一、慢SQL定義
????????執行超過1s的SQL為慢SQL
?三、慢SQl的風險
-
系統的響應時間延遲,影響用戶體驗
-
資源占用增加,增高了系統的負載,其他請求響應時間也可能會收到影響。
-
慢SQL占用數據庫連接的時間長,如果有大量慢SQL查詢同時執行,可能會導致數據庫連接池的連接被全部占用,導致數據連接池打滿、緩沖區溢出等問題,使數據庫無法響應其他請求。(影響業務連續性,系統崩了)
-
還有可能造成鎖競爭增加、數據不一致等問題
四、慢SQL是如何引入的
-
缺乏索引/索引未生效,導致數據庫全表掃描,會產生大量的IO消耗,產生慢SQL。
-
單表數據量太大,會導致加索引的效果不夠明顯。
-
SQL語句書寫不當,例如join或者子查詢過多、in元素過多、limit深分頁問題、order by導致文件排序、group by使用臨時表等。
-
數據庫在刷“臟頁”,redo log寫滿了,導致所有系統更新被堵住,無法寫入了。
-
執行SQL的時候,遇到表鎖或者行鎖,只能等待鎖被釋放,導致了慢SQL。
五、如何發現慢SQL及高危SQL
- 數據庫會將執行慢SQL日志
- 其他的數據庫性能監控工具、SQL性能分析工具
- 發現全量SQL,把系統所有SQL采集起來
- 除了執行時長超過1s的慢SQL之外,我們還額外關注了未來可能劣化的慢SQL,這樣就需要獲取全量SQL,再對其進行分析,篩選出其中風險較大的SQL。我們采取了如下方法
-
基于JVM Sandbox進行SQL流水記錄的采集
識別慢SQL的標準
-
根據歷史慢SQL治理經驗,我們把高危SQL分為以下幾類:
-
不符合集團SQL規約的SQL,可能會埋坑,造成線上問題,影響執行效率等。
-
通過對SQL語句分析,發現SQL索引使用不當、造成全表掃描,或者SQL掃描行數過多、出現文件排序等。這種SQL即使當前不是慢SQL,隨著表數據量的膨脹,未來也可能發展為慢SQL。
-
SQL執行時間過長,比較容易理解。對慢SQL來說,執行時間越長,風險越高
SQL規約
-
【強制】不要使用count(列名)或count(常量)來替代count(*),count(*)就是SQL92定義的標準統計行數的語法,跟數據庫無關,跟NULL和非NULL無關。
-
【強制】count(distinct col) 計算該列除NULL之外的不重復數量。注意 count(distinct col1, col2) 如果其中一列全為NULL,那么即使另一列有不同的值,也返回為0。
-
【強制】當某一列的值全是NULL時,count(col)的返回結果為0,但sum(col)的返回結果為NULL,因此使用sum()時需注意NPE問題。
-
【強制】使用ISNULL()來判斷是否為NULL值。
-
【強制】對于數據庫中表記錄的查詢和變更,只要涉及多個表,都需要在列名前加表的別名(或表名)進行限定。
-
【強制】在代碼中寫分頁查詢邏輯時,若count為0應直接返回,避免執行后面的分頁語句。
-
【強制】不得使用外鍵與級聯,一切外鍵概念必須在應用層解決。
-
【強制】禁止使用存儲過程,存儲過程難以調試和擴展,更沒有移植性。
-
【強制】IDB數據訂正(特別是刪除或修改記錄操作)時,要先select,避免出現誤刪除,確認無誤才能提交執行。
我們使用了Druid SQL Parser進行SQL解析,Druid SQL Parser是阿里巴巴的開源項目,可以將SQL語句解析為語法樹,可以解析SQL的各個部分,如SELECT語句、FROM語、WHERE語句等,并且可以方便獲取SQL語句的結構信息,如表名、列名、操作符等。通過分析SQL,可以輕松判斷SQL是否符合規約
SQL索引


