從《高可用服務設計之二:Rate limiting 限流與降級》中的“自動降級”中,我們這邊將系統遇到“危險”時采取的整套應急方案和措施統一稱為降級或服務降級。想要幫助服務做到自動降級,需要先做到如下幾個步驟:
- 可配置的降級策略:降級策略=達到降級的條件+降級后的處理方案,策略一定得可配置,因為不同的服務對服務的質量定義不一樣,降級的方案也將不一樣。
- 可識別的降級邊界:一定要精確的知道需要對誰進行降級,可以是一個對外服務、對下游的一個依賴或者是內部一段處理邏輯。降級邊界主要用來植入降級邏輯。
- 數據采集:是否達到降級條件依賴于采集的數據,這些數據可以是當前某段時間的數據,也可以是很長一段時間的歷史數據。
- 行為干預:進入降級狀態后將會對正常的業務流程產生干預,可能是限流、熔斷,也可能是同步流程變為異步流程等(比如發送MQ的變成oneway的形式)等。
- 結果干預:是返回null,還是默認值,還是流程上的同步改異步等。
- 快速恢復:即如何從降級狀態變回正常狀態,這也需要達到某些條件。
我們來逐步看下Hystrix是如何做到以上幾點的,
###?可配置的降級策略?###
Hystrix提供了三種降級策略:并發、耗時和錯誤率,而Hystrix的設計本身就能很好的支持動態的調整這些策略(簡單的說就是調整并發、耗時和錯誤率的閾值),當然,如何去動態調整需要用戶自己來實現,Hystrix只提供了入口,就是說,Hystrix并沒有提供一個服務端界面來動態調整這些策略,這多少有點讓人遺憾。如果要了解Hystrix具體的策略配置,可以看看HystrixCommandProperties 和 HystrixThreadPoolProperties兩個類。
###?可識別的降級邊界?###
降級工具面臨的第一個難題就是如何在業務代碼中植入降級邏輯,業務研發人員得提前明確和定義哪些地方是風險點,然后將這些地方的邏輯抽取出來,Hystrix包裝需降級的業務邏輯采用的是Command設計模式,我們知道,命令模式主要是將請求封裝到對象內部,讓我們使用對象一樣來使用請求。這樣對Hystrix大有好處,因為你需要降級的業務邏輯和數據已經封裝成一個Command對象交給Hystrix了,Hystrix直接來接管業務邏輯的執行權,該何時調用,或者甚至不調用都可以,我們來看看Hystrix定義的命令接口。
只需要簡單繼承HystrixCommand,就相當于接入了Hystrix,泛型R代表返回值類型,在run()方法中直接實現正常的業務邏輯,并返回R類型的結果,如果降級后需要返回特殊的值,你只需要覆蓋getFallback()方法即可。
舉個例子,見《服務容錯保護斷路器Hystrix之六:緩存功能的使用》
可以看出,我們創建了一個BookCommand?的實例,然后調用了execute方法來獲取結果,這樣就基本完成了,Hystrix庫類已經給邏輯附上了緩存、自動降級等邏輯了,當然里面使用了大量Hystrix默認的降級策略配置(本文不是Hystrix使用的詳細教程,所以這里主要突出的是用法而不強調具體的策略配置)。這里同樣也說明了為什么動態調整配置是很容易的,因為每個請求都會新建Command對象(注意,Command對象是有狀態的,不能重用),你只需要在創建時調整策略參數就行了,當然,這得用戶自己來實現。
雖然看起來很簡單,但老司機馬上會發現問題:
- 系統中每一處需要降級的邏輯都需要將其封裝成一個Command類,哪怕需要降級的方法只有一行代碼。如果一個系統有一百個需要降級的點,那么我們需要在系統中新增一百個Command類,有時候這讓人難以接受。
- 對老的業務系統來說,接入Hystrix將意味著巨大的工作量,因為你要把很多邏輯都封裝成Command,你能接受但測試同學未必愿意。
- 每次請求都將創建一個Command對象,因為Command對象包含了降級邏輯的大部分操作,是個重狀態的對象,不能復用,如果QPS過高,將產生大量的朝生夕死的對象,對內存分配和GC將產生一定的壓力。
很多用戶確實也提出過抱怨,為何Hystrix的侵入性那么強?但Hystrix設計者們這么做自然有他們的道理(詳見:https://github.com/Netflix/Hystrix/wiki/FAQ%20:%20General?的Why is it so intrusive?部分),他們認為,我們需要給應用的依賴提供一個清晰的屏障,使用Command模式不僅僅是出于功能上的原因,也是作為一種標準機制,通過Command對象來向用戶傳遞它是受保護的資源。可見,Hystrix的設計者們并不建議我們使用基于注解或AOP來作為接入Hystrix的方式,但他們仍然說:If you still feelstrongly that you shouldn't have to modify libraries and add command objectsthen perhaps you can contribute an AOP module.(直譯過來就是如果你嫌麻煩不想創建這么多Command對象,有本事你自己去實現AOP啊!開個玩笑(*^__^*) )。?
###?數據采集?###
收集數據是必不可少的一步,每個降級點(需要采取降級保護的點)的數據是獨立的,所以我們可以給每個降級點配置單獨的策略。這些策略一般是建立在我們對這些降級點的了解之上的,初期甚至可以先觀察一下采集的數據來指定降級策略。采集哪些數據?數據如何存儲?數據如何上報?這都是Hystrix需要考慮的問題,Hystrix采用的是滑動窗口+分桶的形式來采集數據(具體細節見另一篇),這樣既解決了數據在統計周期間切換而帶來的跳變問題(通過時間窗口),也控制了切換了力度(通過桶大小)。另一個有意思的地方是,與常規的同步統計數據的方式不同,Hystrix采用的是RxJava來進行事件流的異步統計數據,類似于觀察者模式(具體細節見另一篇),這樣做的好處是降低統計時阻塞業務邏輯的風險,在某些情況下還能享受多核CPU所帶來的性能上的收益。?
