本節書摘來自華章出版社《計算機科學概論》一書中的第3章,第3.3節文本表示法,作者[美]內爾·黛爾(Nell Dale)約翰·路易斯(John Lewis),更多章節內容可以訪問云棲社區“華章計算機”公眾號查看。
3.3 文本表示法
一個文本文檔可以被分解為段落、句子、詞和最終的單個字符。要用數字形式表示文本文檔,只需要表示每個可能出現的字符。文檔是連續(模擬)的實體,獨立的字符則是離散的元素,它們才是我們要表示并存儲在計算機內存中的。
現在,我們應該區分文本表示法的基本想法和文字處理的概念。當用Microsoft Word這樣的字處理程序創建文檔時,可以設置各種格式,包括字體、頁邊距、制表位、顏色等。 許多字處理程序還允許在文檔中加入自選圖形、公式和其他元素。這些額外信息與文本存儲在一起,以便文檔能夠正確地顯示和打印出來。但核心問題是如何表示字符本身,因此,目前我們把重點放在表示字符的方法上。
要表示的字符數是有限的。一種表示字符的普通方法是列出所有字符,然后賦予每個字符一個二進制字符串。例如,要存儲一個特定的字母,我們將保存它對應的位串。
那么需要表示哪些字符呢?在英語中,有26個字母,但必須有區別地處理大寫字母和小寫字母,所以實際上有52個字母。與數字(0、1到9)一樣,各種標點符號也需要表示。即使是空格,也需要有自己的表示法。那么對于非英語的語言又如何呢?一旦你考慮到這一點,那么我們想表示的字符數就會迅速增長。記住,我們在本章的前面討論過,要表示的狀態數決定了需要多少位來表示一種狀態。
字符集只是字符和表示它們的代碼的清單。這些年來,出現了多種字符集,但只有少數的幾種處于主導地位。在計算機制造商就關于使用哪種字符集達成一致后,文本數據的處理變得容易多了。在接下來的小節中,我們將介紹兩種字符集,即ASCII字符集和Unicode字符集。
字符集(character set):字符和表示它們的代碼的清單。
3.3.1 ASCII字符集
ASCII是美國信息交換標準代碼(American Standard Code for Information Interchange)的縮寫。最初,ASCII字符集用7位表示每個字符,可以表示128個不同的字符。每個字節中的第八位最初被用作校驗位,協助確保數據傳輸正確。之后,ASCII字符集進化了,用8位表示每個字符。這個8位版本的正式名字是Latin-1擴展ASCII字符集。該擴展字符集可以表示256個字符,包括一些重點字符和幾個補充的特殊符號。圖3-5展示了完整的ASCII字符集。
**字符集迷宮
1960年,一篇關于ACM通信的文章報道了字符集使用的調查,描述了60個不同的字符集。僅僅IBM公司的電腦生產線中,就存在9個內容和順序都不同的字符集。**[1]

這個圖表中的代碼是用十進制數表示的,但計算機存儲這些代碼時,將把它們轉換成相應的二進制數。注意,每個ASCII字符都有自己的順序,這是由存儲它們所用的代碼決定的。每個字符都有一個相對于其他字符的位置(在其他字符之前或之后)。這個屬性在許多方面都很有用。例如,可以利用字符代碼對一組單詞按照字母順序排序。
這個圖表中的前32個ASCII字符沒有簡單的字符表示法,不能輸出到屏幕上。這些字符是為特殊用途保留的,如回車符和制表符,處理數據的程序會用特定的方式解釋它們。
3.3.2 Unicode字符集
ASCII字符集的擴展版本提供了256個字符,雖然足夠表示英語,但是卻無法滿足國際需要。這種局限性導致了Unicode字符集的出現,這種字符集具有更強大的國際影響。
Unicode的創建者的目標是表示世界上使用的所有語言中的所有字符,包括亞洲的表意符號。此外,它還表示了許多補充的專用字符,如科學符號。
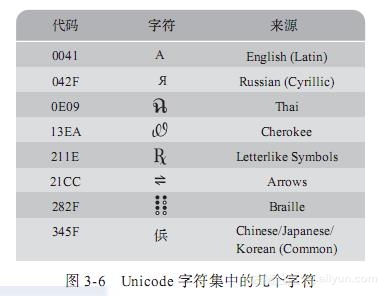
現在,Unicode字符集被許多程序設計語言和計算機系統采用。一般情況下,每個字符的編碼都為16位,但也是十分靈活的,如果需要的話每個字符可以使用更多空間,以便表示額外的字符。Unicode字符集的一個方便之處就是它把ASCII字符集作為了一個子集。圖3-6展示了Unicode字符集中非ASCII部分的幾個字符。
為了保持一致,Unicode字符集被設計為ASCII的超集。也就是說,Unicode字符集中的前256個字符與擴展ASCII字符集中的完全一樣,表示這些字符的代碼也一樣。因此,即使底層系統采用的是Unicode字符集,采用ASCII值的程序也不會受到
影響。
3.3.3 文本壓縮
