what's the 數據結構
數據結構是指相互之間存在著一種或多種關系的數據元素的集合和該集合中數據元素之間的關系組成。 簡單來說,數據結構就是設計數據以何種方式組織并存儲在計算機中。 比如:列表、集合與字典等都是一種數據結構。?
通常情況下,精心選擇的數據結構可以帶來更高的運行或者存儲效率。數據結構往往同高效的檢索算法和索引技術有關。
數據結構按照其邏輯結構可分為線性結構、樹結構、圖結構:
- 線性結構:數據結構中的元素存在一對一的相互關系
- 樹結構:數據結構中的元素存在一對多的相互關系
- 圖結構:數據結構中的元素存在多對多的相互關系
棧
棧(Stack)是一個數據集合,它是一種運算受限的線性表。其限制是僅允許在表的一端進行插入和刪除運算。這一端被稱為棧頂,相對地,把另一端稱為棧底。可以將棧理解為只能在一端進行插入或刪除操作的列表。
棧的特點:后進先出、先進后出(類似于往箱子里放東西,要拿的時候只能拿最上面的,而最上面的是最后進的)
棧操作:進棧push、出棧pop、取棧頂gettop
在Python中,不用自定義棧,直接用列表就行。進棧函數:append;出棧函數:pop;查看棧頂函數:li[-1];
棧的應用
括號匹配問題:給一個字符串,其中包含小括號、中括號、大括號,求該字符串中的括號是否匹配。
基本思路:按順序遍歷字符串是左括號則進棧,來的是右括號則將棧頂左括號pop,若來的右括號與棧頂左括號不匹配或空棧情況下來了右括號則返回錯誤信息
def brace_match(s):stack = []d = {'(':')', '[':']', '{':'}'}for ch in s:if ch in {'(', '[', '{'}:stack.append(ch)elif len(stack) == 0:print('多了右括號%s' % ch)return Falseelif d[stack[-1]] == ch:stack.pop()else:print('括號%s處不匹配' % ch)return Falseif len(stack) == 0:return Trueelse:print("剩余左括號未匹配")return Falseprint(brace_match('[]{{}[]{()})}'))用兩個棧實現隊列
class QueueStack(object):def __init__(self):self.l1 = []self.l2 = []def push(self,a):self.l1.append(a)def pop(self):if not self.l2:for i in range(len(self.l1)):a = self.l1.pop()self.l2.append(a)if self.l2:return self.l2.pop()else:return False隊列
隊列(Queue)是一個數據集合,僅允許在列表的一端進行插入,另一端進行刪除。
進行插入的一端稱為隊尾(rear),插入動作稱為進隊或入隊;
進行刪除的一端稱為隊頭(front),刪除動作稱為出隊。
和棧一樣,隊列是一種操作受限制的線性表。
隊列的性質:先進先出(可以將隊列理解為排隊買東西)
特殊情況——雙向隊列:隊列的兩端都允許進行進隊和出隊操作。
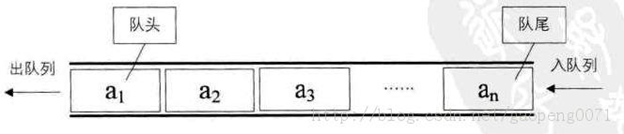
如何用列表實現隊列:
- 初步設想:列表+兩個下標指針
- 創建一個列表和兩個變量,front變量指向隊首,rear變量指向隊尾。初始時,front和rear都為0。
- 進隊操作:元素寫到li[rear]的位置,rear自增1。
- 出隊操作:返回li[front]的元素,front自減1。
以上就是隊列實現的基本思路,但是隊列出隊之后,前面的空間被浪費了,所以實際情況中隊列的實現原理是一個環形隊列
環形隊列:當隊尾指針front == Maxsize + 1時,再前進一個位置就自動到0。
- 實現方式:求余數運算
- 隊首指針前進1:front = (front + 1) % MaxSize
- 隊尾指針前進1:rear = (rear + 1) % MaxSize
- 隊空條件:rear == front
- 隊滿條件:(rear + 1) % MaxSize == front
?
