Linux下的ELF文件、鏈接、加載與庫
鏈接是將將各種代碼和數據片段收集并組合為一個單一文件的過程,這個文件可以被加載到內存并執行。鏈接可以執行與編譯時,也就是在源代碼被翻譯成機器代碼時;也可以執行于加載時,也就是被加載器加載到內存執行時;甚至執行于運行時,也就是由應用程序來執行。
本文主要參考[原創] Linux環境下:程序的鏈接, 裝載和庫,[完結] 2020 南京大學 “操作系統:設計與實現” (蔣炎巖)兩個視頻課程,并有CSAPP中介紹的一些內容。
常用工具
我們首先列出一些在接下來的介紹過程中會頻繁使用的分析工具,如果從事操作系統相關的較底層的工作,那這些工具應該再熟悉不過了。不熟悉的讀者可以先看一下這里的簡單的功能介紹,我們會在后文中介紹一些詳細的參數選項和使用場景。
另外,建議大家在遇到自己不熟悉的命令時,通過 man 命令來查看手冊,這是最權威的、第一手的資料。
| 工具 | 功能 |
|---|---|
| strace | 跟蹤程序執行過程中產生的系統調用及接收到的信號 |
| readelf | 用于查看ELF格式的文件信息 |
| file | 用于辨識文件類型 |
| objdump | 以一種可閱讀的格式讓你更多地了解二進制文件可能帶有的附加信息 |
| ldd | 列出一個程序所需要得動態鏈接庫 |
| hexdump | hexdump主要用來查看“二進制”文件的十六進制編碼 |
| ar | 創建靜態庫,插入/刪除/列出/提取 成員函數 |
| strings | 列出目標文件中所有可打印的字符串 |
| nm | 列出目標文件中符號表所定義的符號 |
| strip | 從目標文件中刪除符號表的信息 |
| size | 列出目標文件中各個段的大小 |
ELF文件詳解
ELF文件的三種形式
在Linux下,可執行文件/動態庫文件/目標文件(可重定向文件)都是同一種文件格式,我們把它稱之為ELF文件格式。雖然它們三個都是ELF文件格式但都各有不同。以下文件的格式信息可以通過 file 命令來查看。
-
可重定位(relocatable)目標文件:通常是
.o文件。包含二進制代碼和數據,其形式可以再編譯時與其他可重定位目標文件合并起來,創建一個可執行目標文件。 -
可執行(executable)目標文件:是完全鏈接的可執行文件,即靜態鏈接的可執行文件。包含二進制代碼和數據,其形式可以被直接復制到內存并執行。
-
共享(shared)目標文件:通常是
.so動態鏈接庫文件或者動態鏈接生成的可執行文件。一種特殊類型的可重定位目標文件,可以在加載或者運行時被動態地加載進內存并鏈接。注意動態庫文件和動態鏈接生成的可執行文件都屬于這一類。會在最后一節辨析時詳細區分。
因為我們知道ELF的全稱:Executable and Linkable Format,即 ”可執行、可鏈接格式“,很顯然這里的三個ELF文件形式要么是可執行的、要么是可鏈接的。
其實還有一種core文件,也屬于ELF文件,在core dumped時可以得到。我們這里暫且不提。
注意:在Linux中并不以后綴名作為區分文件格式的絕對標準。
節頭部表和程序頭表和ELF頭
在我們的ELF文件中,有兩張重要的表:節頭部表(Section Tables)和程序頭表(Program Headers)。可以通過readelf -l [fileName]和readelf -S [fileName]來查看。
但并不是所有以上三種ELF的形式都有這兩張表,
- 如果用于編譯和鏈接(可重定位目標文件),則編譯器和鏈接器將把elf文件看作是節頭表描述的節的集合,程序頭表可選。
- 如果用于加載執行(可執行目標文件),則加載器則將把elf文件看作是程序頭表描述的段的集合,一個段可能包含多個節,節頭部表可選。
- 如果是共享目標文件,則兩者都含有。因為鏈接器在鏈接的時候需要節頭部表來查看目標文件各個 section 的信息然后對各個目標文件進行鏈接;而加載器在加載可執行程序的時候需要程序頭表 ,它需要根據這個表把相應的段加載到進程自己的的虛擬內存(虛擬地址空間)中。
我們在后面的還會詳細介紹這兩張表。
此外,整個ELF文件的前64個字節,成為ELF頭,可以通過readelf -h [fileName]來查看。我們也會在后面詳細介紹。
可重定位ELF文件的內容分析
#include <elf.h>,該頭文件通常在/usr/include/elf.h,可以自己vim查看。
首先有一個64字節的ELF頭Elf64_Ehdr,其中包含了很多重要的信息(可通過readelf -h [fileName]來查看),這些信息中有一個很關鍵的信息叫做Start of section headers,它指明了節頭部表,Section Headers Elf64_Shdr的位置。段表中儲存了ELF文件中各個的偏移量以記錄其位置。ELF中的各個段可以通過readelf -S [fileName]來查看。下表是up主@fengzimu2003總結的ELF文件的內容:
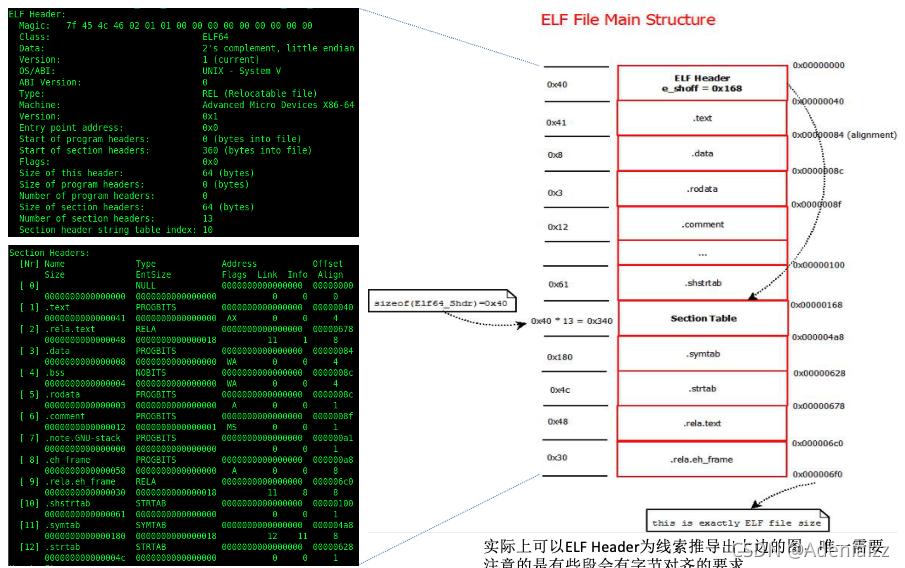
其中各個節的含義如下:
| 名稱 | 意義 |
|---|---|
.text | 已編譯程序的機器代碼 |
.rodata | 只讀數據 |
.data | 已初始化的全局變量和靜態變量 |
.bss | 未初始化的全局變量和靜態變量 |
.symtab | 一個符號表,存放在程序中定義和引用的函數和全局變量的信息 |
.rel.text | 一個.text節中位置的列表,當鏈接器把其他文件和目標文件組合時,需要修改這些位置 |
.rel.data | 被模塊引用或定義的所有全局變量的重定位信息 |
.debug | 一個調試符號表,其條目是程序中定義的局部變量和類型定義,需要-g才有 |
.line | 原始C源程序中的行號和.text節中機器指令的映射,需要-g才有 |
.strtab | 一個字符串表 |
這樣我們就把一個可重定位的ELF文件中的每一個字節都搞清楚了。
靜態鏈接
編譯、鏈接的需求
為了節省空間和時間,不將所有的代碼都寫在同一個文件中是一個很基本的需求。
為此,我們的C語言需要實現這樣的需求:允許引用其他文件(C標準成為編譯單元,Compilation Unit)里定義的符號。C語言中不禁止你隨便聲明符號的類型,但是類型不匹配是Undefined Behavior。
假如我們有三個c文件,分別是a.c,b.c,main.c:
// a.c
int foo(int a, int b){return a + b;
}
// b.c
int x = 100, y = 200;
// main.c
extern int x, y;
int foo(int a, int b);
int main(){printf("%d + %d = %d\n", x, y, foo(x, y));
}
我們在main.c中聲明了外部變量x,y和函數foo,C語言并不禁止我們這么做,并且在聲明時,C也不會做什么類型檢查。當然,在編譯main.c的時候,我們看不到這些外部變量和函數的定義,也不知道它們在哪里。
我們編譯鏈接這些代碼,Makfile如下:
CFLAGS := -Osa.out: a.o b.o main.ogcc -static -Wl,--verbose a.o b.o main.oa.o: a.cgcc $(CFLAGS) -c a.cb.o: b.cgcc $(CFLAGS) -c b.cmain.o: main.cgcc $(CFLAGS) -c main.cclean:rm -f *.o a.out
結果生成的可執行文件可以正常地輸出我們想要的內容。
make
./a.out
# 輸出:
# 100 + 200 = 300
我們知道foo這個符號是一個函數名,在代碼區。但這時,如果我們將main.c中的foo聲明為一個整型,并且直接打印出這個整型,然后嘗試對其加一。即我們將main.c改寫為下面這樣,會發生什么事呢?
