常用的幾種卷積神經網絡介紹
標簽(空格分隔): 深度學習
這是一篇基礎理論的博客,基本手法是抄、刪、改、查,畢竟介紹這幾個基礎網絡的博文也挺多的,就算是自己的一個筆記吧,以后忘了多看看。主要是想介紹下常用的幾種卷積神經網絡。卷積神經網絡最初為解決圖像識別問題而提出,目前廣泛應用于圖像,視頻,音頻和文本數據,可以當做深度學習的代名詞。目前圖像分類中的ResNet, 目標檢測領域占統治地位的Faster R-CNN,分割中最牛的Mask-RCNN, UNet和經典的FCN都是以下面幾種常見網絡為基礎。
LeNet
網絡背景
LeNet誕生于1994年,由深度學習三巨頭之一的Yan LeCun提出,他也被稱為卷積神經網絡之父。LeNet主要用來進行手寫字符的識別與分類,準確率達到了98%,并在美國的銀行中投入了使用,被用于讀取北美約10%的支票。LeNet奠定了現代卷積神經網絡的基礎。
網絡結構?
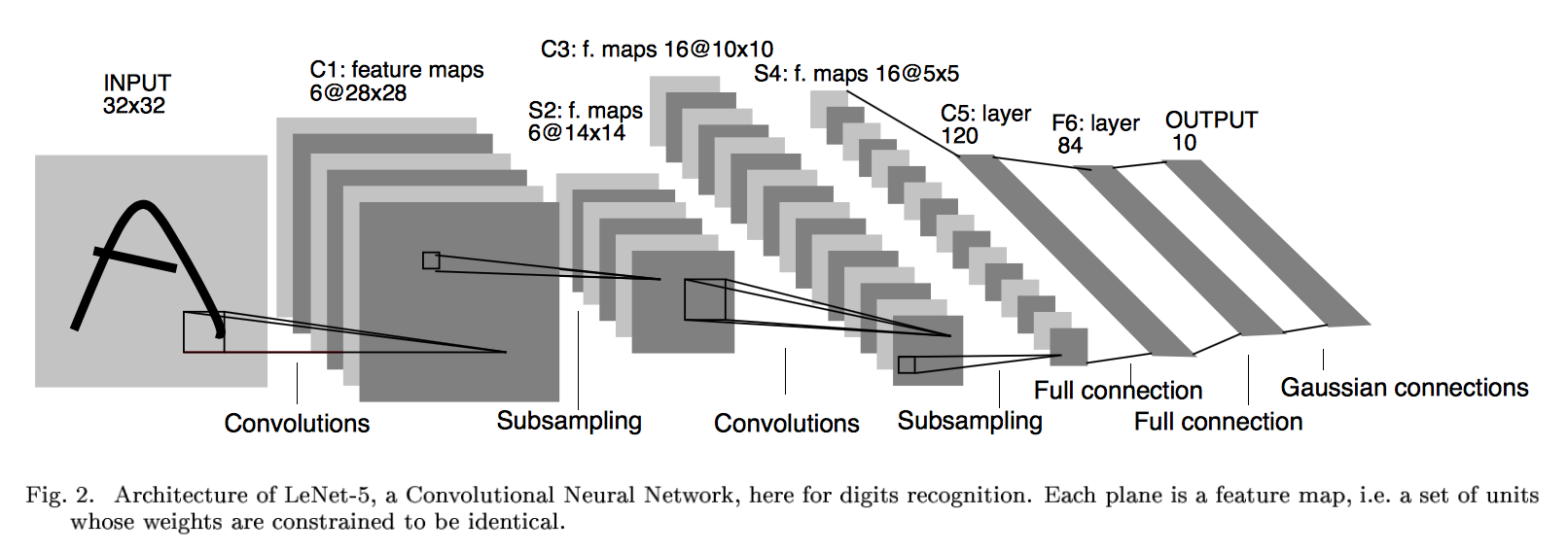
上圖為LeNet結構圖,是一個6層網絡結構:三個卷積層,兩個下采樣層和一個全連接層(圖中C代表卷積層,S代表下采樣層,F代表全連接層)。其中,C5層也可以看成是一個全連接層,因為C5層的卷積核大小和輸入圖像的大小一致,都是5*5(可參考LeNet詳細介紹)。
網絡特點
每個卷積層包括三部分:卷積、池化和非線性激活函數(sigmoid激活函數)
使用卷積提取空間特征
降采樣層采用平均池化
AlexNet
網絡背景
AlexNet由Hinton的學生Alex Krizhevsky于2012年提出,并在當年取得了Imagenet比賽冠軍。AlexNet可以算是LeNet的一種更深更寬的版本,證明了卷積神經網絡在復雜模型下的有效性,算是神經網絡在低谷期的第一次發聲,確立了深度學習,或者說卷積神經網絡在計算機視覺中的統治地位。
網絡結構?
