Spark最初是由美國伯克利大學AMP實驗室在2009年開發,Spark時基于內存計算的大數據并行計算框架,可以用于構建大型的、低延遲的數據分析應用程序。
Spark是當今大數據領域最活躍、最熱門、最高效的大數據通用計算平臺之一。
Spark的特點
-
運行速度快?:Spark使用現金的DAG(Directed Acyclic Graph,有向無環圖)執行引擎,以支持循環數據流與內存計算,基于內存的執行速度可比Hadoop MapReduce快百倍,基于磁盤的執行速度也能快十倍;
-
容易使用:Spark支持使用Java、Python以及scala等編程語言,簡潔的API有助于用戶輕松構建并行程序;
-
通用性:Spark提供了完整而強大的技術棧,包括SQL查詢、流式計算、機器學習以及GraphX圖計算組件,這些組件可以無縫整合在同一個應用中,足以應對復雜的計算;
-
運行模式多樣:Spark可以獨立運行集群模式中,或者運行在Hadoop中,也可以運行在EC2等云環境中,可以訪問HDFS、Hbase、Hive等多種數據源。
Spak相對于Hadoop的優勢
Hadoop雖然被廣泛運用于大數據建設中,但是本身存在著很大的缺陷,最主要的缺陷是其MapReduce計算模型延遲過高,無法勝任實時、快速計算的需求,因而只適用于離線批處理的場景。
Hadoop的缺點:?
- 表達能力有限:計算都必須轉換成Map和Reduce兩個操作,但這并不適合所有的情況,難以描述復雜的數據處理過程;
- 磁盤IO開銷大:每次執行時都需要從磁盤讀取數據,并且在計算完成過后要將中間結果寫入到磁盤中,IO開銷較大;
- 延遲高:一次計算可能需要分解成一系列按照順序執行的MapReduce任務,任務之間銜接由于干涉到IO開銷,會產生較高的延遲。而且,在前一個任務執行完成之前,其他任務無法開始,難以勝任復雜、多階段的計算任務。
Spark優點:
-
編程模式靈活:Spark計算模式?也屬于MapReduce,但不局限于MapReduce操作,還提供了多種數據集操作類型,編程模型也比MapReduce更加靈活;
-
Spark內存計算:Spark提供了內存計算,中間結果直接放到內存中,帶來了更高的迭代運算效率;
-
Spark基于DAG的任務調度執行制度,要優于MapReduce的迭代執行機制。
Spark最大的特點就是將計算數據、中間結果都存儲在內存中,大大較少了IO開銷;
Spark提供了多種高層次的、簡潔的API,通常情況下,對于實現相同功能的應用程序,Spark的代碼量要比Hadoop少2-5倍;
但Spark并不能完全替代Hadoop,主要用于替代MapReduce計算模型。實際上,Spark已經很好的融入Hadoop生態圈,并且稱為其中重要的一員,它可以借助YARN實現資源調度管理,借助HDFS實現分布式存儲。?
Spark生態
- Spark Core:Spark Core包含Spark的基本功能,如內存計算、任務調度、部署模式、故障恢復、存儲管理等。Spark建立在統一的抽象RDD上,使其可以以基本一致的方式應對不同的大數據處理場景;通常所說的Apache Spark,就是指Spark Core。
- Spark SQL:Spark SQL允許開發人員直接處理RDD,同時也可查詢Hive、Hbase等外部數據源。SparkSQL的一個重要特點是其能夠統一處理關系表和RDD,使得開發人員可以輕松的使用SQL命令進行查詢,并進行更復雜的數據分析;
- Spark Streaming:Spark Streaming支持高吞吐量、可容錯處理的實時數據流處理,其核心思路是將流式計算分解成一系列短小的批處理作業。Saprk Streaming支持多種數據輸入源,如Kafka、Flume等;
- MLLib(機器學習):MLLib提供了常用機器學習算法的實現,包括聚類、分類、回歸協同過濾等,降低了機器學習的學習門檻,開發人員只要具備一定的理論知識就可以進行機器學習的工作;
- GraphX(圖計算):GraphX是Spark中用于圖計算的API,可以認為是Pregel在Spark上重寫以及優化,GraphX性能良好,擁有豐富的功能和運算符,能在海量數據上自如的運算復雜的圖算法。?