// main.c (changed)
#include <stdio.h>
extern int x, y;
// int foo(int a, int b);
extern int foo;
int main(){printf("%x\n", foo);foo += 1;// printf("%d + %d = %d\n", x, y, foo(x, y));
}
輸出:
c337048d
Segmentation fault (core dumped)
我們發現,其實是能夠打印出四個字節(整型為4個字節),但這四個字節是什么東西呢?
C語言中的類型:C語言中的其實是可以理解為沒有類型的,在C語言的眼中只有內存和指針,也就是內存地址,而所謂的C語言中的類型,其實就是對這個地址的一個解讀。比如有符號整型,就按照補碼解讀接下來的4個字節地址;又比如浮點型,就是按照IEEE754的浮點數規定來解讀接下來的4字節地址。
那我們這里將符號foo定義為了整型,那編譯器也會按照整型4個自己來解讀它,而這個地址指針指向的其實還是函數foo的地址。那這四個字節應該就是函數foo在代碼段的前四個字節。我們不妨用objdump反匯編來驗證我們的想法:
objdump -d a.out
輸出(節選):

我們看到,foo函數在代碼段的前四個字節的地址確是就是我們上面打印輸出的c3 37 04 8d(注意字節序為小端法)。
那我們接下來試圖對foo進行加一操作相當于是對代碼段的寫操作,而我們知道內存中的代碼段是 可讀可執行不可寫 的,這就對應了上面輸出的Segmentation fault (core dumped)。
總結一下,通過這個例子,我們應當理解:
- 編譯鏈接的需求:允許引用其他文件(C標準成為編譯單元,Compilation Unit)里定義的符號。C語言中不禁止你隨便聲明符號的類型,但是類型不匹配是Undefined Behavior。
- C語言中類型的概念:C語言中的其實是可以理解為沒有類型的,在C語言的眼中只有內存和指針,也就是內存地址,而所謂的C語言中的類型,其實就是對這個地址的一個解讀。
程序的編譯 - 可重定向文件
我們先用file命令來查看main.c編譯生成的main.o文件的屬性:
file main.o
輸出:
main.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
我們看到這里的main.o文件是可重定向( relocatable) 的ELF文件,這里的重定向指的就是我們鏈接過程中對外部符號的引用。也就是說,編譯過的main.o文件對于其中聲明的外部符號如foo,x,y,是不知道的。
既然外部的符號是在鏈接時才會被main程序知道,那在編譯main程序,生成可重定向文件時這些外部的符號是怎么處理的呢?我們同樣通過objdump工具來查看編譯出的main.o文件(未修改的原版本):
objdump -d main.o
輸出:

main在編譯的時候,引用的外部符號就只能 ”留空(0)“ 了。
我們看到,在編譯但還未鏈接的main.o文件中,對于引用的外界符號的部分是用留空的方式用0暫時填充的。即上圖中紅框框出來的位置。注意圖中的最后一列是筆者添加的注釋,指明了本行中留空的地方對應那個外部符號。
另外注意這里的%rip相對尋址的偏移量都是0,一會兒我們會講到,在靜態鏈接完成之后,它們的偏移量會被填上正確的數值。
我們已經知道在編譯時生成的文件中外部符號的部分使用0暫時留空的,這些外部符號是待鏈接時再填充的。那么,我們在鏈接時究竟需要填充哪些位置呢?我們可以使用readelf工具來查看ELF文件的重定位信息:
readelf -r main.o
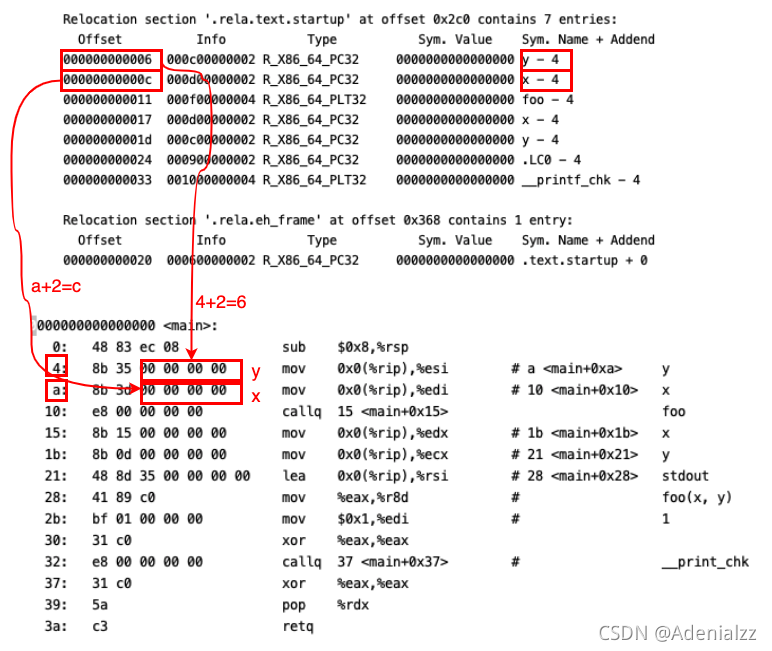
這個圖中上方是readelf的結果,下面是objdump的結果,筆者在這里已經將前兩個外部符號的偏移量的對應關系用紅色箭頭指了出來,其他的以此類推。這種對應也可以證明我們上面的分析是正確的的。
應當講,可重定向ELF文件(如main.o)已經告訴了我們足夠多的信息,指示我們應該將相應的外部符號填充到哪個位置。
另外,注意%rip寄存器指向了當前指令的末尾,也就是下一條指令的開頭,所以上圖中最后的偏移量要減4(如 y - 4)。
程序的靜態鏈接
簡單講,程序的靜態鏈接是會把所需要的文件鏈接起來生成可執行的二進制文件,將相應的外部符號,填入正確的位置(就像我們上面查看的那樣)。
1 段的合并
首先會做一個段的合并。即把相同的段(比如代碼段 .text)識別出來并放在一起。
2 重定位
重定位表,可用objdump -r [fileName] 查看。
簡單講,就是當某個文件中引用了外部符號,在編譯時編譯器是不會阻止你這樣做的,因為它相信你會在鏈接時告訴它這些外部符號是什么東西。但在編譯時,它也不知到這些符號具體在什么地址,因此這些符號的地址會在編譯時被留空為0。此時的重定位,就是鏈接器將這些留空為0的外部符號填上正確的地址。
具體的鏈接過程,可以通過ld --verbose來查看默認的鏈接腳本,并在需要的時候修改鏈接腳本。
我們可以通過使用gcc的 -Wl,--verbose將--verbose傳遞給鏈接器ld,從而直接觀察到整個靜態鏈接的過程,包括:
- ldscript里面各個section是按照何種順序 “粘貼”