在Python中,有一個內置模塊可以幫我們快速建立起一個隊列——deque模塊
使用方法:from collections import deque
創建隊列:queue = deque(li)
進隊:append()
出隊:popleft()
雙向隊列隊首進隊:appendleft()
雙向隊列隊尾進隊:pop()
棧和隊列的應用
求走出迷宮的路徑
用棧解決迷宮問題
基本思路:在一個迷宮節點(x,y)上,可以進行四個方向的探查:maze[x-1][y](表示上), maze[x+1][y](下), maze[x][y-1](左), maze[x][y+1](右)
思路:思路:從一個節點開始,任意找下一個能走的點,當找不到能走的點時,退回上一個點尋找是否有其他方向的點
方法:創建一個空棧,首先將入口位置進棧。當棧不空時循環:獲取棧頂元素,尋找下一個可走的相鄰方塊,如果找不到可走的相鄰方塊,說明當前位置是死胡同,進行回溯(就是講當前位置出棧,看前面的點是否還有別的出路)
maze = [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],[1, 0, 0, 0, 0, 1, 1, 0, 0, 1],[1, 0, 1, 1, 1, 0, 0, 0, 0, 1],[1, 0, 0, 0, 1, 0, 0, 0, 0, 1],[1, 0, 1, 0, 0, 0, 1, 0, 0, 1],[1, 0, 1, 1, 1, 0, 1, 1, 0, 1],[1, 1, 0, 0, 0, 0, 0, 0, 0, 1],[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
]dirs = [lambda x, y: (x - 1, y), # 上lambda x, y: (x, y + 1), # 右lambda x, y: (x + 1, y), # 下lambda x, y: (x, y - 1), # 左
]def stack_solve_maze(x1, y1, x2, y2):""":param x1: 起點x坐標:param y1: 起點y坐標:param x2: 終點x坐標:param y2: 終點y坐標:return:"""stack = []stack.append((x1,y1)) # 起點maze[x1][y1] = 2 # 2表示已經走過的點,我們要將已經走過的點進行標識,免得走重復的路while len(stack) > 0: # 當棧不空循環cur_node = stack[-1] # 棧頂,即目前所在位置if cur_node == (x2,y2): # 到達終點for p in stack:print('==>',p,end='') # 依次輸出棧內坐標return True# 沒到終點時,在任意位置都要試探上下左右是否走得通for dir in dirs:next_node = dir(*cur_node)if maze[next_node[0]][next_node[1]] == 0: # 0是通道,說明找到一個能走的方向stack.append(next_node)maze[next_node[0]][next_node[1]] = 2 # 2表示已經走過的點breakelse: # 如果一個方向也找不到,說明到死胡同了stack.pop()else:print("無路可走")return Falsestack_solve_maze(1,1,8,8)
# ==> (1, 1)==> (1, 2)==> (2, 2)==> (3, 2)==> (3, 1)==> (4, 1)==> (5, 1)==> (5, 2)==> (5, 3)==> (6, 3)==> (6, 4)==>(6, 5)==> (5, 5)==> (4, 5)==> (4, 6)==> (4, 7)==> (3, 7)==> (3, 8)==> (4, 8)==> (5, 8)==> (6, 8)==> (7, 8)==> (8, 8)用隊列解決迷宮問題
思路:從一個節點開始,尋找所有下面能繼續走的點。繼續尋找,直到找到出口。
方法:創建一個空隊列,將起點位置進隊。在隊列不為空時循環:出隊一次。如果當前位置為出口,則結束算法;否則找出當前方塊的4個相鄰方塊中可走的方塊,全部進隊。
?
from collections import dequemaze = [[1,1,1,1,1,1,1,1,1,1],[1,0,0,1,0,0,0,1,0,1],[1,0,0,1,0,0,0,1,0,1],[1,0,0,0,0,1,1,0,0,1],[1,0,1,1,1,0,0,0,0,1],[1,0,0,0,1,0,0,0,0,1],[1,0,1,0,0,0,1,0,0,1],[1,0,1,1,1,0,1,1,0,1],[1,1,0,0,0,0,0,0,0,1],[1,1,1,1,1,1,1,1,1,1]
]dirs = [lambda x,y:(x-1,y), #上lambda x,y:(x,y+1), #右lambda x,y:(x+1,y), #下lambda x,y:(x,y-1), #左
]def deque_solve_maze(x1,y1,x2,y2):queue = deque()# 創建隊列path = [] # 記錄出隊之后的節點queue.append((x1,y1,-1))maze[x1][y1] = 2 # 2表示應經走過的點while len(queue) > 0:cur_node = queue.popleft()path.append(cur_node)if cur_node[0] == x2 and cur_node[1] == y2: # 到終點real_path = []x,y,i = path[-1]real_path.append((x,y)) # 將終點坐標append到real_path中while i >= 0:node = path[i] # node是一個元祖(x坐標,y坐標,該點的leader)real_path.append(node[0:2]) # 只要坐標i = node[2]real_path.reverse() # 反轉后順序才為從起點到終點for p in real_path:print('==>',p,end='')return Truefor dir in dirs:next_node = dir(cur_node[0], cur_node[1])if maze[next_node[0]][next_node[1]] == 0:queue.append((next_node[0], next_node[1], len(path)-1))maze[next_node[0]][next_node[1]] = 2 # 標記為已經走過else:print("無路可走")return Falsedeque_solve_maze(1,1,8,8)
