文章目錄
- 前言
- 1、str
- 1.1、內置方法:
- 1.2、常用的內置方法
- 1.3、String模塊的一些方法
- 2、list
- 2.1、內置方法
- 2.2、常用內置方法
- 3、tupple
- 3.1、內置方法
- 3.2、常用內置方法
- 4、dict
- 4.1、內置方法
- 4.2、常用內置方法
- 5、其他
- 5.1、幾個sort的使用
- 5.2、enumerate():根據可迭代對象創建枚舉對象
- 5.3、filter
- 5.4、map() 會根據提供的函數對指定序列做映射。
- 5.5、reduce()
- 5.6、dir()
- 5.7、eval()
- 5.8、file()
- 5.9、isinstance()
- 5.10、round()
- 5.11、set()
- 5.12、zip()
- 5.13、Format()
前言
由于一些原因,好久沒更博客了,接下來會陸續總結出一些包含各方面的基礎知識的文章(如數據庫、Python、數據挖掘等),算是作為以后的“考前”(面試)回顧的資料吧。首先就寫下關于Python基礎的一些總結吧。
1、str
1.1、內置方法:

[‘capitalize’,‘casefold’,‘center’,‘count’,‘ncode’,‘endswith’,‘expandtabs’,‘find’,‘format’,‘format_map’,‘index’,‘isalnum’,‘isalpha’,‘isdecimal’,‘isdigit’‘isidentifier’,‘islower’,‘isnumeric’,‘isprintable’,‘isspace’,‘istitle’,‘isupper’,‘join’,‘ljust’,‘lower’,‘lstrip’,‘maketrans’,‘partition’,‘replace’,‘rfind’,‘rindex’,‘rjust’,‘rpartition’,‘rsplit’,‘rstrip’,‘split’,‘splitlines’,‘startswith’,‘strip’,‘swapcase’,‘title’,‘translate’,‘upper’,‘zfill’]
1.2、常用的內置方法
S.join(iterable)->str #將iterable拼接成(轉化為)字符串

“”.join(list)#將list轉化為字符串
S.replace(old,new[,count])->str #替換字符串中元素,返回一個新字符串。

S.split(sep,maxsplit)->list#將字符串分割為list

S.strip([chars])->str#剔除字符串中的特定字符

S.swapcase()->str#轉化字符串的大小寫字母

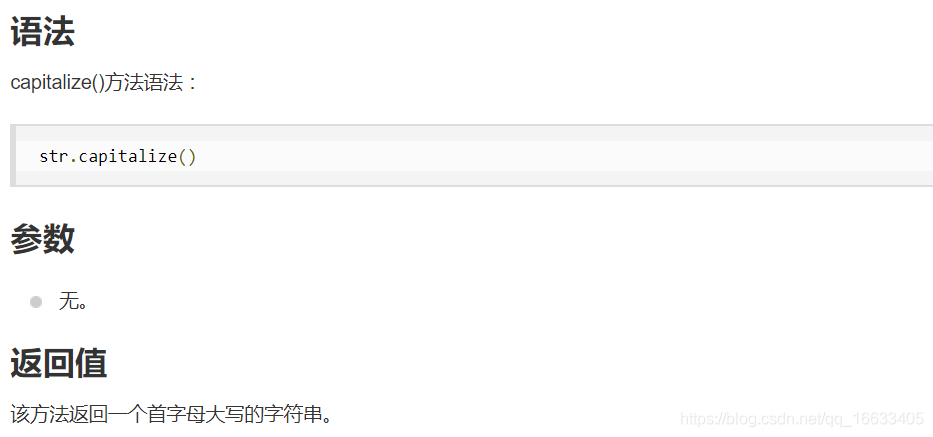
capitalize:Python capitalize()將字符串的第一個字母變成大寫,其他字母變小寫
S.islower()/isupper() #判斷字符是否是全為大/小寫
S.lower()/upper()#將字符串轉化為大寫或小寫