- ctors / dtors (constructors / destructores) 的實現,( 我們用過__attribute__((contructor)) )
- 只讀數據和讀寫數據之間的padding,. = DATA_SEGMENT_ALIGN …
我們可以通過objdump來查看靜態鏈接完成以后生成的可執行文件a.out的內容:
objdump -d a.out

注意,這個a.out的objdump結果圖要與我們之前看到的main.o的objdump輸出對比著來看。
我們可以看到,之前填0留空的地方都被填充上了正確的數值,%rip相對尋址的偏移量以被填上了正確的數值,而且objdump也能夠正確地解析出我們的外部符號名(最后一列)的框。
靜態鏈接庫的構建與使用
假如我們要制作一個關于向量的靜態鏈接庫libvector.a,它包含兩個源代碼addvec.c和multvec.c如下:
// addvec.c
int addcnt = 0;void addvec(int *x, int *y, int*z, int n){int i;addcnt++;for (i=0; i<n; i++) z[i] = x[i] + y[i];
}
// multvec.v
int multcnt = 0;void multvec(int *x, int *y, int*z, int n){int i;multcnt++;for (i=0; i<n; i++) z[i] = x[i] * y[i];
}
我們只需要這樣來進行編譯:
gcc -c addvec.c multvec.c
ar rcs libvector.a addvec.o multvec.o
假如我們有個程序main.c要調用這個靜態庫libvector.a:
// main.c
#include <stdio.h>
#include "vector.h"int x[2] = {1, 2};
int y[2] = {3, 4};
int z[2];int main(){addvec(x, y, z, 2);printf("z = [%d %d]\n", z[0], z[1]);return 0;
}
// vector.h
void addvec(int*, int*, int*, int);
void multvec(int*, int*, int*, int);
只需要在這樣編譯鏈接即可:
gcc -c main.c
gcc -static main.o ./libvector.a
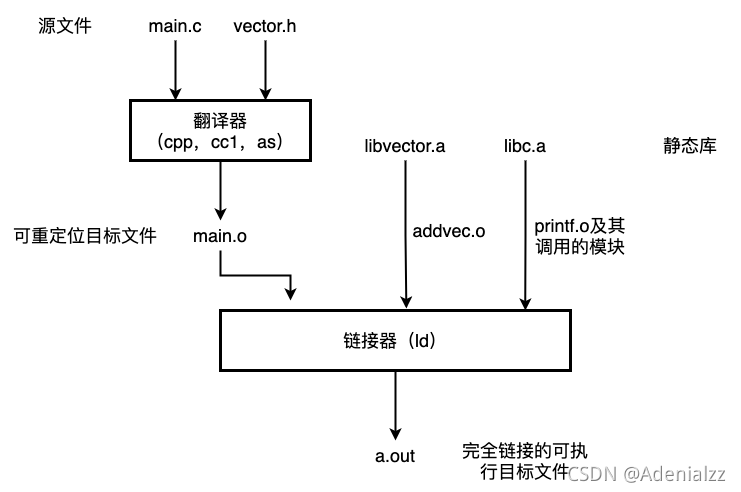
靜態鏈接過程圖示
我們以使用剛才構建的靜態庫libvector.a的程序為例,畫出靜態鏈接的過程。
可執行文件的裝載
進程和裝載的基本概念的介紹
程序(可執行文件)和進程的區別
- 程序是靜態的概念,它就是躺在磁盤里的一個文件。
- 進程是動態的概念,是動態運行起來的程序。
現代操作系統如何裝載可執行文件
- 給進程分配獨立的虛擬地址空間
- 將可執行文件映射到進程的虛擬地址空間(mmap)
- 將CPU指令寄存器設置到程序的入口地址,開始執行
可執行文件在裝載的過程中實際上如我們所說的那樣是映射的虛擬地址空間,所以可執行文件通常被叫做映像文件(或者Image文件)。
可執行ELF文件的兩種視角
可執行ELF格式具有不尋常的雙重特性,編譯器、匯編器和鏈接器將這個文件看作是被區段(section)頭部表描述的一系列邏輯區段的集合,而系統加載器將文件看成是由程序頭部表描述的一系列段(segment)的集合。一個段(segment)通常會由多個區段(section)組成。例如,一個“可加載只讀”段可以由可執行代碼區段、只讀數據區段和動態鏈接器需要的符號區段組成。
區段(section)是從鏈接器的視角來看ELF文件,對應段表 Section Headers,而段(segment)是從執行的視角來看ELF文件,也就是它會被映射到內存中,對應程序頭表 Program Headers。
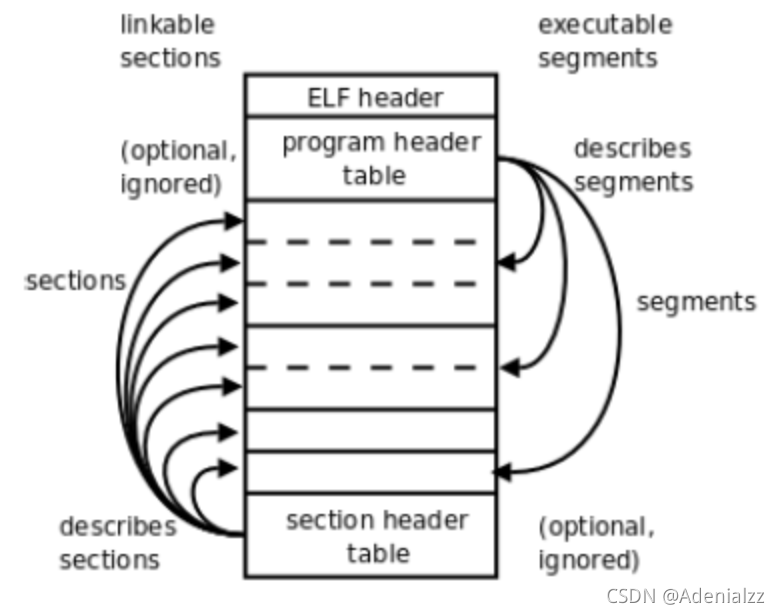
我們用命令readelf -a [fileName] 中的Section to Segment mapping部分來看一下可執行文件中段的映射關系。
可執行文件的程序頭表
我們用readelf -h [fileName]命令查看一個可執行ELF文件的ELF頭時,會發現與可重定位ELF文件的ELF頭有一個重大不同:可重定位文件ELF頭中 Start of program headers 為0,因為它是沒有程序頭表,Program Headers,Elf64_Phdr的;而在可執行ELF文件中,Start of program headers 是有值的,為64,也就是說,在可執行ELF文件中程序頭表會緊接著ELF頭(因為ELF頭的大小即為64字節)。
我們通過readelf -l [fileName]可以直接查看到程序頭表。
可執行ELF文件個進程虛擬地址空間的映射關系
我們可以通過 cat /proc/[pid]/maps 來查看某個進程的虛擬地址空間。
該虛擬文件有6列,分別為:
| 含義 | |
|---|---|
| 地址 | 虛擬內存區域的起始和終止地址 |
| 權限 | 虛擬內存的權限,r=讀,w=寫,x=執行,s=共享,p=私有 |
