【大模型 數據增強】LLMAAA:使用 LLMs 作為數據標注器
- 提出背景
- 算法步驟
- 1. LLM作為活躍標注者(LLMAAA)
- 2. k-NN示例檢索與標簽表述化
- 3. 活躍學習策略
- 4. 自動重權技術
- LLMAAA 框架
- 1. LLM Annotator
- 2. Active Acquisition
- 3. Robust Training
- 總結
- LLMAAA = 提示工程優化 + 活躍數據獲取策略 + 魯棒訓練機制
?
提出背景
論文:https://arxiv.org/pdf/2310.19596.pdf
代碼:https://github.com/ridiculouz/LLMAAA
?
以醫學文獻的實體識別為例,假設我們需要從醫學論文中自動識別出藥物名稱、疾病和治療方法等實體。
這些實體對于構建醫學知識庫、推進藥物發現和支持臨床決策等方面至關重要。
然而,手動標注這些實體通常是時間消耗大且成本高昂的,特別是考慮到專業知識的需求。
在這種情況下,LLMAAA 能自動化標注數據。
-
數據準備:
- 收集一批未標注的醫學研究文獻。
-
提示工程:
- 設計提示指令,告訴LLM如何識別文本中的醫學實體。
- 例如:“識別以下段落中所有的藥物名稱和疾病”。
-
活躍學習樣本選擇:
- 使用活躍學習算法從大量未標注的文獻中選擇最有可能包含重要實體的段落。
-
LLM生成偽標注:
- 利用LLM和設計好的提示對選中的段落進行偽標注。
-
自動重權和微調:
- 應用自動重權技術,根據LLM標注的可信度調整每個標注樣本的權重。
- 使用偽標注的數據微調一個特定于實體識別的模型。
-
人工審核和模型迭代:
- 人工審核一小部分LLM生成的偽標注,以評估和改進標注質量。
- 基于人工審核的結果迭代改進提示和微調模型。
-
模型應用:
- 將訓練好的模型應用于新的醫學文獻集合,自動提取相關實體,支持進一步的醫學研究和分析。
通過這個過程,LLMAAA框架能夠有效地減少手動標注所需的專業人力和時間,同時提高了數據標注的覆蓋率和質量,加速了醫學知識的整理和應用。
?
算法步驟
LLMAAA框架結合了活躍學習和大型語言模型(LLM)的能力來自動化數據標注的過程。
1. LLM作為活躍標注者(LLMAAA)
這個過程的目的是讓LLM在數據標注中起到積極作用,而不是被動地對大量數據進行標注。
- 活躍數據獲取:通過活躍學習機制,系統會評估哪些未標注的數據最有可能提升模型的性能。