#==> (1, 1)==> (2, 1)==> (3, 1)==> (4, 1)==> (5, 1)==> (5, 2)==> (5, 3)==> (6, 3)==> (6, 4)==> (6, 5)==> (7, 5)==> (8, 5)==> (8, 6)==> (8, 7)==> (8, 8)總結:
- 隊列解決迷宮問題找到的出路肯定是最短路徑,但是相對而言用隊列會比較占用內存
- 隊列對應的思想是廣度優先,棧對應的是深度優先
鏈表
鏈表是一種物理存儲單元上非連續、非順序的存儲結構,數據元素的邏輯順序是通過鏈表中的指針鏈接次序實現的。鏈表由一系列結點(鏈表中每一個元素稱為結點)組成,結點可以在運行時動態生成。
每個結點包括兩個部分:一個是存儲數據元素的數據域,另一個是存儲下一個結點地址的指針域。 相比于線性表順序結構,操作復雜。由于不必須按順序存儲,鏈表在插入的時候可以達到O(1)的復雜度,比另一種線性表順序表快得多,但是查找一個節點或者訪問特定編號的節點則需要O(n)的時間,而線性表和順序表相應的時間復雜度分別是O(logn)和O(1)。
使用鏈表結構可以克服數組鏈表需要預先知道數據大小的缺點,鏈表結構可以充分利用計算機內存空間,實現靈活的內存動態管理。但是鏈表失去了數組隨機讀取的優點,同時鏈表由于增加了結點的指針域,空間開銷比較大。鏈表最明顯的好處就是,常規數組排列關聯項目的方式可能不同于這些數據項目在記憶體或磁盤上順序,數據的存取往往要在不同的排列順序中轉換。鏈表允許插入和移除表上任意位置上的節點,但是不允許隨機存取。鏈表有很多種不同的類型:單向鏈表,雙向鏈表以及循環鏈表。鏈表可以在多種編程語言中實現。像Lisp和Scheme這樣的語言的內建數據類型中就包含了鏈表的存取和操作。程序語言或面向對象語言,如C,C++和Java依靠易變工具來生成鏈表。
鏈表中每一個元素都是一個對象,每個對象稱為一個節點,包含有數據域key和指向下一個節點的指針next。通過各個節點之間的相互連接,最終串聯成一個鏈表。
# 結點的定義,單向
class Node(object):def __init__(self, item):self.item = itemself.next = None建立鏈表的方式有頭插法和尾插法兩種
- 頭插法:在一個結點的前面插入元素,head的指針由指向原來的結點變為指向新元素,新元素的指針指向原來的結點
- 尾插法:在一個元素后面插入一個元素,原來結點的指針指向新元素

建立列表實現代碼如下:
# a = Node(1) # 頭結點,是節點
# b = Node(2)
# c = Node(3)
# a.next = b
# b.next = c
# head = a# 帶空頭結點的鏈表
# head = Node() # 頭結點
# a = Node(1)
# b = Node(2)
# c = Node(3)
# head.next = a
# a.next = b
# b.next = c
# print(a.next.data)class Node:def __init__(self, data=None):self.data = dataself.next = Noneclass LinkList:def __init__(self, li, method='tail'):self.head = Noneself.tail = Noneif method == 'tail':self.create_linklist_tail(li)elif method == 'head':self.create_linklist_head(li)else:raise ValueError("Unsupport value %s" % method)def create_linklist_head(self, li):self.head = Node(0)for v in li:n = Node(v)n.next = self.head.nextself.head.next = nself.head.data += 1def create_linklist_tail(self, li):self.head = Node(0)self.tail = self.headfor v in li:p = Node(v)self.tail.next = pself.tail = pself.head.data += 1def traverse(self):p = self.head.nextwhile p:yield p.datap = p.nextdef __len__(self):return self.head.datall = LinkList([1,2,3,4,5], method='tail')
print(len(ll))鏈表結點的插入
鏈表插入結點的操作的重點是指針的變換,首先我們有兩個結點A指向B,這時要在AB中間插入C,我們需要將C的指針指向B,然后將A的指針指向C,在刪除AB之間的指針,就完成了C的插入,由AB變為了ACB
# curNode為A結點
c.next = curNode.next
curNode.next = c鏈表結點的刪除
在鏈表中,要刪除一個結點不能直接刪掉就萬事大吉,我們需要將指向該結點的結點的指針指向該結點指針指向的結點(A指向B指向C,B為要刪除的該結點,將A的指針指向C),然后才能刪除該節點(B)
?