| 偏移量 | 虛擬內存區域在被映射文件中的偏移量 |
| 設備 | 映像文件的主設備號和次設備號; |
| 節點 | 映像文件的節點號; |
| 路徑 | 映像文件的路徑 |
vdso的全稱是虛擬動態共享庫(virtual dynamic shared library),而vsyscall的全稱是虛擬系統調用(virtual system call),關于這部分內容有興趣的讀者可以看看https://0xax.gitbooks.io/linux-insides/content/SysCall/syscall-3.html。
總體來說,在程序加載過程中,磁盤上的可執行文件,進程的虛擬地址空間,還有機器的物理內存的映射關系如下:
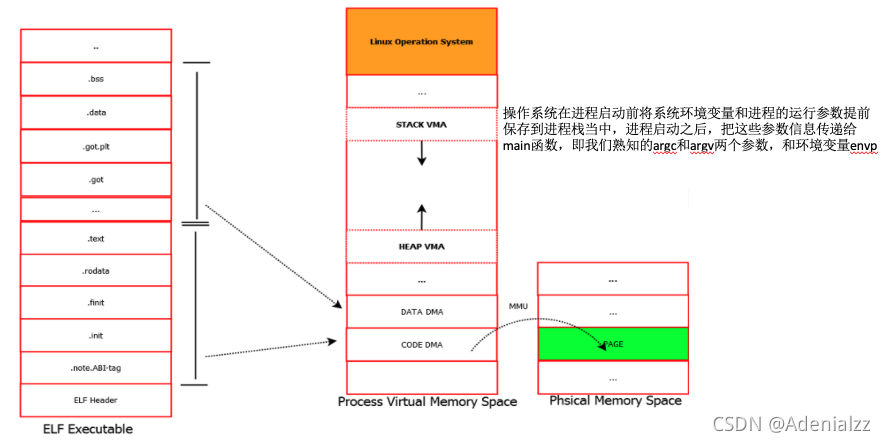
Linux下的裝載過程
接下來我們進一步探究一下Linux是怎么識別和裝載ELF文件的,我們需要深入Linux內核去尋找答案 (內核實際處理過程涉及更多的過程,我們這里主要關注和ELF文件處理相關的代碼)。
當我們在bash下輸入命令執行某一個ELF文件的時候,首先bash進程調用fork()系統調用創建一個新的進程,然后新的進程調用execve()系統調用執行指定的ELF文件 ,內核開始真正的裝載工作。
下圖是Linux內核代碼中與ELF文件的裝載相關的一些代碼:

/fs/binfmt_elf.c中 Load_elf_binary的代碼走讀:
- 檢查ELF文件頭部信息(一致性檢查)
- 加載程序頭表(可以看到一個可執行程序必須至少有一個段(segment),而所有段的大小之和不能超過64K(65536u))
- 尋找和處理解釋器段(動態鏈接部分會介紹)
- 裝入目標程序的段(elf_map)
- 填寫目標程序的入口地址
- 填寫目標程序的參數,環境變量等信息(create_elf_tables)
- start_thread會將 eip 和 esp 改成新的地址,就使得CPU在返回用戶空間時就進入新的程序入口
- …
例子:靜態ELF加載器,加載 a.out 執行
我們同樣以剛才介紹靜態鏈接時的a.c、b.c、main.c的例子來看一下靜態鏈接的可執行文件的加載。
靜態ELF文件的加載:將磁盤上靜態鏈接的可執行文件按照ELF program header,正確地搬運到內存中執行。
操作系統在execve時完成:
- 操作系統在內核態調用mmap
- 進程還未準備好時,由內核直接執行 ”系統調用“
- 映射好 a.out 的代碼、數據、堆區、堆棧、vvar、vdso、vsyscall
- 更簡單的實現:直接讀入進程的地址空間
加載完成之后,靜態鏈接的程序就開始從ELF entry開始執行,之后就變成我們熟悉的狀態機,唯一的行為就是取指執行。
我們通過readelf來查看a.out文件的信息:
readelf -h a.out
輸出:
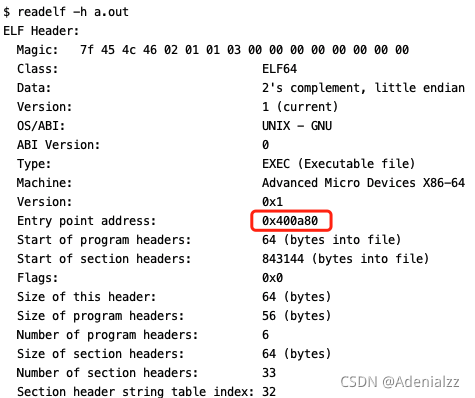
我們這里看到,程序的入口地址是:Entry point address: 0x400a80。我們接著用gdb來調試:
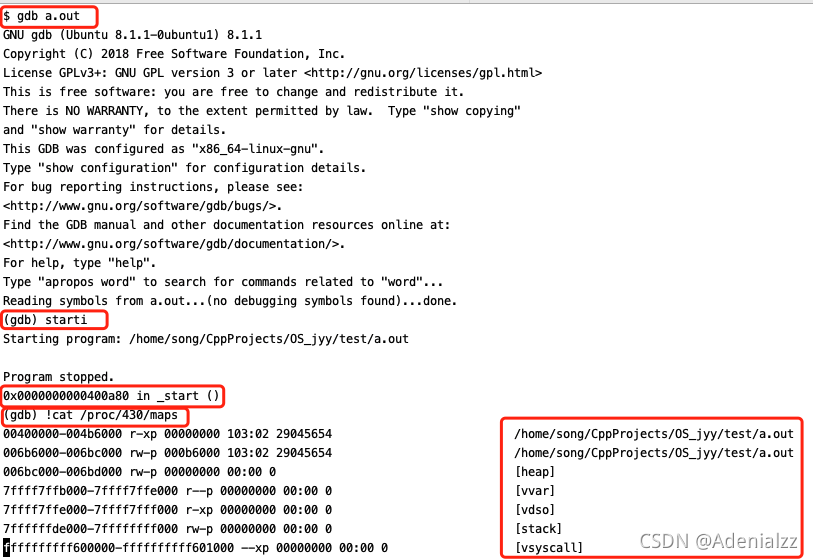
上圖是筆者在gdb中調試的一些內容:
- 我們用
starti來使得程序在第一條指令就停下,可以看到,程序確實是從0x400180開始的,與我們上面查到的入口地址一致。 - 而我們用
cat /proc/[PID]/maps來查看這個程序中內存的內容,看到我們之前提到的代碼、數據、堆區、堆棧、vvar、vdso、vsyscall都已經被映射進了內存中。
調試的結果符合我們對靜態程序加載時操作系統的行為的預期。
動態鏈接
什么是動態鏈接以及為什么需要動態鏈接
實際上,鏈接程序在鏈接時一般是優先鏈接動態庫的,除非我們顯式地使用-static參數指定鏈接靜態庫,像這樣:
gcc -static hello.c
靜態鏈接和動態鏈接的可執行文件的大小差距還是很顯著的, 因為靜態庫被鏈接后庫就直接嵌入可執行文件中了。
這樣就帶來了兩個弊端:
- 首先就是系統空間被浪費了。這是顯而易見的,想象一下,如果多個程序鏈接了同一個庫,則每一個生成的可執行文件就都會有一個庫的副本,必然會浪費系統空間。
- 再者,一旦發現了庫中有bug或者是需要升級,必須把鏈接該庫的程序找出來,然后全部需要重新編譯。
libc.so中有300K 條指令,2 MiB 大小,每個程序如果都靜態鏈接,浪費的空間很大,最好是整個系統里只有一個 libc 的副本,而每個用到 libc 的程序在運行時都可以用到 libc 中的代碼。
下圖中的 hello-dy 和 hello-st 是同一個hello源文件hello.c分別動態 / 靜態鏈接后生成的可執行文件的大小,大家可以感受一下,查了一百倍。而且這只是鏈接了libc標準庫,在大型項目中,我們要鏈接各種各樣的第三方庫,而靜態鏈接會把全部在鏈接時就鏈接到同一個可執行文件,那么其大小是很難接受的。

動態庫的出現正是為了彌補靜態庫的弊端。因為動態庫是在程序運行時被鏈接的,所以磁盤上和內存中只要保留一份副本,因此節約了磁盤空間。如果發現了bug或要升級也很簡單,只要用新的庫把原來的替換掉就行了。
Linux環境下的動態鏈接對象都是以.so為擴展名的共享對象(Shared Object).
