文章目錄
- 往期
- 效果
- 將文章信息導出
- 適配 hexo 的文章模板
- 導出的文章路徑問題
- 終端控制執行腳本
- 代碼整理
- 結尾
往期
- Puppeteer 使用實戰:如何將自己的 CSDN 專欄文章導出并用于 Hexo 博客(二)
效果
-
寫了一個
node腳本用來批量處理md文件 -
本期用的基本上是
node
-
添加終端控制
將文章信息導出
首先在爬取專欄頁數的時候就收集好了信息,我們把信息導出到外部 json
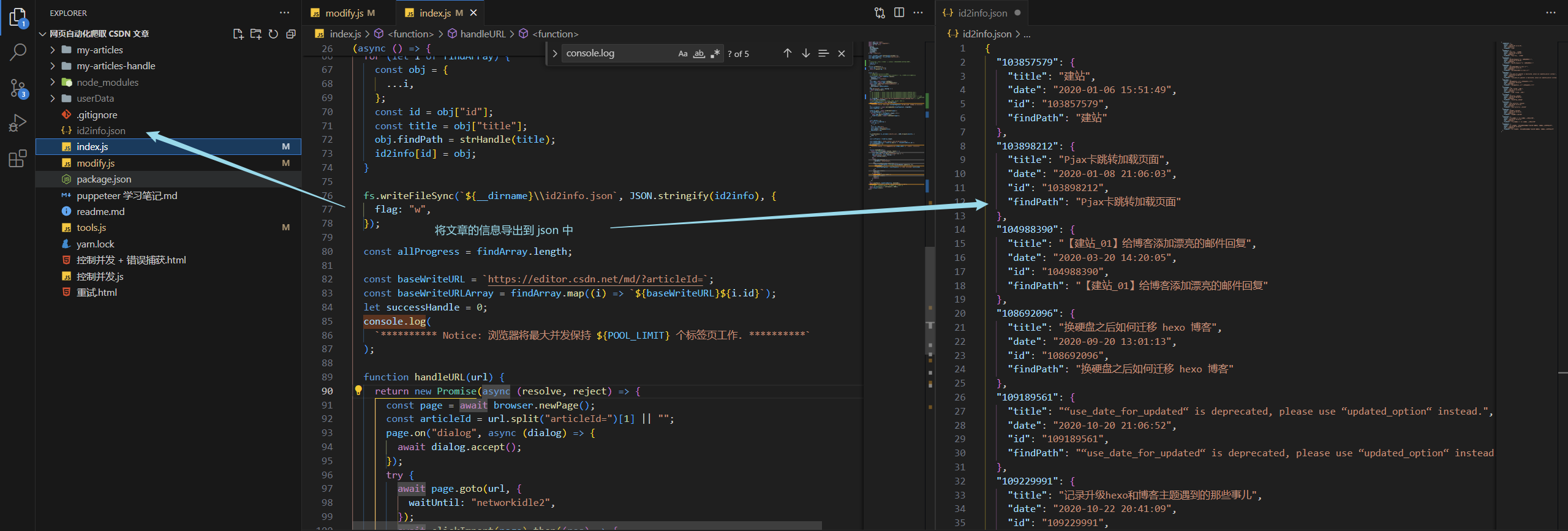
然后再腳本里引入 ,就可以使用這個 json 了
const id2info = JSON.parse(await fs.readFileSync(`${__dirname}\\id2info.json`, "utf-8")
);
適配 hexo 的文章模板
我們可以看到 hexo 的每一個 page 是有一些配置的,我也想給導出的這些文章批量設置一下