# p為要刪除的結點
curNode.next = curNode.next.next # 即p.next
del p鏈表的特殊形態——雙鏈表
雙向鏈表也叫雙鏈表,是鏈表的一種,它的每個數據結點中都有兩個指針,分別指向直接后繼(后面結點)和直接前驅(前面結點)。所以,從雙向鏈表中的任意一個結點開始,都可以很方便地訪問它的前驅結點和后繼結點。一般我們都構造雙向循環鏈表。?
雙向鏈表的節點定義
class Node(object):def __init__(self, item=None):self.item = itemself.next = Noneself.prior = None
雙向鏈表結點的插入
與鏈表相同,雙向鏈表插入結點也需要將指針進行變換。同樣是AB之間要插入C,我們需要先將C的指針指向B、B的指針由指向A轉變為指向B,然后C的另一個指針指向A,A結點的指針由指向B轉變為指向B。
# p為新插入的元素
p.next = curNode.next
curNode.next.prior = p
p.prior = curNode
curNode.next = p雙向鏈表結點的刪除
刪除雙向鏈表的結點前需要建立起該結點前后兩個結點的指針關系,然后才能刪除結點
# p為要刪除的結點
p = curNode.next
curNode.next = p.next
p.next.prior = curNode
del p鏈表的復雜度分析
- 按元素值查找——O(n),因為沒有下標所以沒法做二分
- 按下標查找——O(n),因為沒有下標
- 在某元素后插入——O(1)
- 刪除某元素——O(1)
總結
- 鏈表在插入和刪除的操作上明顯快于順序表
- 鏈表的內存可以更靈活的分配。試利用鏈表重新實現棧和隊列
- 鏈表這種鏈式存儲的數據結構對樹和圖的結構有很大的啟發性
鏈表的題
檢查給定的鏈表是否包含循環,包含循環返回1,不包含循環則返回0。同時說明所實現的時間和空間復雜度是多少。
# 快慢指針法:一個指針每次移動一個單位,一個指針每次移動兩個單位,如果重合,說明有環
def find_loop(list):p1 = p2 = listwhile p2 and p2.pnext:p1 = p1.pnextp2 = p2.pnext.pnextif p1 == p2:return 1return 0
# 時間復雜度O(n), 空間復雜度O(1).
哈希表
哈希表的簡單概述
哈希表一個通過哈希函數來計算數據存儲位置的數據結構,通常支持如下操作 (高效的操作):python中的字典是通過哈希表實現的
- insert(key, value):插入鍵值對(key,value)
- get(key):如果存在鍵為key的鍵值對則返回其value,否則返回空值
- delete(key):刪除鍵為key的鍵值對
?直接尋址表
當關鍵字的 key 的全域U(關鍵字可能出現的范圍)比較小時,直接尋址是一種簡單而有效的方法
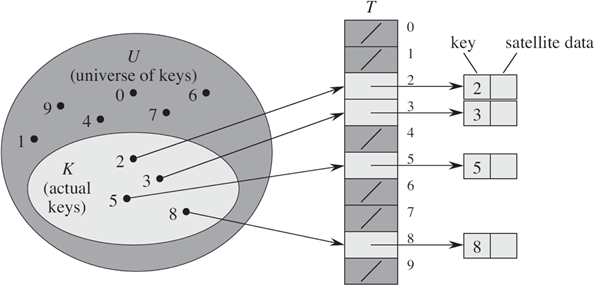
- 存儲:如上圖將數組的下標作為key,將數值存儲在對應的下表位置,key為k的元素放到k位置上
- 刪除:當要刪除某個元素時,將對應的下標的位置值置為空
直接尋址技術缺點:
- 當域U很大時,需要消耗大量內存,很不實際
- 如果域U很大而實際出現的key很少,則大量空間被浪費
- 無法處理關鍵字不是數字的情況,因為key可以是其他的數據類型
哈希與哈希表
改進直接尋址表:?哈希
- 構建大小為m的尋址表T
- key為k的元素放到h(k)位置上
- h(k)是一個函數,其將域U映射到表T[0,1,...,m-1]
哈希表
- 哈希表(Hash Table,又稱為散列表),是一種線性表的存儲結構。哈希表由一個直接尋址表和一個哈希函數組成。
- 哈希函數h(k)將元素關鍵字k作為自變量,返回元素的存儲下標。
簡單的hash函數
- 除法哈希:h(k) = k mod m
- 乘法哈希:h(k) = floor(m(kA mod 1)) 0<A<1
存儲機制
以除法哈希為例討論下存儲機制以及存在的問題
假設有一個長度為7的數組,哈希函數h(k)=k mod 7,元素集合{14,22,3,5}的存儲方式如下圖。
解釋:
- 存儲 : key對數組長度取余,余數作為數組的下標,將值存儲在此處
- 存在的問題 :比如:h(k)=k mod 7, h(0)=h(7)=h(14)=...?
