深入淺出數據庫索引原理
參見:https://www.cnblogs.com/aspwebchh/p/6652855.html
1.為什么給表加上主鍵?
- 1.平時創建表的時候,都會給表加上主鍵。如果沒有主鍵的表,數據會一行行的排列在磁盤上,查找一個數據需要一條條的進行對比。而加上主鍵的表,會變成樹形(B樹/B+樹),這樣整個表就變成一個索引,即聚合索引
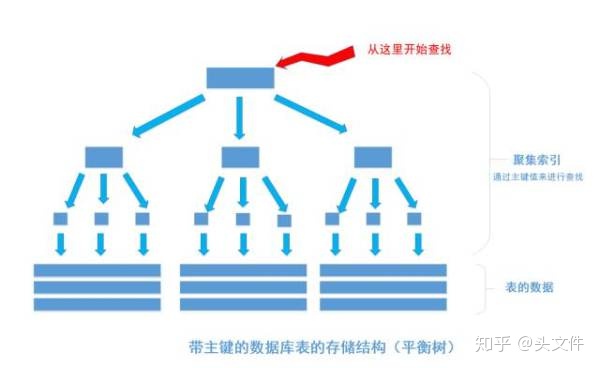
假如我們執行一個SQL語句:
select * from table where id = 1256;
首先根據索引定位到1256這個值所在的葉結點,然后再通過葉結點取到id等于1256的數據行。
2.為什么索引后會使查詢變快?
- 假如一張表有一億條數據 ,需要查找其中某一條數據,按照常規邏輯, 一條一條的去匹配的話, 最壞的情況下需要匹配一億次才能得到結果,用大O標記法就是O(n)最壞時間復雜度,這是無法接受的,而且這一億條數據顯然不能一次性讀入內存供程序使用, 因此, 這一億次匹配在不經緩存優化的情況下就是一億次IO開銷,以現在磁盤的IO能力和CPU的運算能力, 有可能需要幾個月才能得出結果 。如果把這張表轉換成平衡樹結構(一棵非常茂盛和節點非常多的樹),假設這棵樹有10層,那么只需要10次IO開銷就能查找到所需要的數據, 速度以指數級別提升,用大O標記法就是O(log n),n是記錄總樹,底數是樹的分叉數,結果就是樹的層次數。
3.為什么加索引后會使寫入、修改、刪除變慢?
- 事物都是有兩面的, 索引能讓數據庫查詢數據的速度上升, 而使寫入數據的速度下降,原因很簡單的, 因為平衡樹這個結構必須一直維持在一個正確的狀態, 增刪改數據都會改變平衡樹各節點中的索引數據內容,破壞樹結構, 因此,在每次數據改變時, DBMS必須去重新梳理樹(索引)的結構以確保它的正確,這會帶來不小的性能開銷,也就是為什么索引會給查詢以外的操作帶來副作用的原因。
4.什么情況下要同時在兩個字段上建索引?
4.1 非聚合索引
- 非聚集索引和聚集索引一樣, 同樣是采用平衡樹作為索引的數據結構。索引樹結構中各節點的值來自于表中的索引字段, 假如給user表的name字段加上索引 , 那么索引就是由name字段中的值構成,在數據改變時, DBMS需要一直維護索引結構的正確性。如果給表中多個字段加上索引 , 那么就會出現多個獨立的索引結構,每個索引(非聚集索引)互相之間不存在關聯。 如下圖
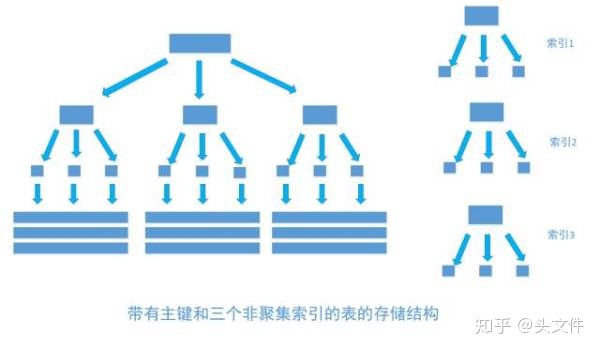
- 每次給字段建一個新索引, 字段中的數據就會被復制一份出來, 用于生成索引。 因此, 給表添加索引,會增加表的體積, 占用磁盤存儲空間。
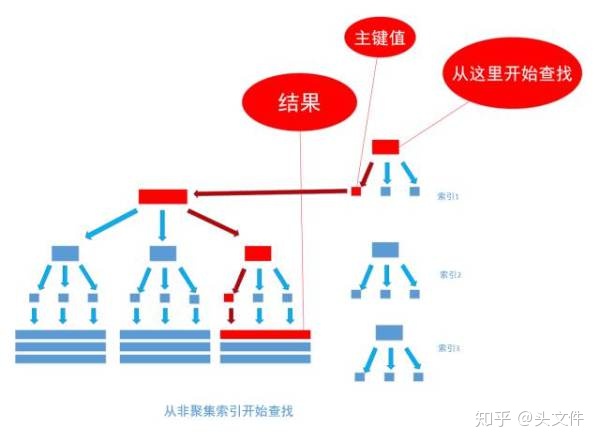
非聚集索引和聚集索引的區別在于, 通過聚集索引可以查到需要查找的數據, 而通過非聚集索引可以查到記錄對應的主鍵值 , 再使用主鍵的值通過聚集索引查找到需要的數據,如下圖
4.2 覆蓋索引
- 非聚合索引都會利用主鍵通過聚合索引來定位到數據,聚合索引(主鍵)是通往真實數據所在的唯一路徑,但是有一種例外是可以不使用聚合索引就能查詢到所需要的數據,這種辦法被稱為覆蓋索引。
先看下面這個SQL語句
//建立索引
create index index_birthday on user_info(birthday);
//查詢生日在1991年11月1日出生用戶的用戶名
select user_name from user_info where birthday = '1991-11-1'
這句SQL語句的執行過程如下
首先,通過非聚集索引index_birthday查找birthday等于1991-11-1的所有記錄的主鍵ID值
然后,通過得到的主鍵ID值執行聚集索引查找,找到主鍵ID值對就的真實數據(數據行)存儲的位置
最后, 從得到的真實數據中取得user_name字段的值返回, 也就是取得最終的結果
