目標:了解字符集的概念,掌握MySQL數據庫存儲數據的字符集邏輯以及設置方式
-
字符集概念
-
MySQL字符集關系
-
解決亂碼問題
-
字符集設置原理
1、字符集概念
目標:了解字符集概念,掌握字符集存儲和讀取的實現原理
概念
字符集:charset或者character set,是各種文字和符號在計算機中的總稱
-
字符集根據不同國家的符號不同,有不同的字符集
-
不同的字符集占用的存儲空間不一樣,存儲的底層也不一樣
-
不同字符集之間可以進行轉換
-
常見字符集
-
ASCI:美國信息交換標準碼,工般英文符號,一個字節存儲
-
latin1:拉丁文字符集,一個字節存儲,ISO-8859-1的別名,能夠向下兼容ASCII
-
GB2312:信息交換用漢字編碼字符集,是中國1981年的一套國標規范,2個字節存儲
-
GBK:漢字內碼擴展規范(1995年),兩個字節表示表示(漢字很多超過5000個)
-
Unicode:萬國碼(統一碼),使用統一的編碼方式來解決傳統的局限,1994年出現
-
UTE-8:8-bit Unicode Transformation Format(萬國碼),針對Unicode的可變長度字符編碼,采用1-6個字
節編碼Unicode字符(目前通用編碼規則)。建議使用UTE-8字符集進行數據存儲
-
演示
ASCII碼表(單字節存儲:1 byke = 8 bits)

原理流程圖
1、數據存儲
graph LR
A(輸入符號<br>A)-->B[計算機存儲]
B-->C{字符集選擇}
C-->|ASCII|D[轉碼<br>01000001]C-->|GBK|E[轉碼<br>0000000001000001]
C-->|ASCII 存儲中文|G[轉碼<br>亂碼]
D-->F((存儲))
E-->F
G-->F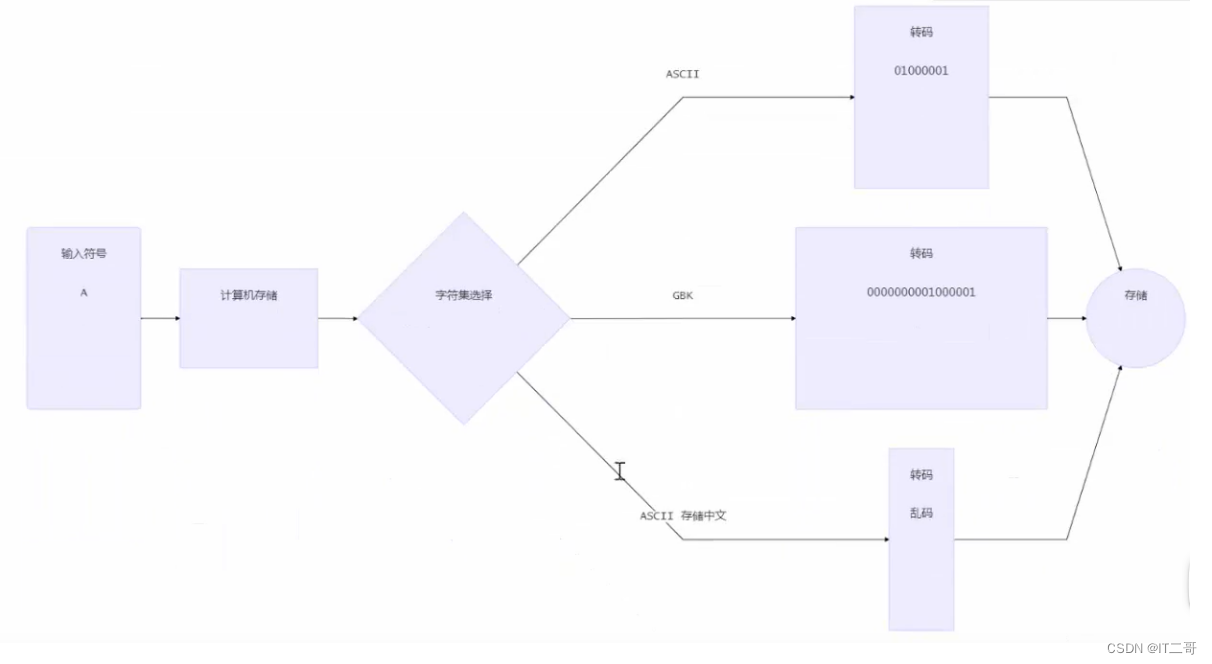
2、數據讀取
graph LR
A(數據讀取)-->B{字符集選擇}
B-->ASCII|C[讀1個字節<br>01000001]
B-->|GBK|D[讀2個字節<br>0000000001000001]
B-->|UTF-8|G[讀3個字節<br>錯誤讀取]
G-->H[解析<br>亂碼]
C-->E[解析<br>A]
D-->E
E-->F((輸出))
H-->F
小結
1、字符集是一套符號的總稱
2、不同國家地區的符號有區別,所以有自己的字符集
3、常見的字符集目前是三個
-
ASClI:美國信息交換標準碼
-
GBK:漢字內碼擴展規范(國標),兼容ASCII
-
UTF-8:8字節萬國碼,兼容GBK和ASCIl
4、目前基本都統一使用UTF-8開發和數據存儲
5、字符集是指定字符的存儲和讀取的規范
-
指定的字符集存儲需要使用對應的字符集讀取
-
錯誤的字符集存儲或者讀取都會產生亂碼
2、MySQL字符集