哈希沖突
由于哈希表的大小是有限的,而要存儲的值的總數量是無限的,因此對于任何哈希函數,都會出現兩個不同元素映射到同一個位置上的情況,這種情況叫做哈希沖突。
比如上圖中的哈希表就存在這哈希沖突——h(k)=k%7, h(0)=h(7)=h(14)=...
解決哈希沖突方法
方法一:開放尋址法——如果哈希函數返回的位置已經有值,則可以向后探查新的位置來存儲這個值。
- 線性探查:如果位置i被占用,則探查i+1, i+2,……
- 二次探查:如果位置i被占用,則探查i+12,i-12,i+22,i-22,……
- 二度哈希:有n個哈希函數,當使用第1個哈希函數h1發生沖突時,則嘗試使用h2,h3,……
方法二:拉鏈法——哈希表每個位置都連接一個鏈表,當沖突發生時,沖突的元素將被加到該位置鏈表的最后。
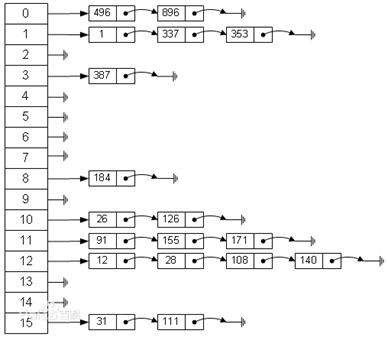
哈希表在Python中的應用
字典與集合都是通過哈希表來實現的
在Python中的字典:a = {'name': 'Damon', 'age': 18, 'gender': 'Man'}
使用哈希表存儲字典,通過哈希函數將字典的鍵映射為下標。假設h(‘name’) = 3, h(‘age’) = 1, h(‘gender’) = 4,則哈希表存儲為[None, 18, None, ’Damon’, ‘Man’]
在字典鍵值對數量不多的情況下,幾乎不會發生哈希沖突,此時查找一個元素的時間復雜度為O(1)。
二叉樹
樹
在了解二叉樹之前,首先我們得有樹的概念。
樹是一種數據結構又可稱為樹狀圖,如文檔的目錄、HTML的文檔樹都是樹結構,它是由n(n>=1)個有限節點組成一個具有層次關系的集合。把它叫做“樹”是因為它看起來像一棵倒掛的樹,也就是說它是根朝上,而葉朝下的。它具有以下的特點:
- 每個節點有零個或多個子節點;
- 沒有父節點的節點稱為根節點;
- 每一個非根節點有且只有一個父節點;
- 除了根節點外,每個子節點可以分為多個不相交的子樹;?