真的是動態鏈接的嗎?
我們常說gcc默認的鏈接類型就是動態鏈接,而且我們及其中運行的大部分進程也都是動態鏈接的,真的是這樣的嗎?我們不妨來做個實驗驗證一下。
我們通過創建一個動態鏈接庫 libhuge.so, 然后創建1000個進程去調用這個庫中的foo函數,該函數是128M 個 nop。如果程序不是動態鏈接的話,1000 * 128MB的內存占用足以撐爆大多數個人電腦的內存。而如果程序確實是動態鏈接的,即內存中只有一份代碼,那么只會有很小的內存占用。我們是這樣做的:
首先我們有huge.S:
.global foo
foo:# 128MiB of nop.fill 1024 * 1024 * 128, 1, 0x90ret
這就是我們剛才說的一個動態鏈接庫的源代碼。我們一會兒會把他編譯成 libhuge.so供我們的huge.c調用,我們的huge.c是這樣的:
#include <unistd.h>
#include <stdio.h>
int main(){foo(); // huge code, dynamic linkedprintf("pid = %d\n", getpid());while (1) sleep(1);
}
它會調用foo函數,并在結束后打印自己的PID,然后睡眠。Makefile如下:
LIB := /tmp/libhuge.soall: $(LIB) a.out$(LIB): huge.Sgcc -fPIC -shared huge.S -o $@a.out: huge.c $(LIB)gcc -o $@ huge.c -L/tmp -lhugeclean:rm -f *.so *.out $(LIB)
正如我們剛才所介紹的,我們會先將huge.S編譯成動態鏈接庫libhuge.so放在/tmp下,然后我們的huge.c回去動態鏈接這個庫,并完成自己的代碼。這還不夠,我們要創建1000個進程來執行上述行為。這樣才能驗證我們的動態鏈接是不是在內存中真的只有一份代碼,我們用下面的腳本來完成:
#!/bin/bash# for i in {1...1000}
for i in `seq 1 100`
doLD_LIBRARY_PATH=/tmp ./a.out &
donewait
# ps | grep "a.out" | grep -Po "^(\d)*" | xargs kill -9 用于清空生成的進程
實驗證明,我們的操作系統能夠很好地運行這1000個進程,并且內存只多占用了 400MB。也就是說,庫中的foo函數確實是動態鏈接的,內存中只有一份foo的副本。
這在操作系統內核不難實現:所有以只讀方式映射同一個文件的部分(如代碼部分)時,都指向同一個副本,這個過程中會創建引用計數。
動態鏈接的例子
假如我們要制作一個關于向量的動態鏈接庫libvector.so,它包含兩個源代碼addvec.c和multvec.c如下:我們只需要這樣來進行編譯:
gcc -shared -fpic -o libvector.so addvec.c multvec.c
其中-fpic選項告訴編譯器生成位置無關代碼(PIC),而-shared選項告訴編譯器生成共享庫。
我們現在拿一個使用到這個共享庫的可執行文件來看一下,其源代碼main.c:
// main.c
#include<stdio.h>int addvec(int*, int*, int*, int);int x[2] = {1, 2};
int y[2] = {3, 4};
int z[2];int main(){addvec(x, y, z, 2);printf("z = [%d %d]\n", z[0], z[1]);while(1);return 0;
}
注意我們在最后加了一個死循環是為了讓進程保持運行,然后去查看進程的虛擬地址空間。
我們先編譯源碼,注意在同目錄下可以直接按以下命令編譯,之后我們會介紹將動態鏈接庫放到環境目錄后的編譯命令。
gcc main.c ./libvector.so
然后先用file命令查看生成的可執行文件a.out的文件信息,再用ldd命令查看其需要的動態庫,最后查看其虛擬地址空間。
file a.out
輸出:

我們看到,該可執行文件是共享對象,并且是動態鏈接的。
ldd a.out
輸出:

ldd命令就是用來查看該文件所依賴的動態鏈接庫。
./a.out &
cat /proc/12002/maps
輸出:
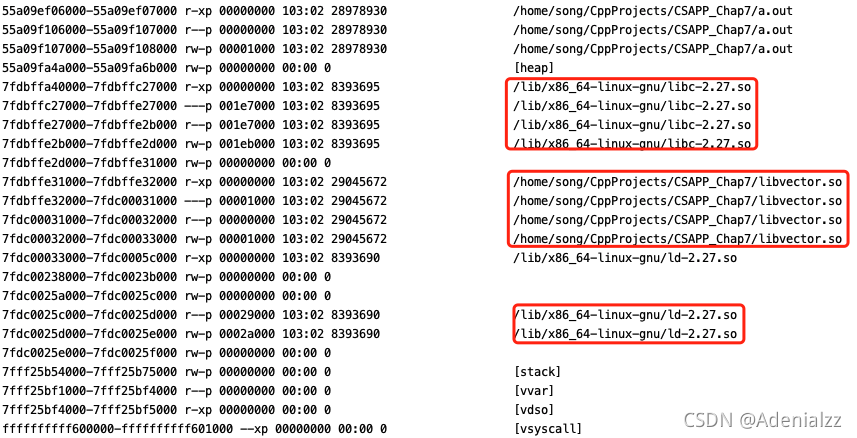
我們看到,除了像靜態鏈接時,進程地址空間中的堆、棧、vvar、vdso、vsyscall等之外,還有了許多動態鏈接庫.so。
動態鏈接的實現機制
程序頭表
我們同樣用readelf -l [fileName]來查看動態鏈接的可執行ELF文件的程序頭表:
readelf -l a.out
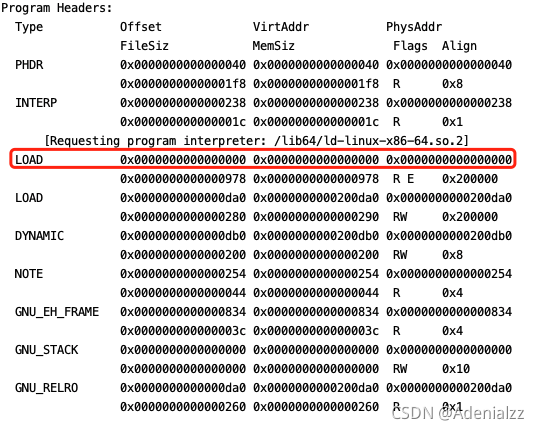
可以看到編譯完成之后地址是從 0x00000000 開始的,即編譯完成之后最終的裝載地址是不確定的。
關鍵技術
之前在靜態鏈接的過程中我們提到過重定位的過程,那個時候其實屬于鏈接時的重定位,現在我們需要裝載時的重定位 ,主要使用了以下關鍵技術:
- PIC位置無關代碼
- GOT全局偏移表
- GOT配合PLT實現的延遲綁定技術
引入動態鏈接之后,實際上在操作系統開始運行我們的應用程序之前,首先會把控制權交給動態鏈接器,它完成了動態鏈接的工作之后再把控制權交給應用程序。
可以看到動態鏈接器的路徑在.interp這個段中體現,并且通常它是個軟鏈接,最終鏈接在像ld-2.27.so這樣的共享庫上。
.dynamic段
我們來看一下和動態鏈接相關的.dynamic段和它的結構,.dynamic段其實就是全局偏移表的第一項,即GOT[0]。
可以通過readelf -d [fileName]來查看。
它對應的是elf.h中的Elf64_Dyn這個結構體。
動態鏈接器ld
對于動態鏈接的可執行文件,內核會分析它的動態鏈接器地址,把動態鏈接器映射到進程的地址空間,把控制權交給動態鏈接器。動態鏈接器本身也是.so文件,但是它比較特殊,它是靜態鏈接的。本身不依賴任何其他的共享對象也不能使用全局和靜態變量。這是合理的,試想,如果動態鏈接器都是動態鏈接的話,那么由誰來完成它的動態鏈接呢?

