
寫在開頭:
本章是Kafka學習歸納第五部分,著重于強調Kafka的事一致性保證,消息重復消費場景及解決方式,記錄偏移量的主題,延時隊列的知識點。
文章內容輸出來源:拉勾教育大數據高薪訓練營。
一致性保證
水位標記
水位或水印(watermark)一詞,表示位置信息,即位移(offset)。Kafka源碼中使用的名字是高水位,HW(high watermark)。
LEO和HW
每個分區副本對象都有兩個重要的屬性:LEO和HW
LEO:即日志末端位移(log end offset),記錄了該副本日志中下一條消息的位移值。如果 LEO=10,那么表示該副本保存了10條消息,位移值范圍是[0, 9]。另外,Leader LEO和 Follower LEO的更新是有區別的。
HW:即上面提到的水位值。對于同一個副本對象而言,其HW值不會大于LEO值。小于等于 HW值的所有消息都被認為是“已備份”的(replicated)。Leader副本和Follower副本的HW更新不同
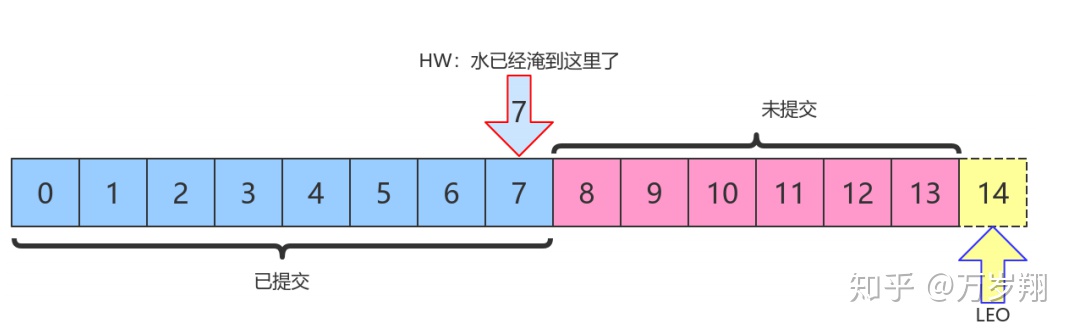
上圖中,HW值是7,表示位移是 0~7 的所有消息都已經處于“已提交狀態”(committed),而LEO值是14,8~13的消息就是未完全備份(fully replicated)——為什么沒有14?LEO指向的是下一條消息到來時的位移。
消費者無法消費分區下Leader副本中位移大于分區HW的消息
Follower副本何時更新LEO
Follower副本不停地向Leader副本所在的broker發送FETCH請求,一旦獲取消息后寫入自己的日志中進行備份。那么Follower副本的LEO是何時更新的呢?首先我必須言明,Kafka有兩套Follower副本
LEO:
1. 一套LEO保存在Follower副本所在Broker的副本管理機中;
2. 另一套LEO保存在Leader副本所在Broker的副本管理機中。Leader副本機器上保存了所有的follower副本的LEO。
Kafka使用前者幫助Follower副本更新其HW值;利用后者幫助Leader副本更新其HW。
1. Follower副本的本地LEO何時更新? Follower副本的LEO值就是日志的LEO值,每當新寫入一條消息,LEO值就會被更新。當Follower發送FETCH請求后,Leader將數據返回給Follower,此時Follower開始Log寫數據,從而自動更新LEO值。
2. Leader端Follower的LEO何時更新? Leader端的Follower的LEO更新發生在Leader在處理 Follower FETCH請求時。一旦Leader接收到Follower發送的FETCH請求,它先從Log中讀取 相應的數據,給Follower返回數據前,先更新Follower的LEO。
Follower副本何時更新HW
Follower更新HW發生在其更新LEO之后,一旦Follower向Log寫完數據,嘗試更新自己的HW值。
比較當前LEO值與FETCH響應中Leader的HW值,取兩者的小者作為新的HW值。
即:如果Follower的LEO大于Leader的HW,Follower HW值不會大于Leader的HW值。
Leader副本何時更新LEO
和Follower更新LEO相同,Leader寫Log時自動更新自己的LEO值。