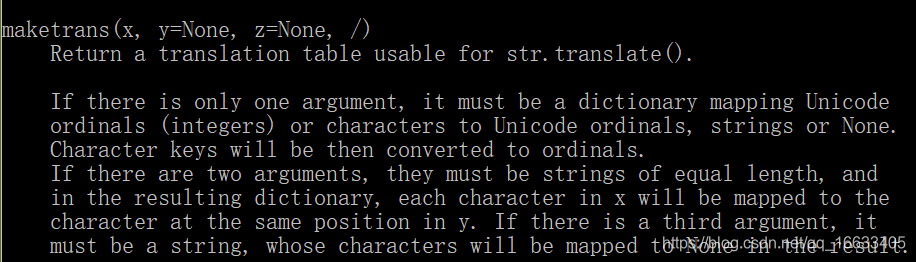
maketrans()->:返回一張翻譯表
#定義翻譯表,然后對相應的字符串一個字一個字的去映射。與replace的區別:replace不能對每個字符進行一一映射,而translate可以
translate(table)->str#傳入table進行映射處理

a="asdfsdafd123"
g = str.maketrans("abc","123")
print(a)
asdfsdafd123
print(a.translate(g))
1sdfsd1fd123
S.count(sub[,start[,end]])->int #返回某個字符(串)出現的次數`

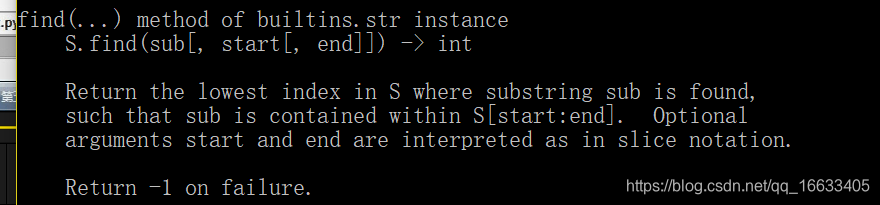
S.find(sub[,star,end]) -> int #返回索引值
S.index()#同find方法一樣,區別:若沒有該值的索引則拋出異常。
a="hello world"
a.find("word")#找到返回初始的索引值
a.find("wordl")#未找到返回-1
S.format(*args,**kwargs)->str #格式化輸出字符串

"my name is {0} and age is {1}".format("xiaoli",25)
"my name is {a}, i love {b}".format(a='pyer',b='apple')
S.isdigit()->bool #判斷字符是否是數字

str.strip([chars])
參數
chars – 移除字符串頭尾指定的字符序列。
返回值
返回移除字符串頭尾指定的字符生成的新字符串。
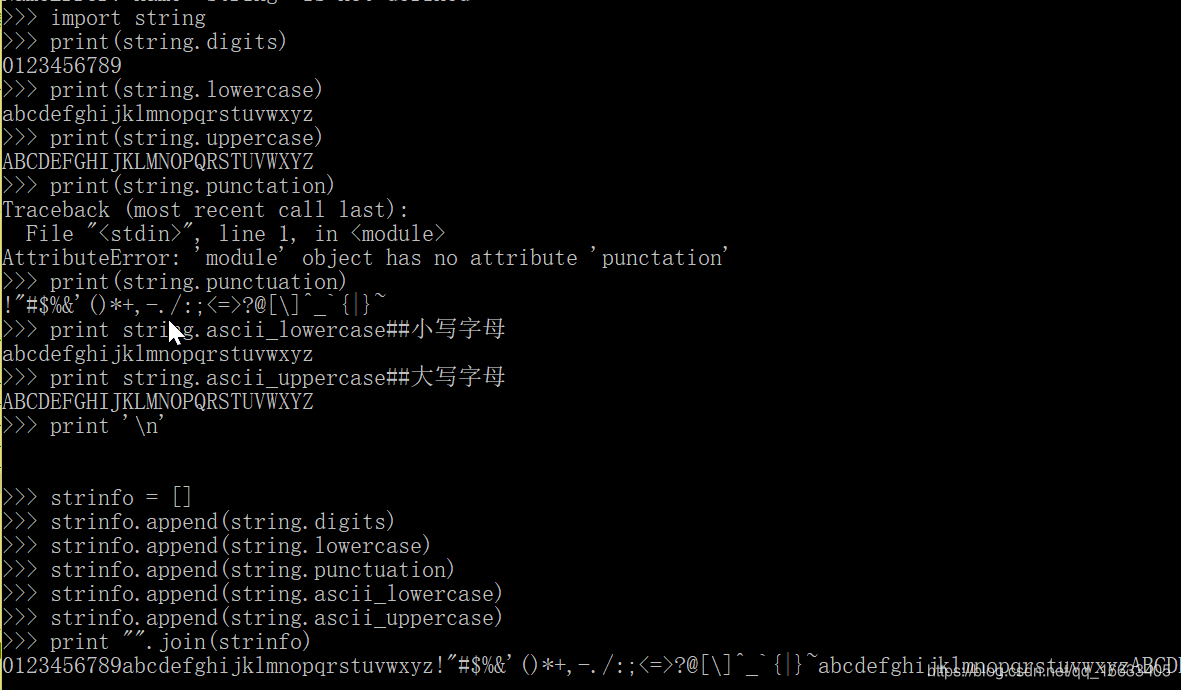
1.3、String模塊的一些方法
2、list
2.1、內置方法