- 生成偽標簽:一旦確定了哪些數據最有價值,LLM會對這些數據生成偽標簽,作為初始的標注結果。
活躍學習讓模型在訓練過程中有選擇性地識別哪些數據最有價值,即對于改善模型性能最有幫助的數據。
活躍學習尤其適用于標注數據稀缺或標注成本高昂的場景。
活躍學習算法通常步驟:
-
選擇樣本:算法從未標注的數據池中選擇一批樣本。這些樣本是基于某種標準挑選的,比如模型對它們的預測不確定性很高,或者樣本能夠最大程度地增加模型的多樣性。
-
人工標注:這些選定的樣本將被人工標注。在一些情況下,可以使用半自動的方法,先由機器生成偽標簽,然后由人類專家進行驗證和修正。
-
更新模型:一旦樣本被標注,模型就用這些新數據進行更新訓練。
-
迭代:上述過程反復進行,每次迭代都選擇新的樣本進行標注和訓練,直到模型性能達到滿意的水平或者資源耗盡。
活躍學習的優勢在于它可以顯著減少所需進行手動標注的數據量,從而節約時間和成本,同時在很多情況下還能保持或提高模型的性能。
2. k-NN示例檢索與標簽表述化
在標注過程中,為了提高LLM生成的標注質量,可以使用以下方法:
- k-NN示例檢索:選取與當前需要標注的數據點在內容上最接近的k個已標注的示例,這有助于LLM更好地理解上下文和預期的輸出格式。
- 標簽表述化:將抽象的標簽(如類別代碼)轉換成自然語言描述。例如,在醫學影像標注中,將“腫瘤”標簽轉換為詳細的描述,如“圓形陰影在右上肺葉”。
假設我們的目標是自動標注一組胸部X光圖像,識別圖中是否存在肺部疾病,如肺炎、腫瘤等。這個任務對于支持醫生快速診斷至關重要。
步驟1: k-NN示例檢索
- 創建示例數據庫:首先,收集一批已經由放射科醫生手動標注的胸部X光圖像。這些圖像被標注了不同的肺部疾病類型,包括肺炎、腫瘤等。
- 計算相似度:對于每張待標注的X光圖像,系統利用圖像處理算法(如基于深度學習的特征提取)計算其與示例數據庫中每張圖像的相似度。
- 選擇最接近的示例:基于相似度評分,為每張待標注的圖像選擇k個最相似的已標注圖像作為參考。
步驟2: 標簽表述化
- 標簽轉換為描述:對于示例數據庫中的每種肺部疾病標簽,創建詳細的自然語言描述。例如,腫瘤標簽對應的描述可能是“圖像中顯示了肺部的不規則圓形陰影,邊界清晰,可能是腫瘤的跡象”。
- 利用描述進行標注:當LLM對待標注的X光圖像進行分析時,將這些自然語言描述作為提示,引導模型生成更精確的診斷標注。
假設有一張待標注的胸部X光圖像顯示了右上肺葉的圓形陰影。
