文章目錄
- 基于Embedding召回介紹
- 基于Embedding召回算法分類
- I2I召回
- U2I召回
- DSSM模型
- DSSM雙塔模型層次
基于Embedding召回介紹
- 基于embedding的召回是從內容文本信息和用戶查詢的角度出發,利用預訓練的詞向量模型或深度學習模型,將文本信息轉換成向量進行表示,通過計算兩個向量之間的距離或者相似度來推薦內容。這種方式主要考慮商品文本信息的語義信息,使推薦的內容更加精準。
- Embedding召回主要的優缺點
- 優點:
擴展性強:基于 Embedding 的召回算法可以學習大規模物品或用戶的向量表示,因此對于超大規模推薦系統也可以進行有效召回。
表達能力強:基于 Embedding 的召回算法可以學習到物品或用戶更為細致的特征表示,因此能夠更好地捕捉物品或用戶之間的相似性。
可解釋性強:基于 Embedding 的召回算法可以自然地將物品或用戶表示為低維向量,這使得我們可以通過可視化等手段來更好地理解和解釋推薦結果。 - 缺點:
數據量大,訓練周期長,只能表示用戶與物品向量表示關系,無法進行高維度特征表示(時間序列等),調參過程比較繁瑣。
- 優點:
基于Embedding召回算法分類
- 基于 Embedding 的召回算法可分為兩類有I2I 的召回和U2I的召回。
I2I召回
- I2I也就是Item-to-Item,實際上就是要將每一個 Item 用向量來表示。在Item-to-Item 召回中,系統會根據用戶已經交互過的物品,找到這些物品的相似度,然后根據相似度來召回其他類似的物品作為推薦結果。這個向量的表示,我們就可以理解為Embedding。
- Item-to-Item召回通常分為兩個步驟:第一步,計算物品之間的相似度;第二步:用戶請求推薦時,系統根據該用戶的歷史交互行為,找到該用戶已交互過的物品并選取與之最相似的一些物品作為推薦結果。
- 常見的I2I召回算法有Word2Vec、Item2Vec、FastText、BERT等。
