新增數據
多數據插入
只要寫一次insert指令,但是可以插入多條記錄
語法:insert into?表名 [(字段列表)] values (值列表1),(值列表2),(值列表3);
主鍵沖突
主鍵沖突,在有的表中,使用的是業務主鍵(字段有業務含義),但是往往在進行數據插入的時候,又不確定數據表中是否已經存在對應的主鍵
解決方案:
1、主鍵沖突更新
類似插入語法,如果插入過程中主鍵沖突,那么采用更新方法分
insert into?表名 [(字段列表)]?values (值列表) on duplicate key?update?字段 =?新值;
2、主鍵沖突替換
當主鍵沖突之后,干掉原來的數據,重新插入進去
replace into [(字段列表)] values (值列表);
蠕蟲復制
一分為二,成倍增加。從已有的數據中獲取數據,并且將獲取到的數據插入到數據表中。
語法:insert into 表名 [(字段列表)] select? */字段列表 from?表;
1、蠕蟲復制的確通常是復制數據,沒有太大業務數據:可以在短期內快速增加表的數據量,從而測試表的壓力,還可以通過大量數據來測試表的效率(索引)
2、蠕蟲復制,要注意主鍵沖突。
更新數據
1、在更新數據的時候,要注意通常一定是跟隨條件更新
update?表名 set?字段名 =?新值 where?判斷條件l
2、如果沒有條件,是全表更新數據,但是可以使用limit來限制更新的數量
update?表名 set?字段名 =?新值 [where?判斷條件] limit?數量;
刪除數據
1、刪除數據的時候,盡量不要全部刪除,應該使用where進行判定
2、刪除數據的時候可以使用limit來限制要刪除的具體數量
delete?刪除數據的時候,無法重置auto_increment
重置語法:trunacate?表名
查詢數據
完整的查詢指令:
select select選項?字段列表?from?數據源 where?條件 group by?分組 having?條件 order by?排序?limit?數量限制;
select選項:系統該如何對待查詢得到的數據
all:默認的,表示保存所有的記錄
distinct:去重,去除重復的記錄,只保留一條(滿足重復:所有的值都相同)
字段列表:
有的時候需要從多張表獲取數據,在獲取數據的時候,可能存在不同表中有同名字段,需要將同名的字段命名成不同名的,
基本語法:?字段名 [as]?別名
from數據源
from是為前面的查詢提供數據:數據源只要是一個符合二維表結構的數據即可
單表數據:from?表名
多表數據:from?表名1 , 表名2
結果是兩張表的記錄數相乘,字段數拼接。得到的結果在數學上叫”笛卡爾積“,這個結果除了給數據庫造成壓力,沒有其他意義,應該盡量避免出現笛卡爾積。
動態數據:from (select?字段列表 from?表) [as] 別名
from后面跟的數據不是一個實體表,而是一個從表中查詢出來得到的二維結果表
where子句
用來從數據表獲取的時候,進行條件篩選,使用過運算符進行結果比較來判斷數據。
數據獲取原理:針對表去對應的磁盤處獲取所有的記錄(一條條),where的作用是在拿到一條結果之后就開始進行判斷,判斷是否符合條件,如果符合就保存,不符合就舍棄(不放在內存中)
group?by子句
分組的恨意:根據指定的字段,將數據進行分組:分組的目標是為了統計(如根據性別將男女分組)
分組統計:group?by?字段名;
group?by?只能幫助數據分組統計,并不能將分組情況展示,在分組之后只會保留每組的第一條記錄
利用一些統計函數:(聚合函數)
count():統計每組中的數量,如果統計目標是字段,那么不統計為空NULL字段
avg():求平均值
sum():求和
max():求最大值
min():求最小值
多分組:
將數據按照某個字段進行分組后,對已經分組的數據進行再次分組
基本語法:group by?字段1,字段2;? //先按照字段1進行分組,結果再 按照字段2分組
分組排序:
MySQL中分組默認有排序的功能:按照分組字段進行排序:默認為升序
語法:group by?字段1 [asc|desc] , [字段2[asc|desc]] ;(asc為升序,desc為降序)
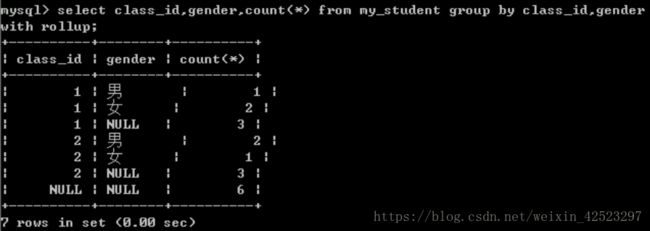
回溯統計:
當分組進行多分組之后,往上統計的過程中,需要進行層層上報,將層層上報統計的過程稱之為回溯統計:每一次分組向上統計的過程都會產生一次新的統計數據,而且當前數據對應的分組字段為NULL
語法:group by?字段 [asc|desc] with rollup;
having子句
本質和where一樣,用來進行數據條件篩選。
1、having實在group子句之后,可以針對分組數據進行統計篩選,但是where不行,where不能使用聚合函數
2、having在group?by?分組之后,可以使用聚合函數或者字段別名(where是從表中取出數據,別名是在數據進入到內存之后才有的)
order by子句
排序,根據校對規則對數據進行排序
基本語法:order by?字段 [asc|desc] ;
也可以像group?一樣進行多字段排序:先按照第一個字段進行排序,再按照第二個字段進行排序
語法:order by?字段1 [asc|desc] ,?字段2[asc|desc]?;
limit子句
limit限制子句:主要是用來限制記錄數量獲取
記錄數限制:
純粹的限制獲取的數量:從第一條到指定的數量
語法:limit?數量;
limit通常在查詢的時候如果限定為一條記錄的時候,使用的比較多,有時候獲取多條記錄并不能解決業務問題,但是會增加服務器的壓力
分頁:(減輕服務器壓力,減少用戶端響應時間)
利用limit限制獲取指定區間的數據
語法:limit offset , length;? ? ? ? ? ? //offset:偏移量,從哪開始? ? ?length:最多獲取多少條記錄,但是如果數量不夠,系統不會強求
MySQL中記錄的數量從0開始
五種子句都不是必要存在,但是存在的子句需要按照順序書寫
:語言處理和Python)

)



搭建網站(nginx+php+mysql+ddclient))


![一幫一python_[python]L1-030?一幫一?(15分)](http://pic.xiahunao.cn/一幫一python_[python]L1-030?一幫一?(15分))



)
![java hibernate 插入數據_[Java教程]hibernate 返回新插入數據的Id](http://pic.xiahunao.cn/java hibernate 插入數據_[Java教程]hibernate 返回新插入數據的Id)

和MySQL不區分大小寫...)


