- 目錄
- 前言:
- 1、Storm編程模型
- 2、對應的的WordCount案例
- 總結:
目錄
前言:
對于Storm的編程模型有必要做一個詳細的介紹(配合WC案例來介紹)
1、Storm編程模型
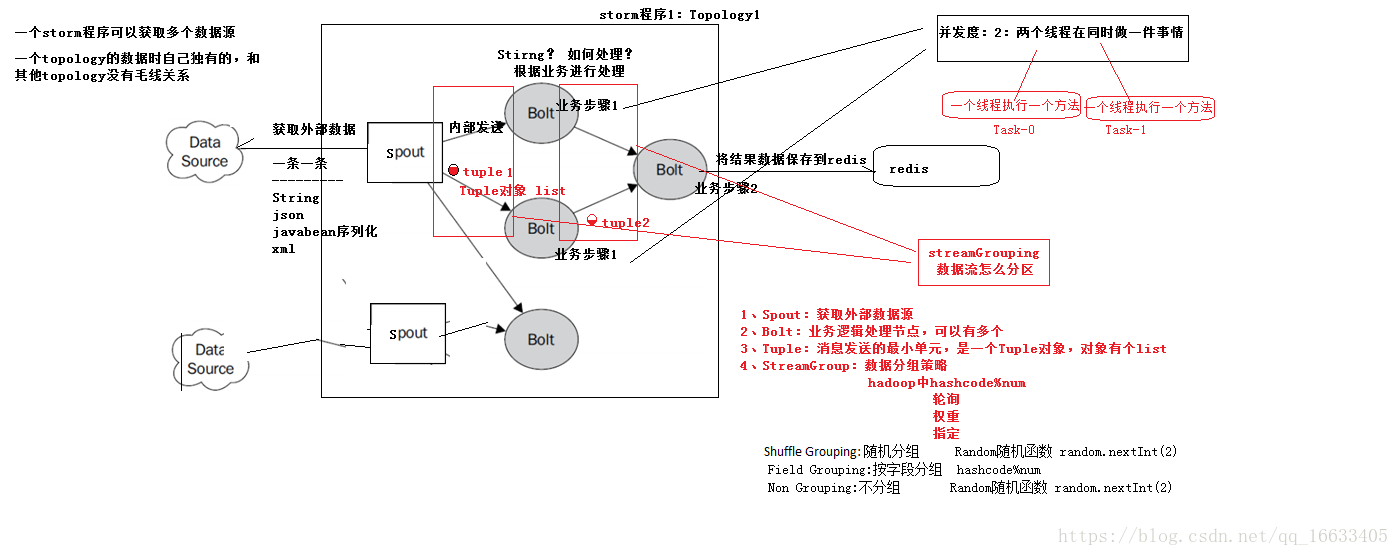
上圖中組件的解釋:
DataSource:外部數據源
Spout:接受外部數據源的組件,將外部數據源轉化成Storm內部的數據,以Tuple為基本的傳輸單元下發給Bolt
Bolt:接受Spout發送的數據,或上游的bolt的發送的數據。根據業務邏輯進行處理。發送給下一個Bolt或者是存儲到某種介質上。介質可以是Redis可以是mysql,或者其他。
Tuple:Storm內部中數據傳輸的基本單元,里面封裝了一個List對象,用來保存數據。
StreamGrouping:數據分組策略
7種:shuffleGrouping(Random函數),Non Grouping(Random函數),FieldGrouping(Hash取模)、Local or ShuffleGrouping 本地或隨機,優先本地。
- Shuffle Grouping: 隨機分組, 隨機派發stream里面的tuple,保證每個bolt接收到的tuple數目大致相同。
- FieldsGrouping:按字段分組,比如按userid來分組,具有同樣userid的tuple會被分到相同的Bolts里的一個task,而不同的userid則會被分配到不同的bolts里的task。
- All Grouping:廣播發送,對于每一個tuple,所有的bolts都會收到。
- Global Grouping:全局分組,這個tuple被分配到storm中的一個bolt的其中一個task。再具體一點就是分配給id值最低的那個task。
- Non Grouping:不分組,這stream grouping個分組的意思是說stream不關心到底誰會收到它的tuple。目前這種分組和Shuffle
grouping是一樣的效果, 有一點不同的是storm會把這個bolt放到這個bolt的訂閱者同一個線程里面去執行。 - Direct Grouping: 直接分組,這是一種比較特別的分組方法,用這種分組意味著消息的發送者指定由消息接收者的哪個task處理這個消息。只有被聲明為Direct Stream的消息流可以聲明這種分組方法。而且這種消息tuple必須使用emitDirect方法來發射。消息處理者可以通過TopologyContext來獲取處理它的消息的task的id(OutputCollector.emit方法也會返回task的id)。
