1.下載
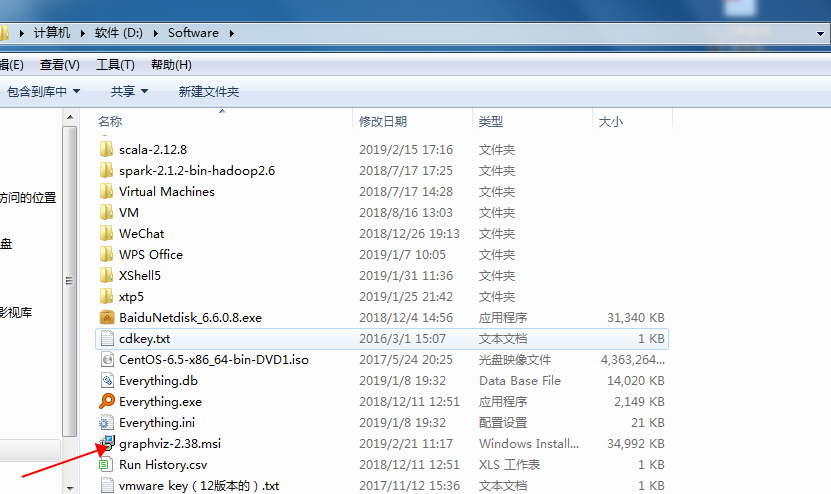
2.安裝:雙擊
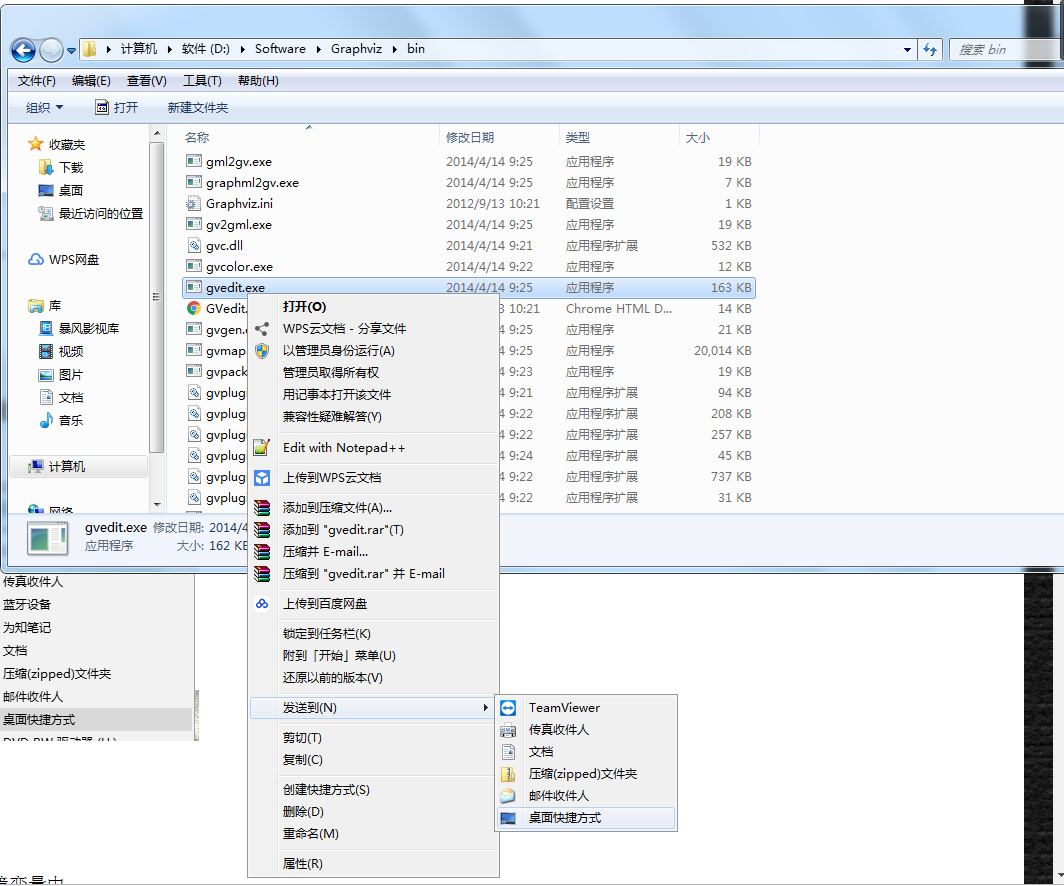
3.創建桌面快捷方式
安裝目錄\bin文件夾\:找到gvedit.exe文件右鍵 發送到桌面快捷方式,如下圖:
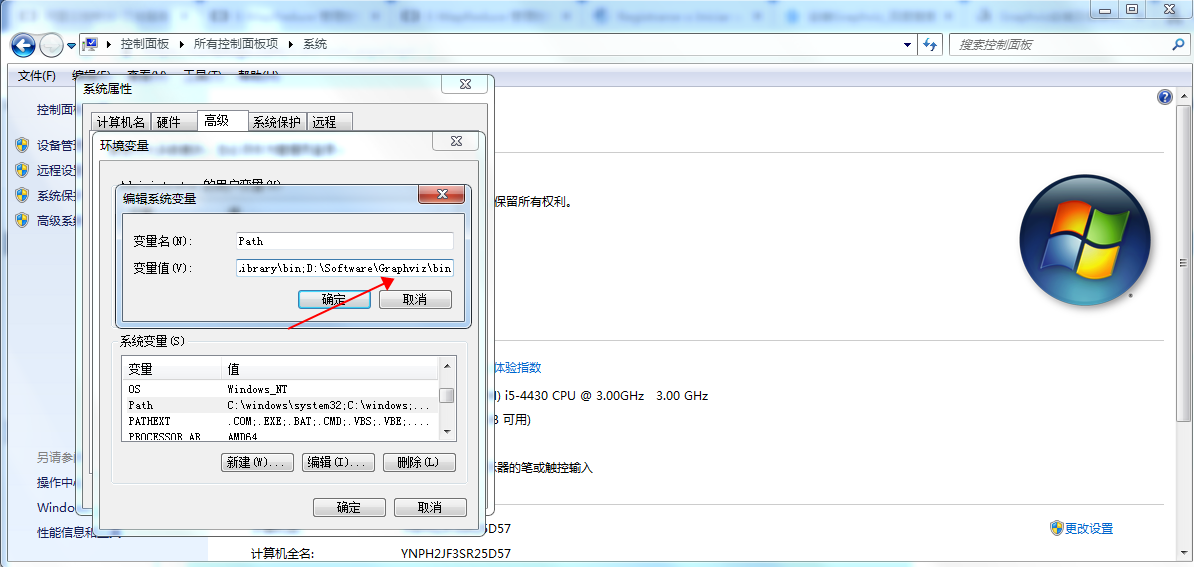
4.配置環境變量
將graphviz安裝目錄下的bin文件夾添加到Path環境變量中:
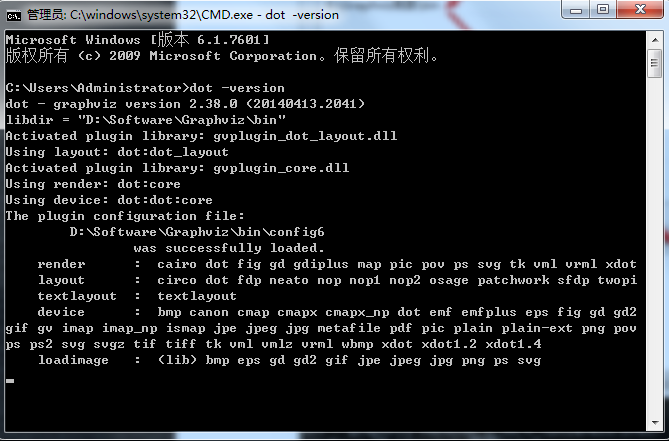
5.驗證是否安裝并配置成功
進入windows命令行界面,輸入dot -version,然后按回車,如果顯示graphviz的相關版本信息,則安裝配置成功。如圖:
6.python環境中安裝:(pycharm中)
File->Settings->Project:Python
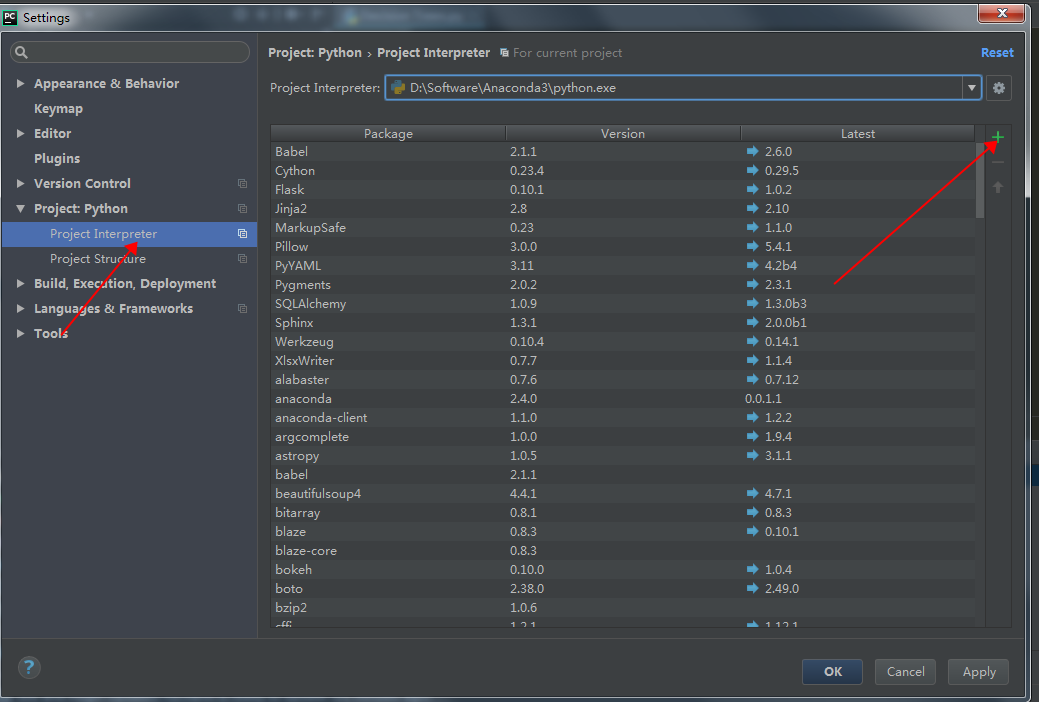
然后輸入graphivz安裝
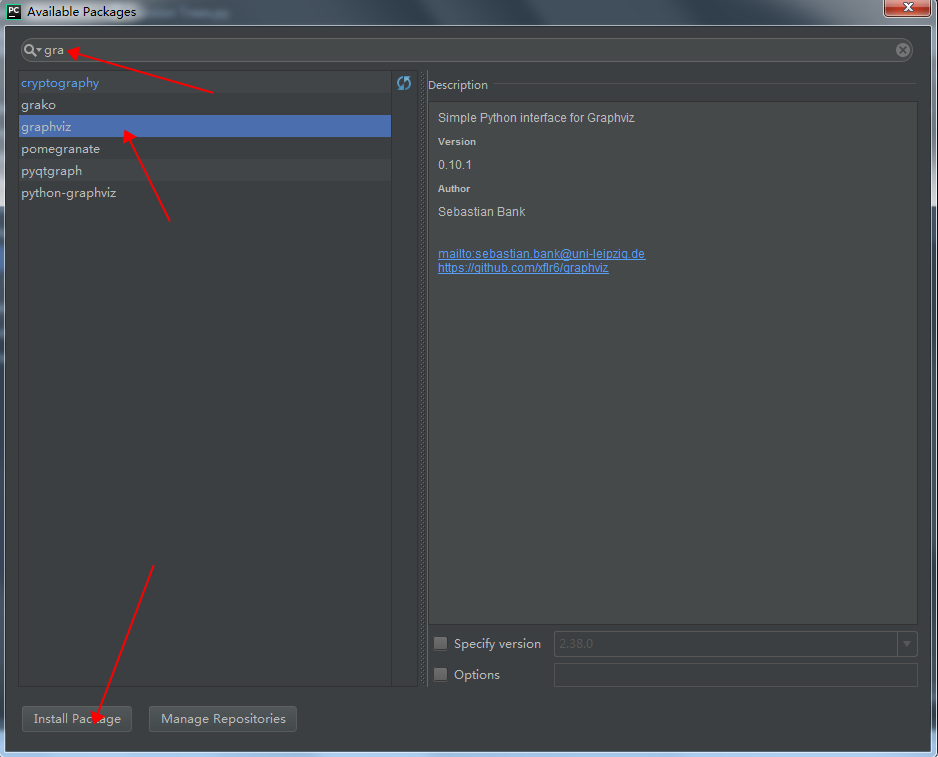
安裝需要等待一會。。。。
決策樹實戰代碼
# -*- coding:utf-8 -*-
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import preprocessing
from sklearn import tree
from sklearn.externals.six import StringIO
#read the csv file
allElectronicsDate = open(r'D:\Python\date\AllElectronics.csv','rt')
reader = csv.reader(allElectronicsDate)
headers = next(reader)
# headers = reader.next()
print(headers)#打印輸出第一行標題
#['RID', 'age', 'income', 'student', 'credit_rating', 'Class_buys_computer']
featureList = [] #用來存儲特征值
labelList = [] #用來存儲類標簽
