
今天給大家介紹一篇有關深度CTR模型增量訓練的文章,來自華為諾亞方舟實驗室。
1、背景
深度CTR模型需要大量的數據進行訓練,同時需要不斷的更新以適應最新的數據分布。如果模型沒有及時更新,則有可能帶來線上效果的衰減,如下圖,當模型5天沒有更新時,線上AUC會有0.66%的下降,這會帶來巨大的收入損失,同時對用戶體驗也會造成一定影響。
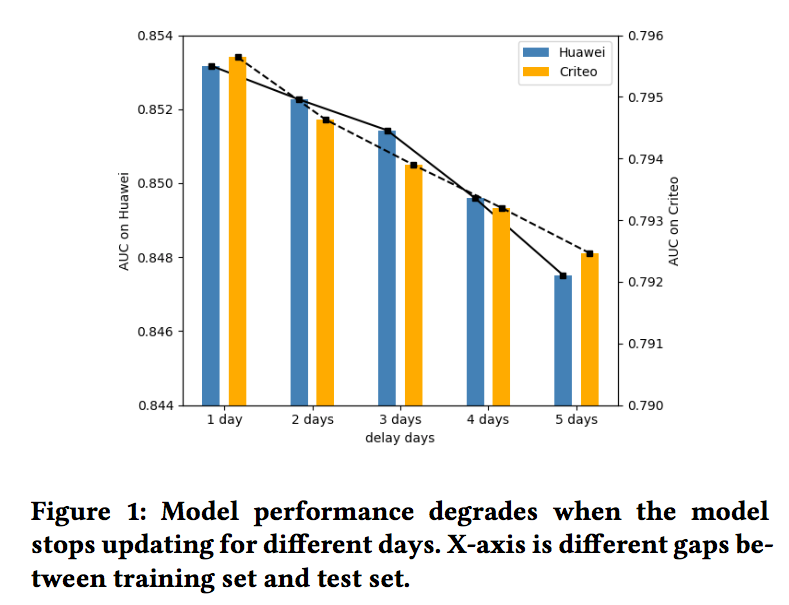
為了保證線上模型的有效性,通常需要對模型進行天級別/小時級別甚至是分鐘級別的更新。而本文將重點放在天級別更新上。
模型的天級別更新比較常用的方式是使用規定時間窗口的數據對模型進行重新訓練,如下圖,模型0使用第1天到第10天的數據進行訓練,模型1使用第2天到第11天的數據進行訓練,依次類推:
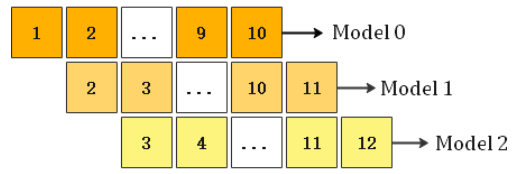
上述重新訓練模型的做法,其缺點是耗時比較高,更新可能不及時,因此可以考慮增量訓練的方式,如下圖,模型0同樣使用第1天到第10天的數據,模型1在模型0的基礎上,加入第11天的數據進行更新,依次類推:
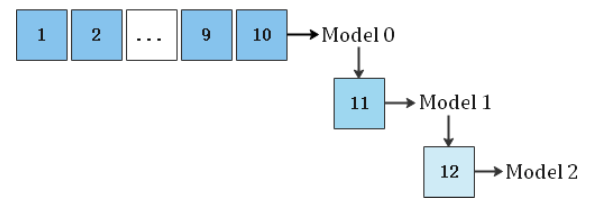
本文重點介紹華為如何對深度CTR模型進行增量訓練,我們在下一節中一起學習一下。
2、增量訓練框架介紹
華為增量訓練框架如下圖所示:
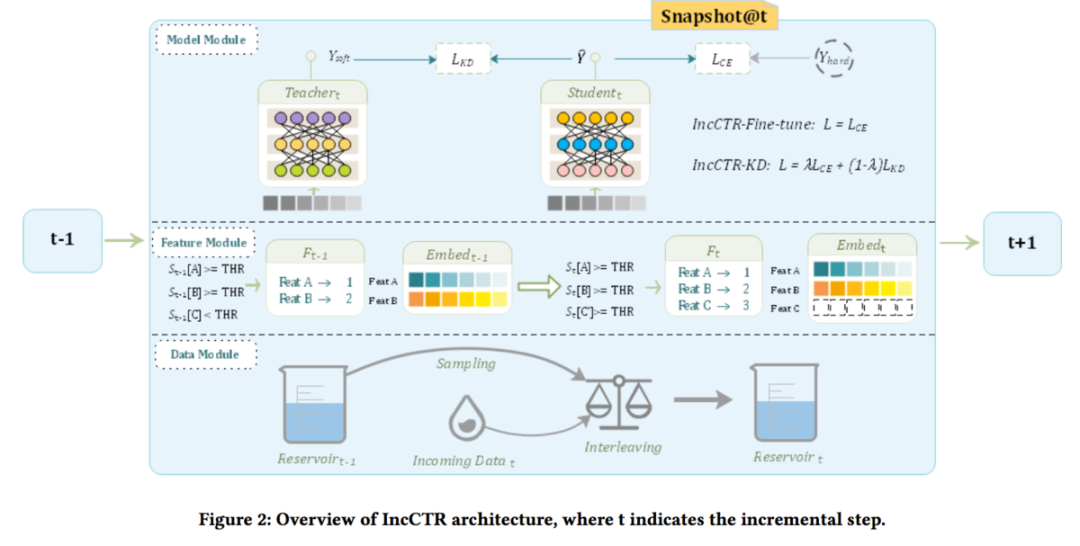
如上圖,該框架主要包含三個模塊:數據模塊、特征模塊、模型模塊,接下來對這三個模塊依次進行介紹。
2.1 數據模塊
數據模塊主要對數據進行存儲和混合。如上圖,在第t天更新模型時,從t-1天的數據池中選擇部分數據,同時混合第t天新的數據,作為第t天模型更新所使用的數據。論文中提到,應該選擇t-1天的數據池中哪部分的數據,這塊仍然處于研究中,期待后續的研究進展。
2.2 特征模塊
特征模塊主要對特征進行處理,這塊重點講解對于離散型特征的增量更新。