2.2、常用內置方法
[‘append’,‘clear’,‘copy’,‘count’,‘extend’,‘index’,‘insert’,‘pop’,‘remove’,‘reverse’,‘sort’]
L.append()->None #添加元素到list末尾

L.insert(index,object)#在對應的index添加元素

L.clear()->None #清空list所有元素

L.pop([index])-|>item#剔除index的元素并返回

L.remove(value)->None#剔除list中的包含的第一項的value。


L.extend(iterable)->None #添加迭代器來擴展list

L.reverse()#反轉list
L.count(value)->int #查找list中某value出現的次數

L.sort(key)->None #只需要傳入對應的key即可,原理就是拿key中的每個元素執行sort方法

a.sort(key=lambda x :x[],reverse=True)
L.copy()->list #生成一個新的list,存儲地址不同
3、tupple
3.1、內置方法

3.2、常用內置方法
count()
index()
4、dict
4.1、內置方法

4.2、常用內置方法
[‘clear’, ‘copy’, ‘fromkeys’
, ‘get’, ‘items’, ‘keys’, ‘pop’, ‘popitem’, ‘setdefault’, ‘update’, ‘values’]
fromkeys(iterable,value=None)#通過傳入iterable生成新的dict。


D.get(k[,d])->D[k]#傳入k得到對應的value

D.items()->set #返回dict的子項item

D.update()#傳入dict進行更新


5、其他
5.1、幾個sort的使用
sorted #傳入對應的迭代器和key即可比較

字典如何去排序#sorted(dict.items(),key=lambdax:x[1])#dict.item()返回值為tuple,所以才能利用sored排序!
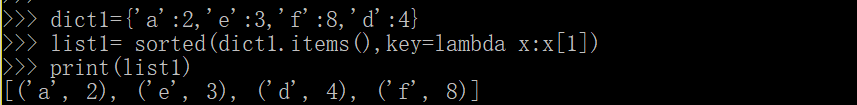
a.sort(key=lambda x :x[],reverse=True)#key最好用#聲明按字典中key或者value進行排序

