前言:之前對mysql的基礎知識通過了幾篇博客進行了一個詳解,包括從數據庫系統的原理以及最基本的操作使用,此篇博客將主要對mysql的事務級別進行實戰分析
1.什么是事務?
事務是應用程序中一系列嚴密的操作,所有操作必須成功完成,否則在每個操作中所作的所有更改都會被撤消。也就是事務具有原子性,一個事務中的一系列的操作要么全部成功,要么全部失敗
2.事務的基本要素
原子性(Atomicity):事務開始后所有操作,要么全部做完,要么全部不做,不可能停滯在中間環節。事務執行過程中出錯,會回滾到事務開始前的狀態。
一致性(Consistency):事 務執行的結果必須是使數據庫從一個一致性狀態變到另一個一致性狀態。因此當數據庫只包含成功事務提交的結果時,就說數據庫處于一致性狀態。
隔離性(Isolation):一個事務的執行不能其它事務干擾。即一個事務內部的操作及使用的數據對其它并發事務是隔離的,并發執行的各個事務之間不能互相干擾。
持久性(Durability):事務完成后,事務對數據庫的所有更新將被保存到數據庫,對數據庫中的數據的改變就應該是永久性,不能回滾。
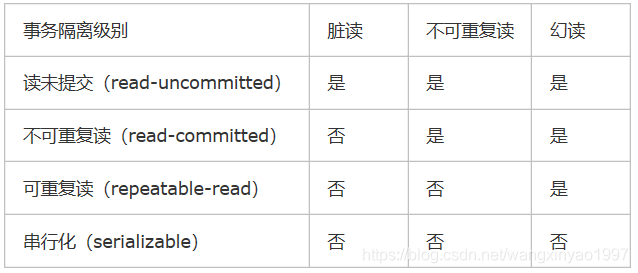
3.事務出現的并發問題
臟讀:事務A讀取了事務B更新的數據,然后B回滾操作,那么A讀取到的數據是臟數據
不可重復讀:事務 A 多次讀取同一數據,事務 B 在事務A多次讀取的過程中,對數據作了更新并提交,導致事務A多次讀取同一數據時,結果 不一致
