- 目錄
- 1 概述
- 2 HDFS寫數據流程
- 3 HDFS讀數據流程
目錄
最近由于要準備面試,就把之前學過的東西好好整理下,權當是復習。
下面說下HDFS讀寫數據的原理。
1 概述
- HDFS集群分為兩大角色:NameNode、DataNode
- NameNode負責管理整個文件系統的元數據
- DataNode 負責管理用戶的文件數據塊
- 文件會按照固定的大小(blocksize)切成若干塊后分布式存儲在若干臺datanode上
- 每一個文件塊可以有多個副本,并存放在不同的datanode上
- Datanode會定期向Namenode匯報自身所保存的文件block信息,而namenode則會負責保持文件的副本數量
- HDFS的內部工作機制對客戶端保持透明,客戶端請求訪問HDFS都是通過向namenode申請來進行
2 HDFS寫數據流程
2.1 概述
客戶端要向HDFS寫數據,首先要跟namenode通信以確認可以寫文件并獲得接收文件block的datanode,然后,客戶端按順序將文件逐個block傳遞給相應datanode,并由接收到block的datanode負責向其他datanode復制block的副本
2.2 詳細步驟圖
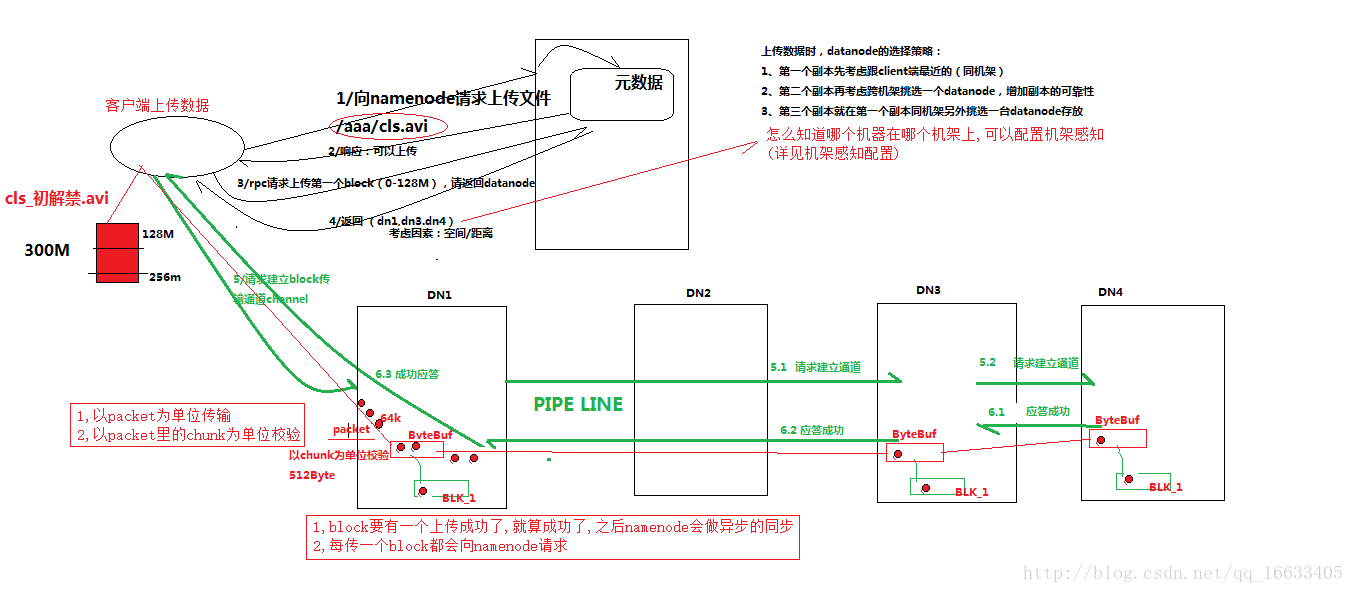
2.3 詳細步驟解析
1、根namenode通信請求上傳文件,namenode檢查目標文件是否已存在,父目錄是否存在
2、namenode返回是否可以上傳
3、client請求第一個 block該傳輸到哪些datanode服務器上
4、namenode返回3個datanode服務器ABC
5、client請求3臺dn中的一臺A上傳數據(本質上是一個RPC調用,建立pipeline),A收到請求會繼續調用B,然后B調用C,將真個pipeline建立完成,逐級返回客戶端
6、client開始往A上傳第一個block(先從磁盤讀取數據放到一個本地內存緩存),以packet為單位,A收到一個packet就會傳給B,B傳給C;A每傳一個packet會放入一個應答隊列等待應答
7、當一個block傳輸完成之后,client再次請求namenode上傳第二個block的服務器。
3 HDFS讀數據流程
3.1 概述
客戶端將要讀取的文件路徑發送給namenode,namenode獲取文件的元信息(主要是block的存放位置信息)返回給客戶端,客戶端根據返回的信息找到相應datanode逐個獲取文件的block并在客戶端本地進行數據追加合并從而獲得整個文件
3.2 詳細步驟圖
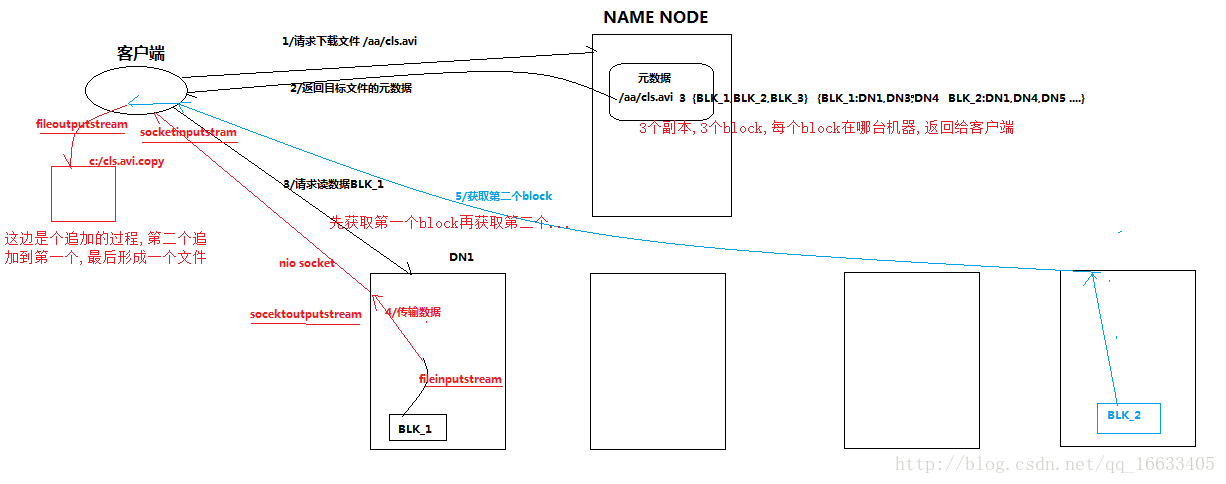
3.3 詳細步驟解析
1、跟namenode通信查詢元數據,找到文件塊所在的datanode服務器
2、挑選一臺datanode(就近原則,然后隨機)服務器,請求建立socket流
3、datanode開始發送數據(從磁盤里面讀取數據放入流,以packet為單位來做校驗)
4、客戶端以packet為單位接收,先在本地緩存,然后寫入目標文件




)











)


)