NVIDIA英偉達的Multi-GPU多卡通信框架NCCL
筆者注:NCCL 開源項目地址:https://github.com/NVIDIA/nccl
轉自:https://www.zhihu.com/question/63219175/answer/206697974
NCCL是Nvidia Collective multi-GPU Communication Library的簡稱,它是一個實現多GPU的collective communication通信(all-gather, reduce, broadcast)庫,Nvidia做了很多優化,以在PCIe、Nvlink、InfiniBand上實現較高的通信速度。
下面分別從以下幾個方面來介紹NCCL的特點,包括基本的communication primitive、ring-base collectives、NCCL在單機多卡上以及多機多卡實現、最后分享實際使用NCCL的一些經驗。
communication primitive
并行任務的通信一般可以分為Point-to-point communication和Collective communication。P2P通信這種模式只有一個sender和一個receiver,實現起來比較簡單。第二種Collective communication包含多個sender多個receiver,一般的通信原語包括broadcast, gather, all-gather, scatter, reduce, all-reduce, reduce-scatter, all-to-all等。簡單介紹幾個常用的操作:
Reduce:從多個sender那里接收數據,最終combine到一個節點上。
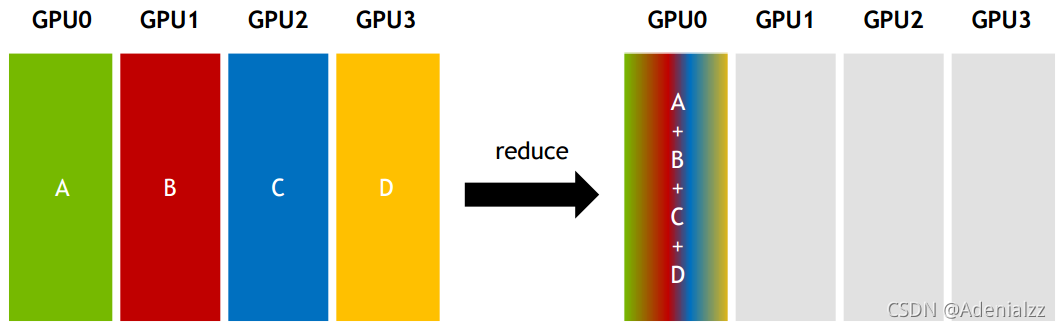
All-reduce:從多個sender那里接收數據,最終combine到每一個節點上。