通過k-NN示例檢索,系統找到了幾張具有相似特征的已標注圖像,這些圖像被標注為顯示腫瘤存在。
接著,利用標簽表述化技術,LLM得到提示:“如果圖像中顯示肺部的不規則圓形陰影,請標注為腫瘤。”
依據這些信息,LLM預測待標注圖像顯示的是腫瘤。
通過這種方式,k-NN示例檢索和標簽表述化技術共同提高了LLM在醫學影像標注任務上的性能,幫助模型以更人性化、更準確的方式理解和描述醫學圖像中的病變,從而為醫生的診斷提供輔助信息。
3. 活躍學習策略
活躍學習策略是整個框架的核心,它決定了哪些數據被選中進行標注以提高模型的性能。
活躍學習讓模型在訓練過程中有選擇性地識別哪些數據最有價值,即對于改善模型性能最有幫助的數據。
那什么是最有幫助的數據:
- 不確定性最大化
- 多樣性最大化
-
不確定性最大化(特征1)
- 描述:選擇那些模型預測結果最不確定的樣本。
- 這些樣本往往能為模型提供最多的信息,因為模型對它們的預測缺乏信心,學習這些樣本能顯著提升模型的性能。
- 實施方法:計算每個樣本的預測不確定性(例如,通過概率分布的熵值)并選擇不確定性最高的樣本進行標注。
-
多樣性最大化(特征2)
- 描述:確保選中的樣本集在特征空間上具有廣泛的覆蓋范圍。
- 這樣做可以讓模型接觸到數據分布的不同區域,增強其泛化能力。
- 實施方法:采用聚類算法(如k-means)對未標注的數據進行聚類,然后從每個聚類中選擇代表性樣本,或者直接基于特征空間的分布來選擇樣本,以保證樣本的多樣性。
- 代表性樣本選擇(隱藏特征)
- 描述:除了考慮不確定性和多樣性外,還需要考慮樣本的代表性,即選擇那些能夠代表數據整體分布的樣本。
- 實施方法:結合不確定性和多樣性指標,使用加權方法來評估每個樣本的綜合價值,確保選中的樣本既有高不確定性,又能代表數據的整體分布。
4. 自動重權技術
由于偽標簽可能包含噪聲,需要一種方法來減少這些標注錯誤對模型訓練的影響。
- 元學習優化:自動重權技術通過元學習框架來優化標注樣本的權重。模型在小規模的驗證集上測試,以評估哪些數據點的標注最可能是錯誤的。
- 權重調整:根據驗證集上的性能,自動調整每個數據點在訓練過程中的權重,從而減少噪聲數據的影響。
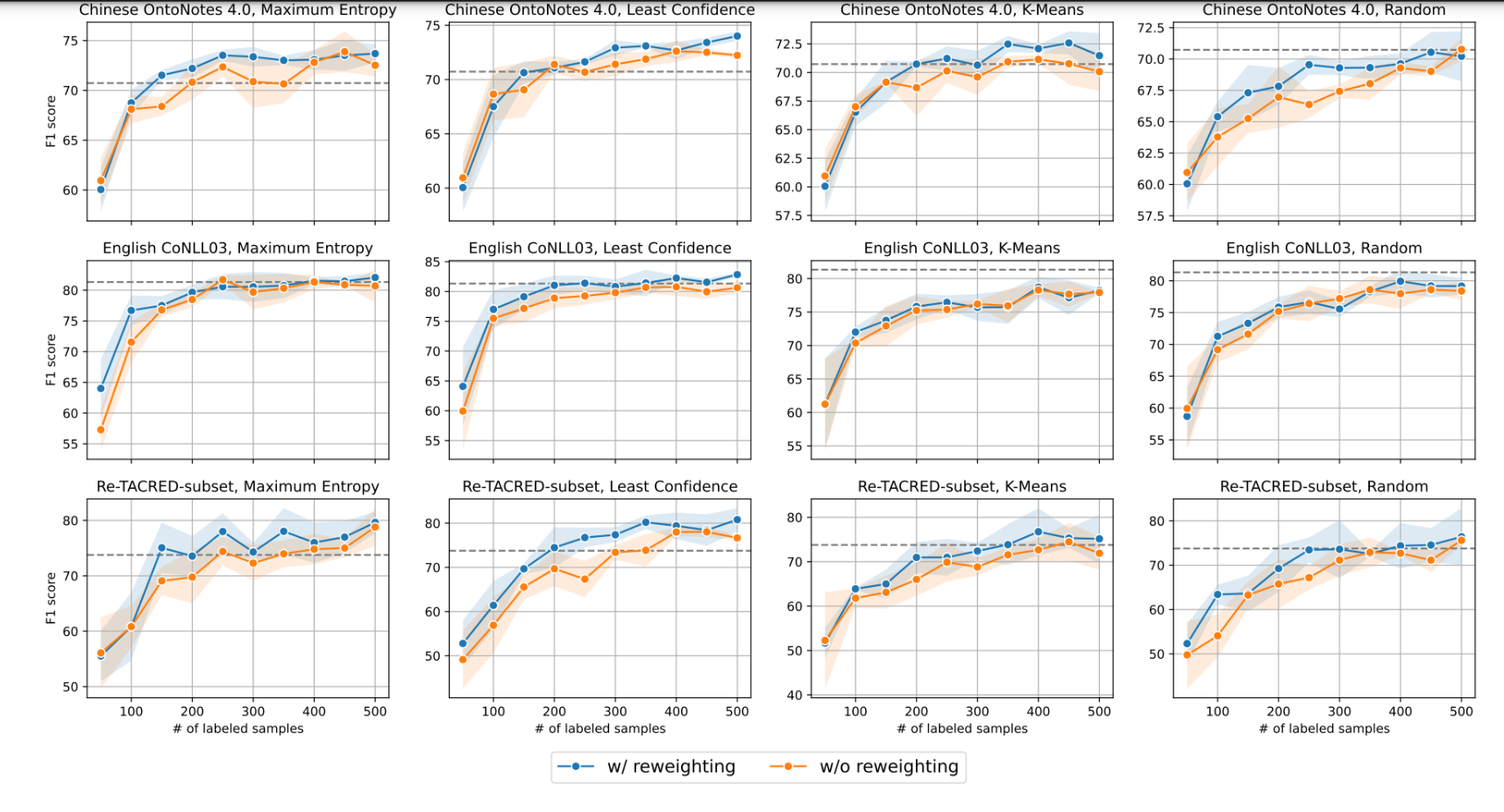
使用重權技術(w/ reweighting)與不使用重權技術(w/o reweighting)時的F1分數變化。
虛線代表了使用傳統提示方法的性能。
可以看出,使用自動重權技術通常會帶來性能的提升。
?
