之前看過高斯過程(GP),不過當時也沒太看懂,最近花時間認真研究了一下,感覺總算是明白咋回事了,本文基于回歸問題解釋GP模型的思想和方法。文中的想法是自己思考總結得來,并不一定準確,也可能存在錯誤性。
為什么要用GP?
回顧一下我們之前在解決回歸問題時,就拿線性回歸舉例,我們為了學習映射函數,總是把函數參數化,例如假設
但是有時候我們并不知道數據到底用什么形式的函數去擬合比較好(是1次的,2次的還是10次的?)。這個時候高斯過程(GP)就閃亮登場了,GP說:“我不需要用參數去刻畫函數,你就告訴我訓練數據是什么,你想要預測哪些數據,我就能給你預測出結果。“這樣一來,我們就省去了去選擇刻畫函數參數的這樣一個過程。
GP是怎么來的?
那么GP是怎么做到的呢?我們先來看這樣一件有趣的事情:
假設我們的函數定義域和值域都是
然而,事實上雖然很多實際問題(比如房價的預測),它的定義域和值域都是
高斯過程(GP)
下面我們就開始正式的介紹高斯過程(GP),它是怎么得到這個
其中
- 在本次訓練中,我們的定義域是
。
- 在這個定義域中,如果
基于核函數是非常接近的,那么你們的輸出值也會非常接近。
- 我們是用高斯分布去進行刻畫(用高斯的好處,至少有一點條件概率密度函數很好算)。
我們把上面的概率分布展開:
其中
利用高斯分布的性質(通過聯合分布計算條件分布),我們可以得到
這樣我們計算出了我們希望得到的
- 這一點也是我們上面就說過的,GP是無參的,對于任何一組數據,你不需要知道他的結構是什么,你也不需要去用參數刻畫它函數的樣子,GP就可以幫你做預測。
- GP它刻畫出了函數的概率分布。這個非常有用。回顧之前的線性回歸的方法,當你把參數 很有信心地給你一個判斷。但是,如果你給我一張鴕鳥照片,強迫我說出它是貓還是狗,我就只能信心全無地預測一下。——Yarin Gal。
估計出來后,你的函數就確定了,接下來我拿出任何一個數,你都會“毫無感情的”給我一個預測值。但是GP不一樣,當我們知道我們預測函數的不確定度(不確定度很高,這個預測的結果就不可靠)之后,我們能探索最不可能實現高效訓練的數據區域。這也是貝葉斯優化背后的主要思想。下面這句話我覺得寫得非常貼切:如果你給我幾張貓和狗的圖片,要我對一張新的貓咪照片分類,我可以
有噪聲觀測的情況下
在有噪觀測的情況下,我們假設觀測模型是這樣的
核函數參數的影響
那么核函數對GP有什么影響呢,假設我們選擇SE核函數:
這個核函數有三個參數,分別是
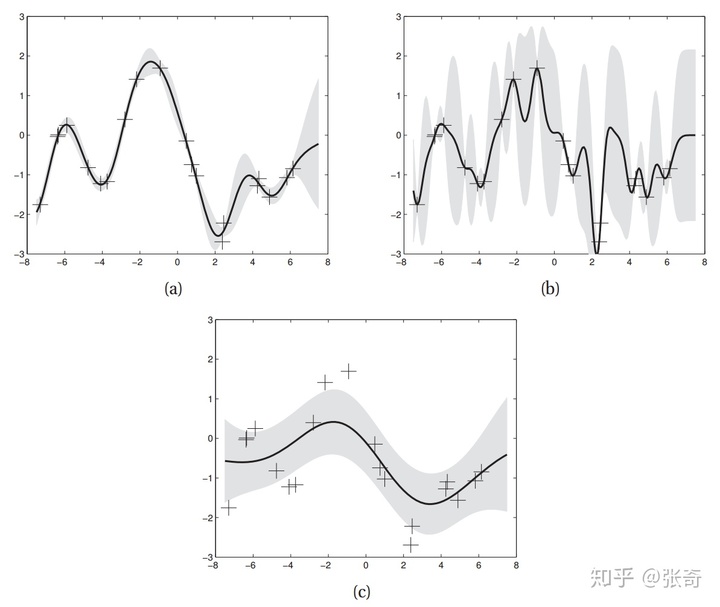
三幅圖的超參數
我們可以看到(a)圖整體看上去是估計的比較好的,(b)圖中,減小了




)
,offer拿到手軟,無償分享...)











有什么作用?)