U2I召回
- U2I也就是User-to-Item,它基于用戶的歷史行為以及用戶的一些個人信息,對系統中的候選物品進行篩選,挑選出一部分最有可能被用戶喜歡的物品,送入推薦模型進行排序和推薦。
- 常見的U2I策略有:
- 基于用戶歷史行為召回
- 基于用戶畫像召回
- 基于社交網絡召回
- 常見的U2I召回算法有DSSM雙塔模型、YouTubeDNN等。
DSSM模型
- DSSM模型又叫雙塔模型(全稱 Deep Structured Semantic Model),User塔適合在線計算User-Embedding;Item塔適合離線計算Item-Embedding,通過向量檢索就可以進行快速地召回。線上預測的時候,只需要在內存中計算相似度運算即可(Cosine-similarity等)。
- DSSM雙塔模型圖
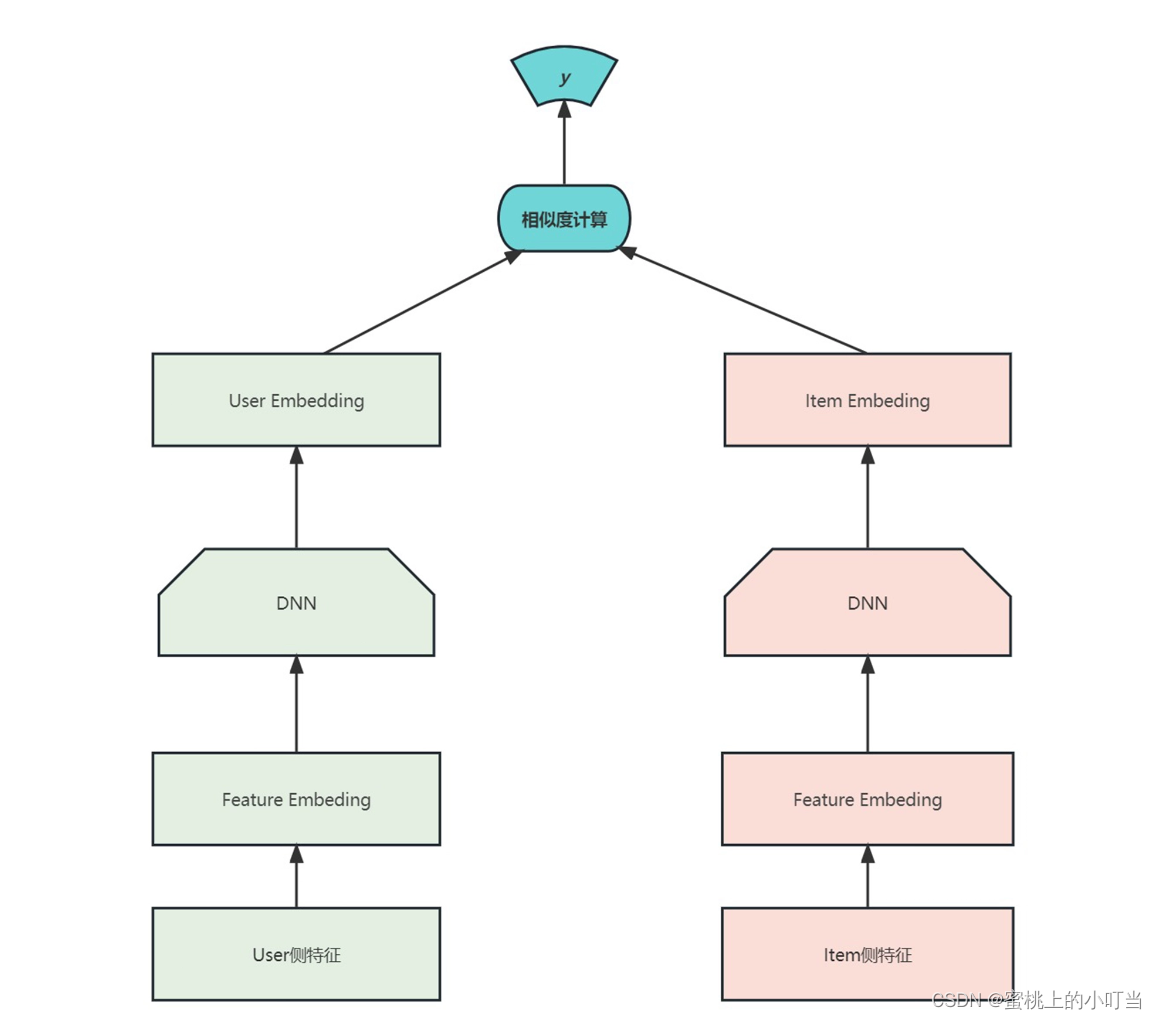
- User塔表示用戶歷史行為的信息(如用戶的瀏覽記錄、購買記錄等)。它的輸入是一個用戶的歷史行為序列,其目標是把這個序列映射為一個固定的用戶向量表示,該向量表示用戶的興趣特征。
- Item塔表示所有的物品的信息(如物品的標題、描述、標簽等)。它的輸入是一個物品的特征序列或向量,其目標是把這個序列或向量映射為一個固定的物品向量表示,該向量表示物品的特征。
- 借助于用戶歷史行為和物品的特征向量表示,DSSM可以計算用戶特征向量和物品特征向量之間的相似度,預測哪些物品最符合用戶的興趣并產生最高的預測分數。這些物品可以按照預測分數的高低排序,推送給用戶進行推薦。所以DSSM雙塔模型的作用就是協同基于用戶歷史行為和物品特征對用戶興趣進行建模,并通過此模型產生個性化推薦結果。
DSSM雙塔模型層次
- 根據上面的架構圖來看,DSSM雙塔模型主要分為三層
- 輸入層:User側特征和Item側特征是輸入層。輸入層主要的作用是把文本映射到低維向量空間,轉化成向量提供給深度學習網絡。