LLMAAA 框架
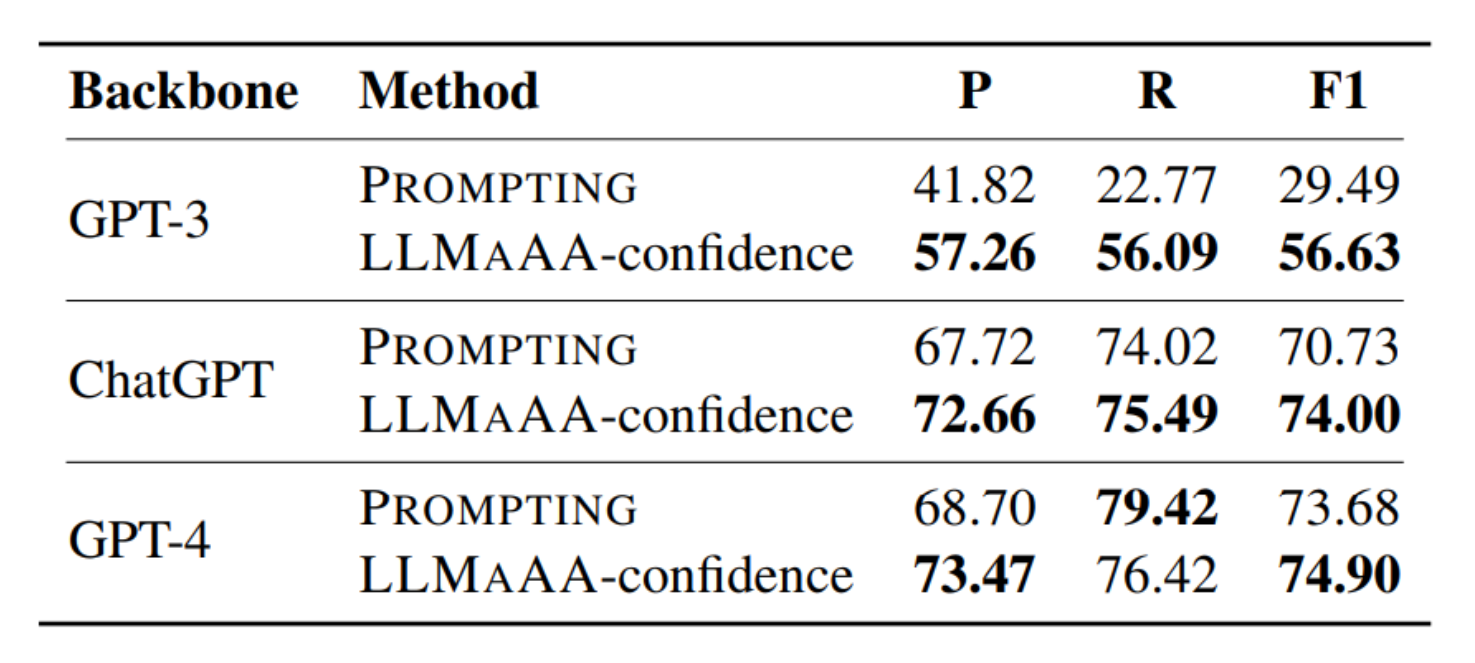
使用不同版本的大型語言模型(如GPT-3, ChatGPT, GPT-4)進行中文OntoNotes 4.0數據集上的命名實體識別(NER)任務時,LLMAAA框架與傳統提示方法(PROMPTING)的性能對比。
表格中的"P", “R”, "F1"分別代表精確度(Precision)、召回率(Recall)、和F1分數,這些是衡量模型性能的標準指標。
LLMAAA框架在提高F1分數方面表現出明顯優勢,這表明了它在標注數據時的高效性和準確性。
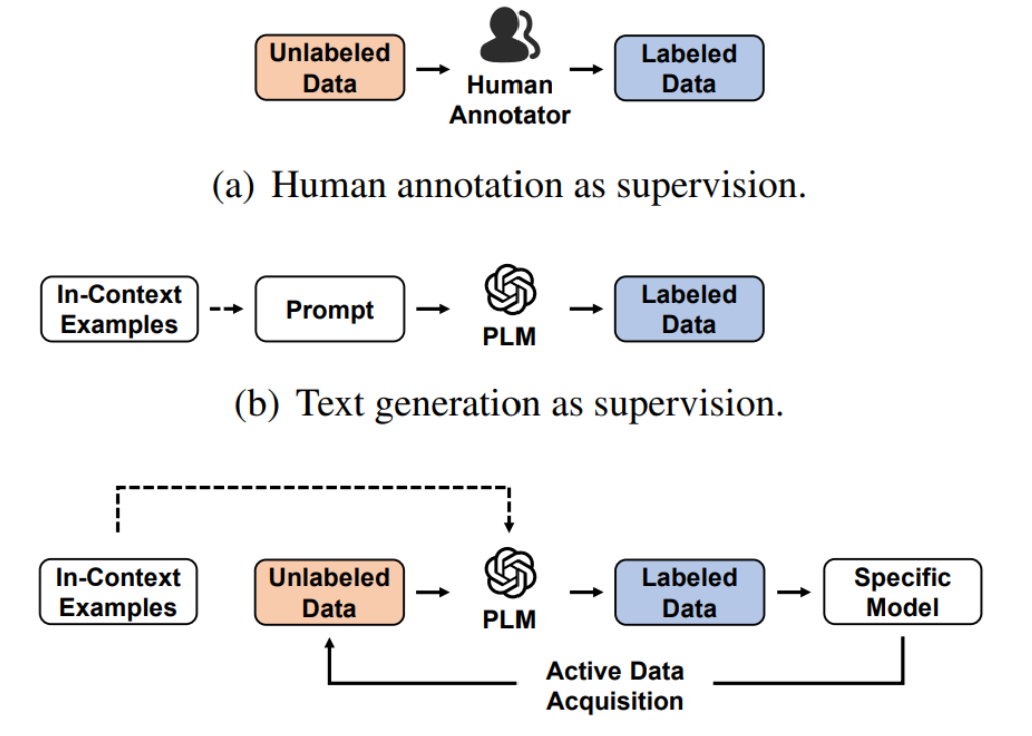
這張圖,它比較了LLMAAA與其他框架的不同:
-
(a) Human annotation as supervision:這個部分展示了傳統的人工注釋流程,即人類注釋者將未標注數據轉換為標注數據。
-
(b) Text generation as supervision:這個部分顯示了一個使用語言模型進行文本生成作為監督的過程。這里,給定上下文示例和提示,預訓練的語言模型(PLM)生成標注數據。
-
? LLMAAA: Active LLM annotation as supervision:此部分具體展示了LLMAAA框架的流程。
這個過程利用活躍數據獲取來指導語言模型注釋未標注數據,生成的標注數據隨后用于訓練特定任務模型。這個框架強調了用于提高效率的活躍學習元素,減少了人類努力的需要。
兩幅圖表共同強調了LLMAAA方法相比傳統人工注釋和簡單的文本生成方法,能夠有效提升數據注釋的效率和質量,同時減少對人工注釋的依賴。
?
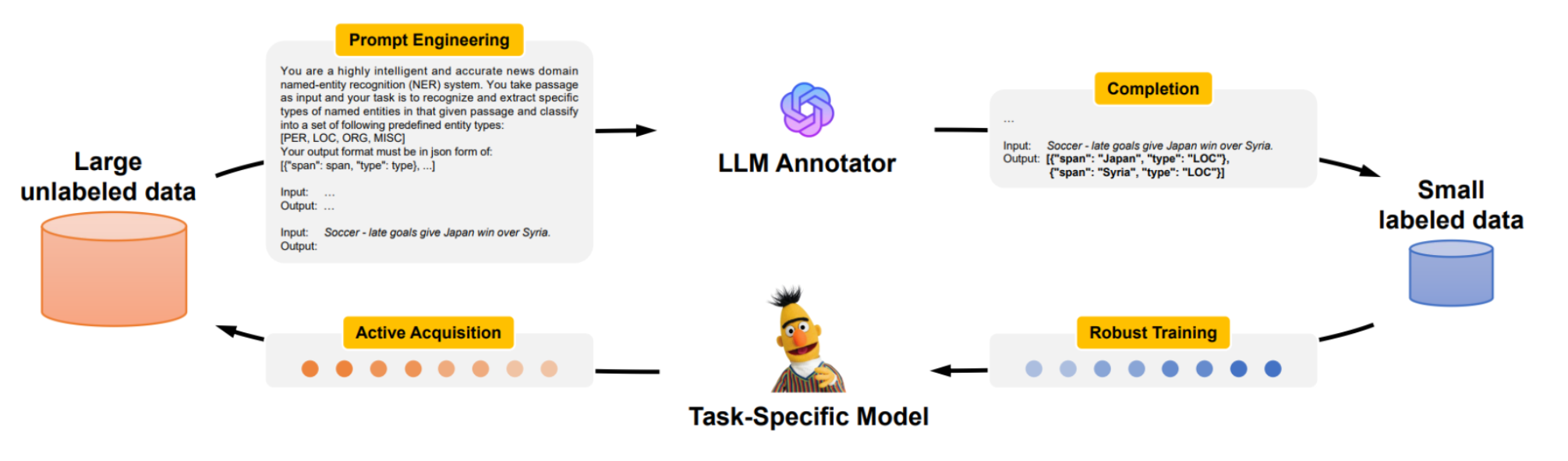
此圖展示了LLMAAA(LLM作為活躍注釋者)的整體架構和工作流程,它主要由以下三個部分組成:
-
LLM Annotator:這個部分說明了如何利用提示工程來優化LLM的注釋器,使其能夠生成偽標簽。
提示工程:利用精心設計的提示來優化LLM的輸出,使其能夠針對特定任務生成高質量的偽標簽。