目標:了解MySQL中字符集的實現原理,掌握數據最終的存儲字符集
概念
MySQL字符集:MySQL內部對于數據實際存儲的字符集(服務器端)
-
MySQL內部對象可以在各個層級設置字符集
-
MySQL內部隊形存在字符集繼承:字段->表->數據庫->DBMS
-
MySQL內部內嵌支持幾乎所有主流字符集
-
數據存儲的最終字符集由字段控制
-
客戶端與服務器進行交互時,需要明確告知服務器客戶端自己的字符集(數據格式)
演示
查看MySQL支持的所有字符集
show charset;結果

原理圖
1、數據庫內部對象字符集原理
graph TB
A(服務器數據管理)-->B[DBMS系統<br>安裝配置字符集]
B-->C[數據庫<br>設定字符集]
C-->|繼承DBMS字符集|B
C-->D[數據表<br>設定字符集]
D-->|繼承數據庫字符集|C
D-->E[數據字段<br>設定字符集]
E-->|繼承數據表字符集|D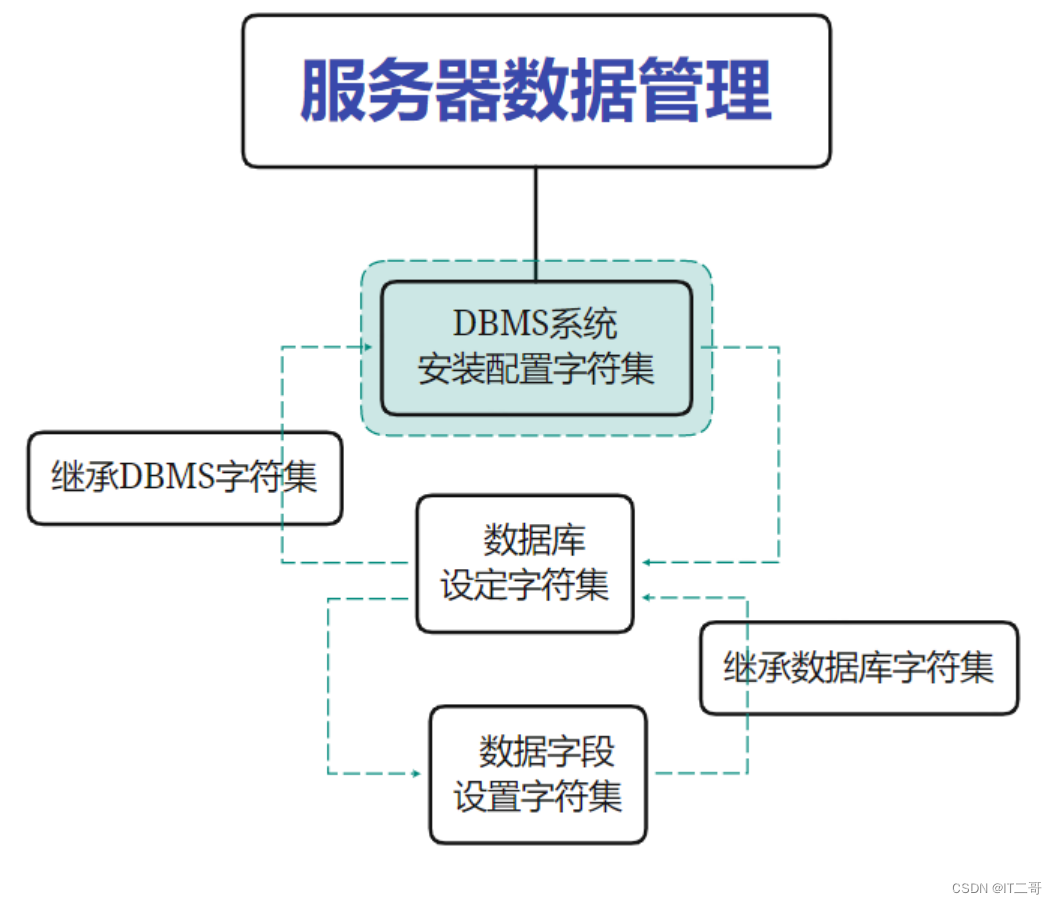
1.1、服務端存儲的數據最終字符集由字段確定
1.2、字段通常不會設置字符集,繼承表的字符集
1.3、數據存儲的字符集與客戶端的字符集沒有直接關系,是由表(字段)決定
小結 1、MySQL服務端數據存儲的字符集依賴各個對象設置
-
DBMS:設置最廣,一旦設置所有對象都可以依賴,但是優先級最低
-
DB:針對數據庫內的所有表,優先級高于DBMS,可以繼承DBMS(一般在數據庫層設置)
-
Table:針對當前表的設置,優先級高于DB,可以繼承DB
-
Field:針對當前字段設置,優先級高于Table,可以繼承Table,優先級最高2
2、通常字符集的設置都是圍繞數據表(現在都在數據庫層),不會到具體字段
3、建議使用UTE-8字符集存儲數據(MySQL8以后建議使用UTF8MB4)
4、MySQL服務端支持各種字符集,并且能夠進行各種字符集轉換
5、客戶端存儲數據到服務端原理
-
客戶端告知服務端客戶端的字符集
-
服務端按照客戶端指定的字符集接收數據(如果沒有指定,使用默認,可能出現亂碼)
-
服務端按照實際存儲表對應的字符集進行轉換
-
服務端存儲數據
6、客戶端讀取服務端數據原理
-
客戶端告知服務端客戶端的字符集
-
服務端按照客戶指定的指令從數據庫讀取原始字符集數據
-
服務端按照客戶端的需求將數據進行字符轉換
-
服務端發送目標數據給客戶端
-
客戶端按照自己的字符集進行解析
3、亂碼問題解決
目標:了解亂碼發生的原因,實現亂碼問題的解決方案
概念
亂碼:指數據不能按照正確的字符集進行存儲或者解析。
-
亂碼原因1:數據在存儲的時候已經變成亂碼
-
客戶端字符集與服務端解析字符集不一致
-
讀取時想轉成其他字符集均會錯誤
-
-
亂碼原因2:數據存儲時正確,但是讀取時解析成錯誤字符集
-
客戶端能解析的字符集與服務器提供的字符集不一致