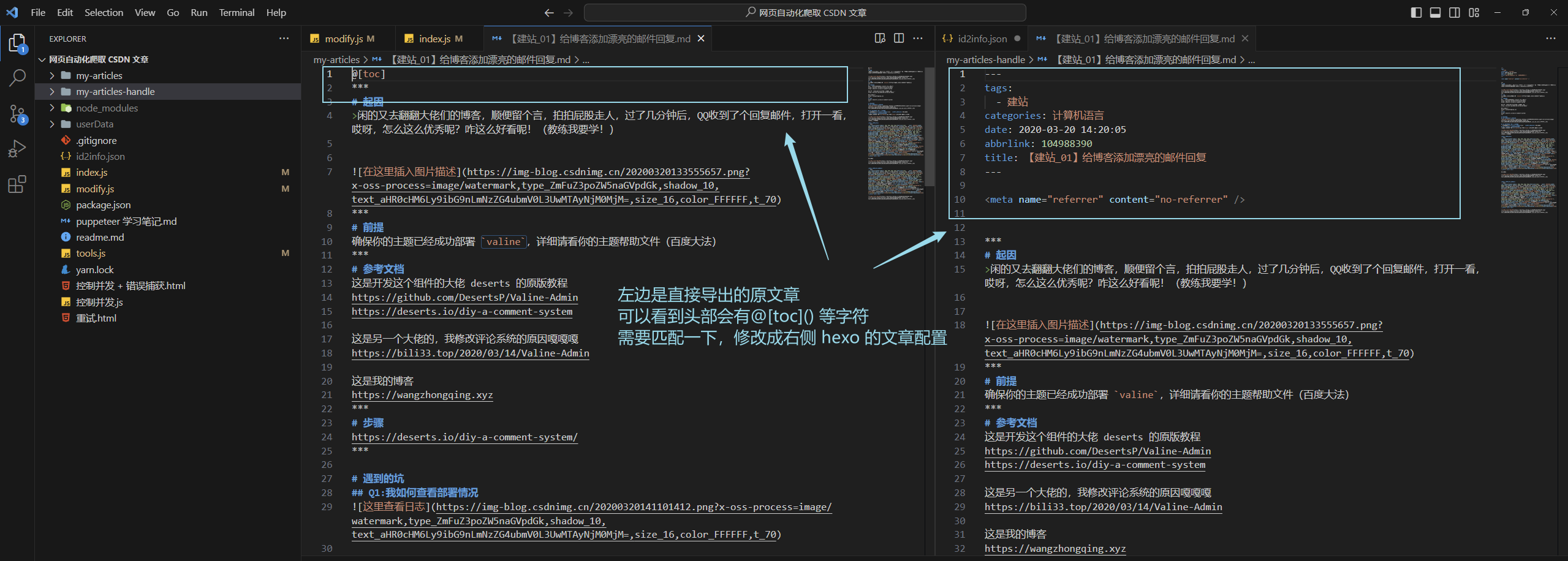
觀察一下導出的文件,可以得出一些規律
- 文章開頭有
@toc[]或者@toc[](文字),然而hexo并不支持,需要替換掉 - 有些文章沒有這些,就可以在內容開頭直接添加即可
這里我是使用正則直接匹配分割
const reg = /\@\[toc\]\(.*?\)|\@\[toc\]/i;
// ....
const content = fs.readFileSync(eachArticlePath, "utf8");
/*** 拼接文章內容:文章分兩種情況* - 一種是頭部有 @[toc]()之類的* - 另一種是什么都沒有的*/
if (content.match(reg) !== null) {const splitContent = content.split(reg)[1];afterContent = `${replaceContent}\n${splitContent}`;