Leader副本何時更新HW值
Leader的HW值就是分區HW值,直接影響分區數據對消費者的可見性
Leader會嘗試去更新分區HW的四種情況:
1. Follower副本成為Leader副本時:Kafka會嘗試去更新分區HW。
2. Broker崩潰導致副本被踢出ISR時:檢查下分區HW值是否需要更新是有必要的。
3. 生產者向Leader副本寫消息時:因為寫入消息會更新Leader的LEO,有必要檢查HW值是否需要更新
4. Leader處理Follower FETCH請求時:首先從Log讀取數據,之后嘗試更新分區HW值
結論:
當Kafka broker都正常工作時,分區HW值的更新時機有兩個:
1. Leader處理PRODUCE請求時
2. Leader處理FETCH請求時。
Leader如何更新自己的HW值?Leader broker上保存了一套Follower副本的LEO以及自己的LEO。當嘗試確定分區HW時,它會選出所有滿足條件的副本,比較它們的LEO(包括Leader的LEO),并選擇最小的LEO值作為HW值。
需要滿足的條件,(二選一):
1. 處于ISR中
2. 副本LEO落后于Leader LEO的時長不大于 replica.lag.time.max.ms 參數值(默認是10s)
如果Kafka只判斷第一個條件的話,確定分區HW值時就不會考慮這些未在ISR中的副本,但這些副本已經具備了“立刻進入ISR”的資格,因此就可能出現分區HW值越過ISR中副本LEO的情況——不允許。因為分區HW定義就是ISR中所有副本LEO的最小值
消息重復的場景及解決方案
消息重復和丟失是kafka中很常見的問題,主要發生在以下三個階段:
1. 生產者階段
2. broke階段
3. 消費者階段
生產者階段重復場景
生產發送的消息沒有收到正確的broke響應,導致生產者重試。
生產者發出一條消息,broke落盤以后因為網絡等種種原因發送端得到一個發送失敗的響應或者網絡中斷,然后生產者收到一個可恢復的Exception重試消息導致消息重復。
生產者發送重復解決方案
啟動kafka的冪等性
要啟動kafka的冪等性,設置: enable.idempotence=true ,以及 ack=all 以及 retries > 1
ack=0,不重試。 可能會丟消息,適用于吞吐量指標重要性高于數據丟失,例如:日志收集。
生產者和broke階段消息丟失場景
ack=0,不重試
生產者發送消息完,不管結果了,如果發送失敗也就丟失了。
ack=1,leader crash
生產者發送消息完,只等待Leader寫入成功就返回了,Leader分區丟失了,此時Follower沒來及同步,消息丟失
unclean.leader.election.enable 配置true
允許選舉ISR以外的副本作為leader,會導致數據丟失,默認為false。生產者發送異步消息,只等待Lead寫入成功就返回,Leader分區丟失,此時ISR中沒有Follower,Leader從OSR中選舉,因為OSR中本來落后于Leader造成消息丟失
解決生產者和broke階段消息丟失
禁用unclean選舉,ack=all
ack=all / -1,tries > 1,unclean.leader.election.enable=false生產者發完消息,等待Follower同步完再返回,如果異常則重試。副本的數量可能影響吞吐量,不超過5個,一般三個。 不允許unclean Leader選舉。
