論文鏈接:https://arxiv.org/abs/1912.04488
代碼鏈接:https://github.com/WXinlong/SOLO
摘要
提出一種新的實例分割方法。與語義分割等其他密集預測任務相比,實例分割的難度要大得多。為了預測每個實例的掩碼,主流方法要么遵循“detect-then-segment”的策略,如Mask R-CNN所使用的策略,要么先預測嵌入向量,然后使用聚類技術將像素分組到單個實例中。通過引入“實例類別”的概念,文章從一個全新的角度來看待實例分割的任務,它根據實例的位置和大小為實例中的每個像素分配類別,從而很好地將實例掩碼分割轉化為一個可分類的問題。將實力分割分解為兩類任務。文章提出的框架在精確度上優于最近的單點實例分段器。
簡介
實例分割不僅要準確的分離圖像中的所有對象,還要求對每個實例實現像素級的語義分割。圖像中的對象屬于一組固定的語義范疇,但是實例的數量不同。因此,語義分割可以很容易地表述為密集的逐像素分類問題,而直接按照相同的范式預測實例標簽則是一個挑戰。
最近的實例分割方法可以分為兩類:自頂向下和自底向上的范例。前一種方法即“detect-then-segment”,首先檢測邊界盒,然后將實例掩碼分割到每個邊界盒中。后一種方法學習一種親緣關系,通過推離屬于不同實例的像素和拉近相同實例的像素,為每個像素分配一個嵌入向量。然后需要分組后處理來分離實例。這兩種范式都是步進式和間接式的,要么嚴重依賴準確的邊界盒檢測,要么依賴逐像素嵌入學習和分組處理。
目標:在完整實例掩碼注釋的監督下直接分割實例掩碼
提出問題:圖像中的對象實例之間的基本區別是什么?
發現:在大多數案例下,圖像中的兩個實例要么有不同的中心位置,要么有不同的對象大小
現今主流:目前占主導地位的范式利用了完全卷積的網絡(FCN)輸出N個信道的稠密預測
語義切分的目的:區分不同的語義類別
文章引入了“實例類別(instance categories)”的概念來區分圖像中的對象實例,量化的中心位置和對象大小,從而能夠按位置劃分對象
文章中提出的SOLO的核心思想是根據位置和大小分離對象實例。
原理:
位置 將圖象劃分為SxS的網格,從而產生 S^2 個中心位置類。根據對象中心的坐標,將對象實例分配給其中一個網格單元格,作為其中心位置類別。SOLO算法將中心位置類別編碼為通道軸,類似于語義分類中的語義類別。每個輸出通道負責一個中心位置類別,相應的通道映射應該預測屬于該類別的對象的實例掩碼。
本質上,實例類別近似于實例的對象中心位置.因此,通過將每個像素分類到其實例類別中,就相當于使用回歸從每個像素中預測目標中心。將位置預測任務轉換為分類而不是回歸
尺寸 為了區分不同對象大小的實例,文章采用了特征金字塔網絡(FPN),從而將不同尺寸的對象分配到不同層次的特征圖中,作為對象尺寸類。因此,所有的對象實例都是定期分離的,從而能夠通過“實例類”對對象進行分類。這里的FPN目的是檢測圖像中不同尺寸的目標。
FPN是SOLO的核心方法。
在SOLO框架中通過使用掩碼注釋,以端到端的方式對網絡進行優化。并跳出局部框劃分和像素分組的限制,進行像素級實例分割。
SOLO在COCO數據集上與Mask R-CNN取得同等結果。另外SOLO具有通用性。
本質上,SOLO將坐標回歸轉化為離散量化的分類。這樣做的一個優點是避免了啟發式協調規范化和日志轉換,這通常在YOLO之類的檢測器中使用.
相關工作
SOLO是完全無箱的,因此不受(錨)箱的位置和規模的限制,并自然受益于固有的優勢FCNs