?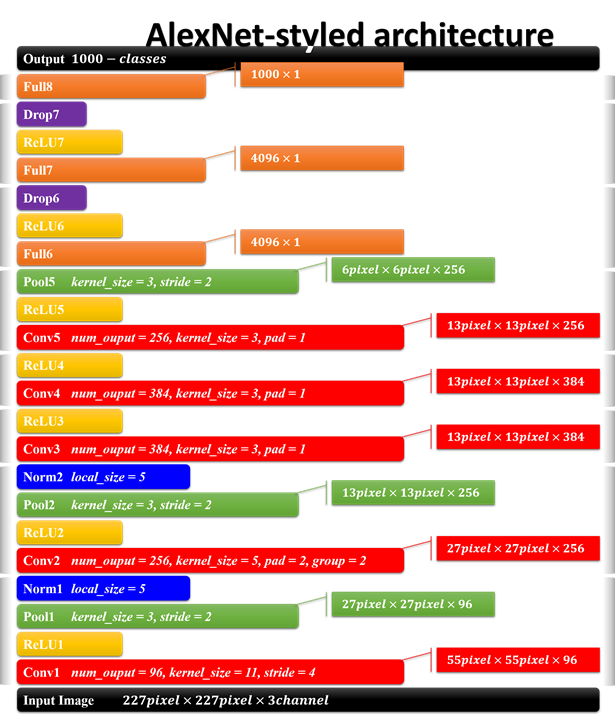
AlexNet的結構及參數如上圖所示,是8層網絡結構(忽略激活,池化,LRN,和dropout層),有5個卷積層和3個全連接層,第一卷積層使用大的卷積核,大小為11*11,步長為4,第二卷積層使用5*5的卷積核大小,步長為1,剩余卷積層都是3*3的大小,步長為1。激活函數使用ReLu(雖然不是他發明,但是他將其發揚光大),池化層使用重疊的最大池化,大小為3*3,步長為2。在全連接層增加了dropout,第一次將其實用化。(參考:AlexNet詳細解釋)
網絡特點
使用兩塊GPU并行加速訓練,大大降低了訓練時間
成功使用ReLu作為激活函數,解決了網絡較深時的梯度彌散問題
使用數據增強、dropout和LRN層來防止網絡過擬合,增強模型的泛化能力
VggNet
網絡背景
VGGNet是牛津大學計算機視覺組和Google DeepMind公司一起研發的深度卷積神經網絡,并取得了2014年Imagenet比賽定位項目第一名和分類項目第二名。該網絡主要是泛化性能很好,容易遷移到其他的圖像識別項目上,可以下載VGGNet訓練好的參數進行很好的初始化權重操作,很多卷積神經網絡都是以該網絡為基礎,比如FCN,UNet,SegNet等。vgg版本很多,常用的是VGG16,VGG19網絡。
網絡結構?