有關樹的一些相關術語:
節點的度:一個節點含有的子樹的個數稱為該節點的度;
葉節點或終端節點:度為0的節點稱為葉節點;
非終端節點或分支節點:度不為0的節點;
雙親節點或父節點:若一個節點含有子節點,則這個節點稱為其子節點的父節點;
孩子節點或子節點:一個節點含有的子樹的根節點稱為該節點的子節點;
兄弟節點:具有相同父節點的節點互稱為兄弟節點;
樹的度:一棵樹中,最大的節點的度稱為樹的度;
節點的層次:從根開始定義起,根為第1層,根的子節點為第2層,以此類推;
樹的高度或深度:樹中節點的最大層次;
堂兄弟節點:雙親在同一層的節點互為堂兄弟;
節點的祖先:從根到該節點所經分支上的所有節點;
森林:由m(m>=0)棵互不相交的樹的集合稱為森林;樹的種類有:無序樹、有序樹、二叉樹、霍夫曼樹。其中最重要應用最多的就是二叉樹,下面我們來學習有關二叉樹的知識。
二叉樹
二叉樹的定義為度不超過2的樹,即每個節點最多有兩個叉(兩個分支)。上面那個例圖其實就是一顆二叉樹。
二叉樹是每個節點最多有兩個子樹的樹結構。通常子樹被稱作“左子樹”(left subtree)和“右子樹”(right subtree)。二叉樹常被用于實現二叉查找樹和二叉堆。
二叉樹的每個結點至多只有二棵子樹(不存在度大于2的結點),二叉樹的子樹有左右之分,次序不能顛倒。二叉樹的第i層至多有個結點;深度為k的二叉樹至多有
個結點;對任何一棵二叉樹T,如果其終端結點數為
,度為2的結點數為
,則
。
一棵深度為k,且有個節點的二叉樹,稱為滿二叉樹。這種樹的特點是每一層上的節點數都是最大節點數。而在一棵二叉樹中,除最后一層外,若其余層都是滿的,并且最后一層或者是滿的,或者是在右邊缺少連續若干節點,則此二叉樹為完全二叉樹。具有n個節點的完全二叉樹的深度為log2n+1。深度為k的完全二叉樹,至少有
個節點,至多有
個節點。
二叉樹的存儲方式分為鏈式存儲和順序存儲(類似列表)兩種
二叉樹父節點下標i和左孩子節點的編號下標的關系為2i+1,和右孩子節點的編號下標的關系為2i+2
二叉樹有兩個特殊的形態:滿二叉樹和完全二叉樹
滿二叉樹:一個二叉樹,如果除了葉子節點外每一個層的結點數都達到最大值,則這個二叉樹就是滿二叉樹。
完全二叉樹:葉節點只能出現在最下層和次下層,并且最下面一層的結點都集中在該層最左邊的若干位置的二叉樹為完全二叉樹。即右邊的最下層和次下層可以適當缺一個右子數
完全二叉樹是效率很高的數據結構
二叉樹的鏈式存儲:將二叉樹的節點定義為一個對象,節點之間通過類似鏈表的鏈接方式來連接。
二叉樹結點的定義
class BiTreeNode:def __init__(self, data):self.data = dataself.lchild = Noneself.rchild = None
二叉樹的遍歷分為四種——前序遍歷、中序遍歷、后序遍歷和層級遍歷
前序+中序或者后序+中序 可以唯一確定一顆子樹(兩個節點除外)
設樹結構為:
- 前序遍歷:先打印根,再遞歸其左子樹,后遞歸其右子數 ? ?E ACBD GF
- 中序遍歷:以根為中心,先打印左子樹,然后打印根,然后打印右子樹(注意,每個子樹也有相應的根和子樹) ? A BCD E GF
- 后序遍歷:先遞歸左子樹,再遞歸右子樹,后打印根(注意,每個子樹也有相應的根和子樹BDC A FG E
- 層次遍歷:從根開始一層一層來,同一層的從左到右輸出E AG CF BD
四種遍歷方法的代碼實現:
# 結點的定義
class BiTreeNode:def __init__(self, data):self.data = dataself.lchild = Noneself.rchild = None
# 二叉樹結點
a = BiTreeNode('A')
b = BiTreeNode('B')
c = BiTreeNode('C')
d = BiTreeNode('D')
e = BiTreeNode('E')
f = BiTreeNode('F')
g = BiTreeNode('G')
# 結點之間的關系
e.lchild = a
e.rchild = g
a.rchild = c
c.lchild = b
c.rchild = d
g.rchild = froot = e# 前序遍歷:先打印根,再遞歸左孩子,后遞歸右孩子
def pre_order(root):if root:print(root.data, end='')pre_order(root.lchild)pre_order(root.rchild)# 中序遍歷:以根為中心,左邊打印左子樹,右邊打印右子樹(注意,每個子樹也有相應的根和子樹)