SOLO不利用像素成對關系和像素分組,而是直接在訓練期間學習實例掩碼注釋,并端到端預測實例掩碼和語義類別,無需分組后處理。SOLO是一種直接的端到端實例分割方法
SOLO以圖像為輸入,直接輸出實例掩碼和對應的類概率,采用完全卷積、無盒、無組的范式。
我們的簡單網絡可以優化端到端,而不需要箱監督。為了進行預測,該網絡直接將輸入圖像映射到每個單獨實例的掩模中,既不依賴于RoI特征裁剪等中間操作,也不依賴于分組后處理。
SOLO
SOLO框架的核心思想是將實例分割重新定義為兩個同時存在的分類感知預測和實例感知掩碼生成問題。系統將輸入圖像劃分為均勻的SXS的網格,如果一個對象中心落到一個網格單元中,該網格單元格負責1)預測語義類別以及2)分割該對象實例。
在語義類別預測的同時,每個正網格單元也將生成相應的實例掩碼。對于一個輸入圖像I,如果我們把它分成S×S個網格,總共最多會有S^2個預測掩模。文章明確地在三維輸出張量的第三維(通道)編碼這些掩模。具體來說,實例掩碼輸出將具有Hi×Wi×S2Hi×Wi×S^2Hi×Wi×S2維。第k個通道負責在網格(i, j)處分段實例,其中k = i·S + j(i和j從零開始).為此,在語義類別和類不可知的掩碼之間建立了一一對應關系
SOLO需要一個在空間上變化的模型,或者更準確地說,位置敏感的模型,因為我們的分割掩模取決于網格單元,必須由不同的特征通道分開。
具體地說,文章創建了一個與輸入具有相同空間大小的張量,該張量包含歸一化為[?1,1]的像素坐標。然后這個張量被連接到輸入特征并傳遞到下面的層。通過讓卷積訪問它自己的輸入坐標,我們將空間功能添加到傳統的FCN模型中。如果原始特征張量的大小為H×W×D,則新張量的大小為H×W×(D+2),其中后兩個通道為x-y像素坐標。
形成實例分割
在SOLO中,類別預測和對應的掩模自然通過它們的參考網格單元k=i?S+jk = i · S + jk=i?S+j關聯起來。在此基礎上,SOLO可以直接形成每個網格的最終實例分割結果。原始實例分割結果是通過收集所有網格結果生成的。最后,使用非最大抑制(non-maximum-suppression, NMS)來獲得最終的實例分割結果。不需要其他后處理操作
網絡結構
我們使用FPN[11],它為每一層生成一個具有固定數量通道(通常為256-d)的不同大小的金字塔特征圖。這些映射用作每個預測頭的輸入:語義類別和實例掩碼。頭部的權重在不同層上共享。在這個場景中,只有最后的1×1 conv不共享。
在每個FPN特征級別上,我們附加兩個兄弟子網絡,一個用于實例類別預測(上),另一個用于實例掩碼分割(下)。在掩碼分支中,我們將x、y坐標和原始特征連接起來,對空間信息進行編碼。這里數字表示空間分辨率和通道。在圖中,我們以256個通道為例。箭頭表示卷積或插值。所有的卷積都是3×3,除了輸出conv。“Align”是指自適應池、插值或區域網格插值,在推理過程中,掩碼分支輸出進一步向上采樣到原始圖像大小。
SOLO 學習
標簽分配
對于類別預測分支,網絡需要給出每個S×S網格下的目標類別概率。具體來說,如果網格(i, j)落在任何ground truth掩碼的中心區域,則認為它是正樣本,反之則認為它是負樣本。使用中心采樣進行掩模類別分類。得到質點中心(n,m),寬w高h的mask,那么該實例的中心位置就是(n,m,w1,h1),其中w1=βw,h1=βh,β在文中設為β=0.2
Loss損失函數
L=Lcate+λLmaskL = L_{cate} + λL_{mask} L=Lcate?+λLmask?
這里的Lcate是傳統的語義類別分類的Focal Loss,Lmask是用于掩模預測的損失,λ=3