幻讀:它發生在一個事務A讀取了幾行數據,接著另一個并發事務B插入了一些數據時。在隨后的查詢中,事務A就會發現多了一些原本不存在的記錄,就好像發生了幻覺一樣,所以稱為幻讀
4.事務的隔離級別
如上都是一些概念的東西,沒有什么意思,還是需要通過實戰來演示一下其中的原理以及奧秘,先放個圖:
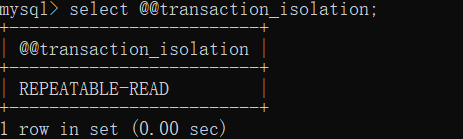
mysql默認的事務隔離級別是rr,也就是可重復讀級別(mysql8.0)
接下來通過操作數據庫對各個事物隔離級別以及實現的原理進行介紹:
1.讀未提交
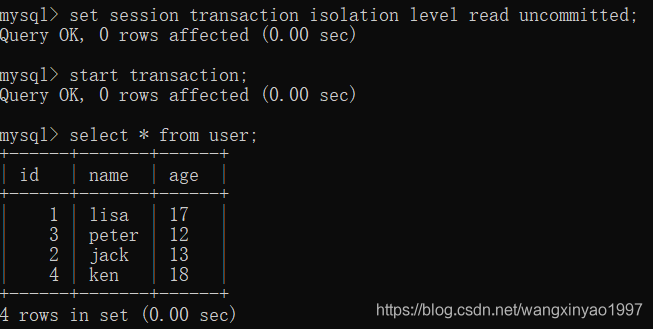
(1)打開一個mysql客戶端A,并設置當前事務模式為read uncommitted(未提交讀),開啟事務,查詢user表的所有記錄
- - >客戶端A
(2)在客戶端A的事務提交之前,打開另一個mysql客戶端B,開啟事務,更新表user
- - >客戶端 B

(3)此時,客戶端B的事務還沒提交,但是客戶端A就可查詢到B已經更新的數據
- - >客戶端A
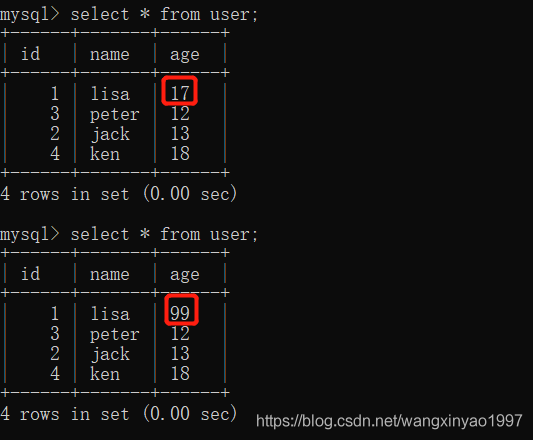
(4)一旦客戶端B的事務因為某種原因回滾,所有的操作都將會被撤銷,那客戶端A查詢到的數據其實就是臟數據
- - >客戶端 B
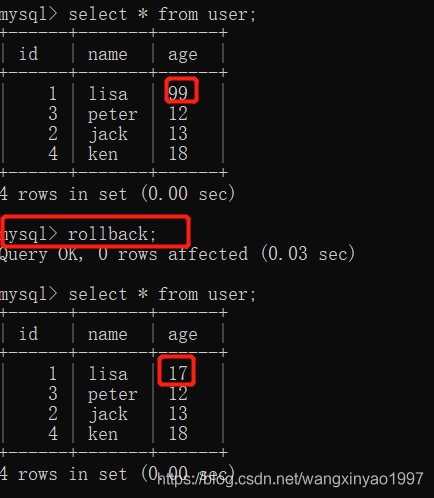
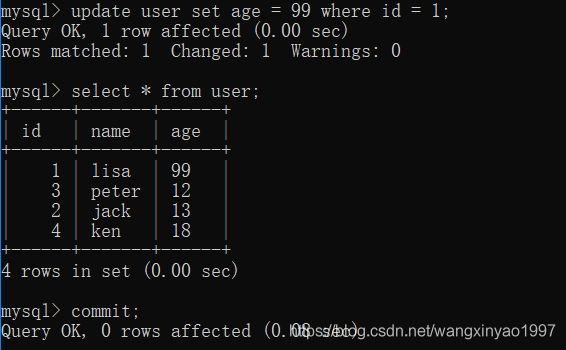
