1、SDK與API的區別?
SDK是Software Development Kit的縮寫,即軟件開發工具包。可以把SDK想象成一個虛擬的程序包,在這個程序包中有一份做好的軟件功能,這份程序包幾乎是全封閉的,通過接口聯通外界,相應的接口就是API。
JDK(Java Development Kit),即Java開發工具包,是針對Java開發者的產品,JDK是SDK的一個子集,JDK已經成為使用最廣泛的JAVA SDK 。JDK是整個Java的核心,包括Java運行環境JRE、一堆Java工具(javac/java/jdb等)和java基礎的類庫(Java API、tr.jar等)。
JAR是java的歸檔格式,是一個程序集,內部全是class文件,是java SDK的一種打包形式。因為SDK不限語言,不限平臺,所以針對不同語言、平臺都有不同的打包方式。
2、長連接與短連接?
HTTP的長連接和短連接本質上是TCP長連接和短連接。HTTP屬于應用層協議,在傳輸層使用TCP協議,在網絡層使用IP協議。 IP協議主要解決網絡路由和尋址問題,TCP協議主要解決如何在IP層之上可靠地傳遞數據包,使得網絡上接收端收到發送端所發出的所有包,并且順序與發送順序一致,TCP協議是可靠的、面向連接的。
【TCP短連接】:client向server發起連接請求,server接到請求,然后雙方建立連接。client向server發送消息,server回應client,然后一次請求就完成了。這時候雙方任意都可以發起close操作,不過一般都是client先發起close操作。上述可知,短連接一般只會在 client/server間傳遞一次請求操作。
【TCP長連接】:client向server發起連接,server接受client連接,雙方建立連接,client與server完成一次請求后,它們之間的連接并不會主動關閉,后續的讀寫操作會繼續使用這個連接。TCP長連接支持Keepalive保活功能,如果客戶端已經消失而連接未斷開,則會使得服務器上保留一個半開放的連接,而服務器又在等待來自客戶端的數據,此時服務器將永遠等待客戶端的數據,保活功能就是試圖在服務端器端檢測到這種半開放的連接。
3、中介者模式
中介者模式(Mediator Pattern):定義一個中介對象來封裝系列對象之間的交互。中介者使各個對象不需要顯示地相互引用,從而使其耦合性松散,而且可以獨立地改變他們之間的交互。
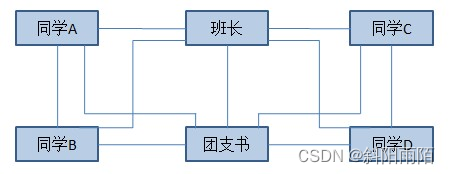
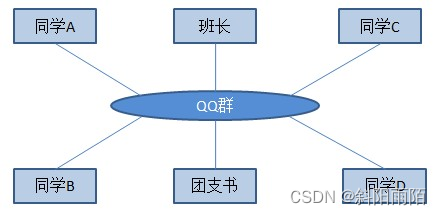
4、日常開發中對MVC的誤解
MVC代表著Model、View、Controller,View層是界面,Controller層是業務邏輯,Model層是數據庫訪問。View通常不會直接提交數據給Model,它會先把數據提交給Controller,然后Controller再將數據轉發給Model。假如此時程序業務邏輯的處理方式有變化,那么只需要在Controller中將原來的Model換成新實現的Model就可以了,控制器的作用就是這么簡單, 用來將不同的View和不同的Model組織在一起,Controller實際相當于一個中介者。