###?行為干預?###
一旦發現采集的數據命中了降級策略,那么降級工具就將對請求進行行為干預,行為干預是評價一個降級工具好壞的重要指標,它的設計直接關系到系統的“彈性”到底有多大。但有時候行為干預和上面提到的數據采集這兩個動作是同時完成的,比如使用信號量、線程池或者令牌桶算法來進行降級的時候。行為干預的設計是很有技巧的,一般來說有如下兩種方案:
- 實時采集(當前某段時間周期的)數據,對每筆請求都進行策略判斷(每筆請求都會加入數據并進行分析),一旦命中策略,當即對這筆請求進行行為干預,如果沒有命中,則執行正常的業務邏輯。
- 實時采集(當前某段時間周期的)數據,對每筆請求都進行策略判斷(每筆請求都會加入數據并進行分析),一旦有一筆請求命中了策略,接下來的一段時間(可配)內的所有請求都會被行為干預,哪怕接下來再也沒有請求命中策略,一直到該段時間過去。
方案a似乎是比較合理的,它總是將系統的行為盡可能的控制在我們預期之內(即各項指標都在配置的策略之下),但多數情況下,我們配置策略會比較寬泛,不那么嚴格,那這時候采用方案a對系統來說還是有一定的風險。這時候就出現了相對更激進的方案b!一但某些請求導致統計數據觸犯了降級策略,那么系統會對后續一段時間的所有請求進行降級處理,即我們熟知的降級延長。而Hystrix將兩者結合起來了,讓行為干預更加靈活。
###?結果干預?###
被降級后的請求是應該返回null?還是默認值?還是拋異常?這些都要根據業務而定。Hystrix也在HystrixCommand提供了getFallback方法來方便用戶返回降級后的結果。
###?快速恢復?###
快速恢復功能在那些經常由于外部因素而導致進入降級狀態的系統來說尤為重要,降級系統或工具的一個重大目標就是自動性,擺脫需要人為控制開關來保證功能熔斷的“原始時代”,所以當外部條件已經恢復,系統也應該在最短的時間內恢復到正常服務狀態,這就要求降級系統能夠在讓業務系統進入降級狀態的同時,讓業務系統有探測外界環境的機會。大多數降級系統都會在一段時間后“放”一筆請求進來,讓它去“試一試”,如果結果是成功的,那么將讓業務系統恢復到正常狀態,Hystrix同樣也是采用這種做法。
如果看到這里,其實大家已經對Hystrix的功能有一定的了解,這里再給一張官方的圖:
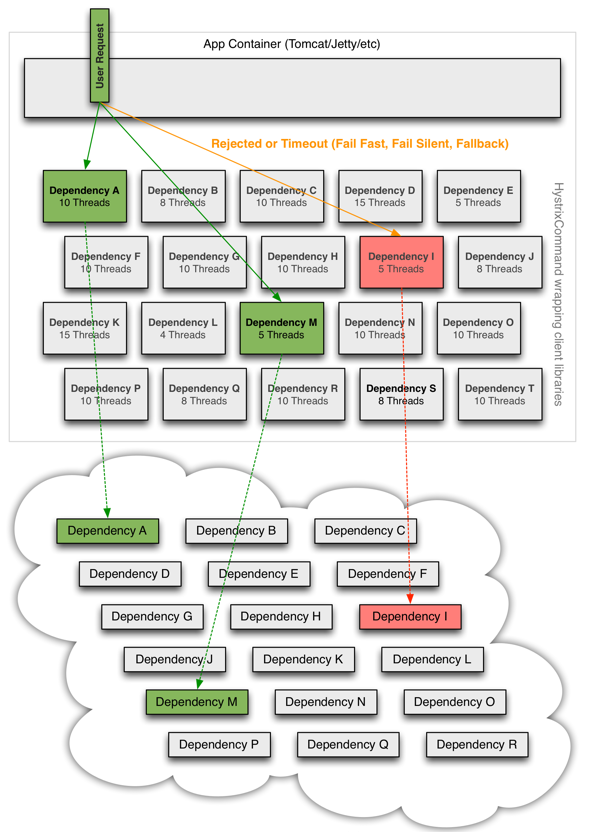
這張圖已經充分說明了官方推薦的是通過Command+線程池的模式來進行業務功能的剝離和管理,這些大大小小的線程池,使用不當,將產生隱患,所以千萬不要讓Hystrix的這種用法變成反模式。
?
在最后,我們來簡單總結下Hystrix的特色:
- Hystrix內部大量使用了響應式編程模型,通過RxJava庫,把能異步做的都做成異步了。這似乎能降低代碼復雜度(我是指對RxJava了解的人),并且在多核CPU的服務器上能帶來意外性能收獲。
- Hystrix能做到通過并發、耗時和異常來進行降級,并能在(并發、限流或內部產生的異常導致的)錯誤率達到一定閾值時進行服務熔斷,并且還能做到從降級狀態快速恢復。
- Hystrix通過Command模式來包裝降級業務,這有時候提高了接入成本。
- Hystrix只提供了策略變更的入口,但具體的策略可視化和動態配置還是得用戶來實現,這確實非常尷尬。
- Hystrix默認的儀表盤只提供了簡單的實時數據顯示,如果要持久化歷史數據,也得用戶來實現。
?





)













