?近一段時間,有同事問我 “MySQL執行count很慢,有沒有什么優化的空間”。當時在忙,就回復了一句“innodb里面count統計都是實時統計,慢一些是正常的”, 周末閑暇下來,想到以前有好多人都問過關于count的問題,今天就聊聊MySQL之Count查詢。
??????? 關于MySQL的count查詢,很多人都會有疑問,同樣在大表中執行 ,有些速度基本不耗時,有些又慢的要死。關于這些問題在《高性能MySQL》這本書中第6.7.1章節有如下相關解釋:
? ? ? COUNT()聚合函數,以及如何優化使用了該函數的查詢,很可能是MySQL中最容易被誤解的前10個話題之一,在網上隨便搜索一下就能看到很多錯誤的理解,可能比我們想象的多得多。
在做優化之前,先來看看COUNT()函數的真正作用是什么。
COUNT()的作用
COUNT()是一個特殊的函數,有兩種非常不同的作用:它可以統計某個列值的數量,也可以統計行數。在統計列值時要求列值非空的(不統計NULL)。如果在COUNT()的括號中指定了列或列的表達式,統計的就是這個表達式有值的結果數。因為很多人對NULL理解有問題,所以這里很容易產生誤解。如果想了解更多關于SQL語句中NULL的含義,建議閱讀一些關于SQL語句基礎的書籍。(關于這個話題,互聯網上的一些信息是不夠精確的)
COUNT()的另外一個作用是統計結果集的行數。當mysql確認括號內的表達式值不可能為空時,實際上就是在統計行數。最簡單的就是當我們使用COUNT(*)的時候,這種情況下通配符*并不會像我們猜想的那樣擴展成所有的列,實際上,它會忽略所有的列而直接統計所有的行數。
我們發現一個最常見的錯誤就是,在括號內指定了一個列卻希望統計結果集的行數。如果希望知道的是結果集的行數,最好使用COUNT(*),這樣寫意義清晰,性能也會很好。
于MyISAM的神話
一個容易產生的誤解就是:MyISAM的COUNT()函數總是非常快,不過這是有前提條件的,即只有沒有任何where條件的COUNT(*)才非常快,因為此時無需實際地去計算表的行數。MySQL可以利用存儲引擎的特性直接獲得這個值。如果MySQL知道某列col不可能為NULL值,那么MySQL內部會將COUNT(col)表達式優化為COUNT(*)。
當統計帶WHERE子句的結果集行數,可以是統計某個列值的數量時,MySQL的COUNT()和其它存儲引擎沒有任何不同,就不再有神話般的速度了。所以在MyISAM引擎表上執行COUNT()有時候比別的引擎快,有時候比別的引擎慢,這受很多因素影響,要視具體情況而定。
《高性能MySQL》這本書只介紹了MyISAM存儲引擎在count上的誤區以及在MyISAM存儲引擎上的count優化,而對于常用的innodb執行Count沒有做過多講解,下面我們就聊聊如何在Innodb上進行count優化。
?
Innodb存儲引擎:
(1) ??? innodb存儲引擎的物理結構包含 表空間、段、區、頁、行 五個層級,數據文件按照主鍵排序存儲在頁中(頁在邏輯上連續),主鍵的位置即為數據存儲位置。
(2) ??? 二級索引存儲的數據為指定字段的值與主鍵值。當我們通過二級索引統計數據的時候,無需掃描數據文件;而通過主鍵索引統計數據時,由于主鍵索引與數據文件存放在一起,所以每次都會掃描數據文件,故大多數情況下,通過二級索引統計數據效率 >= 基于主鍵統計效率。
(3)??? 由于二級索引存儲的數據為指定字段的值與主鍵值,故在無索引覆蓋的情況下,查詢二級索引后會根據二級索引獲取的主鍵到主鍵索引中提取數據,此過程可能造成大量的隨機io,導致查詢速度較慢。
(4) ?? 由于主鍵索引與數據存儲保持一致,故基于主鍵的查找數據要比通過二級索引查詢數據要快(使用二級索引時,查詢到的數據條數>總條數的20%時候mysql就選擇全表掃描,但在主鍵索引上,即使符合條件的達到 90%依然會走索引)。
?
count慢的原因:
innodb為聚簇索引同時支持事物,其在count指令實現上采用實時統計方式。在無可用的二級索引情況下,執行count會使MySQL掃描全表數據,當數據中存在大字段或字段較多時候,其效率非常低下(每個頁只能包含較少的數據條數,需要訪問的物理頁較多)。
?
innodb可優化點:
1.?主鍵需要采用占用空間盡量小的類型且數據具有連續性(推薦自增整形id),這樣有利于減少頁分裂、頁內數據移動,可加快插入速度同時有利于增加二級索引密度(一個數據頁上可以存儲更多的數據)。
2.在表包含大字段或字段較多情況下,若存在count統計需求,可建一個較小字段的二級索引(例 char(1) , tinyint )來進行count統計加速。
?
下面做個count優化例子:
1.首先我們創建一直innodb表,并包含大字段(或包含較多字段):
?
CREATE TABLE `qstardbcontent` (
? `id` BIGINT(20) NOT NULL DEFAULT '0',
? `content` MEDIUMTEXT,
? `length` INT(11)? NOT NULL DEFAULT '0',
? PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
?
2.插入50萬條數據,每條數據 5K
?
3.執行select count(*) from qstardbcontent

?
可以看到,近50萬條內容較多的數據執行一個count(*) 就需要耗時 13分28秒
下面我們做個優化,在length字段上加個索引, 執行sql: ALTER TABLE qstardbcontent ADD KEY(LENGTH);
?
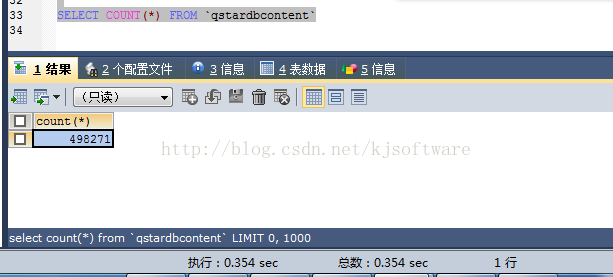
索引建完成后,再執行 select count(*) from qstardbcontent;
?
可以看到,整個統計查詢非常快,僅用了 354毫秒就完成了查詢。
?
加速原因:
我們在innodb表上創建了一個二級索引,Innodb在執行count(*)時候由優化器選擇執行路徑。本例中, 二級索引的存儲空間僅包含length字段值、數據主鍵,假設二級索引輔助結構不占用空間(僅計算數據占用空間),在默認情況下,MySQL的一個數據頁大小為16K,一個頁可存儲的數據條數為 16*1024/(4+8) =1365 ,按照單頁存儲空間占用為50%(頁分裂現象導致頁不滿)計算,50萬條數據的統計僅需要讀取約732個物理頁,而頁在連續的情況下,數據庫一次可讀取多個連續的頁,數據讀取總量為 16k*732約 12MB,因mysql空間分配為按區分配,每個區1M,一次分配1-5個連續區,當數據量較小,一次僅分配一個區,12M數據會分配在12個區中,按照pc硬盤(轉速7200轉/分) 70m/s 的讀取速度,整個過程的io尋址時間(12*8.5ms=102)+讀取時間(12m/70m=171ms)=273ms,而數據解析統計約為 30-100ms,故總耗時會在300ms附近(注:count優化功能在5.1版本并不支持)。









)


, misplaced construct(s))