#獲取特征值并打印輸出
for row in reader:
labelList.append(row[len(row) - 1])#每一行最后的值,類標簽
rowDict = {}
for i in range(1,len(row) - 1):#每一行 遍歷除第一列和最后一列的值
rowDict[headers[i]] = row[i]
featureList.append(rowDict)
print(featureList)
#vectorize feature 使用sklearn自帶的方法將特征值離散化為數字標記
vec = DictVectorizer()
dummyX = vec.fit_transform(featureList).toarray()
print("dummyY:" + str(dummyX))
print(vec.get_feature_names())
# print("feature_name" + str(vec.get_feature_names()))
print("labelList:" + str(labelList))
#vectorize class labels #數字化類標簽
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY:" + str(dummyY))
#use the decision tree for classification
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf = clf.fit(dummyX,dummyY) #構建決策樹
#打印構建決策樹采用的參數
print("clf:" + str(clf))
#visilize the model
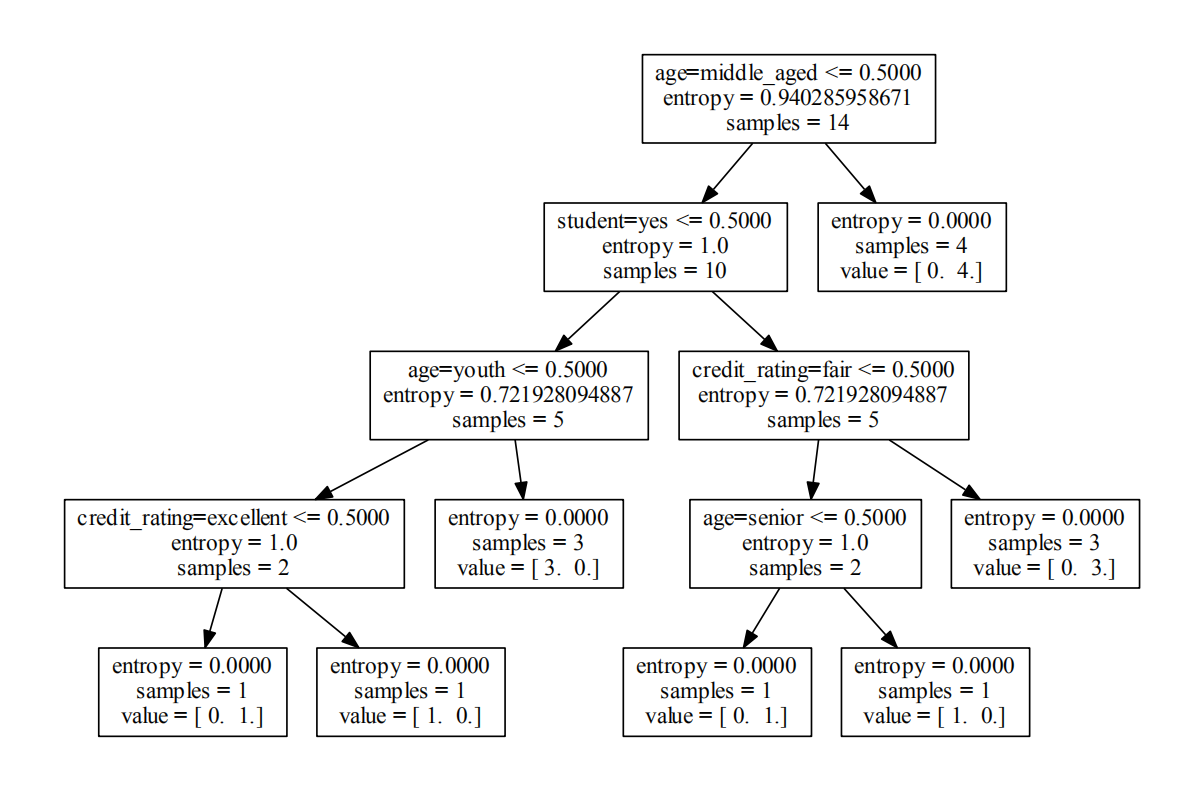
with open("allElectronicInformationGainOri.dot",'w') as f:
f=tree.export_graphviz(clf,feature_names=vec.get_feature_names(),out_file=f)
#這時就生成了allElectronicInformationGainOri.dot文件