(5)在客戶端A執行更新語句update user set age = age + 1where id =1,可以看到 lisa 的 age 沒有變成100,而是18,導致數據不一致,這是因為在應用程序中,我們會用99+1=100,并不知道其他會話回滾,要想解決這個問題可以采用讀已提交的隔離級別
- - >客戶端A
2.讀已提交
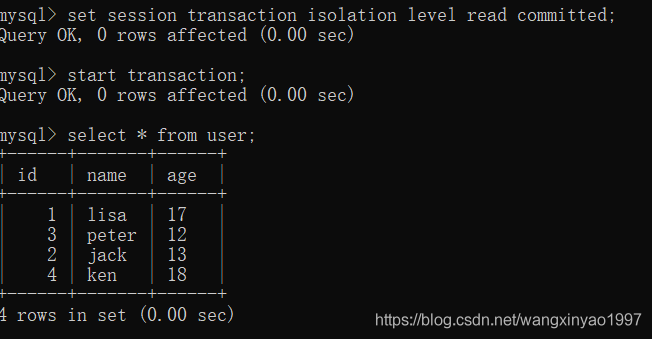
(1)打開一個客戶端A,并設置當前事務模式為read committed(未提交讀),開啟事務,查詢表user的所有記錄
- - >客戶端A
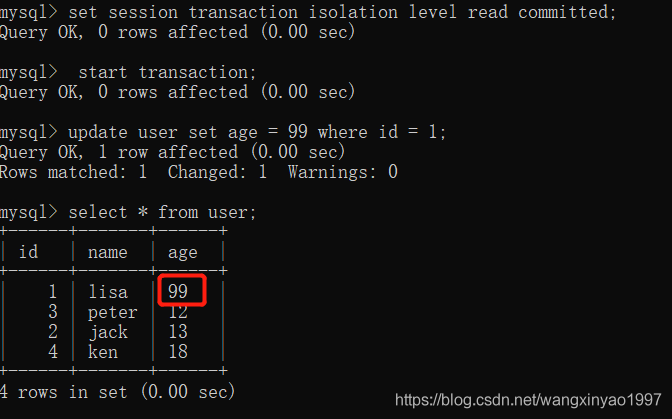
(2)在客戶端A的事務提交之前,打開另一個客戶端B,開啟事務,更新表user
- - >客戶端 B
(3)此時,客戶端B的事務還沒提交,客戶端A不能查詢到B已經更新的數據,解決了臟讀問題
- - >客戶端A
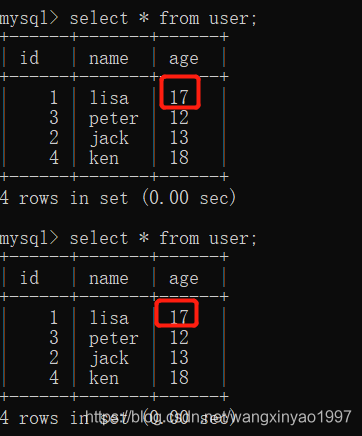
(4)客戶端B事務被提交
- - >客戶端B
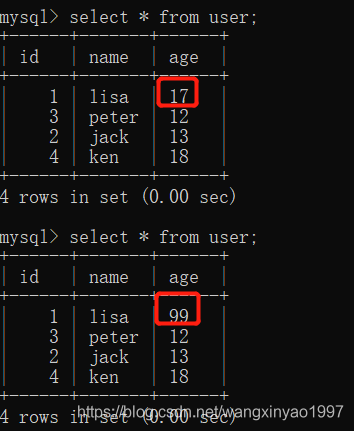
(5)客戶端A執行與上一步相同的查詢,結果 與上一步不一致,所以就產生了不可重復讀的問題,要想解決這個問題可以采用可重復讀的隔離級別
- - >客戶端A
3.可重復讀
(1)打開一個客戶端A,并設置當前事務模式為repeatable read,開啟事務,查詢表user的所有記錄
- - >客戶端A
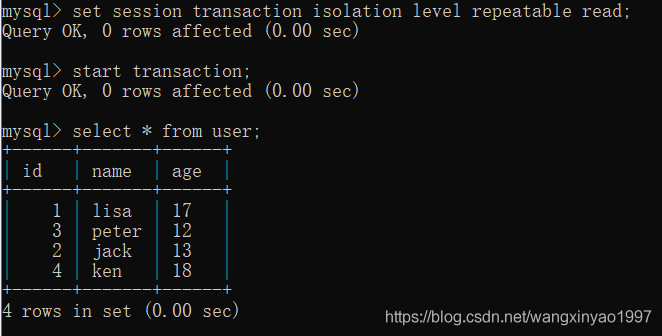