我們在實際的開發過程中,經常會將MVC和另一種軟件開發模式“三層架構”相混淆,“三層架構”分別是UI層表示用戶界面,BLL層表示業務邏輯,DAL層表示數據訪問,當前我們開發大部分使用的都是“三層架構”的模式,卻經常誤解成MVC。
5、Tomcat和Spring的關系
Tomcat是HTTP服務器、Servlet容器,負責給Servlet提供一個運行的環境,可以把HTTP服務器想象成前臺的接待,負責網絡通信和解析請求,Servlet容器是業務部門,負責處理業務請求。Tomcat是實現了Servlet規范的Servlet容器,SpringMVC是處理Servlet請求的應用,其中DispatcherServlet實現了Servlet接口,Tomcat負責加載和調用DispatcherServlet。同時,DispatcherServlet有自己的容器(SpringMVC)容器,這個容器負責管理SpringMVC相關的bean,比如Controler和ViewResolver等。同時,Spring中還有其他的Bean比如Service和DAO等,這些由全局的Spring IOC容器管理,因此,Spring有兩個IOC容器。Tomcat能夠支持的并發連接數是1000左右。
6、PageCache
pageCache頁高速緩沖存儲器,簡稱頁高緩,用于緩存文件的頁數據,從磁盤中讀取到的內容就是存儲在pageCache里的。
在Linux的實現中,文件Cache分為兩個層面,一是PageCache,另一個是BufferCache(塊緩存)。PageCache用于緩存文件的頁數據,大小通常為4K;BufferCache用于緩存塊設備(如磁盤)的塊數據,大小通常為1K。
在Linux2.4版本的內核之前,PageCache和BufferCache是完全分離的。但是塊設備大多數是磁盤,磁盤上的數據又大多通過文件系統來組織,這種設計導致很多數據被緩存了兩次,浪費內存空間。所以在2.4版本內核之后,兩塊內存近似融合在了一起,如果一個文件的頁加載到了PageCache,那么BufferCache只需要維護塊指向頁的指針。在2.6版本內核中,PageCache和BufferCache進一步結合。每一個PageCache包含若干BufferCache。
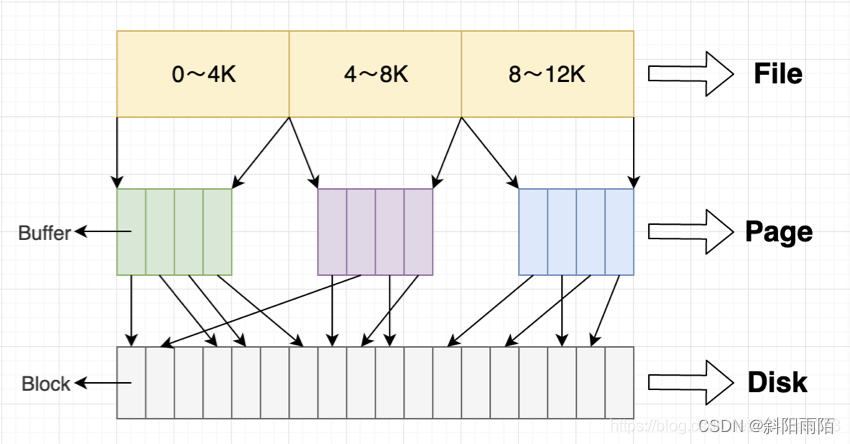
【讀cache】
當內核發起一個讀請求時(例如進程發起read()請求),首先會檢查請求的數據是否緩存到了PageCache中。如果有,那么直接從內存中讀取,不需要訪問磁盤,這被稱為cache命中(cache hit)。如果cache中沒有請求的數據,即cache未命中(cache miss),就必須從磁盤中讀取數據。然后內核將讀取的數據緩存到cache中,這樣后續的讀請求就可以命中cache了。
【寫cache】
當內核發起一個寫請求時(例如進程發起write()請求),直接往cache中寫入。內核會將被寫入的page標記為dirty,并將其加入dirty list中。內核會周期性地將dirty list中的page寫回到磁盤上,從而使磁盤上的數據和內存中緩存的數據一致。
