本文主要通過python實例講解基于RDF和SPARQL的KBQA系統的構建。該項目可在python2和python3上運行通過。
注:KBQA即是我們通常所說的基于知識圖譜的問答系統。這里簡單構建的EasyKBQA,數據來源于網絡,源碼地址看下面補充說明。
目錄:
流程原理:
該問答系統可以解析輸入的自然語言問句,主要運用REFO庫的"對象正則表達式"匹配得到結果, 進而生成對應 SPARQL 查詢語句,再通過API請求后臺基于TDB知識譜圖數據庫的 Apache Jena Fuseki 服務, 得到結果。
實際過程:
1. 預定義 3 ?類共 5 ?個示例問題,?包括:
● "誰是苑茵?",
● "丁洪奎是誰?",
● "蘇進木來自哪里?",
● "苑茵哪個族的?",
● "苑茵是什么民族的人?".
2. 利用結巴分詞對中文句子進行分詞, ?同時進行詞性標注;
3. 將詞的文本和詞性打包, ?視為"詞對象",對應 :class:Word(token,? ?pos)?;
4. 利用 REfO ?模塊對詞進行對象級別 (object-level) ?的正則匹配,判斷問題屬于的?種類?并產生對應的 SPARQL,對應 :class:Rule(condition,? ?action)?;
5. 如果成功匹配并成功產生 SPARQL ?查詢語句, ?立刻請求 Fuseki ?服務并返回結果,打印相關內容;
程序運行:
1、配置第三方庫:pip install refo jieba sparqlwrapper
2、安裝JAVA JDK1.8,配置好環境變量。
3、項目根目錄主要包括backend??文件夾和test.py文件(同一級),backend是Jena?的Fuseki 模塊,?運行第4步
4、cd backend/apache-jena-fuseki-3.5.0,windows下啟動SPARQL endpoint服務:
fuseki-server.bat --loc=../DB /demo > log.txt 2>&1
對應Linux命令為:
nohup ./fuseki-server --loc=../DB /demo > log.txt 2>&1 &
5、運行根目錄代碼:python test.py,結果如下圖:
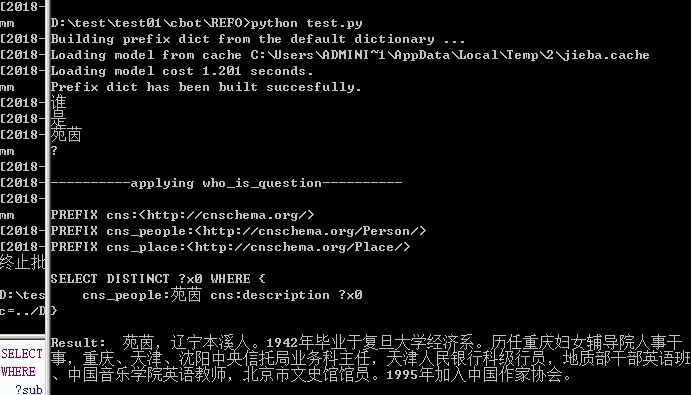
補充說明:
1、啟動fuseki服務器參數,--loc=../DB設置在線服務數據庫位置,參數/demo
2、自然語言問句進行正則匹配的邏輯REfO. ?主要參考根目錄下的代碼:words.py
3、后續改進可參考: 使用鄰接鏈表表示自然語言問句, 通過遍歷有向圖或子圖匹配方法構造 SPAPQL ?查詢語句
代碼下載地址:https://download.csdn.net/download/starbaby01/10621927
簡單用法)

![from server sql 拼接統計兩個子查詢_[SQL SERVER系列]之嵌套子查詢和相關子查詢](http://pic.xiahunao.cn/from server sql 拼接統計兩個子查詢_[SQL SERVER系列]之嵌套子查詢和相關子查詢)




)


)