# (ACBD) E (GF)-->(A(CBD)) E (GF)-->(A (B C D)) E (G F)
def in_order(root):if root:in_order(root.lchild)print(root.data, end='')in_order(root.rchild)# 后序遍歷:先遞歸左子樹,再遞歸右子數,后打印根(注意,每個子樹也有相應的根和子樹)
# (ABCD)(GF)E-->((BCD)A)(GF)E-->(BDCA)(FG)E
def post_order(root):if root:post_order(root.lchild)post_order(root.rchild)print(root.data, end='')# 層次遍歷:一層一層來,同一層的從左到右輸出
def level_order(root):queue = deque()queue.append(root)while len(queue) > 0:node = queue.popleft()print(node.data,end='')if node.lchild:queue.append(node.lchild)if node.rchild:queue.append(node.rchild)pre_order(root)#EACBDGF
print("")
in_order(root)#ABCDEGF
print("")
post_order(root)#BDCAFGE
print("")
level_order(root)#EAGCFBD二叉搜索樹
二叉搜索樹(Binary Search Tree),它或者是一棵空樹,或者是具有下列性質的二叉樹: 若它的左子樹不空,則左子樹上所有結點的值均小于它的根結點的值; 若它的右子樹不空,則右子樹上所有結點的值均大于它的根結點的值; 它的左、右子樹也分別為二叉搜索樹。
二叉搜索樹的中序遍歷得到的是原來列表按升序排序的列表
由列表生成二叉搜索樹、通過二叉搜索樹查詢值
# 結點定義
class BiTreeNode:def __init__(self, data):self.data = dataself.lchild = Noneself.rchild = None
# 建立二叉搜索樹(循環列表,插入值)
class BST:def __init__(self, li=None):self.root = Noneif li:self.root = self.insert(self.root, li[0]) # 列表的第一個元素是根for val in li[1:]:self.insert(self.root, val)# 生成二叉搜索樹遞歸版本def insert(self, root, val):if root is None:root = BiTreeNode(val)elif val < root.data: # 插入的值小于root,要放到左子樹中(遞歸查詢插入的位置)root.lchild = self.insert(root.lchild, val)else: # 插入的值大于root,要放到右子樹中(遞歸查詢插入的位置)root.rchild = self.insert(root.rchild, val)return root# 生成二叉搜索樹不遞歸的版本def insert_no_rec(self, val):p = self.rootif not p:self.root = BiTreeNode(val)returnwhile True:if val < p.data:if p.lchild:p = p.lchildelse:p.lchild = BiTreeNode(val)breakelse:if p.rchild:p = p.rchildelse:p.rchild = BiTreeNode(val)break# 查詢遞歸版本def query(self, root, val):if not root:return Falseif root.data == val:return Trueelif root.data > val:return self.query(root.lchild, val)else:return self.query(root.rchild, val)# 查詢非遞歸版本def query_no_rec(self, val):p = self.rootwhile p:if p.data == val:return Trueelif p.data > val:p = p.lchildelse:p = p.rchildreturn False# 中序遍歷,得到的是升序的列表def in_order(self, root):if root:self.in_order(root.lchild)print(root.data, end=',')self.in_order(root.rchild)tree = BST()
