環境:
python3.6
爬取代碼:
import requests
url = 'https://www.dygod.net/html/tv/hytv/'
req = requests.get(url)
print(req.text)
爬取結果:
μ?êó?? / ?aó?μ?êó??_μ?ó°ììì?-??à×μ?ó°????如上,title內容出現亂碼,自己感覺應該是編碼的問題,但是不知道如何解決,于是上網查看
參考網址:
問題找到,原來是reqponse header只指定了type,但是沒有指定編碼(一般現在頁面編碼都直接在html頁面中),查找原網頁可以看到
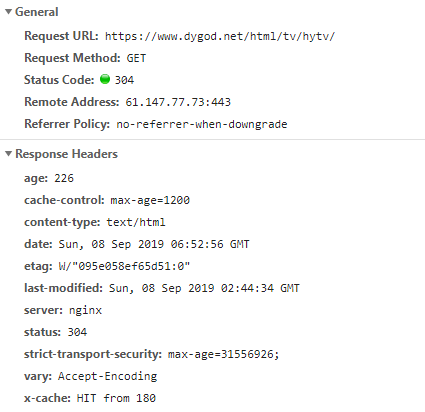
在content-type屬性中,未設置編碼格式,正常設置如下
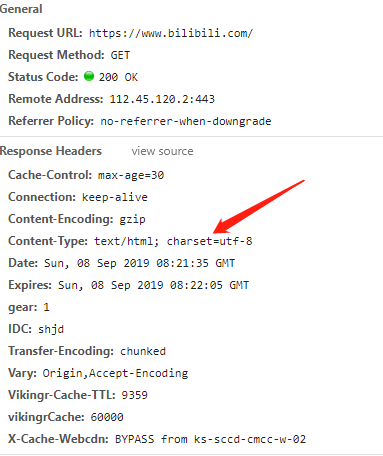
所以使用默認的編碼格式
《HTTP權威指南》里第16章國際化里提到,如果HTTP響應中Content-Type字段沒有指定charset,則默認頁面是'ISO-8859-1'編碼。
這處理英文頁面當然沒有問題,但是中文頁面,就會有亂碼了!
print(req.apparent_encoding)
結果為:GB2312
所以只需要加上
req.encoding = req.apparent_encoding
這個就可以了!
代碼:
import requests
url = 'https://www.dygod.net/html/tv/hytv/'
req = requests.get(url)
req.encoding = req.apparent_encoding
print(req.text)
結果中文就不會亂碼了





)