對于離散變量來說,許多取值出現的次數非常少,通常會設定一個出現次數的閾值,當該取值出現的次數高于閾值時,會計作一個單獨的類別,而出現次數低于閾值的所有取值,會被統一當作others類別處理。當得到所有的類別之后,會將每一個類別映射到一個特定的id,最后轉換成對應的embedding。
類別映射到id的方法有許多種,文中提到了自增映射(auto-increment)和哈希映射( hash-coding)。論文使用的是自增映射,這里也簡單介紹下哈希映射(論文沒有提及,個人經驗,歡迎各位糾錯)。對哈希映射來說,首先要確定一個總的哈希空間大小,如2^10,然后通過某種哈希方式(如murmur哈希),將對應的類別轉換為對應的hash值,作為該類別的id值。對哈希映射來說,通常設定的hash空間的會比實際的類別數量大很多,以盡可能避免沖突的出現。使用Hash這種方式的好處個人認為主要是新出現的特征類別,不需要改變embedding向量的個數,embedding向量的個數和hash空間的大小相同;但hash空間的大小往往比實際的類別數量,會導致導出的模型比較大,同時需要采用合適的hash算法,否則會導致沖突的出現,降低模型的準確度。
而本文使用的自增映射方式,當新類別出現或者Others類別中某種取值出現的次數超過閾值時,則需要進行特殊處理。如上圖所示,t-1天的模型,只有Feat A和Feat B出現次數超過了閾值,因此只需要將Feat A和Feat B轉換為對應的id,分別為1和2(上圖有點不太嚴謹了,應該還有Others類別,不過不影響理解)。此時訓練的模型,embedding的大小為2* K(k為每個embedding向量的長度)。當收集了第t天的數據后,Feat C出現次數也超過了閾值,因此采用自增的方式,將Feat C轉換為對應的自增id,即3。此時第t天的模型不能繼續使用第t-1天的模型進行繼續訓練,而必須重新進行embedding的初始化,大小為3 * K,其中前兩行使用t-1天模型訓練后的embedding值進行初始化,第三行則進行隨機初始化。
下面是對特征模塊處理過程的總結,其中Eexist表示t-1天模型中存在的id對應的embedding,Enew表示第t天模型新增的embedding:

2.3 模型模塊