-
-
亂碼解決方案:不論存儲還是讀取,都提前告知服務器當前客戶端的字符集
set names 客戶端字符集;演示
1、MySQL客戶端(CMD打開),客戶端字符集是固定的GBK
set names gbk;流程圖
graph TB
A(客戶端連接認證服務端)-->B[設定字符集<br>告知服務端當前客戶端的字符集]
B-->C[其他操作<br>內部字符集轉換不用管]
C-->D((結束))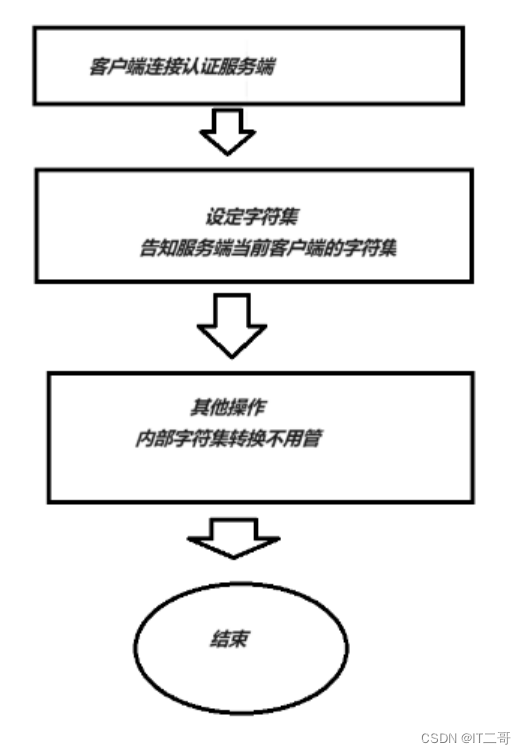
小結
1、亂碼的本質原因就是客戶端與服務端的字符集不一致導致
-
客戶端存儲數據的時候服務端沒有正確理解(服務端按照默認的存儲,存儲的就是亂碼)
-
客戶端讀取的時候沒有正確告知服務端(服務端按照默認的提供)
2、解決亂碼問題的方案:保證服務端正確理解客戶端的字符集
-
setnames 客戶端字符集
-
在任何數據操作之前(尤其是寫數據)
4、字符集設置原理
目標:了解set names字符集的本質原理
概念
字符集設置原理:服務器端正確保障對客戶端的數據識別
-
MySQL服務端提供了變量來記錄客戶端的字符集
-
MySQL對應的存儲字符集的變量可以修改
-
set names 字符集就是對變量的修改,總共有三個
-
character_set_client:客戶端提供的數據的字符集
-
character_set_results:客戶端需要服務端提供的數據的字符集
-
character_set_connection:連接使用的字符集,內部數據操作
-
演示
1、查看系統內部存儲這些記錄字符集的信息
show variables like 'character_set%'; ? #%表示通配符,匹配后續所有不確定的數據2、修改客戶端字符集變量,保證數據正常存進服務端
set character_set_client = gbk;3、修改客戶端解析字符集變量,保證數據正常被客戶端查看
set character_set_results = gbk;4、使用set names 字符集批量修改,保證客戶端被服務端正確理解,同時客戶端也能正確解析
set names gbk;小結
1、MySQL字符集控制是在服務端內部通過變量連接(針對每個獨立的客戶端)
2、set names字符集是一種快捷方式,本質有三個變量被修改
-
character_set_client:服務端接收客戶端數據
-
character_set_connection:服務端內部連接使用
-
character_set_results:服務端提供數據給客戶端
3、通常我們都是使用set names字符集來進行統一設置,而且是在建立連接之后操作數據之前就設置
5、總結
1、字符集是所有編程語言里都必須面對的首要問題,必須在一開始就選擇好字符集(去到企業后先問清楚)
-
業務針對的符號
-
業務針對的范圍