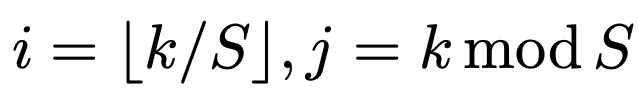
Npos表示正樣本的數量,p?和m?分別代表類別和掩模目標。ll是指示函數,當
Pi,j?>0P^*_{i,j} > 0 Pi,j??>0
時為1,否則為0.對于dmask,文章進行了一系列的對比,最終選用 Dice Loss(效果比BCE、Focal Loss好)。Dice Loss定義為
LDice=1?D(p,q),L_{Dice} = 1 ?D(p, q), LDice?=1?D(p,q),
D是骰子系數,定義為

px,y和qx,y分別是soft mask p和truth mask q位于(x, y)的像素值。
推論
前向傳播得到類別分數pi,j和相應的mask mk,其中k=i?S+j。首先使用置信閾值0.1來過濾低置信的預測,然后選取前500個排好序的mask進行NMS操作,然后用0.5的閾值進行mask二值化,保留前100個instance mask進行評估。
實驗
如何工作

這里我們可以看到不同的實例在不同的掩模預測通道上激活,通過顯式地在不同位置分割實例,SOLO將實例分割問題轉化為位置感知的分類任務。
在每個網格中只有一個實例被激活,并且一個實例可以被多個相鄰掩碼通道預測。在推斷期間,我們使用NMS來抑制這些冗余掩碼
消融實驗1
Grid number
將網格數對性能的影響與單一輸出特征圖進行了比較
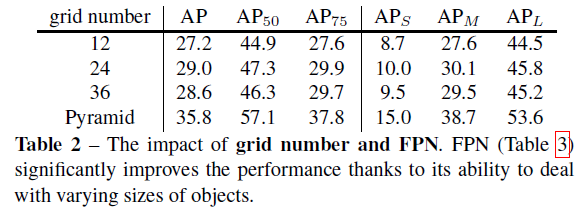
這一結果表明,我們的單尺度SOLO可以適用于一些對象尺度變化不大的場景。然而,單尺度模型在很大程度上滯后于金字塔模型,這說明了FPN在處理多尺度預測中的重要性。
Multi-level Prediction

從表2中我們可以看到,單尺度的SOLO在分割多尺度的對象時遇到了困難。在消融過程中,我們證明這個問題可以通過FPN的多級預測得到很大程度的解決,表3使用
五個FPN金字塔來分割不同尺度的對象.
CoordConv
另一個促進我們的SOLO模式的重要組成部分是空間變化的卷積(CoordConv )

一個單一的CoordConv已經使預測具有良好的空間變異/位置敏感性,過多無用。
Loss function.
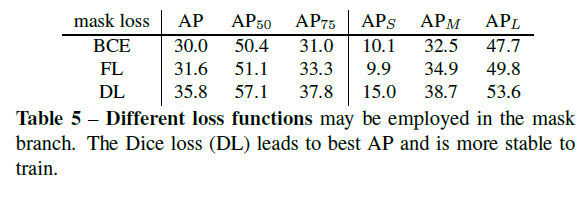
骰子損失(DL)導致最好的AP,訓練時更穩定
Different head depth
圖5中的結果顯示,當深度超過7時,性能會下降。所以使用的深度為7.
Decoupled SOLO
給定一個預先定義好的網格數,如 S=20S=20,這樣SOLO head就會輸出400個通道的特征圖。但是,這樣預測有些冗余,因為絕大多數場景中,圖像上的物體都是比較稀疏的,不太會出現特別多的物體實例。這一節,作者進一步介紹了一個等價的、更加高效率的 SOLO 模型的變體,稱為 Decoupled SOLO, 如下圖所示

在Decoupled SOLO中,原始的輸出張量
M∈RH×W×S2M∈R ^{H×W×S^2} M∈RH×W×S2
被替換為兩個輸出張量X∈R
H×W×S和Y∈R H×W×S ,對應著兩個坐標軸。因此,輸出空間就從HxWxS2 降低到了H×W×2S。對于網格位置為(i,j)的物體,原來的SOLO模型在輸出張量M的第k個通道上分割掩碼,其中k=i?S+j。而 Decoupled SOLO的物體掩碼預測,定義為兩個通道特征圖的 element-wise 相乘。
mk=xj?yim_k=x_j?y _i mk?=xj??yi?
其中xj,yi分別表示X的第j個通道圖,和Y的第i個通道圖。