字母信息(文本)是一種基本數據類型。因此,找到存儲這種信息以及有效地在兩臺計算機之間傳遞它們的方法是很重要的。下面的小節將分析三種文本壓縮類型:
- 關鍵字編碼
- 行程長度編碼
- 赫夫曼編碼
在本章后面的小節中我們還會談到,這些文本壓縮方法的基本思想也適用于其他類型的數據。
關鍵字編碼
想想你在英語中使用“the”“and”“which”“that”和“what”的頻率。如果這些單詞占用更少的空間(即用更少的字符表示),文檔就會減小。即使每個單詞節省的空間都很少,但因它們在典型的文檔中太常用,所以節省出的總空間還是很可觀的。
一種相當直接的文本壓縮方法是關鍵字編碼,它用單個字符代替了常用的單詞。要解壓這種文檔,需要采用壓縮的逆過程,即用相應的完整單詞替換單個字符。
關鍵字編碼(keyword encoding):用單個字符代替常用的單詞。
例如,假設我們用下列圖表對幾個單詞編碼:
單 詞 符 號 單 詞 符 號
as ^ must &
the ~ well %
and + these #
that $
讓我們對下列段落編碼:
The human body is composed of many independent systems, such as the circulatory system, the respiratory system, and the reproductive system. Not only must all systems work independently, but they must interact and cooperate as well. Overall health is a function of the well-being of separate systems, as well as how these separate systems work in concert.
編碼后的段落如下:
The human body is composed of many independent systems, such ^ ~ circulatory system, ~
respiratory system, + ~ reproductive system. Not only & each system work independently, but they & interact + cooperate ^ %. Overall health is a function of ~ %-being of separate systems, ^ % ^ how # separate systems work in concert.
原始段落總共有352個字符,包括空格和標點。編碼后的段落包括317個字符,節省了35個字符。這個例子的壓縮率是317/352,或約為0.9。
關鍵字編碼有幾點局限性。首先,用來對關鍵字編碼的字符不能出現在原始文本中。例如,如果原始段落中包括“$”,那么生成的編碼就會有歧義。我們不知道“$”表示的是單詞“that”還是真正的美元符號。這限制了能夠編碼的單詞數和要編碼的文本的特性。
**昂貴的一晚
如果你曾入住假日酒店、假日快捷酒店或者皇冠假日酒店并在2002年10月24日到10月26日之間結賬離開,那么你就很可能是被多收100倍價錢的26?000人中的一個,有些地方收費達到了每晚6500到21?000美元,小數點的刪除導致了信用卡處理的錯誤。**
此外,示例中的單詞“The”沒有被編碼為字符“~”,因為“The”與“the”不是同一個單詞。記住,在計算機上存儲的字母的大寫版本和小寫版本是不同的字符。如果想對“The”編碼,就必須使用另一個符號,或者采用更加復雜的替換模式。
最后,不要對“a”和“I”這樣的單詞編碼,因為那不過是用一個字符替換另一個字符。單詞越長,每個單詞的壓縮率就越高。遺憾的是,常用的單詞通常都比較短。另一方面,有些文檔使用某些單詞比使用其他單詞頻繁,這是由文檔的主題決定的。例如,在我們的示例中,如果對單詞“system”編碼,將節省很多空間,但在通常情況下,并不值得對它編碼。
關鍵字編碼的一種擴展是用特殊字符替換文本中的特定模式。被編碼的模式通常不是完整的單詞,而是單詞的一部分,如通用的前綴和后綴“ex”“ing”和“tion”。這種方法的一個優點是被編碼的模式通常比整個單詞出現的頻率更高,但缺點同前,即被編碼的通常是比較短的模式,對每個單詞來說,替換它們節省的空間比較少。
行程長度編碼