(2)在客戶端A的事務提交之前,打開另一個客戶端B,開啟事務,更新表user并提交
- - >客戶端B
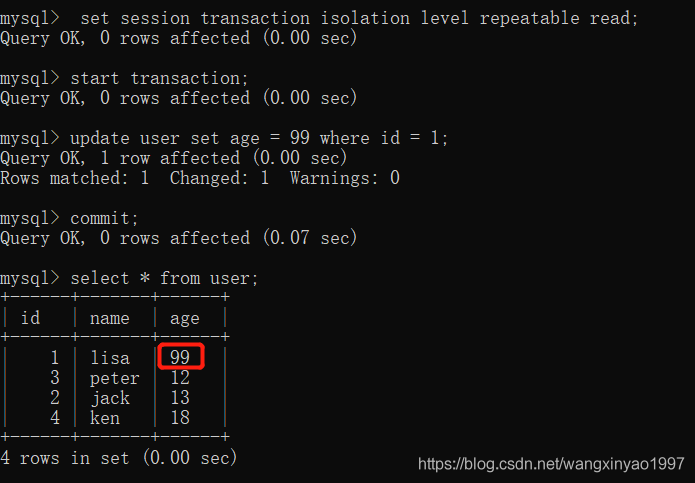
(3)在客戶端A查詢表user的所有記錄,與第一次查詢結果一致,沒有出現不可重復讀的問題
- - >客戶端A
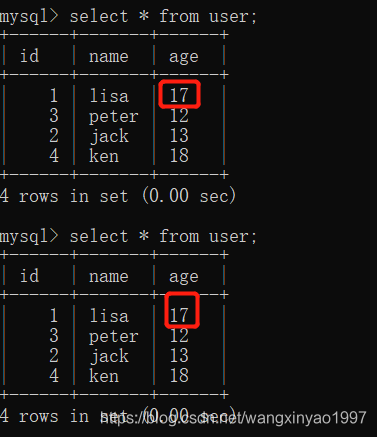
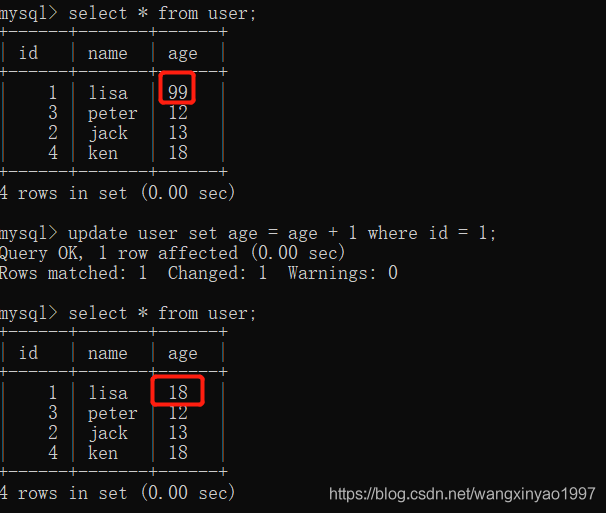
(4)在客戶端A,接著執行update user set age = age + 1 where id = 1,發現age沒有變成17+1=18,lisa的age值用的是步驟客戶端B中的99來算的,所以是100,數據的一致沒有被破壞。這是因為可重復讀的隔離級別下使用了MVCC機制,select操作不會更新版本號,是快照讀(歷史版本);而insert、update和delete會更新版本號,是當前讀(當前版本)。
- - >客戶端A
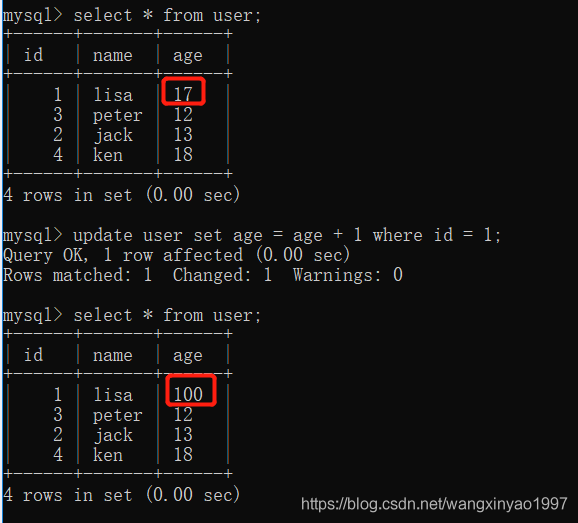
(5)重新打開客戶端B,開啟事務,插入一條新數據后提交
*- - >客戶端 B *

(6)在客戶端A查詢表user的所有記錄,沒有查出新增數據,但是卻發現讀的不是最新數據,這就是所謂的“幻讀”
- - >客戶端A
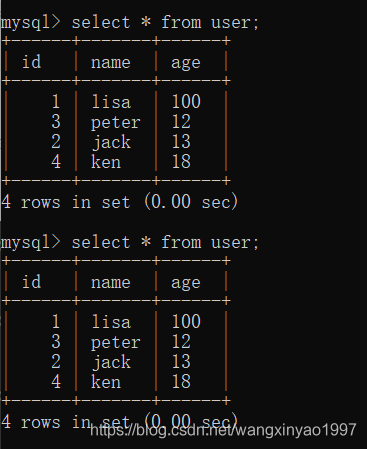
(7)在客戶端A提交本次事務,再次讀取數據,發現讀取正常
