文章目錄
- 一. urllib.parse.urlencode()和urllib.parse.unquote()
- 二. Get方式
- 三. 批量爬取百度貼吧數據
- 四.POST方式
- 五.關于CA
- 六.處理HTTPS請求 SSL證書驗證
一. urllib.parse.urlencode()和urllib.parse.unquote()
編碼工作使用urllib.parse的urlencode()函數,幫我們將key:value這樣的鍵值對轉換成"key=value"這樣的字符串
解碼工作可以使用urllib.parse的unquote()函數。
# IPython3 中的測試結果
In [1]: import urllib.parseIn [2]: word = {"wd" : "傳智播客"}# 通過urllib.urlencode()方法,將字典鍵值對按URL編碼轉換,從而能被web服務器接受。
In [3]: urllib.parse.urlencode(word)
Out[3]: "wd=%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2"# 通過urllib.unquote()方法,把 URL編碼字符串,轉換回原先字符串。
In [4]: print urllib.parse.unquote("wd=%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2")
wd=傳智播客二. Get方式
一般HTTP請求提交數據,需要編碼成 URL編碼格式,然后做為url的一部分,或者作為參數傳到Request對象中。
GET請求一般用于我們向服務器獲取數據,比如說,我們用百度搜索傳智播客:https://www.baidu.com/s?wd=傳智播客
瀏覽器的url會跳轉成如圖所示:
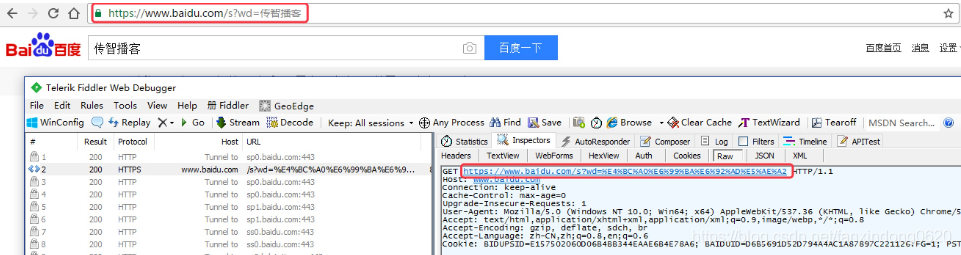
在其中我們可以看到在請求部分里,http://www.baidu.com/s? 之后出現一個長長的字符串,其中就包含我們要查詢的關鍵詞傳智播客,于是我們可以嘗試用默認的Get方式來發送請求。
import urllib.parse
import urllib.requesturl = "http://www.baidu.com/s"
word = {"wd":"傳智播客"}
# 轉換成url編碼格式(字符串)
word = urllib.parse.urlencode(word)
# url首個分隔符就是 ?
newurl = url + "?" + wordheaders={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"}request = urllib.request.Request(newurl, headers=headers)response = urllib.request.urlopen(request)print (response.read())
三. 批量爬取百度貼吧數據
首先我們創建一個python文件,我們要完成的是,輸入一個百度貼吧的地址,比如:
百度貼吧LOL吧第一頁:http://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=0
第二頁: http://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=50
第三頁: http://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=100
發現規律了吧,貼吧中每個頁面不同之處,就是url最后的pn的值,其余的都是一樣的,我們可以抓住這個規律。簡單寫一個小爬蟲程序,來爬取百度LOL吧的所有網頁。
-
步驟一:先寫一個main,提示用戶輸入要爬取的貼吧名,并用urllib.urlencode()進行轉碼,然后組合url,假設是lol吧,那么組合后的url就是:http://tieba.baidu.com/f?kw=lol
-
步驟二:接下來,我們寫一個百度貼吧爬蟲接口,我們需要傳遞3個參數給這個接口, 一個是main里組合的url地址,以及起始頁碼和終止頁碼,表示要爬取頁碼的范圍。
-
步驟三:我們已經之前寫出一個爬取一個網頁的代碼。現在,我們可以將它封裝成一個小函數loadPage,供我們使用。
-
步驟四:最后如果我們希望將爬取到了每頁的信息存儲在本地磁盤上,我們可以簡單寫一個存儲文件的接口。
import urllibfrom notebook.notebookapp import raw_inputdef tiebaSpider(url, beginPage, endPage):"""作用:負責處理url,分配每個url去發送請求url:需要處理的第一個urlbeginPage: 爬蟲執行的起始頁面endPage: 爬蟲執行的截止頁面"""for page in range(beginPage, endPage + 1):pn = (page - 1) * 50filename = "第" + str(page) + "頁.html"# 組合為完整的 url,并且pn值每次增加50fullurl = url + "&pn=" + str(pn)print(fullurl)# 