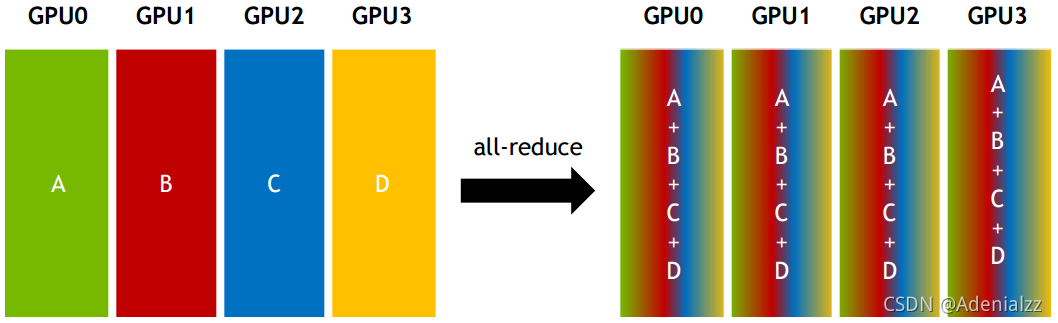
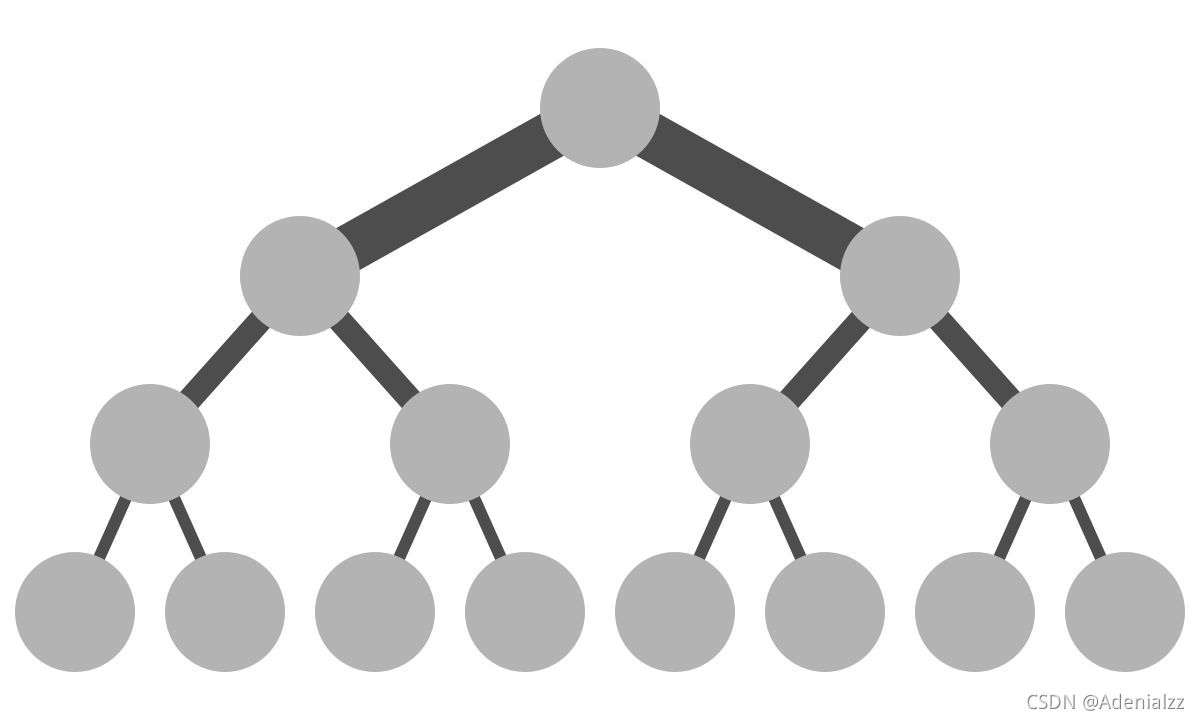
而傳統Collective communication假設通信節點組成的topology是一顆fat tree,如下圖所示,這樣通信效率最高。但實際的通信topology可能比較復雜,并不是一個fat tree。因此一般用ring-based Collective communication。
ring-base collectives
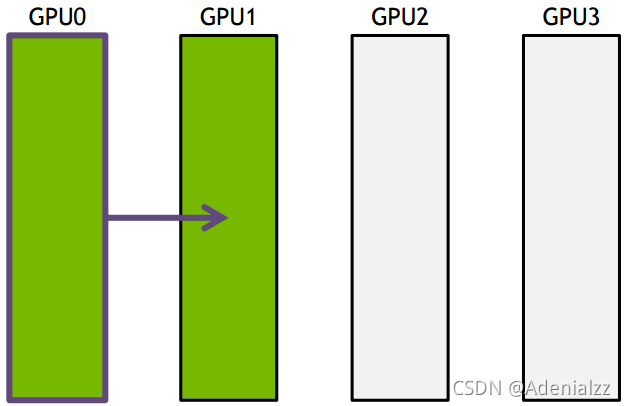
ring-base collectives將所有的通信節點通過首尾連接形成一個單向環,數據在環上依次傳輸。以broadcast為例, 假設有4個GPU,GPU0為sender將信息發送給剩下的GPU,按照環的方式依次傳輸,GPU0–>GPU1–>GPU2–>GPU3,若數據量為N,帶寬為B,整個傳輸時間為(K-1)N/B。時間隨著節點數線性增長,不是很高效。
下面把要傳輸的數據分成S份,每次只傳N/S的數據量,傳輸過程如下所示:
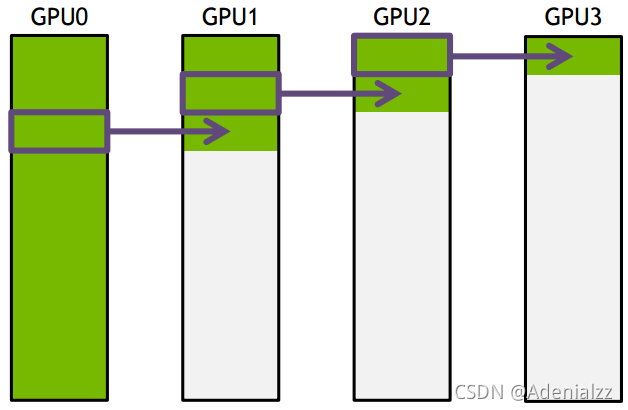
GPU1接收到GPU0的一份數據后,也接著傳到環的下個節點,這樣以此類推,最后花的時間為 S*(N/S/B) + (k-2)*(N/S/B) = N(S+K-2)/(SB) --> N/B,條件是S遠大于K,即數據的份數大于節點數,這個很容易滿足。所以通信時間不隨節點數的增加而增加,只和數據總量以及帶寬有關。其它通信操作比如reduce、gather以此類推。
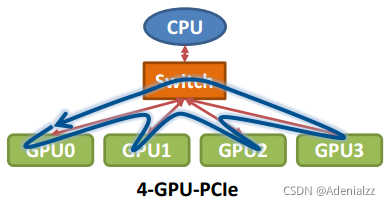
那么在以GPU為通信節點的場景下,怎么構建通信環呢?如下圖所示:
單機4卡通過同一個PCIe switch掛載在一棵CPU的場景:
單機8卡通過兩個CPU下不同的PCIe switch掛載的場景:

NCCL實現
NCCL實現成CUDA C++ kernels,包含3種primitive operations: Copy,Reduce,ReduceAndCopy。目前NCCL 1.0版本只支持單機多卡,卡之間通過PCIe、NVlink、GPU Direct P2P來通信。NCCL 2.0會支持多機多卡,多機間通過Sockets (Ethernet)或者InfiniBand with GPU Direct RDMA通信。
下圖所示,單機內多卡通過PCIe以及CPU socket通信,多機通過InfiniBand通信。

同樣,在多機多卡內部,也要構成一個通信環

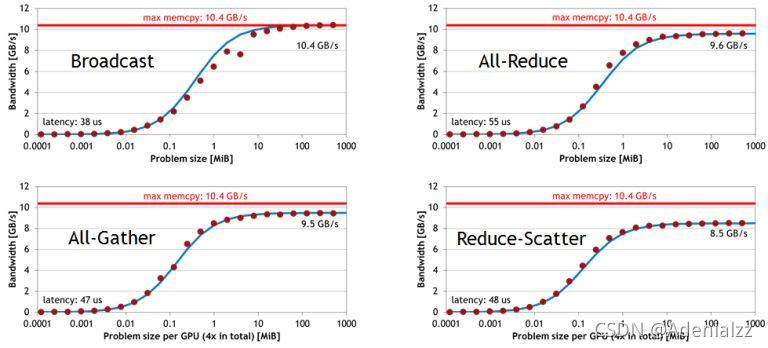
下面是單機 4卡(Maxwel GPU)上各個操作隨著通信量增加的帶寬速度變化,可以看到帶寬上限能達到10GB/s,接近PCIe的帶寬。
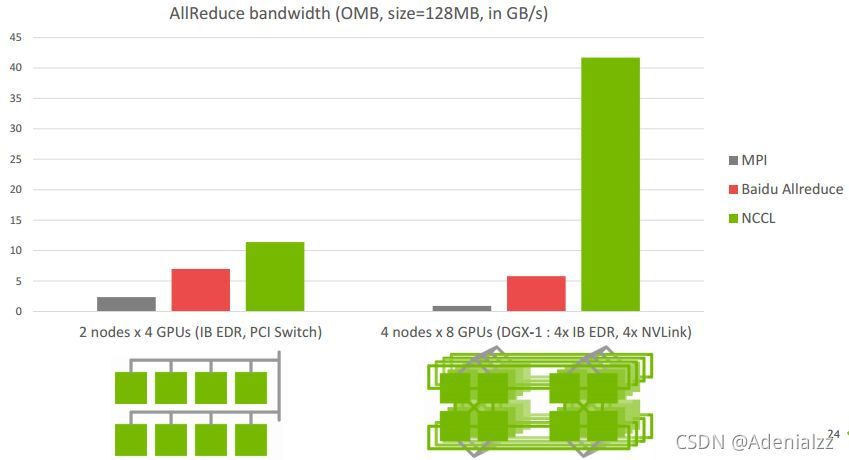
下圖是Allreduce在單機不同架構下的速度比較:
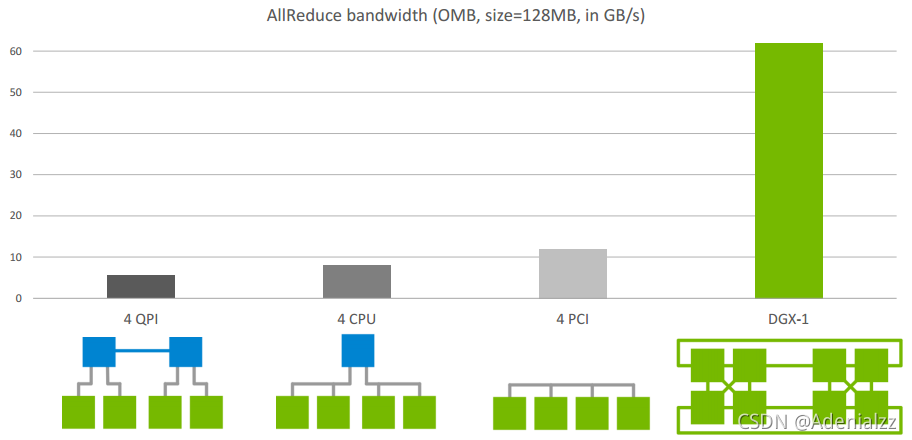
先不看DGX-1架構,這是Nvidia推出的深度學習平臺,帶寬能達到60GB/s。前面三個是單機多卡典型的三種連接方式,第三種是四張卡都在一個PCIe switch上,所以帶寬較高,能達到>10GB/s PCIe的帶寬大小,第二種是兩個GPU通過switch相連后再經過CPU連接,速度會稍微低一點,第一種是兩個GPU通過CPU然后通過QPI和另一個CPU上的兩塊卡相連,因此速度最慢,但也能達到>5GB/s。
下圖是Allreduce多機下的速度表現,左圖兩機8卡,機內PCIe,機間InfiniBand能達到>10GB/s的速度,InfiniBand基本上能達到機內的通信速度。
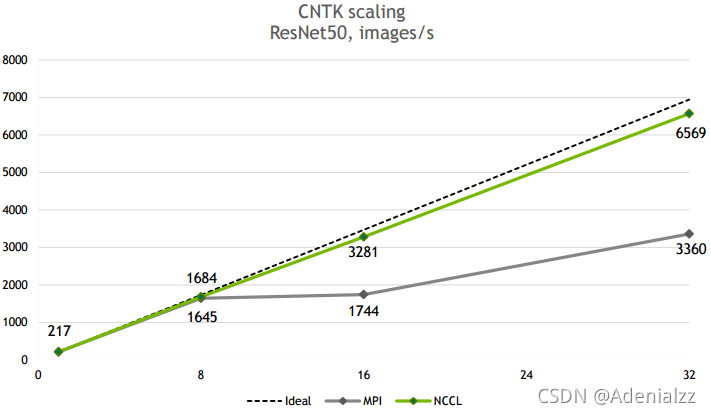