2、亂碼是編程中最基礎要解決的問題,一旦數據產生了亂碼,通常是不可逆操作
3、解決亂碼問題其實本質就是統一字符集問題
-
客戶端字符集:character_set_client
-
連接層字符集:character_set_connection
-
結果集字符集:`character_set_results
-
簡單統一方式:set names 客戶端字符集
-
存儲字符集:不用考慮,因為數據庫有強大的字符集轉換能力,只要在開始設置好,保證后續數據不會超出字符集即可
二、校對集
目標:了解校對集的概念以及校對集在校對時的作用
概念
校對集:collate/collation,即數據比較時對應的規則
-
校對集依賴字符集
-
校對集的校對方式分為三種
-
大小寫不敏感:ci,case insensitive(不區分大小寫)
-
大小寫敏感:cs,case sensitive(區分大小寫)
-
二進制比較: bin(區分大小寫)
-
-
校對集是在進行數據比較的時候觸發
演示
1、_cì,大小寫不敏感
A 與 a 是相同的,不存在誰大誰小(系統會轉換成一種)2、_cs,大小寫敏感
A 與 a有大小關系,所以不同(存儲數值)3、_bin,二進制比較
A的二進制是01000001
a的二進制是01100001
二進制按位比較,所以不同小結
1、校對集是數據比較的規則
-
校對集依賴字符集存在
-
每個字符集有多種校對規則
2、校對規則一共有三種
-
_ci:大小寫不敏感,不區分大小寫
-
_cs:大小寫敏感,區分大小寫
-
_bin:二進制比較(區分大小寫)
1、校對集設置
目標:了解MySQL中校對集的設計方式以及規則查看
概念
校對集設置:在創建數據表的時候創建校對規則
-
校對規則可以在MySQL四層對象設計
-
DBMS:系統配置
-
DB:數據庫指定(庫選項)
-
Table:表指定(表選項)
-
Field:字段指定(字段選項,一般不用)
-
-
校對集從Field到DBMS繼承;優先級Field最高。
-
每個校對集都有字符集對應的默認規則
-
校對集設置語法
co11ate 校對集規則;
演示
1、查看MySQL支持的所有校對集
show co1lation;2、在數據庫層設計校對集(常見)
create database db_4 charset utf8mb4 collate utf8mb4_bin;3、在數據表層設計校對集
create table t_4(id int,name varchar(10)
)charset utf8mb4 collate utf8mb4_bin;4、在字段層設計校對集(一般不常用)
create table t_5(id int,name varchar(10) collate utf8mb4_bin
)charset utf8mb4;小結
1、MySQL中四層對象都可以設置校對集
-