- Local or shuffle grouping:如果目標bolt有一個或者多個task在同一個工作進程中,tuple將會被隨機發生給這些tasks。否則,和普通的Shuffle Grouping行為一致。
FieldGrouping和shuffleGrouping 運行過程分析:
FieldsGroup:你會發現相同的數據被分到相同的線程中。
95 word:am
95 word:am
95 word:am
95 word:am
95 word:am
91 word:love
91 word:love
91 word:love
91 word:love
91 word:love
95 word:am
89 word:i
89 word:hanmeimei
89 word:i
89 word:hanmeimei
89 word:i
93 word:lilei
93 word:lilei
93 word:lilei
93 word:lilei-----------------------------------
shuffleGroup:你會發現相同的數據被分到不同的線程中(數字代表線程id)
95 word:hanmeimei
89 word:love
95 word:hanmeimei
89 word:am
95 word:am
89 word:love
89 word:love
89 word:hanmeimei
89 word:am
95 word:love
95 word:hanmeimei
89 word:i
95 word:am
95 word:i
95 word:hanmeimei
95 word:i
95 word:hanmeimei
89 word:am
95 word:love
89 word:love
95 word:love2、對應的的WordCount案例
2.1、功能說明
設計一個topology,來實現對文檔里面的單詞出現的頻率進行統計。
整個topology分為三個部分:
- RandomSentenceSpout:數據源,在已知的英文句子中,隨機發送一條句子出去。