在某些情況下,一個字符可能在一個長序列中反復出現。在英語文本中,這種重復不常見,但在大的數據流(如DNA序列)中,這種情況則經常出現。一種名為行程長度編碼的文本壓縮技術利用了這種情況。行程長度編碼有時又稱為迭代編碼。
在行程長度編碼中,重復字符的序列將被替換為標志字符,后面加重復字符和說明字符重復次數的數字。例如,下面的字符串由7個A構成:
AAAAAAA
如果用*作為標志字符,這個字符串可以被編碼為:
*A7
行程長度編碼(run-length encoding):把一系列重復字符替換為它們重復出現的次數。
標志字符說明這三個字符的序列應該被解碼為相應的重復字符串,其他文本則按照常規處理。因此,下面的編碼字符串
n5x9ccch6 some other text k8eee
將被解碼為如下的原始文本:
nnnnnxxxxxxxxxccchhhhhh some other text kkkkkkkkeee
原始文本包括51個字符,編碼串包括35個字符,所以這個示例的壓縮率為35/51,或約為0.68。
注意,這個例子中有三個重復的c和三個重復的e都沒有編碼。因為需要用三個字符對這樣的重復序列編碼,所以對長度為2或3的字符串進行編碼是不值得的。事實上,如果對長度為2的重復字符串編碼,反而會使結果串更長。
因為我們用一個字符記錄重復的次數,所以看來不能對重復次數大于9的序列編碼。但是,在某些字符集中,一個字符是由多個位表示的。例如,字符“5”在ASCII字符集中表示為53,這是一個八位的二進制字符串00110101。因此,我們將次數字符解釋為一個二進制數,而不是解釋為一個ASCII數字。這樣一來,能夠編碼的重復字符的重復次數可以是0到255的任何數,甚至可以是4到259的任何數,因為長度為2或3的序列不會被
編碼。
赫夫曼編碼
另一種文本壓縮技術是赫夫曼編碼,以它的創建者David Huffman博士的名字命名。文本中很少使用字母“X”,那么為什么要讓它占用的位數與常用空格字符一樣呢?赫夫曼編碼使用不同長度的位串表示每個字符,從而解決了這個問題。也就是說,一些字符由5位編碼表示,一些字符由6位編碼表示,還有一些字符由7位編碼表示,等等。這種方法與字符集的概念相反,在字符集中,每個字符都由定長(如8位或16位)的位串表示。
這種方法的基本思想是用較少的位表示經常出現的字符,而將較長的位串留給不經常出現的字符,這樣表示的文檔的整體大小將比較小。
赫夫曼編碼(Huffman encoding):用變長的二進制串表示字符,使常用的字符具有較短的編碼。
例如,假設用下列赫夫曼編碼來表示一些字符:
那么單詞DOORBELL的二進制編碼如下:
1011110110111101001100100
如果使用定長位串(如8位)表示每個字符,那么原始字符串的二進制形式應該是8個字符×8位= 64位。而這個字符串的赫夫曼編碼的長度是25位,從而壓縮率為25/64,或約為0.39。
那么解碼過程是怎樣的呢?在使用字符集時,只要把二進制串分割成8位或16位的片段,然后查看每個片段表示的字符即可。在赫夫曼編碼中,由于編碼是變長的,我們不知道每個字符對應多少位編碼,所以看似很難將一個字符串解碼。其實,創建編碼的方式已經消除了這種潛在的困惑。
赫夫曼編碼的一個重要特征是用于表示一個字符的位串不會是表示另一個字符的位串的前綴。因此,在從左到右掃描一個位串時,每當發現一個位串對應于一個字符,那么這個位串就一定表示這個字符,該位串不可能是更長位串的前綴。
例如,如果下列位串是用上面的表創建的:
1010110001111011
那么它只會被解碼為單詞BOARD,沒有其他的可能性。
那么,赫夫曼編碼是如何創建的呢?雖然創建赫夫曼編碼的詳細過程不屬于本書的介紹范圍,但是我們可以討論一下要點。由于赫夫曼編碼用最短的位串表示最常用的字符,所以首先需要列出要編碼的字符的出現頻率。出現頻率可以是字符在某個特定文檔中出現的次數(如352個E、248個S等),也可以是字符在來自特定領域的示例文本中出現的次數。頻率表則列出了字母在一種特定語言(如英語)中出現的頻率。使用這些頻率,可以構建一種二進制代碼的結構。創建這種結構的方法確保了最常用的字符對應于最短的位串。













》——1.4 搭建自己的實驗環境)
![已解決]求問not 1 or 0 and 1 or 3 and 4 or 5 and 6 or 7 and 8 and 9為什么不等于0呢???](http://pic.xiahunao.cn/已解決]求問not 1 or 0 and 1 or 3 and 4 or 5 and 6 or 7 and 8 and 9為什么不等于0呢???)