7、ZeroCopy-零拷貝
【DMA技術】:DMA全稱Direct Memory Access直接內存訪問技術,指的是在進行I/O設備或內存數據傳輸時,數據的搬運工作都交給DMA控制器處理,CPU不參與數據搬運工作,進而提高CPU利用率,各種I/O設備都會自帶DMA控制器。
【傳統文件傳輸】:服務器如果需要進行文件傳輸,首先需要讀取磁盤文件,然后通過網絡協議傳輸給客戶端。由于用戶態沒有操作磁盤和網卡的權限,需要切換為內核態才能操作,所以在傳統的文件傳輸過程中,數據的讀取和寫入都需要在用戶空間和內核空間來回復制。一次上線文切換需要耗時幾十納秒到幾微妙,在高并發場景下會影響系統性能。
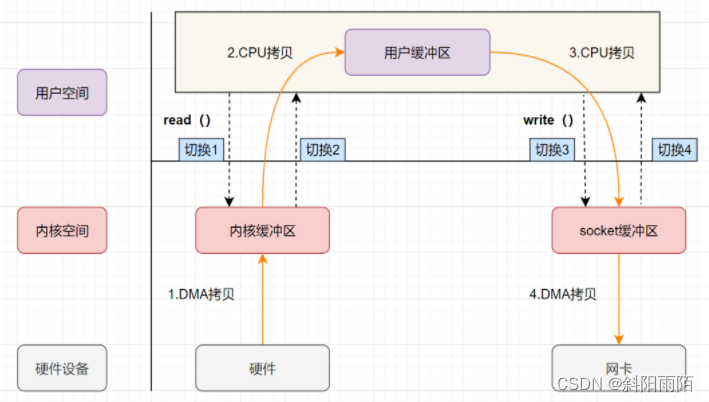
傳統文件傳輸流程:
- 磁盤數據(通常會先緩存到磁盤控制器緩沖區)拷貝到操作系統內核緩沖區。
- 操作系統內核緩沖區數據拷貝到用戶緩沖區
- 用戶緩沖區數據拷貝到socket緩沖區
- socket緩沖區數據拷貝到網卡緩沖區
這個過程中發生了4次上下文切換(從磁盤讀取數據時2次,寫數據到網卡時2次),和4次數據拷貝。在沒有DMA技術前,從磁盤到內核緩存、從Socket緩存到網卡緩存,的數據傳輸也是由CPU處理的,在數據傳輸期間CPU無法執行其他任務,同時這些外設的傳輸效率比起內存傳輸效率低很多,會嚴重影響CPU利用率,所以才出現了DMA技術,外設和系統緩沖區間的數據傳輸由設備自帶的DMA控制器自行處理,處理完成后在發送中斷信號給CPU,CPU再完成用戶空間和內核空間的數據傳輸。
【零拷貝】:零拷貝應用了內存映射技術mmap,它的核心是操作系統把內核緩沖區與應用程序共享,將一段用戶空間內存映射到內核空間,當映射成功后,用戶對這段內存區域的修改可以直接反映到內核空間;同樣地,內核空間對這段區域的修改也直接反映用戶空間。正因為有這樣的映射關系, 就不需要在用戶態與內核態之間拷貝數據, 提高了數據傳輸的效率,這就是內存直接映射技術。
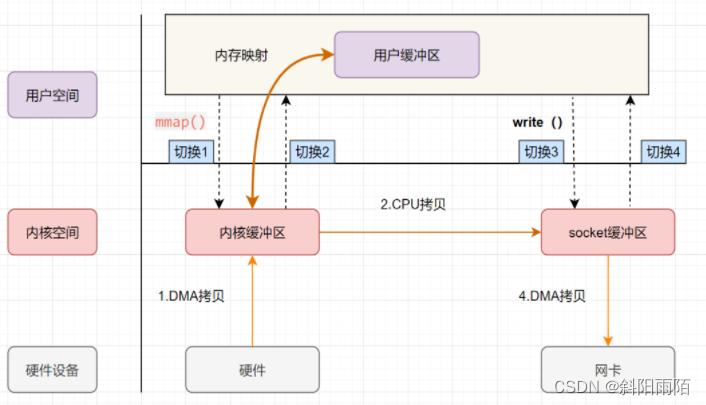
有了mmap后,數據無需再傳輸到用戶空間,節省了兩2次CPU拷貝,但是仍需要4次上下文切換,因為read(從磁盤讀數據)和write(寫數據到網卡)兩次系統調用的發起都需上下文切換,同時內核緩沖區到socket緩沖區的數據傳輸,還是需要一次CPU拷貝。
為了進一步減少上線文切換次數,read、write兩次系統調用被合并成一次sendfile,同時為了將CPU拷貝次數減少到0,又推出了帶DMA收集拷貝功能的sendfile,這才真正意義上的實現了“零拷貝”(這個“零拷貝”實際指的是零CPU拷貝):
- 用戶應用程序發出sendfile系統調用,上下文從用戶態切換到內核態,然后通過DMA控制器將數據從磁盤中復制到內核緩沖區中
- 接下來不需要CPU將數據復制到socket緩沖區,而是將相應的文件描述符信息復制到 socket 緩沖區,該描述符包含了兩種的信息:①內核緩沖區的內存地址、②內核緩沖區的偏移量
- sendfile系統調用返回,上下文從內核態切換到用戶態