Linux的動態鏈接器是glibc的一部分,入口地址是sysdeps/x86_64/dl-machine.h中的_start,然后調用 elf/rtld.c 的_dl_start函數,最終調用 dl_main(動態鏈接器的主函數)。
動態鏈接過程圖示
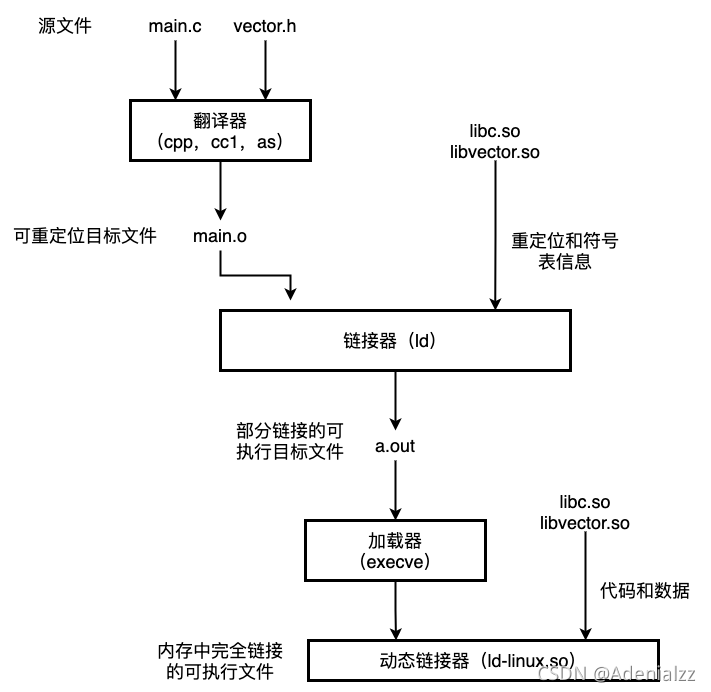
動態鏈接庫的構建與使用
創建自己的動態鏈接庫
創建號一個動態鏈接庫(如我們的libvector.so)之后,我們肯定不可能只在當前目錄下使用它,那樣他就不能被叫做 ”庫“了。
為了在全局使用動態鏈接庫,我們可以將我們自己的動態鏈接庫移動到/usr/lib下:
sudo mv libvector.so /usr/lib
之后我們只要在需要使用到相關庫時加上-l[linName]選項即可,如:
gcc main.c -lvector
大家也注意到了,上面的命令要用到管理員權限sudo。適應為/usr/lib和/lib是系統級的動態鏈接目錄,我們要創建自己的第三方庫最好不要直接放在這個目錄中,而是創建一個自己的動態鏈接庫目錄,并將這個目錄添加到環境變量 LD_LIBRARY_PATH 中:
mkdir /home/song/dynlib
mv libvector.so /home/song/dynlib
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/song/dynlib
命名規范
動態鏈接庫要命名為:lib[libName].so 的形式。
實現動態鏈接及實際ELF的動態鏈接
想必大家看了上面一節對動態鏈接的介紹,已經明白動態鏈接以及動態鏈接庫的大體過程和用法,但是對其中具體的實現細節還是比較迷惑。本節是筆者在聽南大蔣炎巖老師的錄播課程時做的筆記。蔣老師從分析實現一個簡易的動態鏈接的三個等級的需求講起,逐步引出了上面筆者提到的動態鏈接的三個關鍵技術:PIC、GOT并加以介紹,最后通過介紹實際中ELF的動態加載過程,介紹GOT、PLT配合實現的lazy symbol resolve。想要更加深入地理解動態鏈接的實現過程的朋友可以讀一下本節。如果筆者的筆記有令人疑惑的地方,也可以去看蔣老師在B站的錄播課程。
講解的總體思路如下:
我們通過逐步把需求進行分解,從加載的視角理解鏈接:
- 需要加載一段代碼(foo):PIC(通過使用PC相對尋址)+ mmap
- 代碼需要伴隨數據(bar):數據也使用PC相對尋址 + mmap
- 需要解析動態符號(baz):查表(GOT)、優化:PLT,lazy symbol resolve
實現動態鏈接與加載
我們要實現動態鏈接,需要具體做到哪些事情呢?我們希望有一個庫函數,其中包含一些代碼,所有的進程鏈接這一段代碼,這段代碼在內存中只有一份拷貝。
實現動態加載(1)
需求1:加載純粹的代碼
編譯成位置無關代碼(Position Independent Code, PIC)即可,即引用代碼(跳轉)全部使用PC相對尋址。x86已經是這樣了。直接把代碼mmap進地址空間就行了。
# foo.S
.global fool
foo:movl $1, %eaxret
比如上面這段代碼,它很簡單,就是返回1。
實現動態加載(2)
需求2:動態鏈接庫只有純粹的代碼沒有數據可不行,我們要能加載代碼,并且代碼有附帶的數據。
這也好辦,將代碼和數據放在一起,然后都使用PC相對尋址就好了。
對于x86不支持rip相對尋址,我們可以通過 call __i686. get_pc_thunk.bx 來得到下條指令的地址。
我們有這樣一段代碼:
# bar.S
x: # 數據不能共享 (MAP_PRIVATE 方式映射).int 0.global bar
bar:addl $1, x(%rip)movl x(%rip), %eaxret
這相當于這樣一段C代碼:
int bar(){static int x = 0;return ++x;
}
即在靜態區定義一個變量x,然后每次調用bar函數時都會將x加一并返回。這也是一段位置無關代碼,也可以直接mmap到內存中去執行。
實現動態加載(3)
需求3:比較難的是,一個文件或者一個動態鏈接庫想要訪問另外一個動態鏈接庫導出的符號。因為我們想要知道的符號(比如bar)也是動態加載的,也就是說,符號的地址是運行(加載)的時候才能確定的。而我們在編譯(比如編譯baz時)的時候無法知道動態加載的符號bar的地址。即允許訪問其他動態鏈接庫導出的符號(代碼 / 數據)。
解決方法是我們用一張表,編譯時編譯成:call *table[bar]。bar.o會先被映射到進程的地址空間中,然后,我們要將baz.o映射到地址空間時,我們會給baz所保有的這張表中bar所對應的表項填上正確的數值,即此時已知的bar的地址。即我們為每個動態加載的符號(代碼 / 數據)創建一張變,在運行時每次用到這些動態符號時,才解析符號的地址。
.global ..bar
..bat: bar:.quad 0.global baz
baz:movq baz(%rip), %rdicall *%rdiret
重填(相當于在運行時重做靜態鏈接),這樣行嗎?不行,因為這樣違背了我們動態鏈接的初衷:希望整個內存中只有一份代碼的副本,而每次重填會導致每次都在內存中多一份代碼的副本。而上面的解決方案,只有這張表,是需要復制的,這大幅減少了系統中冗余的內存。
總結
總結一下,實現動態鏈接和加載就是兩個關鍵點:
- PIC位置無關代碼,不管是代碼還是數據,我們全部都要通過PC相對尋址,來使得它們是位置無關代碼。
- 要引用動態鏈接庫中的符號(編譯時不知道)時,我們創建一張表,在運行(加載)時將其填上正確的地址。
例子
假如我們是十幾種有這樣一個動態鏈接(共享代碼)的需求:
main需要調用libc中的printfprintf需要調用libfoo中的foo