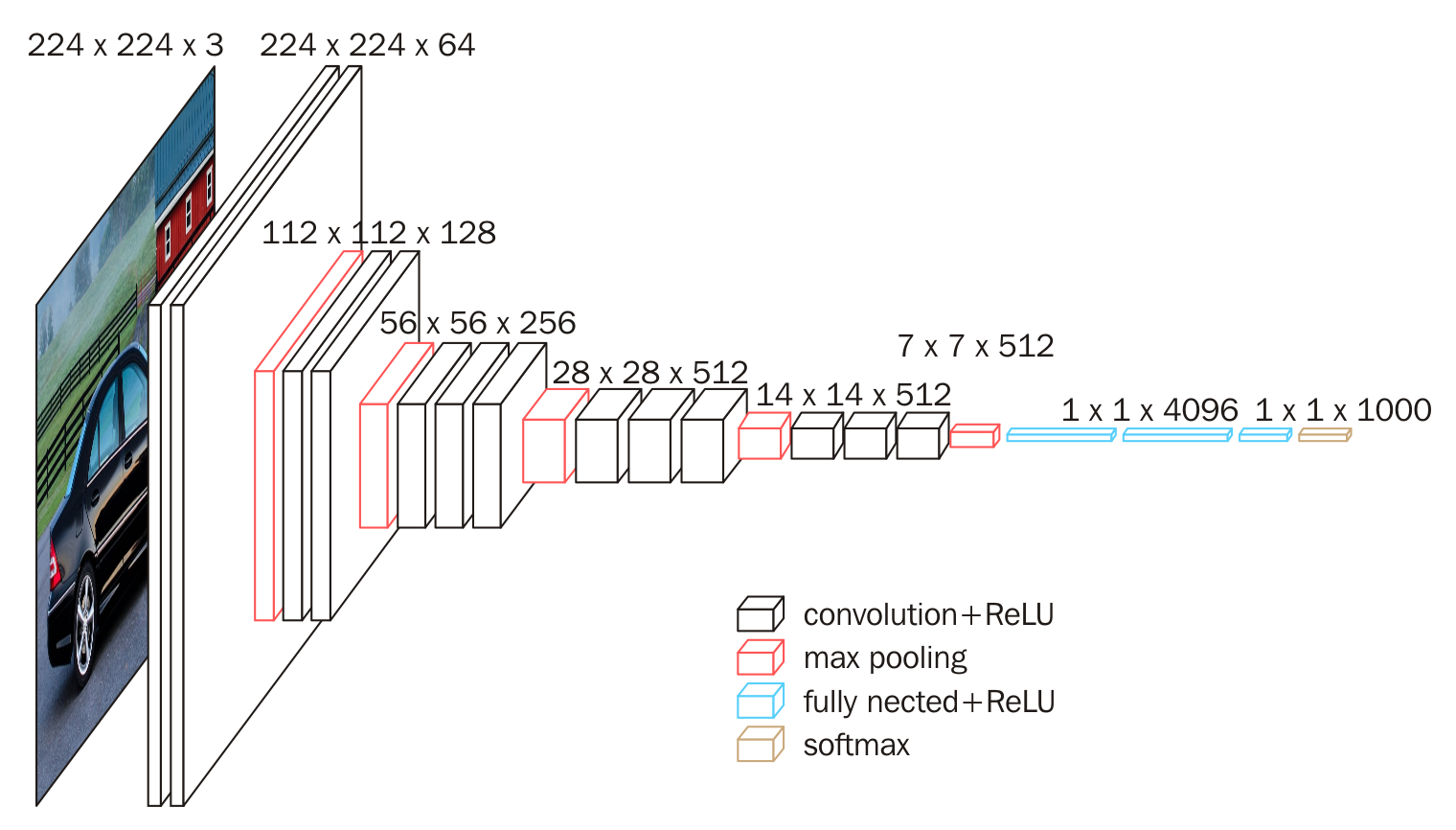
上圖為VGG16的網絡結構,共16層(不包括池化和softmax層),所有的卷積核都使用3*3的大小,池化都使用大小為2*2,步長為2的最大池化,卷積層深度依次為64 -> 128 -> 256 -> 512 ->512。
網絡特點?
