并發系統可以采用多種并發編程模型來實現。并發模型指定了系統中的線程如何通過協作來完成分配給它們的作業。不同的并發模型采用不同的方式拆分作業,同時線程間的協作和交互方式也不相同。這篇并發模型教程將會較深入地介紹目前(2015年,本文撰寫時間)比較流行的幾種并發模型。
并發模型與分布式系統之間的相似性
本文所描述的并發模型類似于分布式系統中使用的很多體系結構。在并發系統中線程之間可以相互通信。在分布式系統中進程之間也可以相互通信(進程有可能在不同的機器中)。線程和進程之間具有很多相似的特性。這也就是為什么很多并發模型通常類似于各種分布式系統架構。
當然,分布式系統在處理網絡失效、遠程主機或進程宕掉等方面也面臨著額外的挑戰。但是運行在巨型服務器上的并發系統也可能遇到類似的問題,比如一塊CPU失效、一塊網卡失效或一個磁盤損壞等情況。雖然出現失效的概率可能很低,但是在理論上仍然有可能發生。
由于并發模型類似于分布式系統架構,因此它們通常可以互相借鑒思想。例如,為工作者們(線程)分配作業的模型一般與分布式系統中的負載均衡系統比較相似。同樣,它們在日志記錄、失效轉移、冪等性等錯誤處理技術上也具有相似性。
【注:冪等性,一個冪等操作的特點是其任意多次執行所產生的影響均與一次執行的影響相同】
并行工作者
第一種并發模型就是我所說的并行工作者模型。傳入的作業會被分配到不同的工作者上。下圖展示了并行工作者模型:

在并行工作者模型中,委派者(Delegator)將傳入的作業分配給不同的工作者。每個工作者完成整個任務。工作者們并行運作在不同的線程上,甚至可能在不同的CPU上。
如果在某個汽車廠里實現了并行工作者模型,每臺車都會由一個工人來生產。工人們將拿到汽車的生產規格,并且從頭到尾負責所有工作。
在Java應用系統中,并行工作者模型是最常見的并發模型(即使正在轉變)。java.util.concurrent包中的許多并發實用工具都是設計用于這個模型的。你也可以在Java企業級(J2EE)應用服務器的設計中看到這個模型的蹤跡。
并行工作者模型的優點
并行工作者模式的優點是,它很容易理解。你只需添加更多的工作者來提高系統的并行度。
例如,如果你正在做一個網絡爬蟲,可以試試使用不同數量的工作者抓取到一定數量的頁面,然后看看多少數量的工作者消耗的時間最短(意味著性能最高)。由于網絡爬蟲是一個IO密集型工作,最終結果很有可能是你電腦中的每個CPU或核心分配了幾個線程。每個CPU若只分配一個線程可能有點少,因為在等待數據下載的過程中CPU將會空閑大量時間。
并行工作者模型的缺點
并行工作者模型雖然看起來簡單,卻隱藏著一些缺點。接下來的章節中我會分析一些最明顯的弱點。
共享狀態可能會很復雜
在實際應用中,并行工作者模型可能比前面所描述的情況要復雜得多。共享的工作者經常需要訪問一些共享數據,無論是內存中的或者共享的數據庫中的。下圖展示了并行工作者模型是如何變得復雜的:

有些共享狀態是在像作業隊列這樣的通信機制下。但也有一些共享狀態是業務數據,數據緩存,數據庫連接池等。
一旦共享狀態潛入到并行工作者模型中,將會使情況變得復雜起來。線程需要以某種方式存取共享數據,以確保某個線程的修改能夠對其他線程可見(數據修改需要同步到主存中,不僅僅將數據保存在執行這個線程的CPU的緩存中)。線程需要避免竟態,死鎖以及很多其他共享狀態的并發性問題。
此外,在等待訪問共享數據結構時,線程之間的互相等待將會丟失部分并行性。許多并發數據結構是阻塞的,意味著在任何一個時間只有一個或者很少的線程能夠訪問。這樣會導致在這些共享數據結構上出現競爭狀態。在執行需要訪問共享數據結構部分的代碼時,高競爭基本上會導致執行時出現一定程度的串行化。
現在的非阻塞并發算法也許可以降低競爭并提升性能,但是非阻塞算法的實現比較困難。
可持久化的數據結構是另一種選擇。在修改的時候,可持久化的數據結構總是保護它的前一個版本不受影響。因此,如果多個線程指向同一個可持久化的數據結構,并且其中一個線程進行了修改,進行修改的線程會獲得一個指向新結構的引用。所有其他線程保持對舊結構的引用,舊結構沒有被修改并且因此保證一致性。Scala編程包含幾個持久化數據結構。
【注:這里的可持久化數據結構不是指持久化存儲,而是一種數據結構,比如Java中的String類,以及CopyOnWriteArrayList類,具體可參考】
雖然可持久化的數據結構在解決共享數據結構的并發修改時顯得很優雅,但是可持久化的數據結構的表現往往不盡人意。
比如說,一個可持久化的鏈表需要在頭部插入一個新的節點,并且返回指向這個新加入的節點的一個引用(這個節點指向了鏈表的剩余部分)。所有其他現場仍然保留了這個鏈表之前的第一個節點,對于這些線程來說鏈表仍然是為改變的。它們無法看到新加入的元素。
這種可持久化的列表采用鏈表來實現。不幸的是鏈表在現代硬件上表現的不太好。鏈表中得每個元素都是一個獨立的對象,這些對象可以遍布在整個計算機內存中。現代CPU能夠更快的進行順序訪問,所以你可以在現代的硬件上用數組實現的列表,以獲得更高的性能。數組可以順序的保存數據。CPU緩存能夠一次加載數組的一大塊進行緩存,一旦加載完成CPU就可以直接訪問緩存中的數據。這對于元素散落在RAM中的鏈表來說,不太可能做得到。
無狀態的工作者
共享狀態能夠被系統中得其他線程修改。所以工作者在每次需要的時候必須重讀狀態,以確保每次都能訪問到最新的副本,不管共享狀態是保存在內存中的還是在外部數據庫中。工作者無法在內部保存這個狀態(但是每次需要的時候可以重讀)稱為無狀態的。
每次都重讀需要的數據,將會導致速度變慢,特別是狀態保存在外部數據庫中的時候。
任務順序是不確定的
并行工作者模式的另一個缺點是,作業執行順序是不確定的。無法保證哪個作業最先或者最后被執行。作業A可能在作業B之前就被分配工作者了,但是作業B反而有可能在作業A之前執行。
并行工作者模式的這種非確定性的特性,使得很難在任何特定的時間點推斷系統的狀態。這也使得它也更難(如果不是不可能的話)保證一個作業在其他作業之前被執行。
流水線模式
第二種并發模型我們稱之為流水線并發模型。我之所以選用這個名字,只是為了配合“并行工作者”的隱喻。其他開發者可能會根據平臺或社區選擇其他稱呼(比如說反應器系統,或事件驅動系統)。下圖表示一個流水線并發模型:

類似于工廠中生產線上的工人們那樣組織工作者。每個工作者只負責作業中的部分工作。當完成了自己的這部分工作時工作者會將作業轉發給下一個工作者。每個工作者在自己的線程中運行,并且不會和其他工作者共享狀態。有時也被成為無共享并行模型。
通常使用非阻塞的IO來設計使用流水線并發模型的系統。非阻塞IO意味著,一旦某個工作者開始一個IO操作的時候(比如讀取文件或從網絡連接中讀取數據),這個工作者不會一直等待IO操作的結束。IO操作速度很慢,所以等待IO操作結束很浪費CPU時間。此時CPU可以做一些其他事情。當IO操作完成的時候,IO操作的結果(比如讀出的數據或者數據寫完的狀態)被傳遞給下一個工作者。
有了非阻塞IO,就可以使用IO操作確定工作者之間的邊界。工作者會盡可能多運行直到遇到并啟動一個IO操作。然后交出作業的控制權。當IO操作完成的時候,在流水線上的下一個工作者繼續進行操作,直到它也遇到并啟動一個IO操作。

在實際應用中,作業有可能不會沿著單一流水線進行。由于大多數系統可以執行多個作業,作業從一個工作者流向另一個工作者取決于作業需要做的工作。在實際中可能會有多個不同的虛擬流水線同時運行。這是現實當中作業在流水線系統中可能的移動情況:

作業甚至也有可能被轉發到超過一個工作者上并發處理。比如說,作業有可能被同時轉發到作業執行器和作業日志器。下圖說明了三條流水線是如何通過將作業轉發給同一個工作者(中間流水線的最后一個工作者)來完成作業:

流水線有時候比這個情況更加復雜。
反應器,事件驅動系統
采用流水線并發模型的系統有時候也稱為反應器系統或事件驅動系統。系統內的工作者對系統內出現的事件做出反應,這些事件也有可能來自于外部世界或者發自其他工作者。事件可以是傳入的HTTP請求,也可以是某個文件成功加載到內存中等。在寫這篇文章的時候,已經有很多有趣的反應器/事件驅動平臺可以使用了,并且不久的將來會有更多。比較流行的似乎是這幾個:
- Vert.x
- AKKa
- Node.JS(JavaScript)
我個人覺得Vert.x是相當有趣的(特別是對于我這樣使用Java/JVM的人來說)
Actors 和 Channels
Actors 和 channels 是兩種比較類似的流水線(或反應器/事件驅動)模型。
在Actor模型中每個工作者被稱為actor。Actor之間可以直接異步地發送和處理消息。Actor可以被用來實現一個或多個像前文描述的那樣的作業處理流水線。下圖給出了Actor模型:

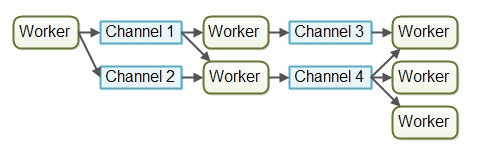
而在Channel模型中,工作者之間不直接進行通信。相反,它們在不同的通道中發布自己的消息(事件)。其他工作者們可以在這些通道上監聽消息,發送者無需知道誰在監聽。下圖給出了Channel模型:

在寫這篇文章的時候,channel模型對于我來說似乎更加靈活。一個工作者無需知道誰在后面的流水線上處理作業。只需知道作業(或消息等)需要轉發給哪個通道。通道上的監聽者可以隨意訂閱或者取消訂閱,并不會影響向這個通道發送消息的工作者。這使得工作者之間具有松散的耦合。
流水線模型的優點
相比并行工作者模型,流水線并發模型具有幾個優點,在接下來的章節中我會介紹幾個最大的優點。
無需共享的狀態
工作者之間無需共享狀態,意味著實現的時候無需考慮所有因并發訪問共享對象而產生的并發性問題。這使得在實現工作者的時候變得非常容易。在實現工作者的時候就好像是單個線程在處理工作-基本上是一個單線程的實現。
有狀態的工作者
當工作者知道了沒有其他線程可以修改它們的數據,工作者可以變成有狀態的。對于有狀態,我是指,它們可以在內存中保存它們需要操作的數據,只需在最后將更改寫回到外部存儲系統。因此,有狀態的工作者通常比無狀態的工作者具有更高的性能。
較好的硬件整合(Hardware Conformity)
單線程代碼在整合底層硬件的時候往往具有更好的優勢。首先,當能確定代碼只在單線程模式下執行的時候,通常能夠創建更優化的數據結構和算法。
其次,像前文描述的那樣,單線程有狀態的工作者能夠在內存中緩存數據。在內存中緩存數據的同時,也意味著數據很有可能也緩存在執行這個線程的CPU的緩存中。這使得訪問緩存的數據變得更快。
我說的硬件整合是指,以某種方式編寫的代碼,使得能夠自然地受益于底層硬件的工作原理。有些開發者稱之為mechanical sympathy。我更傾向于硬件整合這個術語,因為計算機只有很少的機械部件,并且能夠隱喻“更好的匹配(match better)”,相比“同情(sympathy)”這個詞在上下文中的意思,我覺得“conform”這個詞表達的非常好。當然了,這里有點吹毛求疵了,用自己喜歡的術語就行。
合理的作業順序
基于流水線并發模型實現的并發系統,在某種程度上是有可能保證作業的順序的。作業的有序性使得它更容易地推出系統在某個特定時間點的狀態。更進一步,你可以將所有到達的作業寫入到日志中去。一旦這個系統的某一部分掛掉了,該日志就可以用來重頭開始重建系統當時的狀態。按照特定的順序將作業寫入日志,并按這個順序作為有保障的作業順序。下圖展示了一種可能的設計:
實現一個有保障的作業順序是不容易的,但往往是可行的。如果可以,它將大大簡化一些任務,例如備份、數據恢復、數據復制等,這些都可以通過日志文件來完成。
流水線模型的缺點
流水線并發模型最大的缺點是作業的執行往往分布到多個工作者上,并因此分布到項目中的多個類上。這樣導致在追蹤某個作業到底被什么代碼執行時變得困難。
同樣,這也加大了代碼編寫的難度。有時會將工作者的代碼寫成回調處理的形式。若在代碼中嵌入過多的回調處理,往往會出現所謂的回調地獄(callback hell)現象。所謂回調地獄,就是意味著在追蹤代碼在回調過程中到底做了什么,以及確保每個回調只訪問它需要的數據的時候,變得非常困難
使用并行工作者模型可以簡化這個問題。你可以打開工作者的代碼,從頭到尾優美的閱讀被執行的代碼。當然并行工作者模式的代碼也可能同樣分布在不同的類中,但往往也能夠很容易的從代碼中分析執行的順序。
函數式并行(Functional Parallelism)
第三種并發模型是函數式并行模型,這是也最近(2015)討論的比較多的一種模型。函數式并行的基本思想是采用函數調用實現程序。函數可以看作是”代理人(agents)“或者”actor“,函數之間可以像流水線模型(AKA 反應器或者事件驅動系統)那樣互相發送消息。某個函數調用另一個函數,這個過程類似于消息發送。
函數都是通過拷貝來傳遞參數的,所以除了接收函數外沒有實體可以操作數據。這對于避免共享數據的競態來說是很有必要的。同樣也使得函數的執行類似于原子操作。每個函數調用的執行獨立于任何其他函數的調用。
一旦每個函數調用都可以獨立的執行,它們就可以分散在不同的CPU上執行了。這也就意味著能夠在多處理器上并行的執行使用函數式實現的算法。
Java7中的java.util.concurrent包里包含的ForkAndJoinPool能夠幫助我們實現類似于函數式并行的一些東西。而Java8中并行streams能夠用來幫助我們并行的迭代大型集合。記住有些開發者對ForkAndJoinPool進行了批判(你可以在我的ForkAndJoinPool教程里面看到批評的鏈接)。
函數式并行里面最難的是確定需要并行的那個函數調用。跨CPU協調函數調用需要一定的開銷。某個函數完成的工作單元需要達到某個大小以彌補這個開銷。如果函數調用作用非常小,將它并行化可能比單線程、單CPU執行還慢。
我個人認為(可能不太正確),你可以使用反應器或者事件驅動模型實現一個算法,像函數式并行那樣的方法實現工作的分解。使用事件驅動模型可以更精確的控制如何實現并行化(我的觀點)。
此外,將任務拆分給多個CPU時協調造成的開銷,僅僅在該任務是程序當前執行的唯一任務時才有意義。但是,如果當前系統正在執行多個其他的任務時(比如web服務器,數據庫服務器或者很多其他類似的系統),將單個任務進行并行化是沒有意義的。不管怎樣計算機中的其他CPU們都在忙于處理其他任務,沒有理由用一個慢的、函數式并行的任務去擾亂它們。使用流水線(反應器)并發模型可能會更好一點,因為它開銷更小(在單線程模式下順序執行)同時能更好的與底層硬件整合。
使用那種并發模型最好?
所以,用哪種并發模型更好呢?
通常情況下,這個答案取決于你的系統打算做什么。如果你的作業本身就是并行的、獨立的并且沒有必要共享狀態,你可能會使用并行工作者模型去實現你的系統。雖然許多作業都不是自然并行和獨立的。對于這種類型的系統,我相信使用流水線并發模型能夠更好的發揮它的優勢,而且比并行工作者模型更有優勢。
你甚至不用親自編寫所有流水線模型的基礎結構。像Vert.x這種現代化的平臺已經為你實現了很多。我也會去為探索如何設計我的下一個項目,使它運行在像Vert.x這樣的優秀平臺上。我感覺Java EE已經沒有任何優勢了。
?
轉自:http://ifeve.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B%E6%A8%A1%E5%9E%8B/
方法與示例)

)













方法與示例)


方法與示例)