MapReduce剖析圖
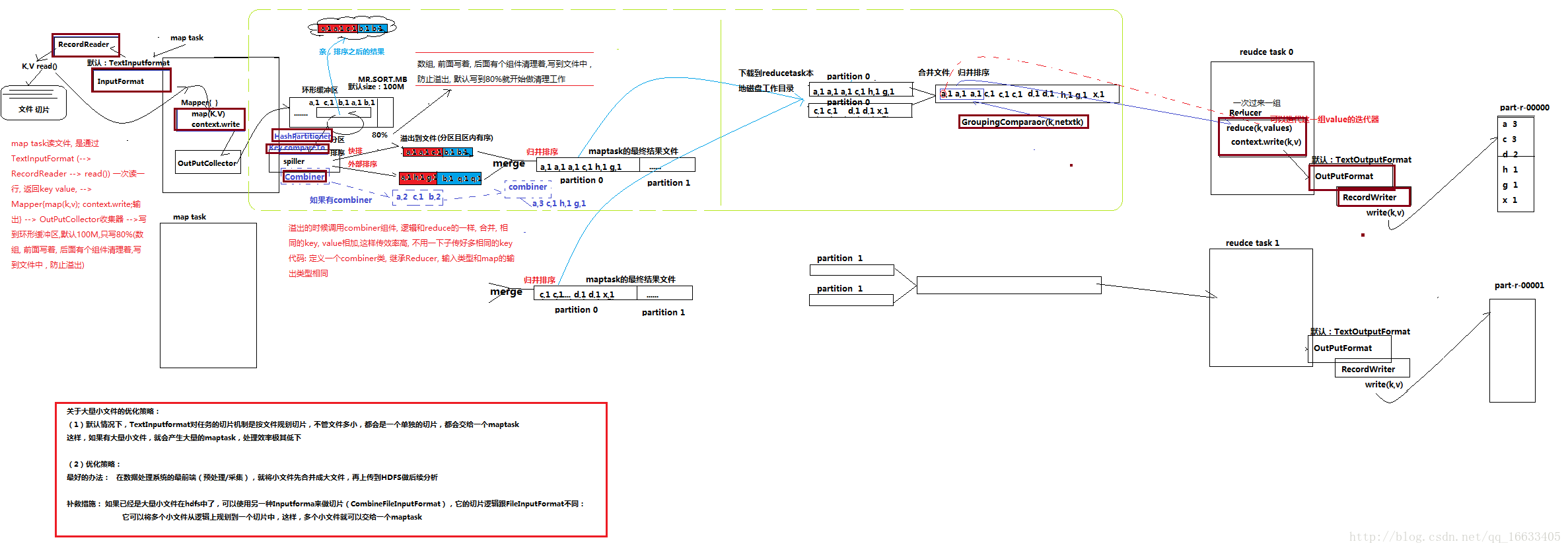
如上圖所示是MR的運行詳細過程
- 首先mapTask讀文件是通過InputFormat(內部是調RecordReader()–>read())來一次讀一行,返回K,V值。(默認是TextInputFormat,還可以輸入其他的類型如:音視頻,圖片等。)。
- mapper(map(k,v))–>context.write()即mapTask階段。
- 輸出數據到OutputCollector收集器(不會輸出一組就傳到下一步進行處理,而是需要一個收集的過程,減少IO)
- 將收集到的數據寫到環形緩沖區–>通過Spiller來將溢出的數據溢出到文件中去(在這里會通過hashPartitioner執行分區、通過key.comPareTo來實現排序(分為系統默認的快排和外部排序)即實現了shuffle的核心機制:分區和排序)。
- 將多個溢出文件進行Merge(采用歸并排序),合并成一個大文件。
- 將文件下載到ReduceTask的本地磁盤工作目錄–>將多個MapTask的輸出結果再進行歸并排序(也可以說是ReduceTask去各個mapTask對應的分區去取對應的數據)。
- Reducer(reduce(k,v))–>context.write(k,v)–>
OutputFormat(RecordWriter.write(k,v))即reduceTask階段。 - 將數據寫到part-r-00000這里
如上圖所示,圖中用紅色粗線描述的組件都是可以重寫的。
mapreduce在編程的時候,基本上一個固化的模式,沒有太多可靈活改變的地方,除了以下幾處:
1、輸入數據接口:InputFormat —> FileInputFormat(文件類型數據讀取的通用抽象類) DBInputFormat (數據庫數據讀取的通用抽象類)
默認使用的實現類是 :TextInputFormat。
job.setInputFormatClass(TextInputFormat.class)
TextInputFormat的功能邏輯是:一次讀一行文本,然后將該行的起始偏移量作為key,行內容作為value返回
2、邏輯處理接口: Mapper
完全需要用戶自己去實現其中 map() setup() clean()
3、map輸出的結果在shuffle階段會被partition以及sort,此處有兩個接口可自定義:
Partitioner
有默認實現 HashPartitioner,邏輯是 根據key和numReduces來返回一個分區號; key.hashCode()&Integer.MAXVALUE % numReduces
通常情況下,用默認的這個HashPartitioner就可以,如果業務上有特別的需求,可以自定義Comparable
當我們用自定義的對象作為key來輸出時,就必須要實現WritableComparable接口,override其中的compareTo()方法
4、reduce端的數據分組比較接口 : Groupingcomparator