上下文示例利用:通過提供相關的上下文示例來輔助LLM更好地理解任務需求和數據特點。
-
Active Acquisition:這個部分描述了一種有效的數據選擇機制。
數據價值評估:對大量未標注的數據進行評估,識別出對模型性能提升最有幫助的數據。
策略性數據選擇:基于模型的不確定性或數據的多樣性來選擇最有價值的數據進行標注,而不是隨機選擇。
-
Robust Training:最后,它強調了自動重權技術以確保在噪聲標簽存在的情況下也能進行穩健的學習。
這樣的訓練過程考慮到了標簽質量可能不一,且通過重權技術調整學習過程,減少噪聲的影響。
自動重權技術:利用元學習框架對標注樣本的權重進行動態調整,以應對標注中的噪聲問題。
標簽質量適應性學習:根據模型在驗證集上的表現來調整權重,優先訓練那些標注質量高的數據。
舉個例子。
目標是使用LLMAAA框架自動標注醫學影像數據集,如X射線或MRI掃描圖像,以識別出不同類型的病變(比如腫瘤、骨折等)。
1. LLM Annotator
- 提示工程:設計提示來指導LLM識別和標注醫學影像中的特定病變。例如,提示可能是“在這張X射線圖像中識別所有可見的腫瘤,并描述它們的位置和大小”。
- 上下文示例利用:提供一些已經由醫學專家標注的影像作為示例。這些示例幫助LLM理解腫瘤在醫學影像中的典型外觀和如何準確描述它們的位置和大小。
2. Active Acquisition
- 數據價值評估:使用一個初始的、簡單的醫學影像分析模型來評估未標注影像的價值。挑選出這個模型最不確定的影像,即那些模型難以判斷病變類型的影像。
- 策略性數據選擇:選擇這些高不確定性的影像進行LLM標注,因為這些影像提供了最大的學習機會,有助于快速提升模型性能。
3. Robust Training
- 自動重權技術:在得到LLM標注的影像后,可能存在一些標注錯誤或不準確的情況。使用自動重權技術,根據一個小的、已經由醫學專家準確標注的驗證集來動態調整每張影像的權重。這樣可以減少錯誤標注的影響。
- 標簽質量適應性學習:如果模型在驗證集上對某些LLM標注的影像表現不佳,這些影像的權重會被降低,從而優先訓練那些標注質量更高的數據。
