前言
HBOS(Histogram-based Outlier Score)核心思想:將樣本按照特征分成多個區間,樣本數少的區間是異常值的概率大。
原理
該方法為每一個樣本進行異常評分,評分越高越可能是異常點。評分模型為:
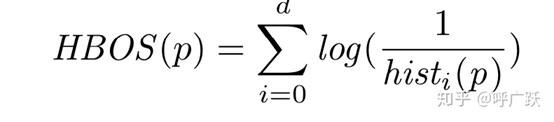
假設樣本p第 i 個特征的概率密度為Pi ,則p的概率密度可以計算為(多個特征的概率密度的乘積):

兩邊取對數:

概率密度越大,異常評分越小,則兩邊乘以“-1”:

即:

如何計算概率密度,特別是對于連續型數據?最簡單的方法是對連續數據進行離散化。離散化的基本思想是設置“斷點”,將數據分割成若干個區間。其中,“斷點”的設置可以是靜態的,也可以是動態的。
對于樣本集D,設置合適的“斷點”集合,將特征的取值分割成若干個區間。統計區間的樣本數,可以構建一個頻數直方圖H。假設第 i 個特征分割成m 個區間,每個區間統計的樣本個數分別為:

頻率(概率)分布表

明顯,根據頻數直方圖H可以計算出所有特征的頻率分布。
為什么頻率越大,異常評分越小?
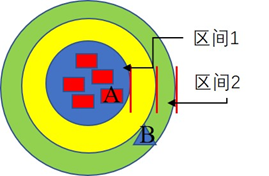
上圖是特征c的樣本分布例圖。直觀上,B樣本是異常點,A點是正常點。由于,樣本A(樣本B)關于特征c的概率密度估計可以用特征c在相應區間的頻率來近似。顯然,特征的取值頻率越大,樣本的關于該特征的異常評分越小。
優缺點
優點:
算法原理簡單,復雜度低。
缺點:
1、難以確定最佳的帶寬(即每個區間的長度)。
2、高維情形下的效果不佳。
3、特征相互獨立的條件比較強。
適用場景
適用于樣本維度低的大數據場景。
參數詳解
from pyod.models.hbos import HBOS
HBOS(n_bins=10, alpha=0.1, tol=0.5, contamination=0.1)n_bins:樣本劃分為多少個區間。默認10。contamination:污染度
總結
該算法針對大數據場景特別好用,但是異常識別的效果一般,且針對特征間比較獨立的場景。直白點講該算法就是把數據劃分為多個區間,然后根據每個區間的頻次根據概率密度函數轉化為對應的出現概率,在將這個概率轉化為異常分數,以此來區分異常數據。





 就是二分法)








)