下圖是NCCL在CNTK ResNet50上的scalability,32卡基本能達到線性加速比。
我們的實測實驗
首先,在一臺K40 GPU的機器上測試了GPU的連接拓撲(筆者注:可在命令行通過nvidia-smi topo --matrix查看),如下:
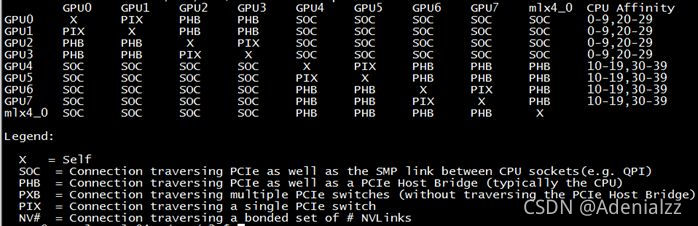
可以看到前四卡和后四卡分別通過不同的CPU組連接,GPU0和GPU1直接通過PCIe switch相連,然后經過CPU與GPU2和GPU3相連。
下面是測試PCIe的帶寬,可以看到GPU0和GU1通信能達到10.59GB/s,GPU0同GPU2~3通信由于要經過CPU,速度稍慢,和GPU4~7的通信需要經過QPI,所以又慢了一點,但也能達到9.15GB/s。

而通過NVlink連接的GPU通信速度能達到35GB/s:

NCCL在不同的深度學習框架(CNTK/Tensorflow/Torch/Theano/Caffe)中,由于不同的模型大小,計算的batch size大小,會有不同的表現。比如上圖中CNTK中Resnet50能達到32卡線性加速比,Facebook之前能一小時訓練出ImageNet,而在NMT任務中,可能不會有這么大的加速比。因為影響并行計算效率的因素主要有并行任務數、每個任務的計算量以及通信時間。我們不僅要看絕對的通信量,也要看通信和計算能不能同時進行以及計算/通信比,如果通信占計算的比重越小,那么并行計算的任務會越高效。NMT模型一般較大,多大幾十M上百M,不像現在image的模型能做到幾M大小,通信所占比重會較高。
下面是NMT模型單機多卡加速的一個簡單對比圖:

以上就是對NCCL的一些理解,很多資料也是來自于NCCL的官方文檔,歡迎交流討論。

![[分布式訓練] 單機多卡的正確打開方式:理論基礎](http://pic.xiahunao.cn/[分布式訓練] 單機多卡的正確打開方式:理論基礎)






)









)