- DMA根據socket緩沖區中描述符提供的地址和偏移量直接將內核緩沖區中的數據復制到網卡
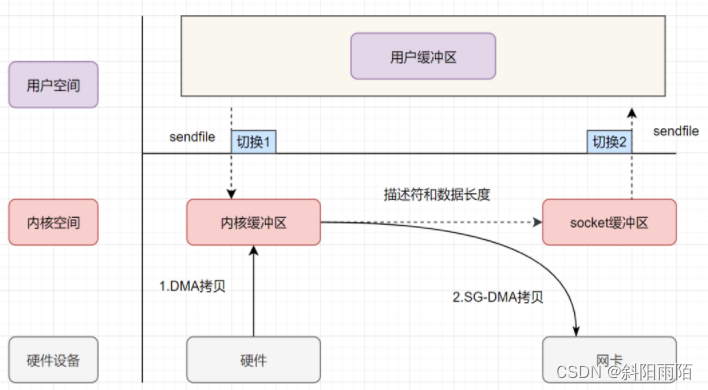
零拷貝極大地提升了文件傳輸效率,在Java NIO、Netty框架、kafka中都有應用,但是因為數據實際并沒有進入用戶空間,所以零拷貝不支持進程對文件內容作一些加工再發送,比如數據壓縮后再發送。
8、fsync
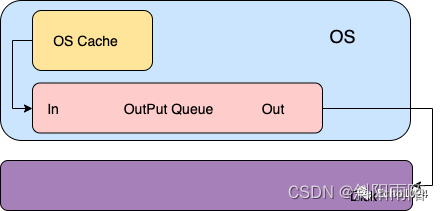
當你想將數據write進文件時,內核通常會將該數據復制到其中一個緩沖區中,如果該緩沖沒被寫滿的話,內核就不會把它放入到輸出隊列中。當這個緩沖區被寫滿或者內核想重用這個緩沖區時,才會將其排到輸出隊列中。等它到達等待隊列首部時才會進行實際的IO操作。這里的輸出方式就是大家耳熟能詳的:延遲寫,這個緩沖區就是大家耳熟能詳的:OS Cache。很明顯、延遲寫降低了磁盤讀寫的次數,但同時也降低了文件的更新速度。這樣當OS Crash時由于這種延遲寫的機制可能會造成文件更新內容的丟失。而為了保證磁盤上的實際文件和緩沖區中的內容保持一致,UNIX系統提供了三個系統調用:sync、fsync、fdatasync。
-
sync系統調用:將所有修改過的緩沖區排入寫隊列,然后就返回了,它并不等實際的寫磁盤的操作結束。所以它的返回并不能保證數據的安全性。通常會有一個update系統守護進程每隔30s調用一次sync。
-
fsync系統調用:需要你在入參的位置上傳遞給他一個fd,然后系統調用就會對這個fd指向的文件起作用。fsync會確保一直到寫磁盤操作結束才會返回,所以當你的程序使用這個函數并且它成功返回時,就說明數據肯定已經安全的落盤了。所以fsync適合數據庫這種程序。
-
fdatasync系統調用:和fsync類似但是它只會影響文件的一部分,因為除了文件中的數據之外,fsync還會同步文件的屬性。
9、Nginx、LVS、HAProxy
在實際的APP應用程序中,我們知道Web服務群集前總是有負載平衡服務,典型的負載平衡軟件使用會根據網站規模的增加而使用不同的技術。 例如,中小型WEB APP應用程序Nginx就足夠了,但對于大型站點和關鍵服務可以使用LVS。Nginx、LVS、HAProxy是目前使用最廣泛的三種負載平衡軟件。
【Nginx】 是高性能的Web和反向代理服務器,Nginx是三種負載均衡軟件中最容易使用、適用性最廣的軟件,主要是七層網絡通信模型中的第七層APP應用。Nginx內存消耗少:3萬個連接,打開10個Nginx進程,只占用150M內存(15M*10=150M )。
【HAProxy】 是一款以c語言編寫的自由開放源代碼軟件,提供高可用性、負載平衡、基于TCP (第4層)和HTTP (第7層)的APP應用程序代理。 特別適用于負荷較高的網站。 這些站點通常需要保持會話或處理7個階段。不同于Nginx可以作為WEB服務器,HAProxy本身僅僅就只是一款負載均衡軟件,單純從效率上來講HAProxy更會比Nginx有更出色的負載均衡速度,在并發處理上也是優于Nginx的。






)













)