?作者:江小白
?
郵箱:jieresearch@163.com
我們在使用stata進行數據分析時,可能涉及多個數據文檔的合并操作或者同時使用不同數據集中的多個變量,這都需要我們進行文檔間不同變量的歸并。
例如,我們需要使用CFPS(中國家庭追蹤調查)數據庫進行實證分析,而申請拿到的原始數據中包含成人數據庫,兒童數據庫,家庭關系庫等多個數據集,我們需要的變量分散在這些數據集中,此時就需要將不同數據庫中的不同變量放到一起;再譬如我們需要CFPS多期的調查數據構建多期面板,這又需要我們把多期的數據合并到一起...
在stata中就為我們提供了merge ,append 等命令以實現多個數據文件的「橫向合并」或「縱向合并」。
「merge」 命令
merge和 append 都是stata自帶的數據處理命令,為了了解命令的使用,我們可以使用help 命令
help merge通過幫助命令我們可以觀察到如下語句格式
?通過關鍵變量進行1對1合并
merge ?1:1 ?varlist ?using ?filename通過關鍵變量進行多對1合并
merge m:1 varlist using filename通過關鍵變量進行1對多合并
merge 1:m varlist using filename通過關鍵變量進行多對多合并
merge m:m varlist using filename通過觀測數進行1對1合并
?
merge 1:1 _n using filename
利用幫助文件的示例演示1對1的數據合并如何操作
webuse autosizelistwebuse autoexpenselist/*Perform 1:1 match merge*/webuse autosizemerge 1:1 make using http://www.stata-press.com/data/r15/autoexpenselist通過list命令,我們可以觀察到 autosize 和 autoexpense 的數據詳情
autosize 數據
| make | weight | length |
|---|---|---|
| Toyota ? Celica | 2,410 | 174 |
| BMW 320i | 2,650 | 177 |
| Cad. Seville | 4,290 | 204 |
| Pont Grand Prix | 3,210 | 201 |
| Datsun 210 | 2,020 | 165 |
| Plym. Arrow | 3,260 | 170 |
autoexpense 數據
| make | price | mpg |
|---|---|---|
| Toyota Celica | 5,899 | 18 |
| BMW 320i | 9,735 | 25 |
| Cad. Seville | 15,906 | 21 |
| Pont. Grand Prix | 5,222 | 19 |
| Datsun 210 | 4,589 | 35 |
根據數據中的make變量,進行 1對1 的合并,在merge合并中我們需要定義 master 數據集和 using 數據集,相當于我們對于數據集定義主從關系,我們將 autosize 數據集作為master,然后 using autoexpense 數據集1對1合并,那么可以得到如下合并結果:
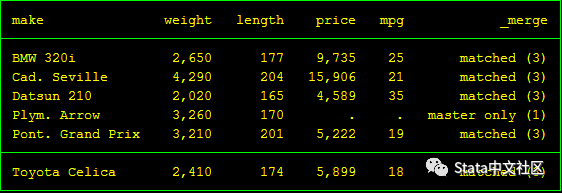
使用 merge 后,stata會給出數據 match 的結果,如下表:這個結果告訴我們,兩個數據集中有5個觀測變量成功 match(用_merge==3表示這類變量),有1個觀測變量 not matched,而且這個匹配失敗的變量來自master 數據集 (用_merge==1表示這類變量)。
「數據match結果」
| Result | # of obs. |
|---|---|
| not matched | 1 |
| from master | 1 ?(_merge==1) |
| from using | 0 ?(_merge==2) |
| matched | 5 ?(_merge==3) |
在數據處理過程中可以在匹配后刪除我們不需要的not matched 的樣本,例如:drop if merge==1可以直接刪除master數據集中未匹配的樣本。
此外,merge 命令還提供了諸多的選擇項(option)內容,比較常用的有:
keepusing(varlist):保留數據集中特定變量generate(newvar):使用新的變量名稱標記merge結果,默認為mergenogenerate:不生成merge變量update: 用using數據集中的值替代master數據集中相同變量的缺失值replace:用using數據集中的值替代master數據集中相同變量的非缺失值force:允許字符型和數值型變量之間不匹配
示例中還提供了1:m,m:1,以及多個選擇項使用的例子(我們一般很少用到m:m合并),其操作與解讀與1:1的合并類似
/*進行 1:1 merge, 并保留匹配變量*/webuse autosize, clearmerge 1:1 make using http://www.stata-press.com/data/r15/autoexpense, ///keep(match) nogenlist/* Setup */webuse dollars, clearlistwebuse sforcelist/*與 sforce 進行 m:1 merge */merge m:1 region using http://www.stata-press.com/data/r15/dollarslist/*Setup*/webuse overlap1, clearlist, sepby(id)webuse overlap2list/*進行 1:m merge, 帶update replace選項*/webuse overlap2, clearmerge 1:m id using http://www.stata-press.com/data/r15/overlap1 /// update replacelist /*按樣本進行順序合并*/webuse sforce, clearlistmerge 1:1 _n using http://www.stata-press.com/data/r15/dollarslist「append」 命令
如果需要實現數據的縱向合并,我們使用append命令
help appendappend的語句格式如下
?append using filename [filename ...] [, options]
?
使用示例數據演示合并
/*Setup*/webuse evenlistwebuse oddlistappend using http://www.stata-press.com/data/r15/evenlisteven數據集
| number | even |
|---|---|
| 6 | 12 |
| 7 | 14 |
| 8 | 16 |
odd 數據集
| number | odd |
|---|---|
| 1 | 1 |
| 2 | 3 |
| 3 | 5 |
| 4 | 7 |
| 5 | 9 |
合并結果
| number | odd | even |
|---|---|---|
| 1 | 1 | . |
| 2 | 3 | . |
| 3 | 5 | . |
| 4 | 7 | . |
| 5 | 9 | . |
| 6 | . | 12 |
| 7 | . | 14 |
| 8 | . | 16 |
append命令也帶有 keep nolabel force等選擇項,使用方法與merge大同小異
這些操作可以幫助我們在stata中實現數據的橫向與縱向合并。例如在CFPS數據集中,可以根據追蹤調查所標記的個人ID(pid)和家庭ID(fid)等變量從相應數據庫中提取我們所需的變量進行合并;也可以根據調查年份合并我們所需的面板...
在實際中可以根據數據的結構特點和研究需求選擇合適的操作命令,用stata進行數據集的合并你學會了嗎?
本文相關的附件可以從https://github.com/czxa/Stata-Chinese-community獲取,點擊閱讀原文即可跳轉~
歡迎關注公眾號獲取更多stata相關推文


)










貝塞爾曲線)


)


選擇器怎么用)
)