網絡結構和AlexNet有點兒像,不同的地方在于:
主要的區別,一個字:深,兩個字:更深。把網絡層數加到了16-19層(不包括池化和softmax層),而AlexNet是8層結構。
將卷積層提升到卷積塊的概念。卷積塊有2~3個卷積層構成,使網絡有更大感受野的同時能降低網絡參數,同時多次使用ReLu激活函數有更多的線性變換,學習能力更強(詳細介紹參考:TensorFlow實戰P110頁)。
在訓練時和預測時使用Multi-Scale做數據增強。訓練時將同一張圖片縮放到不同的尺寸,在隨機剪裁到224*224的大小,能夠增加數據量。預測時將同一張圖片縮放到不同尺寸做預測,最后取平均值。
ResNet
網絡背景
ResNet(殘差神經網絡)由微軟研究院的何凱明等4名華人于2015年提出,成功訓練了152層超級深的卷積神經網絡,效果非常突出,而且容易結合到其他網絡結構中。在五個主要任務軌跡中都獲得了第一名的成績:
ImageNet分類任務:錯誤率3.57%
ImageNet檢測任務:超過第二名16%
ImageNet定位任務:超過第二名27%
COCO檢測任務:超過第二名11%
COCO分割任務:超過第二名12%
作為大神級人物,何凱明憑借Mask R-CNN論文獲得ICCV2017最佳論文,也是他第三次斬獲頂會最佳論文,另外,他參與的另一篇論文:Focal Loss for Dense Object Detection,也被大會評為最佳學生論文。
網絡結構?
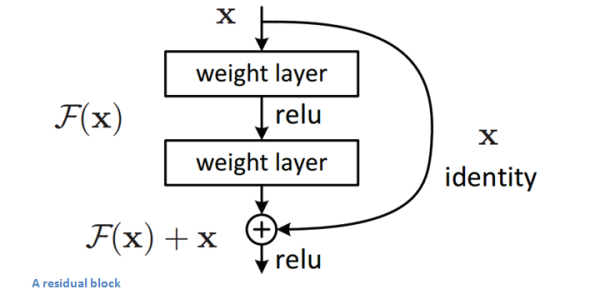
?
上圖為殘差神經網絡的基本模塊(專業術語叫殘差學習單元),輸入為x,輸出為F(x)+x,F(x)代表網絡中數據的一系列乘、加操作,假設神經網絡最優的擬合結果輸出為H(x)=F(x)+x,那么神經網絡最優的F(x)即為H(x)與x的殘差,通過擬合殘差來提升網絡效果。為什么轉變為擬合殘差就比傳統卷積網絡要好呢?因為訓練的時候至少可以保證殘差為0,保證增加殘差學習單元不會降低網絡性能,假設一個淺層網絡達到了飽和的準確率,后面再加上這個殘差學習單元,起碼誤差不會增加。(參考:ResNet詳細解釋)?
通過不斷堆疊這個基本模塊,就可以得到最終的ResNet模型,理論上可以無限堆疊而不改變網絡的性能。下圖為一個34層的ResNet網絡。?
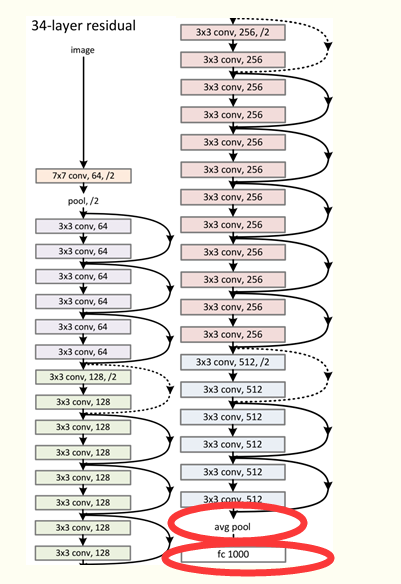
網絡特點
使得訓練超級深的神經網絡成為可能,避免了不斷加深神經網絡,準確率達到飽和的現象(后來將層數增加到1000層)
輸入可以直接連接到輸出,使得整個網絡只需要學習殘差,簡化學習目標和難度。
ResNet是一個推廣性非常好的網絡結構,容易和其他網絡結合
論文地址:?
1. LeNet論文?
2. AlexNet論文?
3. VGGNet論文?
4. ResNet論文
---------------------?
作者:feixian15?
來源:CSDN?
原文:https://blog.csdn.net/qq_34759239/article/details/79034849?
版權聲明:本文為博主原創文章,轉載請附上博文鏈接!
爆力)







)


)


)