- SplitSentenceBolt:負責將單行文本記錄(句子)切分成單詞
- WordCountBolt:負責對單詞的頻率進行累加
執行wc時,通過Spout來讀取數據,然后通過Bolt來切分數據(如map階段)再通過另一個Bolt和上一個Bolt相連來進一步做單詞的統計(通過hashmap來實現)
2.2、項目主要流程

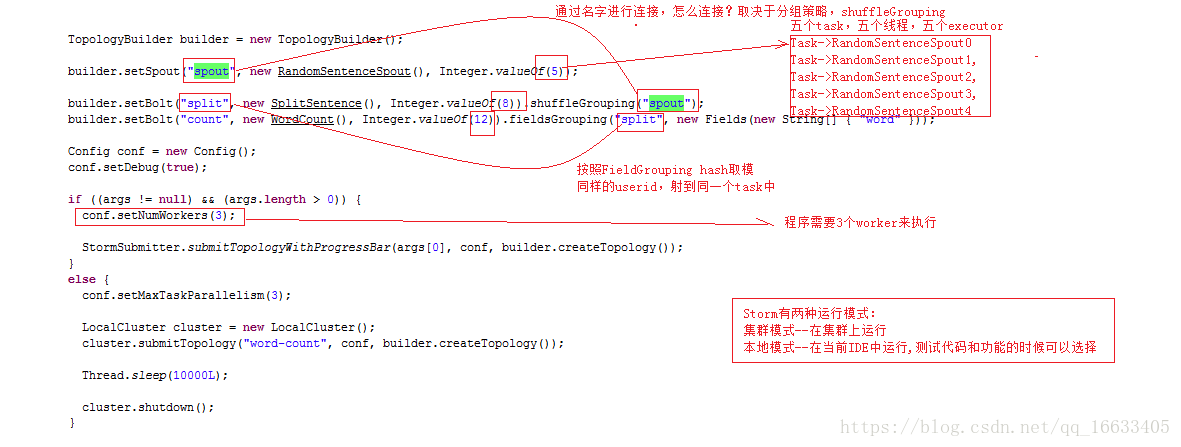
首先new TopologyBuilder->setSpout(spot的id,new spot的實現類,并發度)->setBolt(Bolt的id,new Bolt的實現類,并發度)<可設置多個Bolt>->new Config->config設置worker的數量。
2.3、RandomSentenceSpout的實現及生命周期
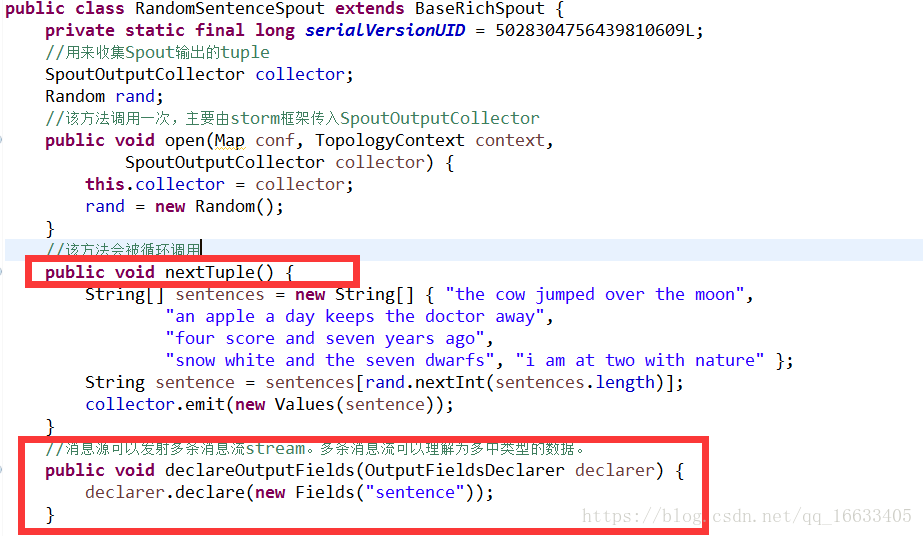
Spout的生命周期:open(初始化)->nextTuple(框架一直調用)->declareOutputFields(該方法用于聲明自己發射出去的數據的類型(自定義或者可以理解為標識自己發射出去的數據))
2.4、SplitSentenceBolt的實現及生命周期
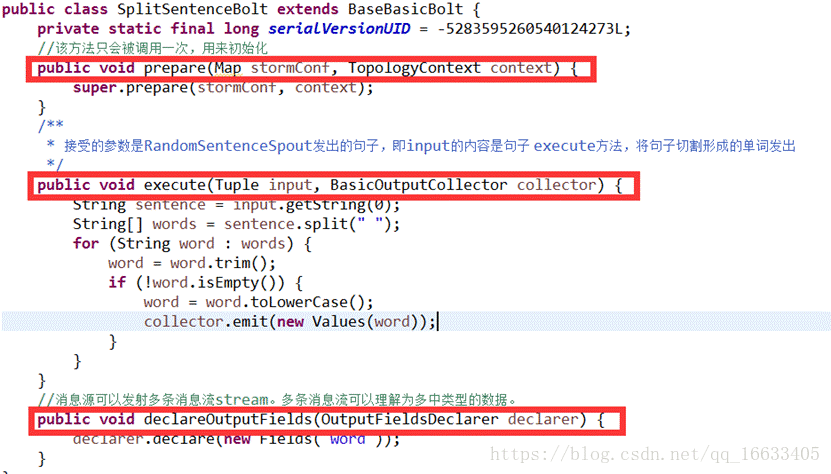
Bolt的生命周期:prepare(初始化)->execute(對傳過來的tuple進行處理)->declareOutoutFields(聲明輸出的數據類型若輸出數據類型為多個則聲明多個如下圖所示(自定義))
2.5、WordCountBolt的實現及生命周期
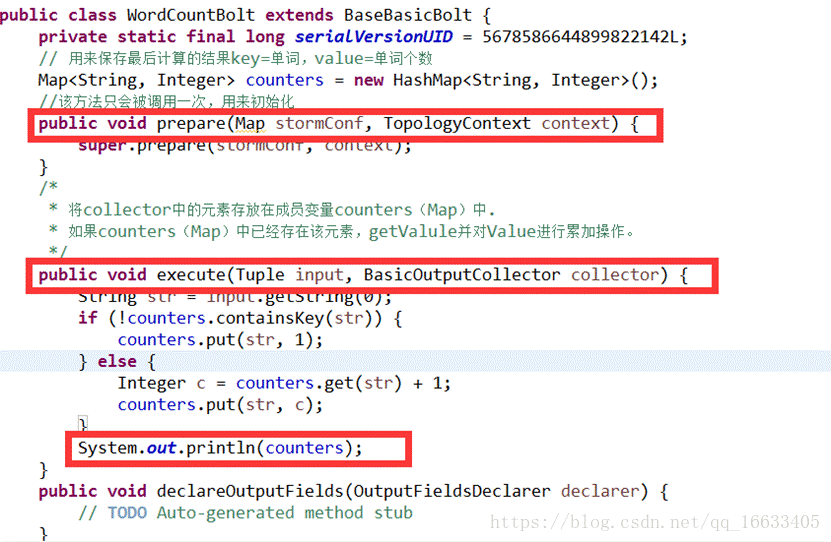
代碼執行圖:
總結:
這篇文章最主要的目的還是讓讀者能夠對Storm的編程模型有個初步的認識;至少你得能夠看懂簡單的WC案例,知道里面各個參數的含義,以及整個程序的執行流程。







》——1.4 搭建自己的實驗環境)
![已解決]求問not 1 or 0 and 1 or 3 and 4 or 5 and 6 or 7 and 8 and 9為什么不等于0呢???](http://pic.xiahunao.cn/已解決]求問not 1 or 0 and 1 or 3 and 4 or 5 and 6 or 7 and 8 and 9為什么不等于0呢???)