我們重點關注的點如下:
-
使用全表掃描,性能最差,即type="ALL"
-
掃描行數過多,即rows>閾值
-
查詢時使用了排序操作,也比較耗時,即Extra包含"Using filesort"
-
索引類型為index,代表全盤掃描了索引的數據,Extra信息為Using where,代表要搜索的列沒有被索引覆蓋,需要回表,性能較差。
以上幾點都可能造成SQL性能的劣化,是我們需要額外關注的高風險sql
六、如何推動治理慢SQL
存量慢SQL治理
存量慢SQL治理的難點在于,歷史遺留下的慢SQL可能量級很大,所以要區分慢SQL治理的優先級。我們制定了健康分機制,對SQL分批分級治理。
對慢SQL來說,健康分主要受SQL的執行次數、掃描行數、執行時長影響。另外根據應用中包含慢SQL的數量、平均SQL執行數據等,給應用打出健康分。再根據部門維度匯總,根據應用等級、應用健康分情況等,計算出部門維度的健康分。
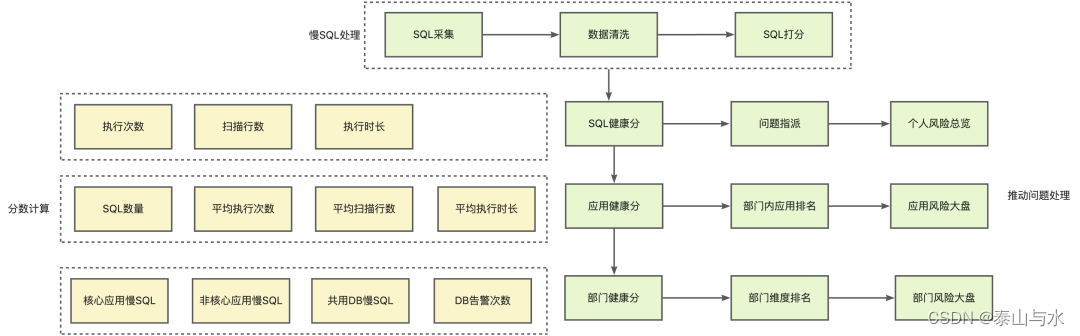
原文鏈接????????SQL高發團隊等,進行集中的推進治理SQL高發團隊等,進行集中的推進在慢SQL推動治理方面,高危慢SQL,會建立Issue持續追蹤,Issue存在超期時間,超期后會影響團隊健康分。另外,提供應用維度、部門維度的整體慢SQL風險大盤以及排名,針對重點業務、慢SQL高發團隊等,進行集中的推進治理
增量慢SQL治理
我們希望增量慢SQL能在上線前得到解決,即分支內不要引入慢SQL或者風險SQL,我們建立了開發環境下增量慢SQL發現機制,并建立發布前卡點能力。整體流程如下:
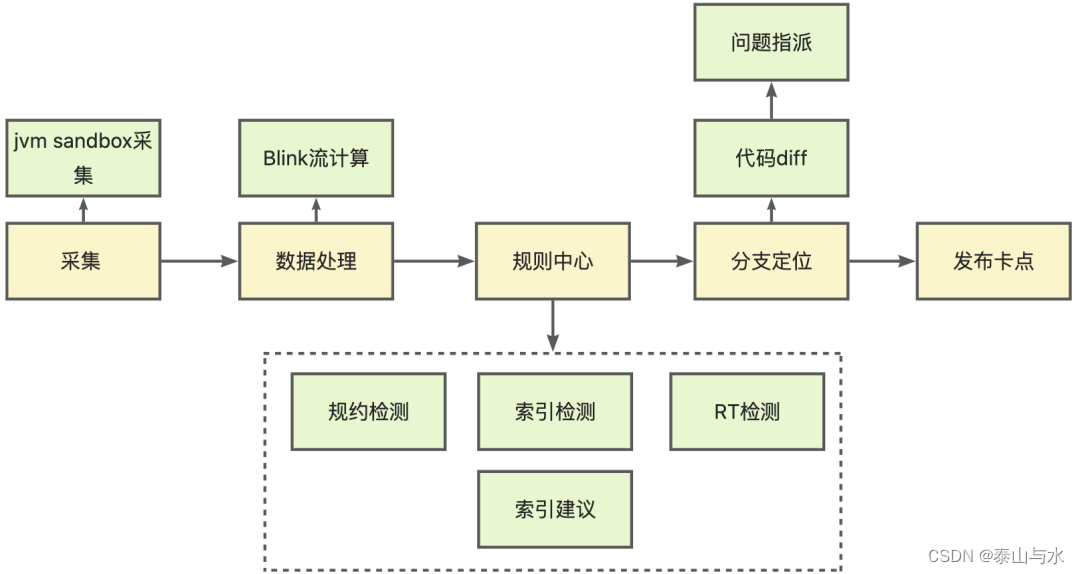
增量慢SQL的修復代價是小于存量慢SQL的,因此這里我們添加了分支定位的能力。同一應用存在多個同學共同開發的情況,有效的分支定位,可以準確指派慢SQL引入人,實現快速推動治理。這里以git上代碼改動為切入點,完成了引入慢SQL的sql_map與修改人之間的關系映射,大致邏輯如下:
a. 監聽應用部署消息
b. 獲取應用信息,拿到git地址
c. 將本次部署分支與master分支做分支diff
d. 解析sql_map文件,獲取本次修改的sql內容
e. 記錄被修改sql_id與分支的對應關系
f. 根據sql_id查詢對應分支
……
這樣就可以精準匹配到增量SQL的引入分支,從而指派到開發者,實現了定向問題指派和追蹤,并且可以方便完成分支發布前的管控能力。如果存在增量慢SQL,分支發布,合并到master之前,會觸發卡點,需要問題解決才能發布