我們把birthday字段上的索引改成雙字段的覆蓋索引
create index index_birthday_and_user_name on user_info(birthday, user_name);
這句SQL語句的執行過程就會變為
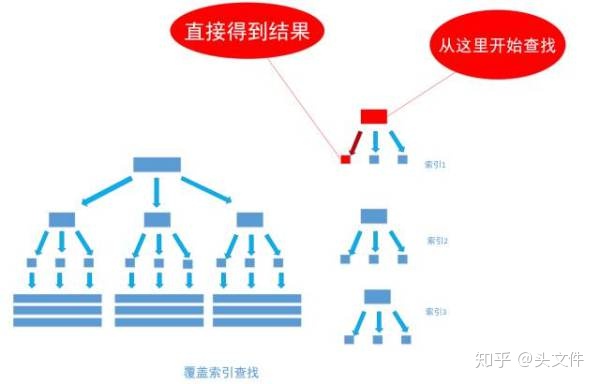
通過非聚集索引index_birthday_and_user_name查找birthday等于1991-11-1的葉節點的內容,然而, 葉節點中除了有user_name表主鍵ID的值以外, user_name字段的值也在里面, 因此不需要通過主鍵ID值的查找數據行的真實所在, 直接取得葉節點中user_name的值返回即可。 通過這種覆蓋索引直接查找的方式, 可以省略不使用覆蓋索引查找的后面兩個步驟, 大大的提高了查詢性能,如下圖
一、為什么要創建索引呢(優點)?
這是因為,創建索引可以大大提高系統的性能。
第一, 通過創建唯一性索引,可以保證數據庫表中每一行數據的唯一性。
第二, 可以大大加快數據的檢索速度,這也是創建索引的最主要的原因。
第三, 可以加速表和表之間的連接,特別是在實現數據的參考完整性方面特別有意義。
第四, 在使用分組和排序子句進行數據檢索時,同樣可以顯著減少查詢中分組和排序的時間。
第五, 通過使用索引,可以在查詢的過程中,使用優化隱藏器,提高系統的性能。
二、建立方向索引的不利因素(缺點)
也許會有人要問:增加索引有如此多的優點,為什么不對表中的每一個列創建一個索引呢?這種想法固然有其合理性,然而也有其片面性。雖然,索引有許多優點,但是,為表中的每一個列都增加索引,是非常不明智的。這是因為,增加索引也有許多不利的一個方面。
第一, 創建索引和維護索引要耗費時間,這種時間隨著數據量的增加而增加。
第二, 索引需要占物理空間,除了數據表占數據空間之外,每一個索引還要占一定的物理空間,如果要建立聚簇索引,那么需要的空間就會更大。
第三, 當對表中的數據進行增加、刪除和修改的時候,索引也要動態的維護,這樣就降低了數據的維護速度。
三、創建方向索引的準則
索引是建立在數據庫表中的某些列的上面。因此,在創建索引的時候,應該仔細考慮在哪些列上可以創建索引,在哪些列上不能創建索引。
一般來說,應該在這些列上創建索引。
第一, 在經常需要搜索的列上,可以加快搜索的速度;
第二, 在作為主鍵的列上,強制該列的唯一性和組織表中數據的排列結構;
第三, 在經常用在連接的列上,這些列主要是一些外鍵,可以加快連接的速度;
第四, 在經常需要根據范圍進行搜索的列上創建索引,因為索引已經排序,其指定的范圍是連續的;
第五, 在經常需要排序的列上創建索引,因為索引已經排序,這樣查詢可以利用索引的排序,加快排序查詢時間;
第六, 在經常使用在WHERE子句中的列上面創建索引,加快條件的判斷速度。
同樣,對于有些列不應該創建索引。一般來說,不應該創建索引的的這些列具有下列特點:
第一, 對于那些在查詢中很少使用或者參考的列不應該創建索引。這是因為,既然這些列很少使用到,因此有索引或者無索引,并不能提高查詢速度。相反,由于增加了索引,反而降低了系統的維護速度和增大了空間需求。
第二, 對于那些只有很少數據值的列也不應該增加索引。這是因為,由于這些列的取值很少,例如人事表的性別列,在查詢的結果中,結果集的數據行占了表中數據行的很大比例,即需要在表中搜索的數據行的比例很大。增加索引,并不能明顯加快檢索速度。
第三, 對于那些定義為text, image和bit數據類型的列不應該增加索引。這是因為,這些列的數據量要么相當大,要么取值很少。
第 四, 當修改性能遠遠大于檢索性能時,不應該創建索引。這是因為,修改性能和檢索性能是互相矛盾的。當增加索引時,會提高檢索性能,但是會降低修改性能。當減少 索引時,會提高修改性能,降低檢索性能。因此,當修改性能遠遠大于檢索性能時,不應該創建索引。



)




)

)
)
技術 -- AlwaysOn可用性組(理論篇))
)

)