配置:min.insync.replicas > 1
當生產者將 acks 設置為 all (或 -1 )時, min.insync.replicas>1 。指定確認消息寫成功需要的最小副本數量。達不到這個最小值,生產者將引發一個異常(要么是NotEnoughReplicas,要么是NotEnoughReplicasAfterAppend)。
當一起使用時, min.insync.replicas 和 ack 允許執行更大的持久性保證。一個典型的場景是創建一個復制因子為3的主題,設置min.insync復制到2個,用 all 配置發送。將確保如果大多數副本沒有收到寫操作,則生產者將引發異常。
失敗的offset單獨記錄
生產者發送消息,會自動重試,遇到不可恢復異常會拋出,這時可以捕獲異常記錄到數據庫或緩存,進行單獨處理。
消費者數據重復場景及解決方案
數據消費完沒有及時提交offset到broker。
消息消費端在消費過程中掛掉沒有及時提交offset到broke,另一個消費端啟動拿之前記錄的offset開始消費,由于offset的滯后性可能會導致新啟動的客戶端有少量重復消費。
解決方案
取消自動提交
每次消費完或者程序退出時手動提交。這可能也沒法保證一條重復。
下游做冪等
一般是讓下游做冪等或者盡量每消費一條消息都記錄offset,對于少數嚴格的場景可能需要把 offset或唯一ID(例如訂單ID)和下游狀態更新放在同一個數據庫里面做事務來保證精確的一次更新或者在下游數據表里面同時記錄消費offset,然后更新下游數據的時候用消費位移做樂觀鎖拒絕舊位移的數據更新。
__consumer_offsets
Kafka 1.0.2將consumer的位移信息保存在Kafka內部的topic中,即__consumer_offsets主題,并且默認提供了kafka_consumer_groups.sh腳本供用戶查看consumer信息。
創建topic “tp_test_01”
kafka-topics.sh --zookeeper node1:2181/myKafka --create --
topic tp_test_01 --partitions 5 --replication-factor 1使用kafka-console-producer.sh腳本生產消息
[root@node1 ~]# for i in `seq 60`; do echo "hello lagou $i" >> messages.txt;
done
[root@node1 ~]# kafka-console-producer.sh --broker-list node1:9092 --topic
tp_test_01 < messages.txt 由于默認沒有指定key,所以根據round-robin方式,消息分布到不同的分區上。 (本例中生產了60條消息)
驗證消息生產成功
kafka-run-class.sh kafka.tools.GetOffsetShell
--broker-list node1:9092 --topic tp_test_01 --time -1
創建一個console consumer group
kafka-console-consumer.sh