多級排序咋個辦#使用sort方法中operator

sorted() 函數對所有可迭代的對象進行排序操作。
sort 與 sorted 區別:
1、sort 是應用在 list 上的方法,sorted 可以對所有可迭代的對象進行排序操作。
2、list 的 sort 方法返回的是對已經存在的列表進行操作,無返回值,而內建函數 sorted 方法返回的是一個新的 list,而不是在原來的基礎上進行的操作。
語法
sorted 語法:
sorted(iterable[, cmp[, key[, reverse]]])
參數說明:
iterable – 可迭代對象。
cmp – 比較的函數,這個具有兩個參數,參數的值都是從可迭代對象中取出,此函數必須遵守的規則為,大于則返回1,小于則返回-1,等于則返回0。
key – 主要是用來進行比較的元素,只有一個參數,具體的函數的參數就是取自于可迭代對象中,指定可迭代對象中的一個元素來進行排序。
reverse – 排序規則,reverse = True 降序 , reverse = False 升序(默認)。
返回值
返回重新排序的列表。
>>>a = [5,7,6,3,4,1,2]
>>> b = sorted(a) # 保留原列表
>>> a
[5, 7, 6, 3, 4, 1, 2]
>>> b
[1, 2, 3, 4, 5, 6, 7]>>> L=[('b',2),('a',1),('c',3),('d',4)]
>>> sorted(L, cmp=lambda x,y:cmp(x[1],y[1])) # 利用cmp函數
[('a', 1), ('b', 2), ('c', 3), ('d', 4)]
>>> sorted(L, key=lambda x:x[1]) # 利用key
[('a', 1), ('b', 2), ('c', 3), ('d', 4)]>>> students = [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
>>> sorted(students, key=lambda s: s[2]) # 按年齡排序
[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]>>> sorted(students, key=lambda s: s[2], reverse=True) # 按降序
[('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
>>>
5.2、enumerate():根據可迭代對象創建枚舉對象
enumerate() 函數用于將一個可遍歷的數據對象(如列表、元組或字符串)組合為一個索引序列,同時列出數據和數據下標,一般用在 for 循環當中。
語法
以下是 enumerate() 方法的語法:
enumerate(sequence, [start=0])
參數
sequence – 一個序列、迭代器或其他支持迭代對象。
start – 下標起始位置。
返回值
返回 enumerate(枚舉) 對象。
>>>seasons = ['Spring', 'Summer', 'Fall', 'Winter']
>>> list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
>>> list(enumerate(seasons, start=1)) # 下標從 1 開始
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
>>>seq = ['one', 'two', 'three']
>>> for i, element in enumerate(seq):
... print i, element
...
0 one
1 two
2 three
5.3、filter
filter() 函數用于過濾序列,過濾掉不符合條件的元素,返回由符合條件元素組成的新列表。
該接收兩個參數,第一個為函數,第二個為序列,序列的每個元素作為參數傳遞給函數進行判,然后返回 True 或 False,最后將返回 True 的元素放到新列表中。
語法
以下是 filter() 方法的語法:
filter(function, iterable)
參數
function – 判斷函數。
iterable – 可迭代對象。
返回值
返回列表。
實例
以下展示了使用 filter 函數的實例:
過濾出列表中的所有奇數:
#!/usr/bin/python
# -*- coding: UTF-8 -*-def is_odd(n):return n % 2 == 1newlist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
print(newlist)
