邏輯回歸本質是分類問題,而且是二分類問題,不屬于回歸,但是為什么又叫回歸呢。我們可以這樣理解,邏輯回歸就是用回歸的辦法來做分類。它是在線性回歸的基礎上,通過Sigmoid函數進行了非線性轉換,從而具有更強的擬合能力
sigmoid 函數
https://blog.csdn.net/fenglepeng/article/details/104829873
Logistic回歸分類器
為了實現Logistic回歸分類器,我們可以在每個特征上都乘以一個回歸系數,然后把所有的結果值相加,將這個總和代入Sigmoid函數中,進而得到一個范圍在0~1之間的數值。任何大于0.5的數據被分入1類,小于0.5即被歸入0類。所以,Logistic回歸也可以被看成是一種概率估計。
所以說,Logistic回歸分類器可以看成線性回歸與sigmoid的混合函數,是一個二分類的模型(這里是取的0和1,有的算法是+1和-1)
在用于分類時,實際上是找一個閾值,大于閾值的屬于1類別,小于的屬于0類別。(閾值是可根據具體情況進行相應變動的)
Logistic回歸及似然函數
我們假設
把兩個式子結合起來
運用極大似然估計得到似然函數
累乘不好求,我們可以求其對數似然函數。最值的問題,求導(第三行到第四行使用了sigmoid函數求導)
求解,使用批量梯度下降法BGD
或者隨機梯度下降法SGD
可以發現邏輯回歸與線性回歸梯度下降求解的形式類似,唯一的區別在于假設函數hθ(x)不同,線性回歸假設函數為θTx,邏輯回歸假設函數為Sigmoid函數。
線性回歸模型服從正態分布,邏輯回歸模型服從二項分布(Bernoulli分布),因此邏輯回歸不能應用最小二乘法作為目標/損失函數,所以用梯度下降法。
極大似然估計與Logistic回歸損失函數
我們要讓對數似然函數最大,也就是他的相反數 最小。而
最小化,則可以看成損失函數,求其最小化:
似然函數:
logistic函數
帶入得
這個結果就是交叉熵損失函數。
總結
就一句話:通過以上過程,會發現邏輯回歸的求解,跟線性回歸的求解基本相同。
多分類問題(Multi-class classification)
????????對于分類多于2個的問題, 可以將其看做二分類問題,即以其中一個分類作為一類,剩下的其他分類作為另一類,多分類問題的假設函數為?
one-vs-all/rest 問題解決方法:
- 訓練一個邏輯回歸分類器,預測 i 類別 y=i 的概率;
- 對一個新的輸入值x,為了作出類別預測,分別在k個分類器運行輸入值,選擇h最大的類別?
Softmax回歸模型??
Softmax回歸是logistic回歸的一般化模型,適用于k(k>2)分類的問題,第k類的參數為向量,組成的二維矩陣為
(k為類別數,n為特征數,即為每一個類別構建一個
,用到的是ova思想)。
參考鏈接:機器學習之單標簽多分類及多標簽多分類
Softmax函數的本質就是將一個k維的任意實數向量映射成為另一個k維的實數向量,其中向量中的每個元素的取值都介于(0,1)之間。
Softmax回歸的概率函數為:
注釋:?計算的是,他屬于第k類的回歸值,
計算的是他屬于每個類別的累加,用e的指數是為了加大 大的類別的影響

Softmax回歸的似然估計
似然函數:
對數似然函數:
?
?推導和Logistic回歸類似,只是將分類的個數從2擴展到k的情形。Softmax算法的損失函數:
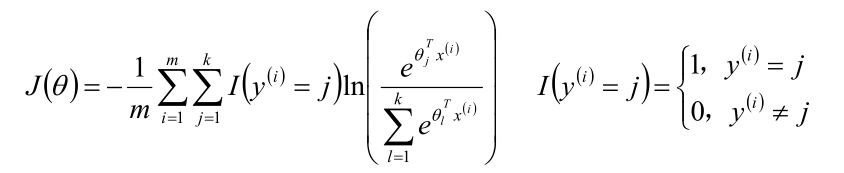
梯度下降法

總結
- 線性回歸模型一般用于回歸問題,邏輯回歸和Softmax回歸模型一般用于分類問題;
- 求θ的主要方式是梯度下降算法,該算法是參數優化的重要手段,主要使用SGD或MBGD;
- 邏輯回歸/Softmax回歸模型是實際問題中解決分類問題的最重要的方法;
- 廣義線性模型對樣本的要求不必一定要服從正態分布,只要服從指數分布簇(二項分布、Poisson分布、Bernoulli分布、指數分布等)即可;廣義線性模型的自變量可以是連續的也可以是離散的。
?






![Console-算法[for]-國王與老人的六十四格](http://pic.xiahunao.cn/Console-算法[for]-國王與老人的六十四格)



)






多種解決方案匯總)
)
)