} else {afterContent = `${replaceContent}\n${content}`;
}
導出的文章路徑問題
通過 csdn 導出的文章,如果 title 中有一些特殊符號的,那么導出的時候會幫你替換成 _,因為 Windows 中不允許特殊字符在路徑中

為了不改變之前的 title,我又寫了一個 filePath 專門用來讀文章

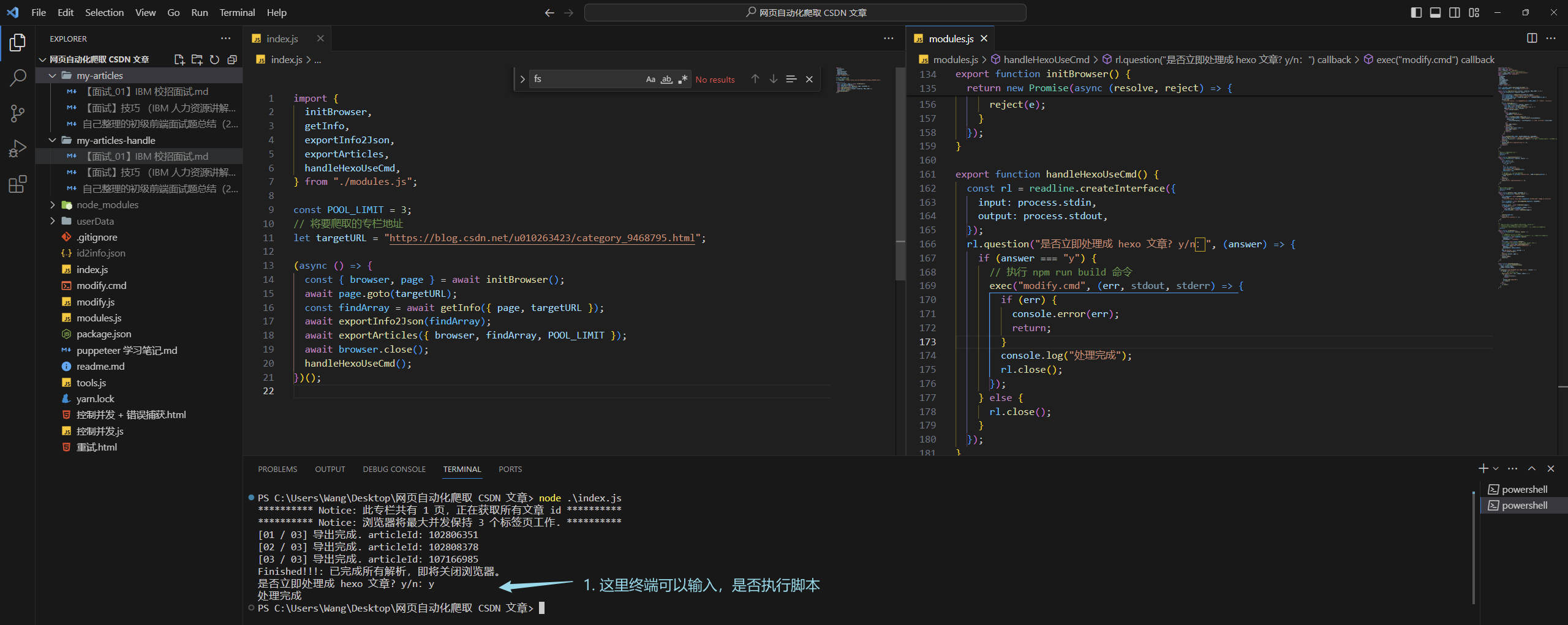
終端控制執行腳本
這里寫了個終端的函數,如果選擇 y,那么就執行腳本
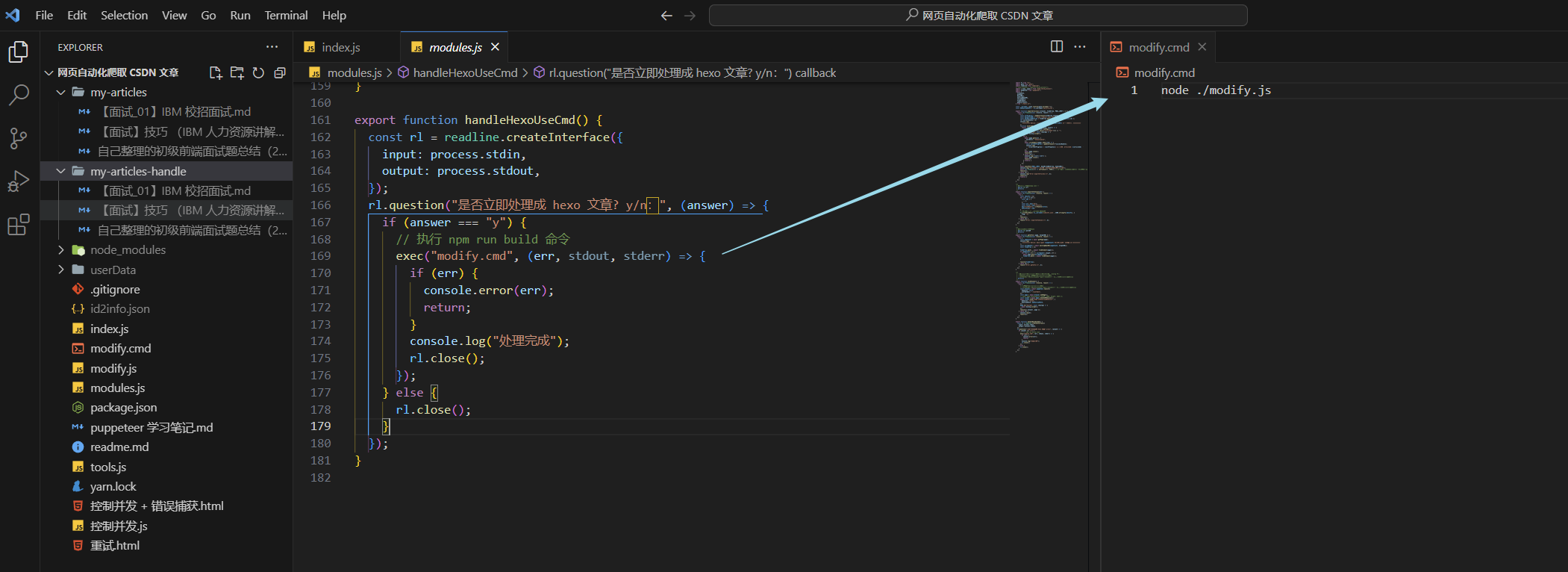
需要引入 readline 以及 exec ,簡單的使用邏輯可以看一下我寫的:
import readline from "readline";
import { exec } from "node:child_process";
// ...