調用loadPage()發送請求獲取HTML頁面html = loadPage(fullurl, filename)# 將獲取到的HTML頁面寫入本地磁盤文件writeFile(html, filename)def loadPage(url, filename):'''作用:根據url發送請求,獲取服務器響應文件url:需要爬取的url地址filename: 文件名'''print ("正在下載" + filename)headers = {"User-Agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}request = urllib.request.Request(url, headers = headers)response = urllib.request.urlopen(request)return response.read()def writeFile(html, filename):"""作用:保存服務器響應文件到本地磁盤文件里html: 服務器響應文件filename: 本地磁盤文件名"""print ("正在存儲" + filename)with open(filename, 'wb') as f:f.write(html)print("-" * 20)# 模擬 main 函數
if __name__ == "__main__":kw = raw_input("請輸入需要爬取的貼吧:")# 輸入起始頁和終止頁,str轉成int類型beginPage = int(raw_input("請輸入起始頁:"))endPage = int(raw_input("請輸入終止頁:"))url = "http://tieba.baidu.com/f?"key = urllib.parse.urlencode({"kw" : kw})# 組合后的url示例:http://tieba.baidu.com/f?kw=lolurl = url + keytiebaSpider(url, beginPage, endPage)
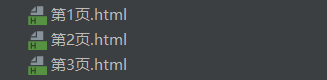
輸出結果:
請輸入需要爬取的貼吧:lol
請輸入起始頁:1
請輸入終止頁:3
http://tieba.baidu.com/f?kw=lol&pn=0
正在下載第1頁.html
正在存儲第1頁.html
--------------------
http://tieba.baidu.com/f?kw=lol&pn=50
正在下載第2頁.html
正在存儲第2頁.html
--------------------
http://tieba.baidu.com/f?kw=lol&pn=100
正在下載第3頁.html
正在存儲第3頁.html
--------------------
四.POST方式
上面我們說了Request請求對象的里有data參數,它就是用在POST里的,我們要傳送的數據就是這個參數data,data是一個字典,里面要匹配鍵值對。
有道詞典翻譯網站:
輸入測試數據,再通過使用Fiddler觀察,其中有一條是POST請求,而向服務器發送的請求數據并不是在url里,那么我們可以試著模擬這個POST請求。
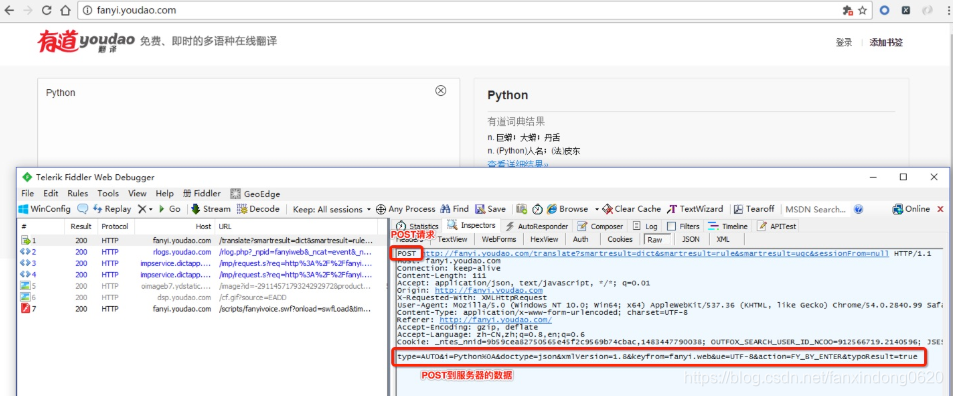
于是,我們可以嘗試用POST方式發送請求。
import urllib.parse
import urllib.request# POST請求的目標URL
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null"headers={"User-Agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}formdata = {"type":"AUTO","i":"i love python","doctype":"json","xmlVersion":"1.8","keyfrom":"fanyi.web","ue":"UTF-8","action":"FY_BY_ENTER","typoResult":"true"
}data = urllib.parse.urlencode(formdata)
data = data.encode('utf-8')request = urllib.request.Request(url, data = data, headers = headers)
response = urllib.request.urlopen(request)print ("*" * 100)
print (response.read())
print ("*" * 100)
輸出結果:
****************************************************************************************************
b' {"type":"EN2ZH_CN","errorCode":30,"elapsedTime":1,"translateResult":[[{"src":"\xe6\x82\xa8\xe7\x9a\x84\xe8\xaf\xb7\xe6\xb1\x82\xe6\x9d\xa5\xe6\xba\x90\xe9\x9d\x9e\xe6\xb3\x95\xef\xbc\x8c\xe5\x95\x86\xe4\xb8\x9a\xe7\x94\xa8\xe9\x80\x94\xe4\xbd\xbf\xe7\x94\xa8\xe8\xaf\xb7\xe5\x85\xb3\xe6\xb3\xa8\xe6\x9c\x89\xe9\x81\x93\xe7\xbf\xbb\xe8\xaf\x91API\xe5\xae\x98\xe6\x96\xb9\xe7\xbd\x91\xe7\xab\x99\\u201C\xe6\x9c\x89\xe9\x81\x93\xe6\x99\xba\xe4\xba\x91\\u201D: http:\\/\\/ai.youdao.com","tgt":"\xe6\x82\xa8\xe7\x9a\x84\xe8\xaf\xb7\xe6\xb1\x82\xe6\x9d\xa5\xe6\xba\x90\xe9\x9d\x9e\xe6\xb3\x95\xef\xbc\x8c\xe5\x95\x86\xe4\xb8\x9a\xe7\x94\xa8\xe9\x80\x94\xe4\xbd\xbf\xe7\x94\xa8\xe8\xaf\xb7\xe5\x85\xb3\xe6\xb3\xa8\xe6\x9c\x89\xe9\x81\x93\xe7\xbf\xbb\xe8\xaf\x91API\xe5\xae\x98\xe6\x96\xb9\xe7\xbd\x91\xe7\xab\x99\\u201C\xe6\x9c\x89\xe9\x81\x93\xe6\x99\xba\xe4\xba\x91\\u201D: http:\\/\\/ai.youdao.com"}]]}\n'
****************************************************************************************************
五.關于CA
CA(Certificate Authority)是數字證書認證中心的簡稱,是指發放、管理、廢除數字證書的受信任的第三方機構,如北京數字認證股份有限公司、上海市數字證書認證中心有限公司等…
CA的作用是檢查證書持有者身份的合法性,并簽發證書,以防證書被偽造或篡改,以及對證書和密鑰進行管理。
現實生活中可以用身份證來證明身份, 那么在網絡世界里,數字證書就是身份證。和現實生活不同的是,并不是每個上網的用戶都有數字證書的,往往只有當一個人需要證明自己的身份的時候才需要用到數字證書。
普通用戶一般是不需要,因為網站并不關心是誰訪問了網站,現在的網站只關心流量。但是反過來,網站就需要證明自己的身份了。
比如說現在釣魚網站很多的,比如你想訪問的是www.baidu.com,但其實你訪問的是www.daibu.com”,所以在提交自己的隱私信息之前需要驗證一下網站的身份,要求網站出示數字證書。
一般正常的網站都會主動出示自己的數字證書,來確保客戶端和網站服務器之間的通信數據是加密安全的。
六.處理HTTPS請求 SSL證書驗證
現在隨處可見 https 開頭的網站,urllib可以為 HTTPS 請求驗證SSL證書,就像web瀏覽器一樣,如果網站的SSL證書是經過CA認證的,則能夠正常訪問,如:https://www.baidu.com/等,如果SSL證書驗證不通過,或者操作系統不信任服務器的安全證書,會警告用戶證書不受信任。
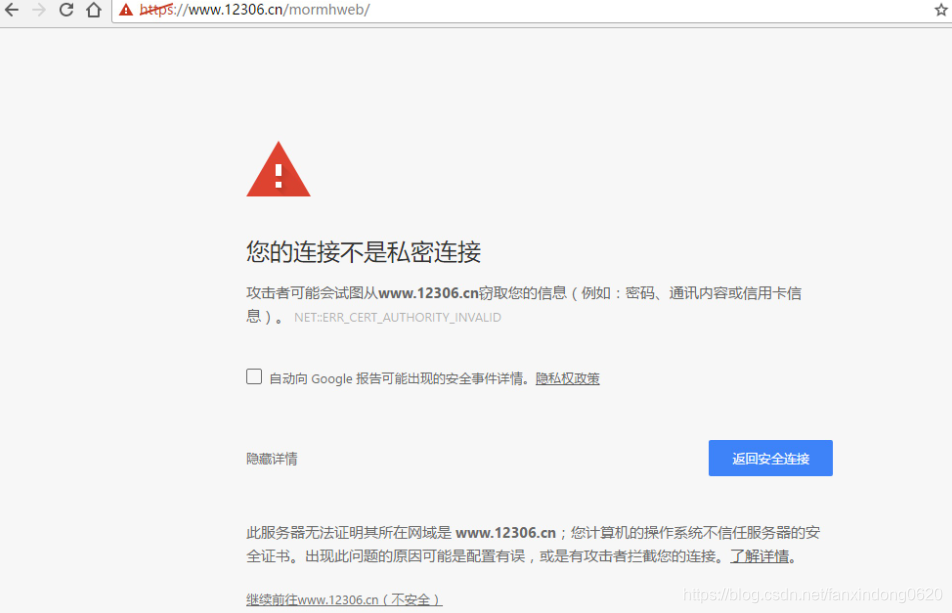
urllib在訪問的時候則會報出SSLError:
import urllib.parse
import urllib.requesturl = "https://www.12306.cn/mormhweb/"headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}request = urllib.request.Request(url, headers = headers)response = urllib.request.urlopen(request)print (response.read())
運行結果:
URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:749)>
所以,如果以后遇到這種網站,我們需要單獨處理SSL證書,讓程序忽略SSL證書驗證錯誤,即可正常訪問。
import urllib.parse
import urllib.request
# 1. 導入Python SSL處理模塊
import ssl# 2. 表示忽略未經核實的SSL證書認證
context = ssl._create_unverified_context()url = "https://www.12306.cn/mormhweb/"headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}request = urllib.request.Request(url, headers = headers)# 3. 在urlopen()方法里 指明添加 context 參數
response = urllib.request.urlopen(request, context = context)print (response.read().decode())
















...)
)