- 表示層:DNN就是表示層,DSSM模型表示層使用的是BOW(Bag Of Words)詞袋模型,沒有考慮詞序的信息。不考慮詞序其實存在明顯的問題,因為一句話可能詞相同,但是語義則相差十萬八千里。
- 匹配層:匹配層就是針對于前面的Query和Doc進行相似度計算,這個過程實際上非常簡單,就是把Query 和Doc統一轉換成了兩個128維的語義向量,通過Cosine計算這兩個向量的余弦相似度。
- 表示層的結構圖
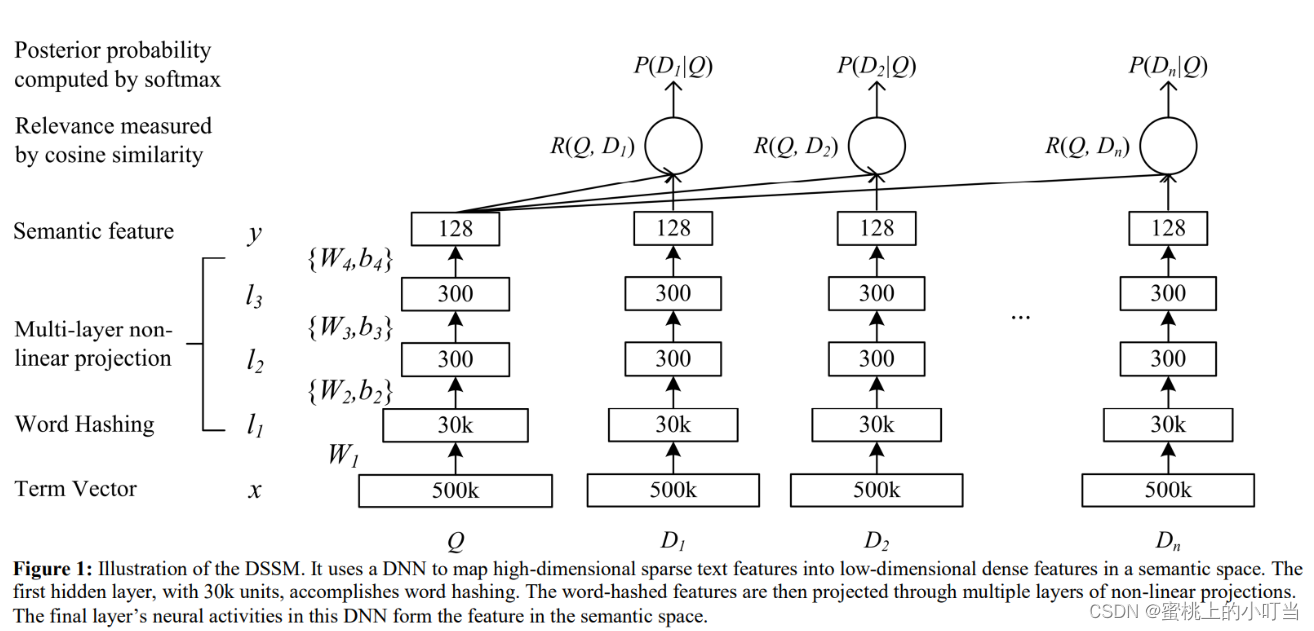
- 術語解釋:
- Term Vector:目標文本的embedding向量
- Word Hashing:因為目標向量維數比較大,而對BOW向量進行降維。
- Multi-layer non-linear projection:深度學習網絡多隱層,通過降維最終生成128維。
- Semantic Feature:Query&Doc最終生成的embedding向量。
- Relevance measured by cosine similarity:Query&Doc所計算的余弦相似度。
- Posterior probability computed by softmax:通過Softmax函數計算Query和正樣本Doc語義相似性進行后驗概率。
- 所用公式:
-
DNN:
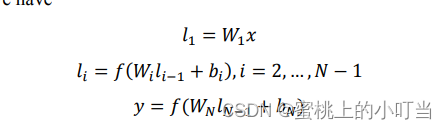
-
激活函數:
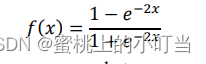
-
相似度計算公式:
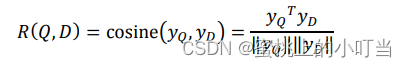
-
softmax后驗概率公式:
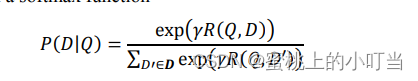
-
損失函數:
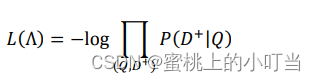
Tips:這些截圖信息都是我在論文里找的,詳細請參考鏈接。
-






)




)
)

)