七、學習總結
本篇文章非常優秀,從技術,管理,制度,組織各個層面介紹了如何治理慢SQL,堪稱教科書級別的。
技術:標準,風險,原因,自動化
管理:問題識別,問題跟蹤到責任人及部門,且配合自動化的工具
制度:慢SQL排名,打分到個人,應用,部門,加上獎懲制度等
組織:公共的團隊及監測系統來做治理這件事
八、亮點
- 采集全量SQL的自動化工具,解放dba人工分析慢SQL,極大提升效率
- SQL健康分評價體系
- 流程管理自動化體系
- 提前預警慢SQL及風險SQL自動化檢測工具
九、實施思考
上面的方案堪稱完美方案,但是大部分公司都不具備完全執行的條件
主要卡點:dba數量都不夠,采集工具不具備,流程制度不具備,人力安排不具備
實施慢SQL本身這件事的卡點有那些?
- 業務需求多,業務團隊如果是沒有出生產事故的情況下,是不愿意主動投入資源做優化的,且優化還有風險
- 慢sql有的是架構不合理,數據結構本身不合理,更本不能單純通過SQL本身去優化,完成優化涉及的范圍面比較大,阻礙大
- 業務團隊的技術支持不行,沒辦法優化慢SQL,優化慢SQL的風險意識不夠
- 慢SQL的發現工具不夠完善,不能及時高效發現
- 慢SQL的預防,治理及簡單規范沒有
- 考核本身
如果是一個小公司要執行慢sql治理,核心治理方案怎么制定?
- 慢SQL定義:再小的團隊一個架構師,技術經理都能出一個團隊范圍內的定義
- 慢SQL的風險及如果引入:認知培訓及意識培養,小團隊能進行
- 慢SQL的發現:通過數據庫自帶的慢SQL日志發現慢SQL一般效率比較低,可以借鑒一些開源功能,或開發一些簡單腳本定時做巡檢分析那些慢SQL,比如dba一個季度出一次分析報告給到研發團隊
- 研發要么從dba哪里獲取慢SQL分析報告,要么有比較友好的入口可以自己檢查看,這個比較重要
- 慢sql找到后,安裝技術優化排期解決并考核
- 宣講研發階段怎么避免慢sql引入,團隊知識升級
兩三個人的團隊都可以按照上面的流程來優化,不一定要非常完善的方案,這樣投入產出比不劃算,沒有完美的方案只有適合的最佳方案;我們公司好幾百個系統,研發上千人,dba才20人不到,根本沒資源做
核心關鍵
- 慢sql的第一責任人研發,第二責任人dba,第三責任人sre;
- 慢sql的風險及收益,宣講培養
- 考核
?








)


)

 - 全局搜索功能)





)