我們知道,動態加載的程序最先并不是從main的入口地址開始執行的。而是需要先由加載器libld進行動態加載。libld由操作系統加載,按照相互依賴相反的方向加載:
libld加載libfoo,一切順利libld加載libclibc對foo的調用在編譯時,被編譯為call *libc.tab[FOO]libld調用dl_runtime_resolve解析符號,填入libc.tab[FOO],因為此時libfoo已經被加載到地址空間中了,foo地址是已知的
libld完成main的初始化a.out對printf的調用在編譯時,被編譯成call *a.out.tab[PRINTF]libld機械printf的地址,填入call *a.out.tab[PRINTF],因為此時libc已經被加載到地址空間中了,printf地址是已知的
所有的填表都完成之后,就跳轉到main的入口地址開始執行。
ELF 動態鏈接與加載
上面一種簡化版的動態加載過程,實際的ELF動態加載比這要復雜一點。
GOT (Global Offset Table)
GOT
GOT:shared object用來存儲動態符號的表格。庫函數有,可執行文件也有。
所以用file命令查看a.out和libc.so時都是 ”shared object“ 。也就是說我們生成的可執行文件其實和庫函數是同一種文件格式。它們都需要調用其他的動態鏈接庫中的符號。
GOT中儲存的數據
- GOT[0]:.dynamic節的地址
- GOT1:link map,用于遍歷依賴的動態鏈接庫
- GOT2:dl_runtime_resolve 的地址,即call *GOT2 可以完成符號解析
- GOT[i]:程序所需的動態符號的地址(printf, …)
新需求
新需求:能否降低實際沒有調用到的符號的開銷?
程序可能會引用很多符號,但執行時可能大部分符號都沒用到,逐個dl_runtime_resolve的話會造成不必要的開銷。
lazy symbol resolution
想法:加載時設置為NULL,加載時來判斷 / 解析
使用一小段 ”trampoline code“ 跳板代碼
- 如果符號還未解析,就解析
- 跳轉到解析后的符號執行
int print_internal(const char *fmt, ...){if (GOT[PRINRF]){GOT[PRINTF] = call_dl_runtime_reslove("printf");}return GOT[PRINTF]{...};
}
需要編譯器把向printf(動態鏈接庫)的調用翻譯成call printf_internal
壞處:fast path多做一次判斷:call + load + 判斷 + jump,會損失一定的性能。
黑科技:讓printf@GOT指向trampoline的下一條指令。

- 只有兩條指令:call print@plt; jmp *a.out.GOT[PRINTF]
- 對現代處理器非常友好,因為有branch-target-buffer(BTB),幾乎不損失性能。
Takeaways and Wrap-up
我們通過逐步把需求進行分解,從加載的視角理解鏈接:
- 需要加載一段代碼(foo):PIC(通過使用PC相對尋址)+ mmap
- 代碼需要伴隨數據(bar):數據也使用PC相對尋址 + mmap
- 需要解析動態符號(baz):查表(GOT)、優化:PLT,lazy symbol resolve
入口函數和運行庫
入口函數
初學者可能一直以來都認為C程序的第一條指令就是從我們的main函數開始的,實際上并不是這樣,在main開始前和結束后,系統其實幫我們做了很多準備工作和掃尾工作,下面這個例子可以證明:
我們有兩個C代碼:
// entry.c
#include <stdio.h>__attribute((constructor)) void before_main()
{ printf("%s\n",__FUNCTION__); }int main() {printf("%s\n",__FUNCTION__);
}// atexit.c
#include <stdio.h>void post(void)
{printf("goodbye!\n");
}int main()
{atexit(&post);printf("exiting from main\n");
}
分別編譯運行這兩個程序,輸出結果分別為:
# entry.c
before_main
main
# atexit.c
exiting from main
goodbye!
可見,在main開始前和結束后,其實還有一部分程序在運行。
事實上操作系統裝載程序之后首先運行的代碼并不是我們編寫的main函數的第一行,而是某些運行庫的代碼,它們負責初始化main函數正常執行所需要的環境,并負責調用main函數,并且在main返回之后,記錄main函數的返回值,調用atexit注冊的函數,最后結束進程。以Linux的運行庫glibc為例,所謂的入口函數,其實 就是指ld 默認的鏈接腳本所指定的程序入口_start (默認情況下)
運行庫
glibc = GNU C library
Linux環境下的C語言運行庫glibc包括:
-
啟動和退出相關的函數
-
C標準庫函數的實現 (標準輸入輸出,字符處理,數學函數等等)
-
…
事實上運行庫是和平臺相關的,和操作系統聯系的非常緊密,我們可以把運行庫理解成我們的C語言(包括c++)程序和操作系統之間的抽象層,使得大部分時候我們寫的程序不用直接和操作系統的API和系統調用直接打交道,運行庫把不同的操作系統API抽象成相同的庫函數,方便應用程序的使用和移植。
Glibc有幾個重要的輔助程序運行的庫 /usr/lib64/crt1.o, /usr/lib64/crti.o, /usr/lib64/crtn.o。
其中crt1包含了基本的啟動退出代碼, ctri和crtn包含了關于.init段及.finit段相關處理的代碼(實際上是_init()和_finit()的開始和結尾部分)
