
簡介
StringTable是什么?它和String.intern有什么關系呢?在字符串對象的創建過程中,StringTable有起到了什么作用呢?
一切的答案都在本文中,快來看看吧。
intern簡介
intern是String類中的一個native方法,所以它底層是用c++來實現的。感興趣的同學可以去查看下JVM的源碼了解更多的內容。
這里我們主要談一下intern的作用。
intern返回的是這個String所代表的對象,怎么理解呢?
String class維護了一個私有的String pool, 這個String pool也叫StringTable,中文名字叫做字符串常量池。
當我們調用intern方法的時候,如果這個StringTable中已經包含了一個相同的String對象(根據equals(Object)方法來判斷兩個String對象是否相等),那么將會直接返回保存在這個StringTable中的String。
如果StringTable中沒有相同的對象,那么這個String對象將會被加入StringTable,并返回這個String對象的引用。
所以,當且僅當 s.equals(t) 的時候s.intern() == t.intern()。
intern和字符串字面量常量
我們知道在類文件被編譯成class文件時,每個class文件都有一個常量池,常量池中存了些什么東西呢?
字符串常量,類和接口名字,字段名,和其他一些在class中引用的常量。
看一個非常簡單的java類:
public class SimpleString {public String site="www.flydean.com";
}然后看一下編譯出來的class文件中的Constant Pool:
Constant pool:#1 = Methodref #2.#3 // java/lang/Object."<init>":()V#2 = Class #4 // java/lang/Object#3 = NameAndType #5:#6 // "<init>":()V#4 = Utf8 java/lang/Object#5 = Utf8 <init>#6 = Utf8 ()V#7 = String #8 // www.flydean.com#8 = Utf8 www.flydean.com#9 = Fieldref #10.#11 // com/flydean/SimpleString.site:Ljava/lang/String;#10 = Class #12 // com/flydean/SimpleString#11 = NameAndType #13:#14 // site:Ljava/lang/String;#12 = Utf8 com/flydean/SimpleString#13 = Utf8 site#14 = Utf8 Ljava/lang/String;#15 = Utf8 Code#16 = Utf8 LineNumberTable#17 = Utf8 LocalVariableTable#18 = Utf8 this#19 = Utf8 Lcom/flydean/SimpleString;#20 = Utf8 SourceFile#21 = Utf8 SimpleString.java上面的結果,我們可以看到class常量池中的index 7存放了一個字符串,這個字符串的實際內容存放在index 8中,是一個變種的Utf8的編碼。
#7 = String #8 // www.flydean.com#8 = Utf8 www.flydean.com好了,現在問題來了,class文件中的常量池在運行時需要轉換成為JVM能夠識別的運行時常量池,這個運行時的常量池和StringTable和intern有什么關系呢?
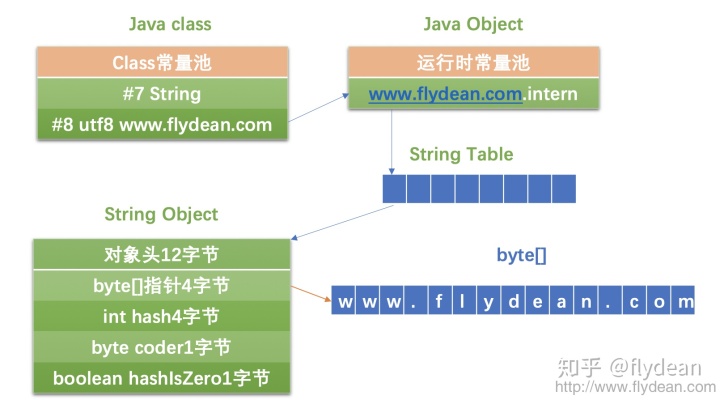
在java對象的實例化過程中,所有的字符串字面量都會在實例化的時候自動調用intern方法。
如果是第一次調用,則會創建新的String對象,存放在String Table中,并返回該String對象的引用。
分析intern返回的String對象
從上面的圖中,我們也可以出來String Table中存儲的是一個String對象,它和普通的String對象沒有什么區別,也分為對象頭,底層的byte數組引用,int hash值等。
如果你不相信,可以使用JOL來進行分析:
log.info("{}", ClassLayout.parseInstance("www.flydean.com".intern()).toPrintable());看下輸出結果:
INFO com.flydean.StringInternJOL - java.lang.String object internals:OFFSET SIZE TYPE DESCRIPTION VALUE0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)8 4 (object header) 77 1a 06 00 (01110111 00011010 00000110 00000000) (399991)12 4 byte[] String.value [119, 119, 119, 46, 102, 108, 121, 100, 101, 97, 110, 46, 99, 111, 109]16 4 int String.hash 020 1 byte String.coder 021 1 boolean String.hashIsZero false22 2 (loss due to the next object alignment)
Instance size: 24 bytes
Space losses: 0 bytes internal + 2 bytes external = 2 bytes total分析實際的問題
有了上面的知識,讓我們分析一下下面的實際問題吧:
String a =new String(new char[]{'a','b','c'});String b = a.intern();System.out.println(a == b);String x =new String("def");String y = x.intern();System.out.println(x == y);兩個很簡單的例子,答案是什么呢? 答案是true和false。
第一個例子按照上面的原理很好理解,在構建String a的時候,String table中并沒有”abc“這個字符串實例。所以intern方法會將該對象添加到String table中,并返回該對象的引用。
所以a和b其實是一個對象,返回true。
那么第二個例子呢?初始化String的時候,不是也沒有”def“這個字符串嗎?為什么回返回false呢?
還記得我們上面一個小節分析的嗎?所有的字符串字面量在初始化的時候會默認調用intern方法。
也就是說”def“在初始化的時候,已經調用了一次intern了,這個時候String table中已經有”def“這個String了。
所以x和y是兩個不同的對象,返回的是false。
注意,上面的例子是在JDK7+之后運行的,如果你是在JDK6中運行,那么得到的結果都是false。
JDK6和JDK7有什么不同呢?
在JDK6中,StringTable是存放在方法區中的,而方法區是放在永久代中的。每次調用intern方法,如果String Table中不存在該String對象,則會將該String對象進行一次拷貝,并返回拷貝后String對象的引用。
因為做了一次拷貝,所以引用的不是同一個對象了。結果為false。
在JDK7之后,StringTable已經被轉移到了java Heap中了,調用intern方法的時候,StringTable可以直接將該String對象加入StringTable,從而指向的是同一個對象。
G1中的去重功能
如果頻繁的進行String的復制,實際上是非常消耗內存空間的。所以在G1垃圾回收器中,可以使用下面的:
-XX:+UseStringDeduplication來開啟String的去重功能。
我們還記得String對象的底層結構吧,就是一個byte[]數組,String去重的原理就是讓多個字符串對象底層的byte數組指向同一個地方。從而節省內存。
我們可以通過使用:
-XX:+PrintStringTableStatistics參數來查看StringTable的大小。并通過:
-XX:StringTableSizen=n來指定StringTable的大小。
總結
本文講了String.intern和String table的關系,如果有什么錯誤或者遺漏的地方,歡迎大家留言給我!
本文作者:flydean程序那些事本文鏈接:http://www.flydean.com/jvm-string-intern/本文來源:flydean的博客歡迎關注我的公眾號:程序那些事,更多精彩等著您!














)