Spark的基礎概念?
- RDD:彈性分布式數據集(Resilient Distributed Dataset)的簡稱,是分布式內存的一個抽象概念,提供了一種高度受限的共享內存模型;RDD是一個可以容錯且并行的數據結構(可以理解成分布式的集合,操作起來和操作本地集合一樣簡單),它可以將數據集保存在內存中,并且通過控制數據集的分區來達到數據存放處理最優化。代表一個不可變、可分區、里面的元素可并行計算的集合。
- a list of partitions:一組分片列表,即數據集的基本組成單位。對于RDD來說,每個分片都會被一個計算任務處理,分片數決定并行度。
- A function for computing each split:一個函數會被作用到每一個分區。Spark中RDD的計算是分片為單位的,compute函數會被作用到每個分區上;
- A list of dependencies on other RDDS:一個RDD會依賴于其他多個RDD。RDD的每次轉換都會生成一個新的RDD,所以RDD之間就會形成類似流水線一樣的前后依賴關系。在部分分區數據丟失時,Spark可以通過這個依賴關系重新計算丟失的數據,而不是對RDD的所有分區進行重新計算。(Spark的容錯機制)
- Optionally,a Partitioner for key-value RDDS:可選項,對于KV類型的RDD會有一個Partitioner,即RDD的分區函數,默認為HashPartitioner。
- Optionally,a list of preferred locations to compute each split on (e.g.block locations for an HDFS file):可選項,一個列表,存儲每個Partition的優先位置(preferred location)。對于一個HDFS文件來說,這個列表保存的就是每個Partition 所在快的位置。按照“移動數據不如移動計算”的理念,Spark在進行任務調度的時候,會盡可能選擇那些存有數據的worker節點來進行任務計算。
- 總結:分區列表、分區函數、最佳位置,這三個屬性其實說的就是數據集在哪,在哪計算更合適,如何分區;計算函數、依賴關系,這兩個屬性其實說的是數據集怎么來的。
- DAG:有向無環圖,是Directed Acyclic Graph的簡稱,反映了RDD之間的依賴關系;
- Executor:是運行在工作節點(Worker Node)上的一個進程,負責運行任務,并為應用程序存儲數據;
- 應用:用戶編寫的Spark應用程序;
- 任務:運行在Executor上的工作單元;?
- 作業:一個作業包含多個RDD以及作用于響應RDD上的各種操作;
- 階段:是作業的基本調度單位,一個作業會分為多組任務,每個任務被稱為階段,或者被稱為“任務集”。
Spark結構設計

Spark運行架構包括集群資源管理器(Cluster Manager)、運行作業任務的工作節點(Worker Node) 、每個應用的任務控制節點(Driver)和每個工作節點上負責具體任務的執行進程(Executor)。其中,集群資源管理器可以是Spark自帶的資源管理器,也可以是Yarn或Mesos等資源管理框架。
Spark各種概念之間的關系
?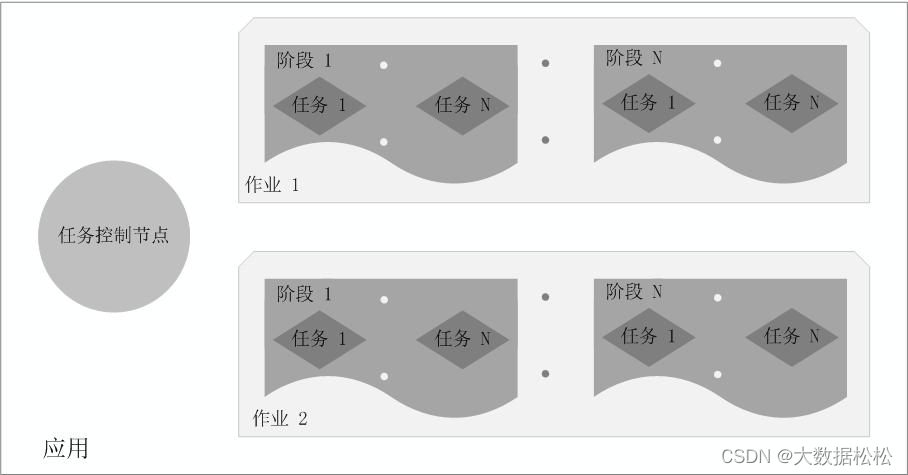