Glibc是運行庫,它對語言的實現并不太了解,真正實現C++語言特性的是gcc編譯器,所以gcc提供了兩個目標文件crtbeginT.o和crtend.o來實現C++的全局構造和析構 – 實際上以上兩個高亮出來的函數就是gcc提供的,有興趣的讀者可以自己翻閱gcc源代碼進一步深入學習。
幾組概念的辨析
動態鏈接的可執行文件和共享庫文件的區別
問題: 可執行文件和動態庫之間的區別?我們在第一節中提到過動態鏈接的可執行文件和動態庫文件file命令的查看結果是類似的,都是shared object,一個不同之處在于可執行文件指明了解釋器intepreter:

可執行文件和動態庫之間的區別,簡單來說:可執行文件中有main函數,動態庫中沒有main函數,可執行文件可以被程序執行,動態庫需要依賴程序調用者。
在可執行文件的所有符號中,main函數是一個很特別的函數,對C/C++程序開發人員來說,main函數是整個程序的起點;但是,main函數卻不是程序啟動后真正首先執行的代碼。
除了由程序員編寫的源代碼編譯成目標文件進而鏈接到程序內存映射,還有一部分機器指令代碼是在鏈接過程中添加到程序內存映射中。
比如,程序的啟動代碼,放在內存映射的起始處,在執行main函數之前執行以及在程序終止后完成一些任務
編譯動態庫時,鏈接器沒有添加這部分代碼。這是可執行文件和動態庫之間的區別。
靜態鏈接 / 動態鏈接的可執行文件的第一條指令地址
靜態鏈接可執行文件的第一條指令地址
我們之前提到過,靜態鏈接的可執行文件的其實地址就是本文件的_strat,即readelf -h所得到的的起始地址。對于一個hello程序:
// hello.c
#include <stdio.h>int main(){printf("Hellow World.\n");return 0;
}
我們先用選項-static來靜態鏈接它,得到hello-st:
gcc -static hello.c -o hello-st
我們先用file命令看一下:

它是靜態鏈接的可執行文件。
我們用readelf -h查看其入口地址,并在gdb中starti查看它實際的第一條指令的地址:
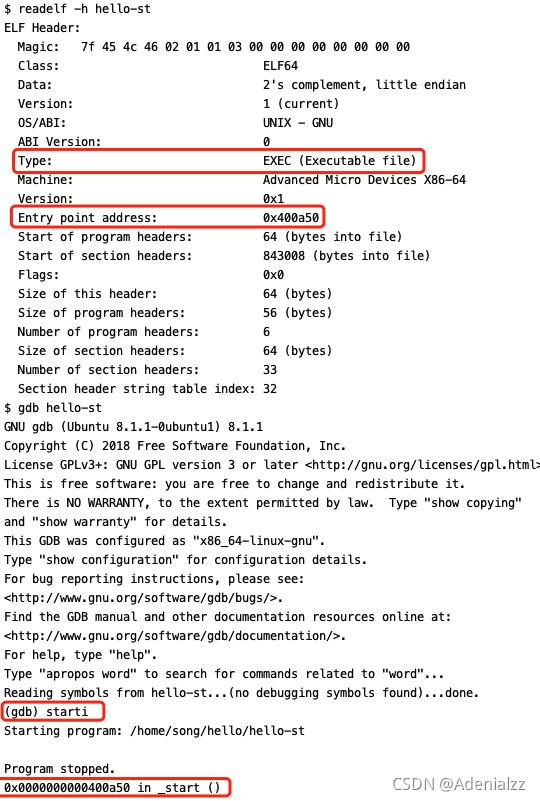
可以看到,與我們的預期是一致的,確是是從文件本身真正的入口地址entry point0x400a50開始執行第一條指令。而在動態鏈接的可執行文件中,我們將看到不同。
動態鏈接的可執行文件的第一條指令地址
我們現在動態鏈接(默認)編譯hello程序得到hello-dy:
gcc hello.c -o hello-dy
還是先來file一下:

我們看到hello-dy是一個動態鏈接的共享目標文件,當然它也是可執行的,共享庫文件和可執行的共享目標文件的區別我們上面已經介紹過了。大家注意,這里還多了一個奇怪的家伙:解釋器,interpreter /lib64/ld-linux-x86-64.so.2。
實際上,它就是動態鏈接文件的鏈接加載器。我們之前已經介紹過,在動態鏈接的可執行文件中,外部符號的地址在程序加載、運行的過程中才被確定下來。這個鏈接加載器 ld 就是負責完成這個工作的。當 ld 將外部符號的地址都確定好之后,才將指令指針執行程序本身的_start。也就是說,在動態鏈接的可執行文件中,第一條指令應該在鏈接加載器 ld 中。我們接下來還是通過readelf -h和gdb來驗證一下。
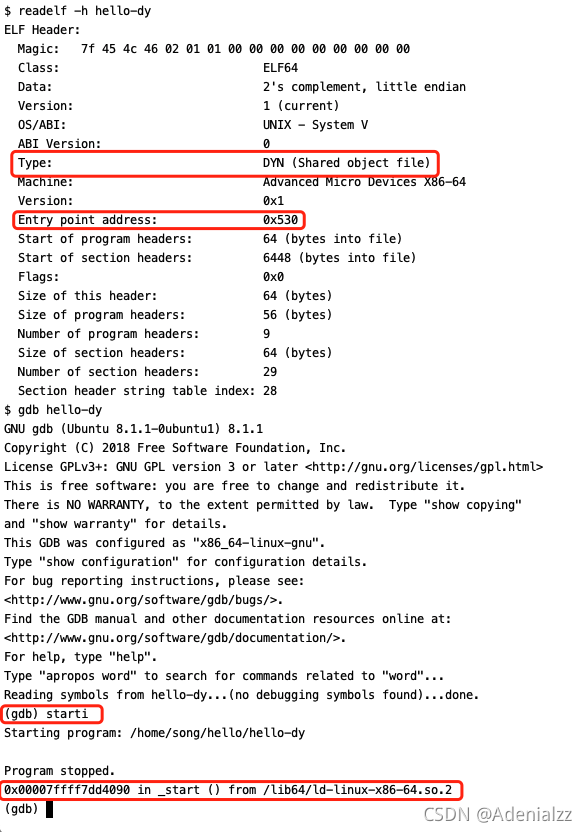
可以看到,我們的動態鏈接的可執行程序的第一條指令的地址并不是本文件的entry point 0x530,而是鏈接加載器 ld 的第一條指令_start的地址 0x7ffff7dd4090。
這就驗證了我們上面的說法:動態鏈接的可執行文件的第一條指令是鏈接加載器的程序入口,它會完成外部符號地址的綁定,然后將控制權交還給程序本身,開始執行。
靜態庫和共享庫
庫:有時候需要把一組代碼編譯成一個庫,這個庫在很多項目中都要用到,例如libc就是這樣一個庫,我們在不同的程序中都會用到libc中的庫函數(例如printf)。
共享庫和靜態庫的區別:在鏈接libc共享庫時只是指定了動態鏈接器和該程序所需要的庫文件,并沒有真的做鏈接,可執行文件調用的libc庫函數仍然是未定義符號,要在運行時做動態鏈接。而在鏈接靜態庫時,鏈接器會把靜態庫中的目標文件取出來和可執行文件真正鏈接在一起。
- 靜態庫鏈接后,指令由相對地址變為絕對地址,各段的加載地址定死了。
- 共享庫鏈接后,指令仍是相對地址,共享庫各段的加載地址并沒有定死,可以加載到任意位置。
靜態庫好處:靜態庫中存在很多部分,鏈接器可以從靜態庫中只取出需要的部分來做鏈接 (比如main.c需要stach.c其中的一個函數,而stach.c中有4個函數,則打包庫后,只會鏈接用到那個函數)。另一個好處就是使用靜態庫只需寫一個庫文件名,而不需要寫一長串目標文件名。
Ref
Computer Systems A Programmer’s Perspective - by Randal E. Bryant & David O’Hallaron
https://www.bilibili.com/video/BV1hv411s7ew
https://blog.csdn.net/weixin_44966641/article/details/120616894?spm=1001.2014.3001.5501
https://www.bilibili.com/video/BV1N741177F5?p=15
https://www.jianshu.com/p/7c609b70acbd
https://blog.csdn.net/xuehuafeiwu123/article/details/72963229





)










)