--bootstrap-server linux121:9092 --topic tp_test_01 --from-beginning獲取該consumer group的group id(后面需要根據該id查詢它的位移信息)
kafka-consumer-groups.sh --bootstrap-server linux121:9092 --list
查詢__consumer_offsets topic所有內容
注意:運行下面命令前先要在consumer.properties中設置exclude.internal.topics=false
kafka-console-consumer.sh --topic __consumer_offsets
--bootstrap-server node1:9092 --formatter
"kafka.coordinator.group.GroupMetadataManager$OffsetsMessageFormatter"
--consumer.config config/consumer.properties --from-beginning 默認情況下__consumer_offsets有50個分區,如果你的系統中consumer group也很多的話,那么這個命令的輸出結果會很多。
計算指定consumer group在__consumer_offsets topic中分區信息
這時候就用到了group.id :console-consumer-77682
Kafka會使用下面公式計算該group位移保存在__consumer_offsets的哪個分區上:
Math.abs(groupID.hashCode()) % numPartitions 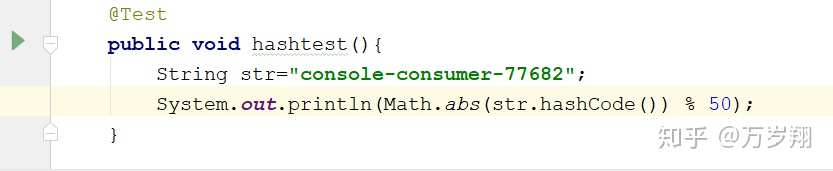
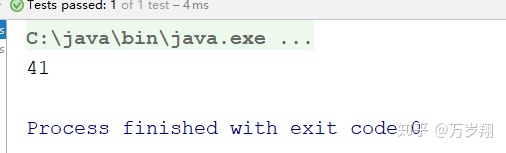
即
__consumer_offsets的分區41保存了這個consumer group的位移信息。
獲取指定consumer group的位移信息
kafka-simple-consumer-shell.sh --topic __consumer_offsets
--partition 41 --broker-list linux121:9092
--formatter "kafka.coordinator.group.GroupMetadataManager$OffsetsMessageFormatter"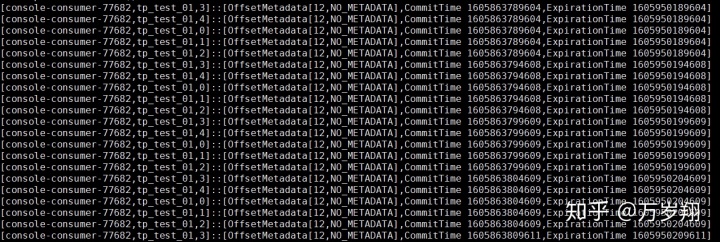
可以看到__consumer_offsets topic的每一日志項的格式都是:
[Group, Topic, Partition]::[OffsetMetadata[Offset, Metadata], CommitTime, ExpirationTime]
延時隊列
兩個follower副本都已經拉取到了leader副本的最新位置,此時又向leader副本發送拉取請求,而leader副本并沒有新的消息寫入,那么此時leader副本該如何處理呢?可以直接返回空的拉取結果給follower副本,不過在leader副本一直沒有新消息寫入的情況下,follower副本會一直發送拉取請求,并且總收到空的拉取結果,消耗資源。