對于模型的更新,這里介紹兩種方式,Fine-tune和Knowledge distillation。
2.3.1 Fine-tune
對于Fine-tune方式,除Embedding從t-1天模型進行warm-start外,其余的網絡參數也從t-1天模型進行拷貝。然后使用數據模塊混合后的訓練數據進行參數更新。這里還使用了一些小的trick來實現更好的效果,比如對于Eexist部分的embedding,使用較小的學習率,而對于Enew部分的embedding,則使用一個相對更大的學習率。模型使用交叉熵損失進行更新。
2.3.2 Knowledge distillation
為了增強模型從歷史數據中學到的知識,避免出現不同天的模型預測差距過大的情況,在使用Fine-tune方式所有特性的基礎上,還增加了teather網絡,來輔助模型的訓練。
此時模型的損失變為:
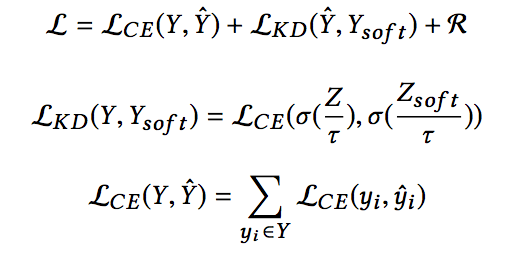
首先提一下,這個地方我感覺符號上還是有些值得商榷的地方,即student net的預測值,在和真實值(hard label)計算交叉熵損失,以及和teacher net的預測值(soft label,Ysoft)計算交叉熵損失時,二者的計算是存在一定的差別的(區別在于是否把log logits即Z除以temperature τ),因此符號上應該也做區別處理更加合適。
上面損失的三項分別是student net的預測值和真實值計算的交叉熵損失,student net的soft預測值和teacher net的soft預測值計算的交叉熵損失,以及正則項。
簡單解釋下損失中temperature τ的含義,知識蒸餾這種方式,我們希望得到的結果是student net和teacher net的輸出盡可能接近,假設不對logits除以temperature,那么teacher net輸出的類別概率可能會比較懸殊,比如0.99和0.01,那么0.01這一類對于損失的貢獻是非常小的,解決方式就是在計算損失函數時放大其他類的概率值所對應的損失值。假設teacher net的log logits = 3,那么softmax之后兩類的概率分別為0.95和0.05,再假設temperature=10,那么softmax之后兩類的概率分別為0.57和0.43,這樣兩種類別對于損失的貢獻更為接近了。這樣更加有助于student net向teacher net的方向優化。