輸出結果 :[1, 3, 5, 7, 9]
5.4、map() 會根據提供的函數對指定序列做映射。
第一個參數 function 以參數序列中的每一個元素調用 function 函數,返回包含每次 function 函數返回值的新列表。
map() 函數語法:
map(function, iterable, …)
參數
function – 函數
iterable – 一個或多個序列
返回值
Python 2.x 返回列表。
Python 3.x 返回迭代器
>>>def square(x) : # 計算平方數
... return x ** 2
...
>>> map(square, [1,2,3,4,5]) # 計算列表各個元素的平方
[1, 4, 9, 16, 25]
>>> map(lambda x: x ** 2, [1, 2, 3, 4, 5]) # 使用 lambda 匿名函數
[1, 4, 9, 16, 25]# 提供了兩個列表,對相同位置的列表數據進行相加
>>> map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10])
[3, 7, 11, 15, 19]
5.5、reduce()
函數會對參數序列中元素進行累積。
函數將一個數據集合(鏈表,元組等)中的所有數據進行下列操作:用傳給 reduce 中的函數 function(有兩個參數)先對集合中的第 1、2 個元素進行操作,得到的結果再與第三個數據用 function 函數運算,最后得到一個結果。
語法
reduce() 函數語法:
reduce(function, iterable[, initializer])
參數
function – 函數,有兩個參數
iterable – 可迭代對象
initializer – 可選,初始參數
返回值
返回函數計算結果。
實例
以下實例展示了 reduce() 的使用方法:
>>>def add(x, y) : # 兩數相加
... return x + y
...
>>> reduce(add, [1,2,3,4,5]) # 計算列表和:1+2+3+4+5
15
>>> reduce(lambda x, y: x+y, [1,2,3,4,5]) # 使用 lambda 匿名函數
15
5.6、dir()
dir() 函數不帶參數時,返回當前范圍內的變量、方法和定義的類型列表;帶參數時,返回參數的屬性、方法列表。如果參數包含方法__dir__(),該方法將被調用。如果參數不包含__dir__(),該方法將最大限度地收集參數信息。
dir 語法:
dir([object])
參數說明:
object – 對象、變量、類型。
返回值
返回模塊的屬性列表。
>>>dir() # 獲得當前模塊的屬性列表
['__builtins__', '__doc__', '__name__', '__package__', 'arr', 'myslice']
>>> dir([ ]) # 查看列表的方法
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__delslice__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getslice__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__setslice__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
5.7、eval()
用來執行一個字符串表達式,并返回表達式的值。
語法
以下是 eval() 方法的語法:
eval(expression[, globals[, locals]])
參數
expression – 表達式。
globals – 變量作用域,全局命名空間,如果被提供,則必須是一個字典對象。
locals – 變量作用域,局部命名空間,如果被提供,可以是任何映射對象。
返回值
返回表達式計算結果。
>>>x = 7
>>> eval( '3 * x' )
21
>>> eval('pow(2,2)')
4
>>> eval('2 + 2')
4
>>> n=81
>>> eval("n + 4")
85
5.8、file()
用于創建一個 file 對象,它有一個別名叫 open(),更形象一些,它們是內置函數。參數是以字符串的形式傳遞的。
語法
以下是 file() 方法的語法:
file(name[, mode[, buffering]])
參數
name – 文件名