在Spark中,一個應用(Application)由一個任務控制節點和若干個作業(Job)構成,一個作業由多個階段(Stage)構成,一個階段由多個任務(Task)組成。當執行一個應用時,任務控制節點會向集群管理器(Cluster Manager)申請資源,啟動Executor,并向Executor發送應用程序代碼和文件,然后在Executor上執行任務, 運行結束后,執行結果會返回給任務控制節點,或者寫到HDFS或者其他數據庫中。
Executor的優點
與Hadoop MapReduce計算框架相比,Spark所采用的Executor有兩個優點:
- 利用多線程來執行具體的任務(Hadoop MapReduce采用的是進程模型),減少任務的啟動開銷;
- Executor中有一個BlockManager存儲模塊,會將內存和磁盤共同作為存儲設備,當需要多輪迭代計算時,可以將中間結果存儲到這個存儲模塊里,下次需要時,就可以直接讀取該存儲模塊里的數據,而不需要讀寫到HDFS等文件系統里,因而有效減少了IO開銷;或者在交互式查詢場景下,預先將表緩存到該存儲系統上,從而可以提高讀寫IO性能。
Spark運行架構的特點:
-
每個應用都有自己專屬的Executor進程,并且該進程在應用運行起家一直駐留。Executor進程以多線程的方式運行任務,減少多進程任務頻繁的啟動開銷,使得任務執行變得非常高效和可靠;
-
Spark運行過程與資源管理器無關,只要能夠獲取Executor進程并保持通信即可;
-
Executor上有一個BlockManager存儲模塊,類似于鍵值存儲系統(把內存和磁盤共提供作為存儲設備),在處理迭代計算任務時,不需要把中間結果寫入到hdfs等文件系統,而是直接放在這個存儲系統上,后續有需要時就可以直接讀取;在交互查詢場景下,也可以把表提前緩存到這個存儲系統上,提高讀寫IO性能;
-
任務采用了數據本地性和瑞測執行等優化機制。數據本地性是盡量將計算移到數據所在的節點上進行,即“計算向數據靠攏”,因為移動計算比移動數據所占的網絡資源要少得多。而且,Spark采用了延時調度機制,可以在更大的程度上實現執行過程優化。比如,擁有數據的節點當前整被其他任務占用,那么,在這種情況下是否需要將數據移動到其他的空閑節點呢?答案是不一定,因為,如果經過預測發現當前節點結束前任務的時間要比移動數據的時間要少,那么,調度就會等待,直到當前節點可用。?
RDD持久化/緩存
? ? ? ? 某些RDD計算或轉換可能會比較耗費時間,如果這些RDD后續還會頻繁的被使用到,那么可以將這些RDD進行持久化/緩存;
? ? ? ? RDD通過presis或cache方法可以將前面的計算結果緩存,但是并不是這兩個方法被調用時立即緩存,而是觸發后面的action時,該RDD將會被緩存在計算節點的內存中,并供后面重用。
? ? ? ? 通過查看RDD的源碼發現cache最終也調用了presist無參方法(默認存儲只存在內存中)。
小結:
-
RDD持久化/緩存的目的時為了提高后續操作的速度
-
緩存的級別有很多,默認只存在內存中,開發中使用memory_and_disk
-
只有執行action操作的時候才會真正將RDD數據進行持久化/緩存
-
實際開發中如果某一個RDD后續會被頻繁使用,可以將該RDD進行持久化/緩存?