# dot -Tpdf in.dot -o out.pdf dot文件輸出為pdf文件
#驗證數據,取出一行數據,修改幾個屬性預測結果
oneRowX = dummyX[0,:]
print("oneRowX:" + str(oneRowX))
newRowX = oneRowX
newRowX[0] = 1
newRowX[2] = 0
print("newRowX:" + str(newRowX))
predictedY = clf.predict(newRowX)
print("predictedY:"+str(predictedY))
結果:
['RID', 'age', 'income', 'student', 'credit_rating', 'class_buys_computer']
[{'income': 'high', 'age': 'youth', 'student': 'no', 'credit_rating': 'fair'}, {'income': 'high', 'age': 'youth', 'student': 'no', 'credit_rating': 'excellent'}, {'income': 'high', 'age': 'middle_aged', 'student': 'no', 'credit_rating': 'fair'}, {'income': 'medium', 'age': 'senior', 'student': 'no', 'credit_rating': 'fair'}, {'income': 'low', 'age': 'senior', 'student': 'yes', 'credit_rating': 'fair'}, {'income': 'low', 'age': 'senior', 'student': 'yes', 'credit_rating': 'excellent'}, {'income': 'low', 'age': 'middle_aged', 'student': 'yes', 'credit_rating': 'excellent'}, {'income': 'medium', 'age': 'youth', 'student': 'no', 'credit_rating': 