const rl = readline.createInterface({input: process.stdin,output: process.stdout,
});
rl.question("是否立即處理成 hexo 文章? y/n:", (answer) => {if (answer === "y") {// 執行 npm run build 命令exec("modify.cmd", (err, stdout, stderr) => {if (err) {console.error(err);return;}console.log("處理完成");rl.close();});} else {rl.close();}
});
其中的 cmd 命令很簡單,就是 node 腳本.js 即可運行
代碼整理
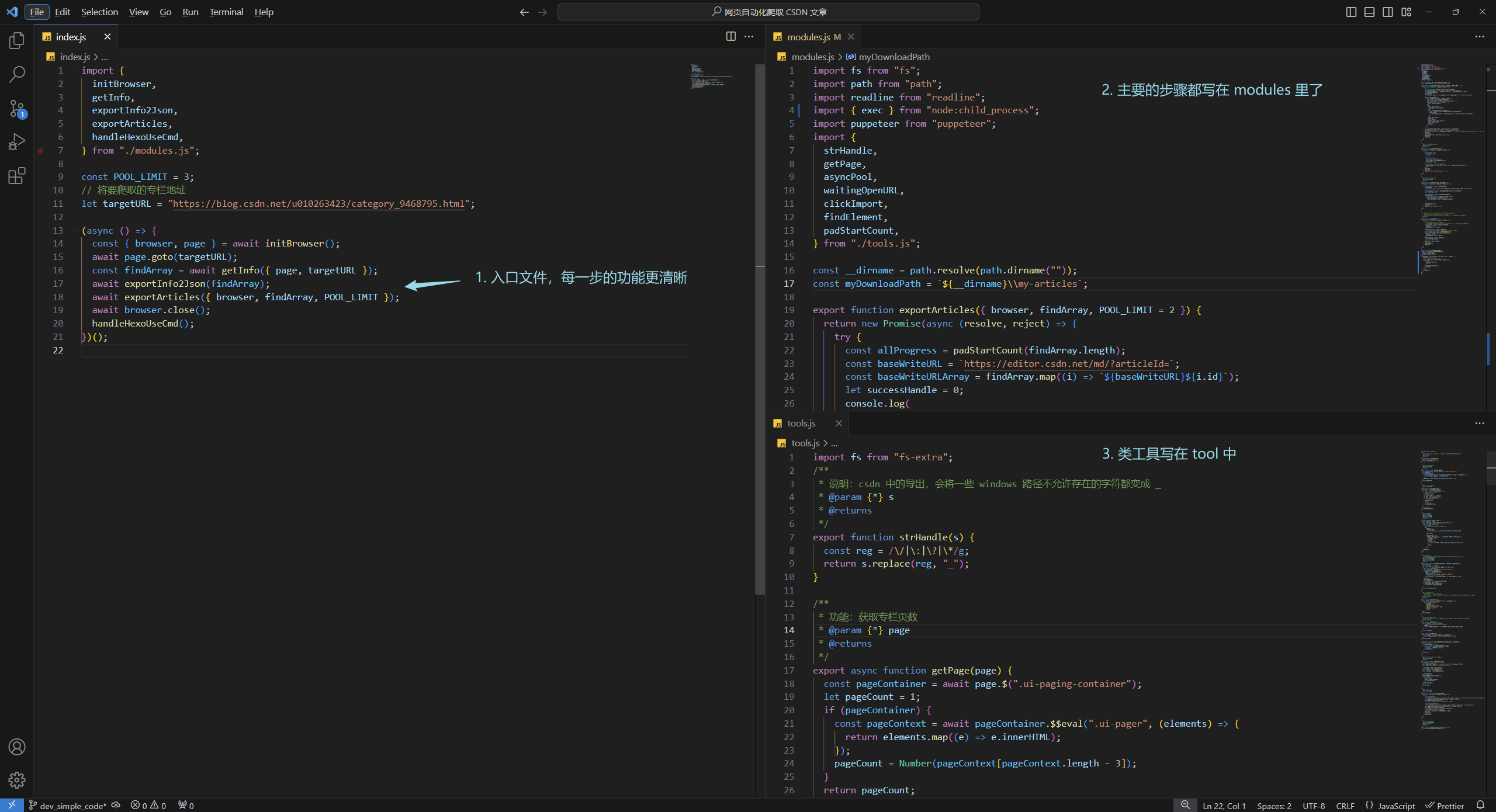
花了點時間抽離了一下代碼,這樣入口文件更簡潔了,每個功能也都獨立出來,方便修改和查錯,歡迎使用并 start ~代碼倉庫
結尾
基本上文章已經批量處理好了,可以放到 hexo 里生成了!









函數)






偽元素 筆記240223)


)