在實際應用中,這個過程可以幫助醫學影像分析系統快速學習和適應新的、未見過的病變類型,特別是在數據標注資源有限的情況下。
例如,如果新出現了一種腫瘤類型,系統可以通過上述流程迅速集成這類腫瘤的識別能力,從而提升整個醫學影像分析系統的準確性和魯棒性。
?
總結
LLMAAA = 提示工程優化 + 活躍數據獲取策略 + 魯棒訓練機制
-
提示工程優化(Prompt Engineering Optimization)
- 特征1:任務定制提示 - 設計與特定任務緊密相關的提示,來引導LLM的輸出。
- 特征2:上下文示例 - 提供與任務相關的上下文示例,輔助LLM理解任務目標。
-
活躍數據獲取策略(Active Data Acquisition Strategy)
- 特征1:數據價值評估 - 使用算法評估未標注數據的價值,以確定哪些數據可能最有助于提高模型性能。
- 特征2:策略性樣本選擇 - 基于價值評估選擇樣本,而不是隨機選擇,確保標注工作集中在可能帶來最大性能提升的數據上。
-
魯棒訓練機制(Robust Training Mechanism)
- 特征1:自動重權技術 - 在訓練過程中應用元學習算法自動調整數據樣本的權重,以解決偽標簽噪聲問題。
- 特征2:標簽質量適應性學習 - 調整權重以偏好那些與驗證集上高質量標注一致的樣本,優化模型對于高質量數據的學習。
傳統方法依賴大量的人工作業和專業知識,而沒有充分利用現有的自動化工具和技術,如大型語言模型、活躍學習等,來提高標注的效率和準確性。
更深層次的原因是,現有技術和方法沒有被整合到一個統一的框架中,缺乏一個系統性的解決方案來綜合利用這些技術的優勢。
最根本的原因是缺少一個能夠綜合利用大型語言模型的生成能力、活躍學習的數據選擇優勢和自動重權技術的魯棒性,來優化數據標注過程的框架。
所以,可以通過整合提示工程優化、活躍數據獲取策略和魯棒訓練機制到一個統一的框架中,即LLMAAA,來解決這一問題。


:2024.02.05-2024.02.10)
——8266發布數據到mqtt服務器)















-ControlNet(深度Depth))