?RDD容錯機制CheckPoint
持久化的局限性:
? ? ? ? 持久化/緩存可以把數據放在內存中,雖然是快速的,但是也是最不可靠的;也可以把數據存在磁盤上,也不是完全可靠的!例如磁盤會損壞等。
解決方案:
Checkpoint的產生就是為了更加可靠的數據持久化,在Checkpoint的時候一般把數據放在HDFS上,這就天然的借助了HDFS天生的高容錯、高可靠來實現數據最大程度的安全,實現了RDD的容錯和高可用。
小結:開發中如何保證數據的安全性及讀取效率,可以先對頻繁使用且重要的數據,先做緩存/持久化,再做checkpoint操作。
持久化和Checkpoint的區別:
- 位置:Presist和cache只能保存在本地的磁盤和內存中(或者堆外內存);Checkpoint可以保存數據到HDFS這類可靠的存儲上;
- 生命周期:Cache和Presist的RDD會在程序結束后被清除或者手動調用unpersist方法checkpoint的RDD在程序結束后依然存在,不會被刪除。
RDD的依賴關系
? ? ? ? RDD有兩種依賴,分別為寬依賴和窄依賴。
- 窄依賴:父RDD的一個分區只會被一個子RDD的分區依賴;
- 窄依賴的多個分區可以并行計算;
- 窄依賴的一個分區的數據如果丟失只需要重新計算對應的分區的數據就可以了
- 寬依賴:父RDD的一個分區會被子RDD的多個分區依賴(涉及到shuffle)
- 劃分Stage(階段)的依據:對于寬依賴,必須等待上一個階段計算完成次啊能計算下一個階段。
?DAG的生成和劃分Stage
? ? ? ? DAG(Directed Acyclic Graph 有向無環圖):指的是數據轉換執行的過程,有方向,無閉環(其實就是RDD執行的流程);原始的RDD通過一系列的轉換操作就形成了DAG有向無環圖,任務執行時,可以按照DAG的描述,執行真正的計算(數據被操作的一個過程)。
- 開始:通過SparkContext創建的RDD
- 結束:觸發Action,一旦觸發Action就形成了一個完整的DAG
DAG劃分Stage?
- 一個Spark程序可以有多個DAG(有幾個Action,就有幾個DAG);
- 一個DAG可以有多個Stage(根據寬依賴/shuffle進行劃分);
- 同一個Stage可以有多個Task并行執行(task數= 分區數);
- DAG中遇到reduceByKey操作(寬依賴),Spark內核以此為界將其劃分成不同的Stage
- flatMap、Map都是窄依賴,這些轉換可以形成一個流水操作,通過flatMap操作生成partition可以不用等待整個RDD計算結束,而是繼續進行map操作,這樣可以大大提高了計算的效率。
為什么要劃分Stage--并行計算
? ? ? ? 一個復雜的業務邏輯如果有shuffle,那么就意味著前面階段產生的結果后,才能執行下一個階段,即下一個階段的計算要依賴于上一個階段的數據。那么我們按照shuffle進行劃分(也就是按照寬依賴劃分),就可以將一個DAG劃分成多個Stage階段,在同一個Stage中,會有多個算子操作,可以形成一個pipeline流水線,流水線內的多個平行的分區可以并行計算。
如何劃分DAG的stage
-
? ? 對于窄依賴:partition的轉換處理在stage中完成計算,不劃分(將窄依賴盡量放在同一個stage中,可以實現流水線計算)
-
對于寬依賴:由于shuffle的存在,只能在父RDD處理完成后,才能開始接下來的計算,也就是說需要劃分stage
-
總結:Spark會根據shuffle/寬依賴使用回溯算法來對DAG進行Stage劃分,從后往前,遇到寬依賴就斷開,遇到窄依賴就把當前的RDD加入到當前的stage/階段中。?

)
內容記錄)
)





無人機三維路徑規劃,輸出做短路徑圖和適應度曲線。)