'fair'}, {'income': 'low', 'age': 'youth', 'student': 'yes', 'credit_rating': 'fair'}, {'income': 'medium', 'age': 'senior', 'student': 'yes', 'credit_rating': 'fair'}, {'income': 'medium', 'age': 'youth', 'student': 'yes', 'credit_rating': 'excellent'}, {'income': 'medium', 'age': 'middle_aged', 'student': 'no', 'credit_rating': 'excellent'}, {'income': 'high', 'age': 'middle_aged', 'student': 'yes', 'credit_rating': 'fair'}, {'income': 'medium', 'age': 'senior', 'student': 'no', 'credit_rating': 'excellent'}]
dummyY:[[ 0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]
[ 0. 0. 1. 1. 0. 1. 0. 0. 1. 0.]
[ 1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
[ 0. 1. 0. 0. 1. 0. 0. 1. 1. 0.]
[ 0. 1. 0. 0. 1. 0. 1. 0. 0. 1.]
[ 0. 1. 0. 1. 0. 0. 1. 0. 0. 1.]
[ 1. 0. 0. 1. 0. 0. 1. 0. 0. 1.]
[ 0. 0. 1. 0. 1. 0. 0. 1. 1. 0.]
[ 0. 0. 1. 0. 1. 0. 1. 0. 0. 1.]
[ 0. 1. 0. 0. 1. 0. 0. 1. 0. 1.]
[ 0. 0. 1. 1. 0. 0. 0. 1. 0. 1.]
[ 1. 0. 0. 1. 0. 0. 0. 1. 1. 0.]
[ 1. 0. 0. 0. 1. 1. 0. 0. 0. 1.]
[ 0. 1. 0. 1. 0. 0. 0. 1. 1. 0.]]