reduceTask拿到輸入數據(一個partition的所有數據)后,首先需要對數據進行分組,其分組的默認原則是key相同,然后對每一組kv數據調用一次reduce()方法,并且將這一組kv中的第一個kv的key作為參數傳給reduce的key,將這一組數據的value的迭代器傳給reduce()的values參數
5、邏輯處理接口:Reducer
完全需要用戶自己去實現其中 reduce() setup() clean()
6、輸出數據接口: OutputFormat —> 有一系列子類 FileOutputformat DBoutputFormat …..
默認實現類是TextOutputFormat,功能邏輯是: 將每一個KV對向目標文本文件中輸出為一行
整個過程需要注意以下幾點:
- 環形緩存區(數據從outputCollector中傳入環形緩存區,直到達到80%的緩存時,緩存才會啟用清理機制,將已經溢出的數據溢出到文件中去(通過spiller來將數據溢出到文件中去))會溢出多次,每次溢出都會對數據進行分區排序,形成多個分區排序后的數據,最終進行合并。
- combiner的作用:對spiller階段的溢出數據進行一個reduce處理,直接讓相同k的value值相加,減少數據量以及傳輸過程中的開銷,大大提高效率。(根據業務需求使用,并不是每個業務都要用。可自定義一個Combiner類,內部邏輯和Reduce類似)
shuffle:洗牌、發牌——(核心機制:數據分區,排序,緩存)
具體來說:就是將maptask輸出的處理結果數據,分發給reducetask,并在分發的過程中,對數據按key進行了分區和排序;數據傾斜:指的是任務在shuffle階段時會進行一個分區操作(默認的是hashcode取模),如果有大部分數據被分到一個ReduceTask端進行處理,一小部分任務被分到其他的ReduceTask端進行處理,就會造成其他ReduceTask處理完成后,仍有一個ReduceTask還在處理數據。最終造成整個工程延遲的情況。(為了解決這個問題,引入了Partition)
總結:
MapReduce中最核心的知識點就是MR運行的整體流程;除此之外要達到博主菜鳥級別的水平,你還需要了解以下幾個知識點:
1、MapReduce是什么,用來干什么的(無論學什么首先都得知道這一點)。
2、MapReduce框架的設計思想。
3、MapReduce框架中的程序實體角色以及對應的作用:maptask reducetask mrappmaster。
(1和2詳見:https://blog.csdn.net/qq_16633405/article/details/78404018)
4、MapReduce程序中maptask任務切片規劃的機制。
(詳見:https://blog.csdn.net/qq_16633405/article/details/79729172)
5、Yarn在MapReduce中作用。
(詳見:https://blog.csdn.net/qq_16633405/article/details/79734021)
6、掌握MapReduce的編程套路,通過不斷的寫MR案例領悟編寫MR程序的核心思想(即如何確定對應K-V值)。
(后續會將對應的MR的一些特殊套路案例上傳到Git上)
目前想到的就這么點,后續有遺漏的話會接著補充。









)


)