for i in [1,5,9,8,7,6,4,3,2]:tree.insert_no_rec(i)
tree.in_order(tree.root)
#print(tree.query_no_rec(12))刪除操作
- 1. 如果要刪除的節點是葉子節點:直接刪除
- 2. 如果要刪除的節點只有一個孩子:將此節點的父親與孩子連接,然后刪除該節點。
- 3. 如果要刪除的節點有兩個孩子:將其右子樹的最小節點(該節點最多有一個右孩子)刪除,并替換當前節點。


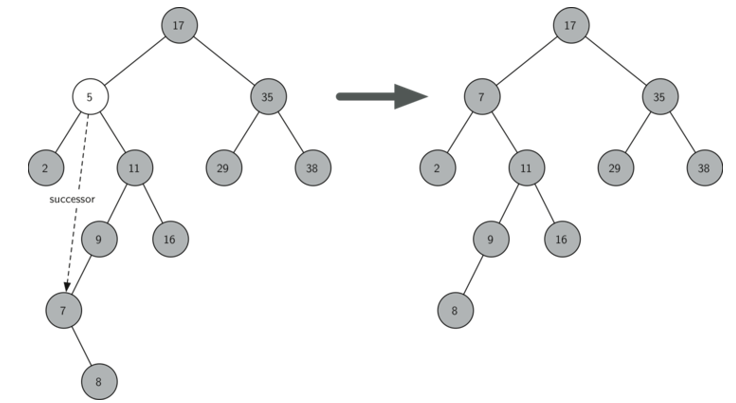
二叉搜索樹效率:
- 平均情況下,二叉搜索樹進行搜索的時間復雜度為O(nlogn)。
- 最壞情況下,二叉搜索樹可能非常偏斜。
- 解決方案:隨機化插入,AVL樹
二叉搜索樹的應用——AVL樹、B樹、B+樹
AVL樹
AVL樹:AVL樹是一棵自平衡的二叉搜索樹。
AVL樹具有以下性質: 根的左右子樹的高度之差的絕對值不能超過1,根的左右子樹都是平衡二叉樹

插入一個節點可能會破壞AVL樹的平衡,可以通過旋轉操作來進行修正。
插入一個節點后,只有從插入節點到根節點的路徑上的節點的平衡可能被改變。我們需要找出第一個破壞了平衡條件的節點,稱之為K。K的兩顆子樹的高度差2。
不平衡的出現可能有4種情況
1.不平衡是由于對K的右孩子的右子樹插入導致的:左旋
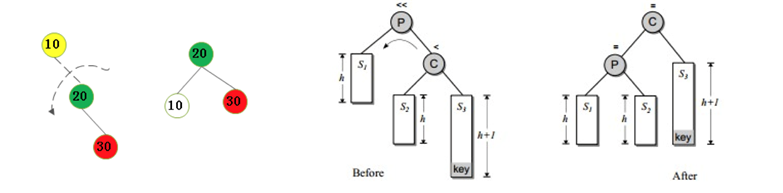
2.不平衡是由于對K的左孩子的左子樹插入導致的:右旋
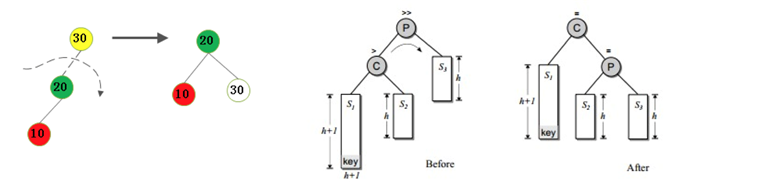
3.不平衡是由于對K的右孩子的左子樹插入導致的:右旋-左旋
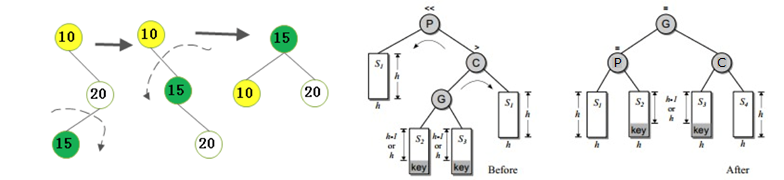
4.不平衡是由于對K的左孩子的右子樹插入導致的:左旋-右旋

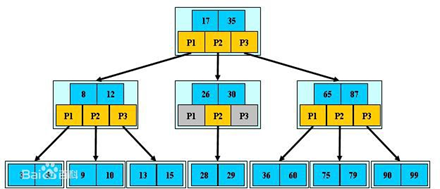
B樹
B樹是一棵自平衡的多路搜索樹。常用于數據庫的索引。
B+ 樹
B+ 樹是一種樹數據結構,是一個n叉排序樹,每個節點通常有多個孩子,一棵B+樹包含根節點、內部節點和葉子節點。根節點可能是一個葉子節點,也可能是一個包含兩個個或兩個以上孩子節點的節點。
B+ 樹通常用于數據庫和操作系統的文件系統中。NTFS, ReiserFS, NSS, XFS, JFS, ReFS 和BFS等文件系統都在使用B+樹作為元數據索引。B+ 樹的特點是能夠保持數據穩定有序,其插入與修改擁有較穩定的對數時間復雜度。B+ 樹元素自底向上插入。
B+樹是應文件系統所需而出的一種B樹的變型樹。B和B+樹的區別在于,B+樹的非葉子結點只包含導航信息,不包含實際的值,所有的葉子結點和相連的節點使用鏈表相連,便于區間查找和遍歷。
B+ 樹的優點在于:
由于B+樹在內部節點上不包含數據信息,因此在內存頁中能夠存放更多的key。 數據存放的更加緊密,具有更好的空間局部性。因此訪問葉子節點上關聯的數據也具有更好的緩存命中率。
B+樹的葉子結點都是相鏈的,因此對整棵樹的便利只需要一次線性遍歷葉子結點即可。而且由于數據順序排列并且相連,所以便于區間查找和搜索。而B樹則需要進行每一層的遞歸遍歷。相鄰的元素可能在內存中不相鄰,所以緩存命中性沒有B+樹好。
但是B樹也有優點,其優點在于,由于B樹的每一個節點都包含key和value,因此經常訪問的元素可能離根節點更近,因此訪問也更迅速。
通常在B+樹上有兩個頭指針,一個指向根結點,一個指向關鍵字最小的葉子結點。
https://www.cnblogs.com/zhuminghui/p/8414317.html
數據結構 - 哈希表 - 一路向北_聽風 - 博客園









 斷言(assert))


位運算)





和坐標軸下降法(CD))
