,查找以這個經緯度為中心的一定范圍內的其他元素。當然,我們可以自己定義這個范圍。
操作如下:

GEOADD 如果member 沒有就增加,有就是修改,用 GEOPOS cars:locations 33 可以看到每個member 具體的經緯度
GEORADIUS 可以根據坐標找到相應的member。命令的詳解可以看官網文檔 GEORADIUS | Redis
非常感謝 蔣德鈞的《Redis 核心技術與實戰》以及 redis 官網提供了非常寶貴的資料




)





)








)