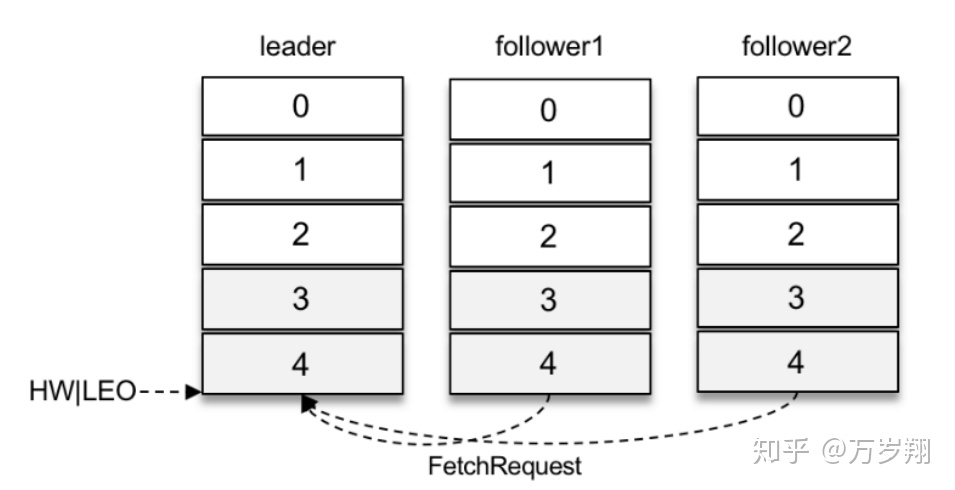
Kafka在處理拉取請求時,會先讀取一次日志文件,如果收集不到足夠多(fetchMinBytes,由參數fetch.min.bytes配置,默認值為1)的消息,那么就會創建一個延時拉取操作(DelayedFetch)以等待拉取到足夠數量的消息。當延時拉取操作執行時,會再讀取一次日志文件,然后將拉取結果返回給follower副本。
延遲操作不只是拉取消息時的特有操作,在Kafka中有多種延時操作,比如延時數據刪除、延時生產等。
對于延時生產(消息)而言,如果在使用生產者客戶端發送消息的時候將acks參數設置為-1,那么就意味著需要等待ISR集合中的所有副本都確認收到消息之后才能正確地收到響應的結果,或者捕獲超時異常。
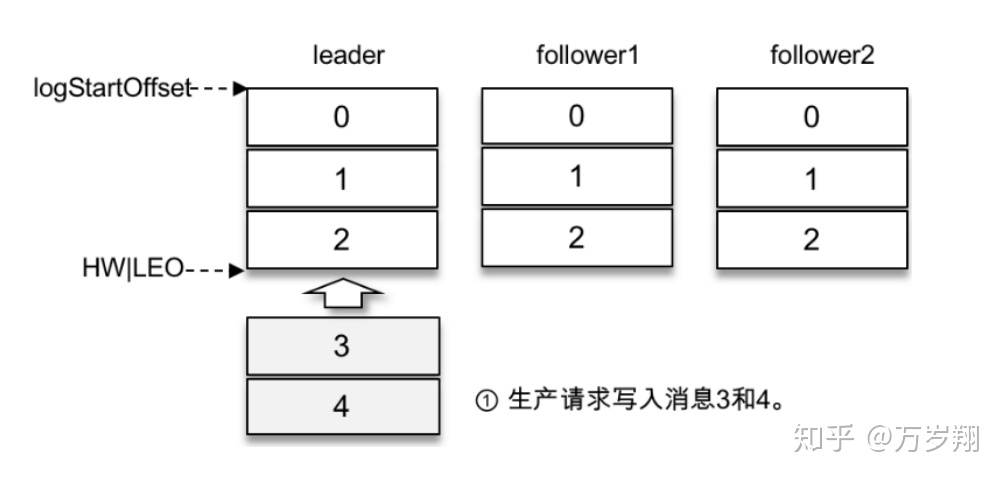
假設某個分區有3個副本:leader、follower1和follower2,它們都在分區的ISR集合中。不考慮ISR變動的情況,Kafka在收到客戶端的生產請求后,將消息3和消息4寫入leader副本的本地日志文件。
由于客戶端設置了acks為-1,那么需要等到follower1和follower2兩個副本都收到消息3和消息4后才能告知客戶端正確地接收了所發送的消息。如果在一定的時間內,follower1副本或follower2副本沒能夠完全拉取到消息3和消息4,那么就需要返回超時異常給客戶端。生產請求的超時時間由參數request.timeout.ms配置,默認值為30000,即30s。
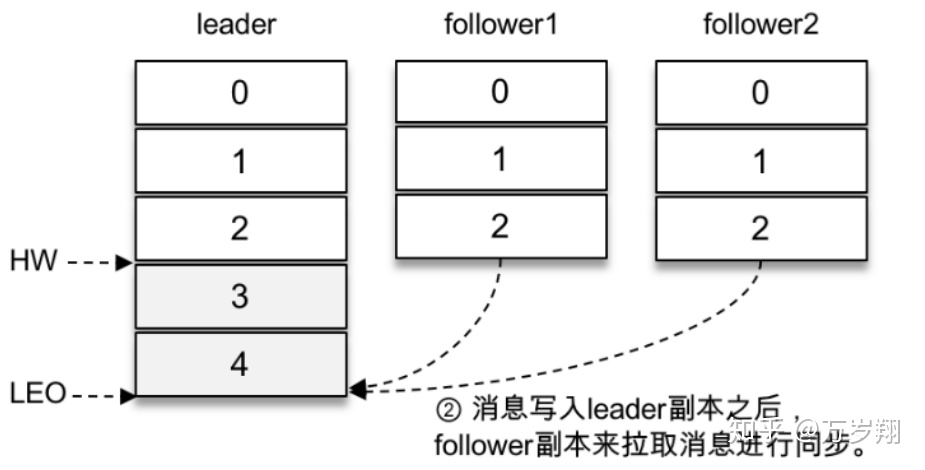
那么這里等待消息3和消息4寫入follower1副本和follower2副本,并返回相應的響應結果給客戶端的動作是由誰來執行的呢?在將消息寫入leader副本的本地日志文件之后,Kafka會創建一個延時的生產操作(DelayedProduce),用來處理消息正常寫入所有副本或超時的情況,以返回相應的響應結果給客戶端。
延時操作需要延時返回響應的結果,首先它必須有一個超時時間(delayMs),如果在這個超時時間內沒有完成既定的任務,那么就需要強制完成以返回響應結果給客戶端。其次,延時操作不同于定時操作,定時操作是指在特定時間之后執行的操作,而延時操作可以在所設定的超時時間之前完成,所以延時操作能夠支持外部事件的觸發。
就延時生產操作而言,它的外部事件是所要寫入消息的某個分區的HW(高水位)發生增長。也就是說,隨著follower副本不斷地與leader副本進行消息同步,進而促使HW進一步增長,HW每增長一次都會檢測是否能夠完成此次延時生產操作,如果可以就執行以此返回響應結果給客戶端;如果在超時時間內始終無法完成,則強制執行。
延時拉取操作,是由超時觸發或外部事件觸發而被執行的。超時觸發很好理解,就是等到超時時間之后觸發第二次讀取日志文件的操作。外部事件觸發就稍復雜了一些,因為拉取請求不單單由follower副本發起,也可以由消費者客戶端發起,兩種情況所對應的外部事件也是不同的。如果是follower副本的延時拉取,它的外部事件就是消息追加到了leader副本的本地日志文件中;如果是消費者客戶端的延時拉取,它的外部事件可以簡單地理解為HW的增長。



