關于teacher net的選擇,文中給出了兩種方式:
KD-batch:使用一定時間窗口內全量數據訓練的模型KD-self:t-1天的模型
后續會給出這兩種方式的實驗對比結果,好了,接下來是對模型模塊的總結:

3、實驗結果
好了,最后來看一下論文的實驗結果:
首先,使用論文提到的增量訓練的方式,表現能否超過本文一開始提到的使用固定長度的時間窗口重新訓練模型的方式呢?結果如下表所示,其中Batch-0表示使用最新的時間窗口訓練的模型,Batch-1表示使用延遲一天的時間窗口訓練的模型,依次類推,可以看到增量訓練方式得到了一定程度的AUC的提升,以及模型更新耗時的大幅縮短。
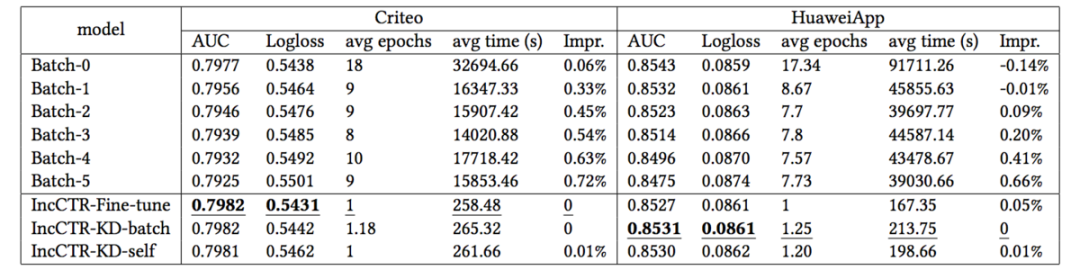
同時,從上表可以看到,在模型模塊使用或Fine-tune或者KD的方式,在Criteo數據集上表現接近,但在華為App上的數據來看,KD的方式表現更好。
最后,論文還驗證了特征模塊的作用,如果不對新加入的特征列別進行處理的話,會帶來效果的衰減,隨著天數的增加,這種衰減會越來越明顯。
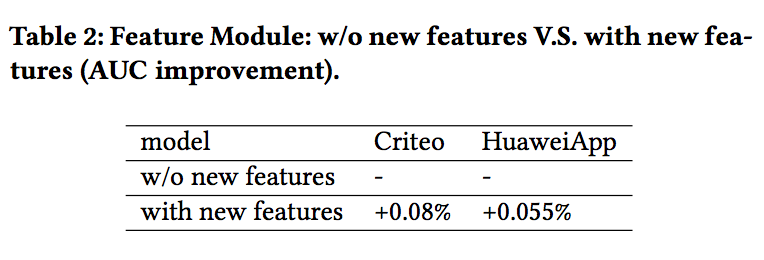
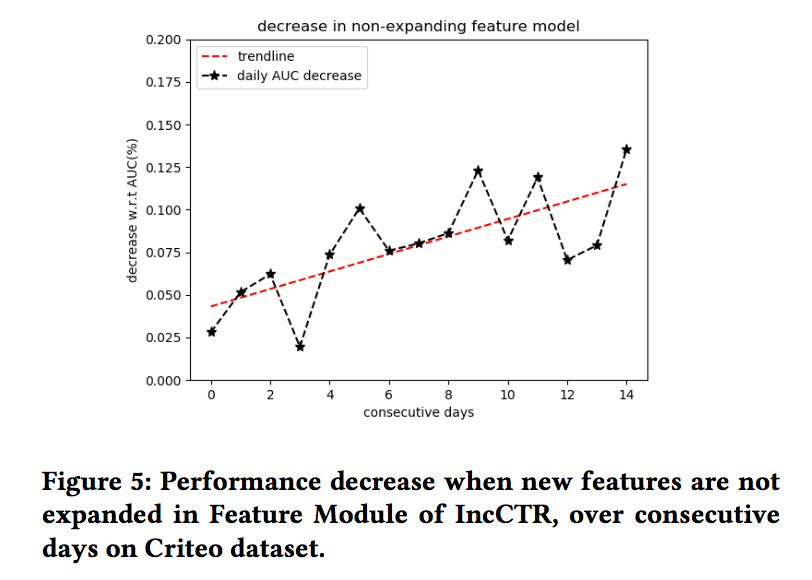
好了,本文就介紹到這里,又是一篇可以學到很多工業經驗的文章,值得仔細品讀!
推薦閱讀
- 計算廣告OCPC算法實踐(一) 智能出價PID控制中的偏差與響應函數設計
- 分享我收藏的100篇精選算法技術文章
- Embedding 技術在民宿推薦中的應用
- 分類模型與排序模型在推薦系統中的異同分析
想了解更多關于推薦系統的內容,歡迎掃碼關注公眾號淺夢的學習筆記。回復加群可以加入我們的交流群一起學習!
碼字很辛苦,有收獲的話就請分享、點贊、在看三連吧?















)