DBMS:配置文件
-
DB:創建數據庫時限定(設置)
-
Table:創建表示限定
-
Field:創建字段時限定
2、校對集從Field到DBMS實現繼承
3、校對集依賴字符集,且每個字符集都有默認的校對集(一般情況不需要設置)
2、校對集應用
目標:了解不同校對集的實際校對原理,掌握校對規則的應用場景
概念
校對集應用:觸發校對規則的使用
-
校對集的應用通常是通過數據比較觸發:order by 字段
-
數據表中數據一旦產生,校對集的修改就無效
演示
1、創建校對規則數據表并插入數據
# 創建默認校對規則表(不區分大小寫)
create table t_4(name varchar(1)
)charset utf8mb4;
insert into t_4 value('B');
insert into t_4 values('A');
insert into t_4 values('b');
insert into t_4 values('a');#創建二進制校對規則(區分大小寫)
create table t_5(name varchar(1)
)charset utf8mb4 collate utf8mb4_bin;
insert into t_5 values('B');
insert into t_5 values('A');
insert into t_5 values('b');
insert into t_5 values('a');2、觸發校對:排序 order by
select *from t_4 order by name;#升序
select *from t_5 order by name;3、數據已經存在的表重新修改校對規則無效
alter table t_5 collate utf8mb4_general_ci: 小結
1、校對集的應用不是主動觸發,而是通過數據比較自動觸發
2、校對集對應的數據一旦產生,那么就不可以修改數據表的校對規則
3、校對集通常使用字符集默認校對集,如果需要進行額外的比較應用(通常是區分大小寫),那么需要在建表的時候設定好目標校對規則
3、總結
1、校對集是數據比較的標準
2、校對集的校對規則都是依賴字符集存在的,不外乎三種規則
-
_ci:不區分大小寫
-
_cs:區分大小寫
-
_bin:二進制比較(區分大小寫)
3、校對集的觸發是自動的,只要數據在進行比較的時候就會自動觸發設定的校對規則
-
校對集的維護要在數據產生之前
-
數據產生之后校對集的修改將無效
4、在進行數據表設計之前,要提前了解數據后續可能產生的比較形態,選擇好合適的校對規則(一般都默認不區分大小寫)
【Jmeter】線程(Threads(Users))之setUp 線程組)















(判斷年、月、日是否合法,判斷打魚還是曬網,判斷星座))
)

獲取用戶唯一標識openid和unionid)