
- 從一線收集了兩百個文件,要整合到一起?總部一張全國兩百個城市的匯總表,拆成兩百個小文件?開什么玩笑,難道要復制粘貼到天荒地老。。。
- 不用這么麻煩,一個循環,一個語句,實現快速表拆分和表拼接,從此告別復制粘貼
本節測試數據:鏈家上海小區測試數據 提取碼:9172
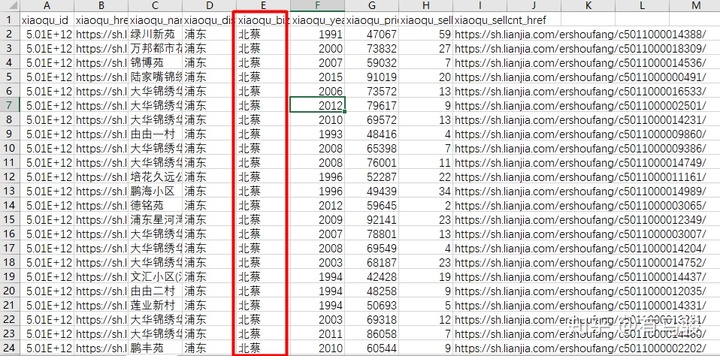
上海215個商圈,每個拆分成一個文件,怎么操作?
一、dplyr包之filter操作
#讀取文件數據
#install.packages('readr')
library(readr)
file <- readr::read_csv("D:/從0到1學習數據科學/xiaoqu.csv",locale = locale(encoding = "GB18030"))
#提取商圈不同的商圈
biz_circle <- unique(file$xiaoqu_bizcircle)#用dplyr包的filter操作循環拆分數據
#install.packages('dplyr')
library(dplyr)
begin_time <- Sys.time()
for (circle in biz_circle) {#拼接文件名和文件路徑file_name = paste(circle,'.csv',sep = '')file_path = paste('D:/從0到1學習數據科學/拆分文件/',file_name,sep = '')#過濾操作,注意%>%為管道符號file_bizcircle <- file %>% filter(xiaoqu_bizcircle == circle)#寫文件write_csv(file_bizcircle,file_path)
}
end_time <- Sys.time()#測試一下拆表運行時間
print(end_time - begin_time)step 1:讀取文件,不明之處可看課程 表快速讀取
step 2:unique函數獲取文件中商圈的不同值

step 3:for循環,循環中的circle為之前unique函數獲取到的不同商圈名稱
step 4:paste函數拼接文件名以及文件路徑名
將字符串拼接,sep表示拼接時的連接符,默認為空格
舉例:
輸入:file_name = paste('北蔡','.csv',sep = '')
輸出file_name:'北蔡.csv'
step 5:filter函數過濾出不同商圈的小區
file %>% filter(xiaoqu_bizcircle == circle)
等價于
filter(file, xiaoqu_bizcircle == circle)
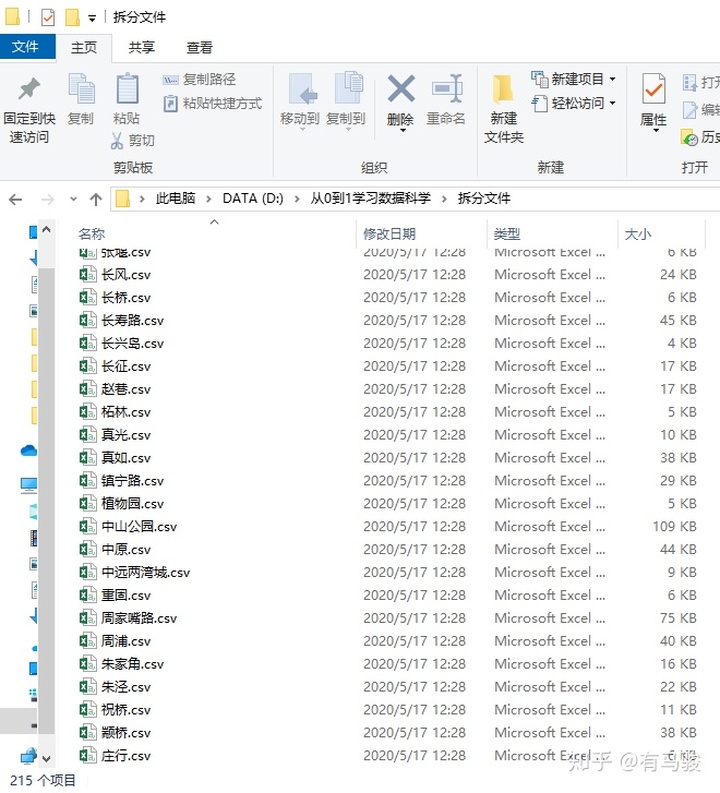
step 6:我們來看下運行結果
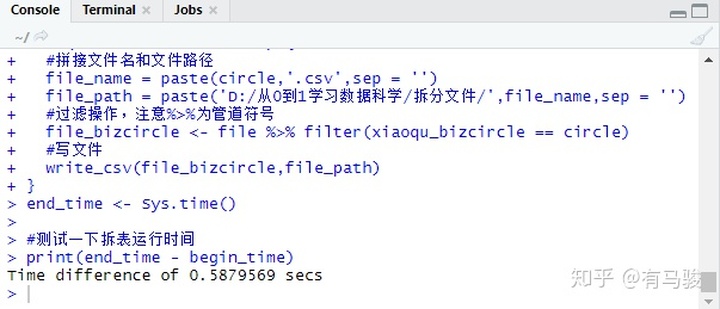
step 7:看下總的運行時間,用了0.58秒
一線有200張小表,要拼接成一張大表,怎么操作?
二、rbind操作數據合并
#獲取文件夾中的文件名
fileName <- dir('D:/從0到1學習數據科學/拆分文件/')
#拼接文件路徑
file_path <- paste('D:/從0到1學習數據科學/拆分文件/',fileName,sep = '')#循環讀入
file_conbind <- data_frame()
for (path in file_path) {file_bizcircle <- read_csv(path)#rbind拼接數據file_conbind <- rbind(file_conbind,file_bizcircle)
}step 1:dir()函數獲取文件夾中的所有文件名
step 2:通過paste()函數拼接文件的讀取地址
step 3:for循環,path為file_path中的每一個文件地址
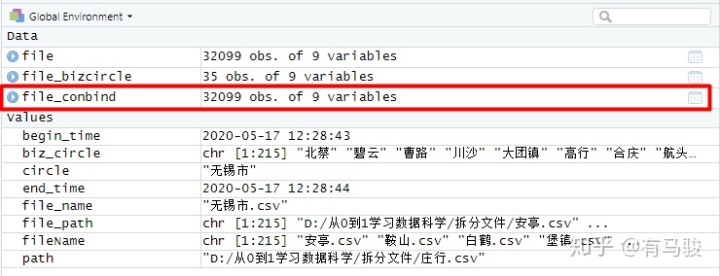
step 4:rbind()函數拼接數據,獲得最終的結果
結束語:filter和rbind操作使用起來很簡單,但它們能解決的問題卻很大,工作中經常會需要拆表和合并表操作,如果用復制黏貼,可能需要耗費一天的時間,通過短短的幾行代碼,就可以在一秒內就處理完所需的工作量。
數據處理課程:

數據采集課程:
有馬駿:第0課:一個周末學會R語言數據采集:數據從哪里來??zhuanlan.zhihu.com


:自定義層)
方法及示例)


方法與示例)

方法與示例)


方法與示例)




方法)


方法與示例)