['age=middle_aged', 'age=senior', 'age=youth', 'credit_rating=excellent', 'credit_rating=fair', 'income=high', 'income=low', 'income=medium', 'student=no', 'student=yes']
labelList:['no', 'no', 'yes', 'yes', 'yes', 'no', 'yes', 'no', 'yes', 'yes', 'yes', 'yes', 'yes', 'no']
dummyY:[[0]
[0]
[1]
[1]
[1]
[0]
[1]
[0]
[1]
[1]
[1]
[1]
[1]
[0]]
clf:DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
random_state=None, splitter='best')
oneRowX:[ 0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]
newRowX:[ 1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
predictedY:[1]
在項目路徑里面打開dot文件

將dot文件轉化為直觀的PDF文件(dos 里面輸入dot -Tpdf D:\Python\機器學習\allElectronicInformationGainOri.dot -o D:\Python\機器學習\out.pdf 然后回車)
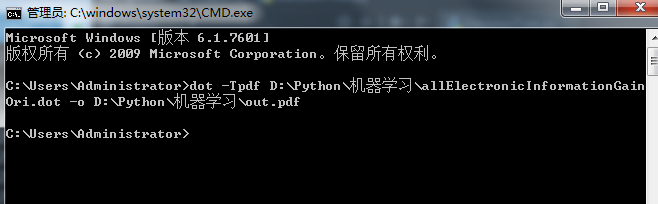
dot -Tpdf D:\Python\機器學習\allElectronicInformationGainOri.dot -o D:\Python\機器學習\out.pdf


)


...)











函數(指南))
爬取天涯論壇評論)
![python快遞費用計算_[Python]簡單用Python寫個查詢快遞的程序最后附源代碼](http://pic.xiahunao.cn/python快遞費用計算_[Python]簡單用Python寫個查詢快遞的程序最后附源代碼)