- - >客戶端A
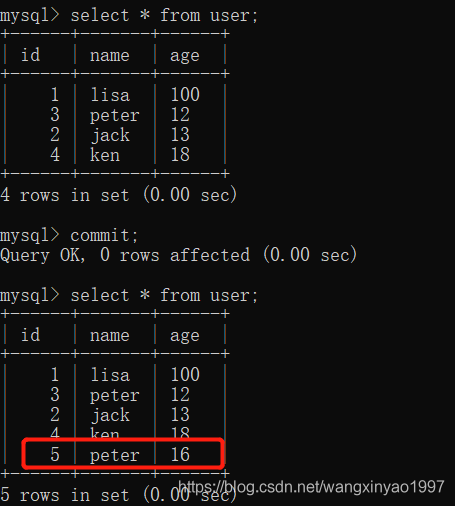
4.串行化
(1)打開一個客戶端A,并設置當前事務模式為可串行化(Serializable),開啟事務,查詢表user的所有記錄
- - >客戶端A
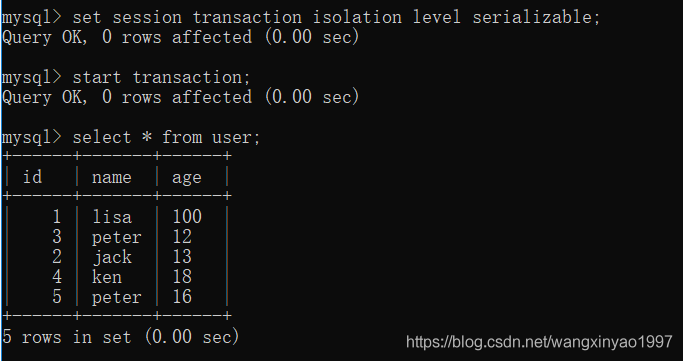
(2)打開一個客戶端B,并設置當前事務模式為可串行化(Serializable),開啟事務,向user表中新添加一條數據
- - >客戶端 B

(3)提交A客戶端事務,然后發現B客戶端插入數據成功
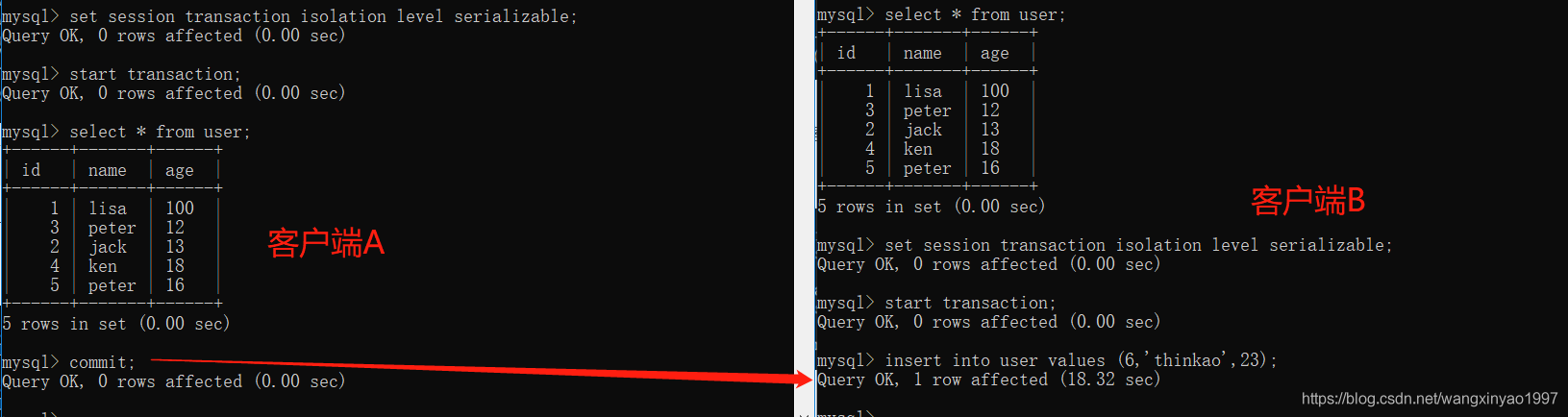
serializable完全鎖定字段,若一個事務來查詢同一份數據就必須等待,直到前一個事務完成并解除鎖定為止。是完整的隔離級別,會鎖定對應的數據表格,因而會有效率的問題
看這里↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
綜上就是針對于mysql事務各種隔離級別的原理實現以及解決辦法,在這里博主給各位游客出個mysql的面試題,你會嗎?
問題:兩個表結構完全相同,在不用not in的情況下根據name查出user表里有,但是user1表里沒有的數據
以此題為例:查詢結果是 gaowei,peter,jack 三條數據
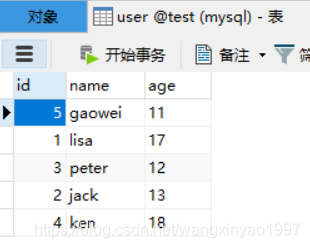












實例代碼)