mode – 打開模式
buffering – 0 表示不緩沖,如果為 1 表示進行行緩沖,大于 1 為緩沖區大小。
返回值
文件對象。
實例
測試文件 test.txt,內容如下:RUNOOB1
RUNOOB2
>>>f = file('test.txt')
>>> f.read()
'RUNOOB1\nRUNOOB2\n'
5.9、isinstance()
來判斷一個對象是否是一個已知的類型,類似 type()。
isinstance() 與 type() 區別:
type() 不會認為子類是一種父類類型,不考慮繼承關系。
isinstance() 會認為子類是一種父類類型,考慮繼承關系。
如果要判斷兩個類型是否相同推薦使用 isinstance()。
語法
以下是 isinstance() 方法的語法:
isinstance(object, classinfo)
參數
object – 實例對象。
classinfo – 可以是直接或間接類名、基本類型或者由它們組成的元組。
返回值
如果對象的類型與參數二的類型(classinfo)相同則返回 True,否則返回 False。。
實例
>>>a = 2
>>> isinstance (a,int)
True
>>> isinstance (a,str)
False
>>> isinstance (a,(str,int,list)) # 是元組中的一個返回 True
True
5.10、round()
方法返回浮點數x的四舍五入值。
語法
以下是 round() 方法的語法:
round( x [, n] )
參數
x – 數值表達式。
n – 數值表達式。
返回值
返回浮點數x的四舍五入值。
round(80.23456, 2) : 80.23
round(100.000056, 3) : 100.0
round(-100.000056, 3) : -100.0
5.11、set()
函數創建一個無序不重復元素集,可進行關系測試,刪除重復數據,還可以計算交集、差集、并集等。
語法
set 語法:
class set([iterable])
參數說明:
iterable – 可迭代對象對象;
返回值
返回新的集合對象。
>>>x = set('runoob')
>>> y = set('google')
>>> x, y
(set(['b', 'r', 'u', 'o', 'n']), set(['e', 'o', 'g', 'l'])) # 重復的被刪除
5.12、zip()
函數用于將可迭代的對象作為參數,將對象中對應的元素打包成一個個元組,然后返回由這些元組組成的列表。
如果各個迭代器的元素個數不一致,則返回列表長度與最短的對象相同,利用 * 號操作符,可以將元組解壓為列表。
zip 方法在 Python 2 和 Python 3 中的不同:在 Python 3.x 中為了減少內存,zip() 返回的是一個對象。如需展示列表,需手動 list() 轉換。
如果需要了解 Pyhton3 的應用,可以參考 Python3 zip()。
語法
zip 語法:
zip([iterable, …])
參數說明:
iterabl – 一個或多個迭代器;
返回值
返回元組列表。
實例
>>>a = [1,2,3]
>>> b = [4,5,6]
>>> c = [4,5,6,7,8]
>>> zipped = zip(a,b) # 打包為元組的列表
[(1, 4), (2, 5), (3, 6)]
>>> zip(a,c) # 元素個數與最短的列表一致
[(1, 4), (2, 5), (3, 6)]
>>> zip(*zipped) # 與 zip 相反,*zipped 可理解為解壓,返回二維矩陣式
[(1, 2, 3), (4, 5, 6)]
5.13、Format()
>>>"{} {}".format("hello", "world") # 不設置指定位置,按默認順序
'hello world'>>> "{0} {1}".format("hello", "world") # 設置指定位置
'hello world'>>> "{1} {0} {1}".format("hello", "world") # 設置指定位置
'world hello world'
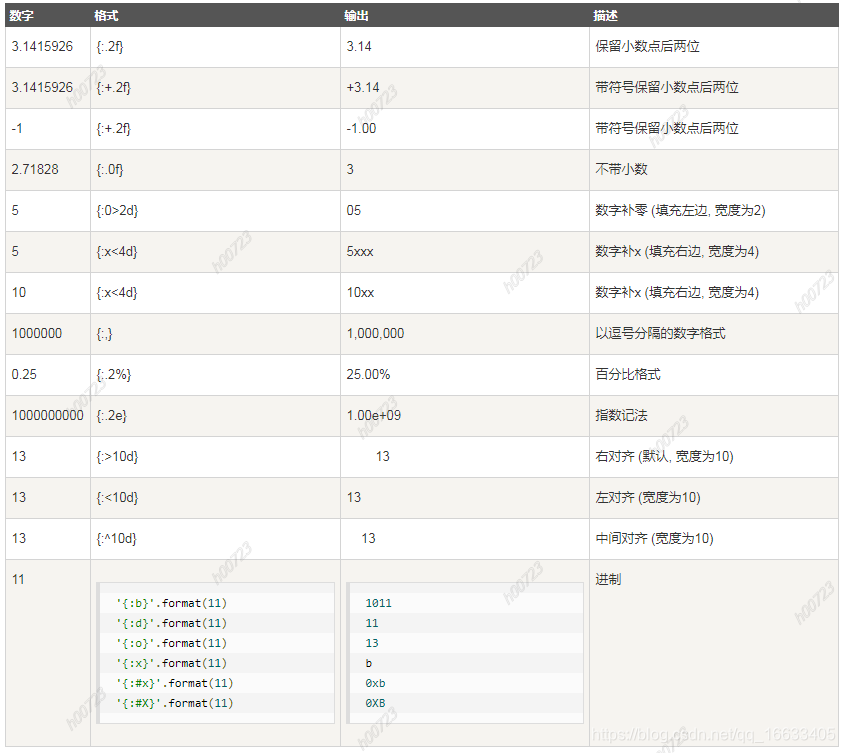
數字格式化
下表展示了 str.format() 格式化數字的多種方法:







 函數)





![BZOJ 3093: [Fdu校賽2012] A Famous Game](http://pic.xiahunao.cn/BZOJ 3093: [Fdu校賽2012] A Famous Game)


 (1406數據庫字段超出長度錯誤))


