為什么80%的碼農都做不了架構師?>>> ??
本系列共6篇文章,會通過一些代碼示例,講解如何在Ignite中使用機器學習庫,本文是本系列的第一篇。
從Ignite的2.4版本開始,機器學習就可以用于生產環境了。在這個版本中,進行了大量的開發和改進,其中包括對分區化數據集和遺傳算法的支持,Ignite提供的很多機器學習示例也可以獨立運行,這樣就使入門變得很簡單。并且在本系列的后面,還會使用Ignite支持的一些算法,對一些免費的數據集進行分析,進一步方便開發者學習。
介紹
本文中,先大概看一下機器學習網格,如圖1所示: 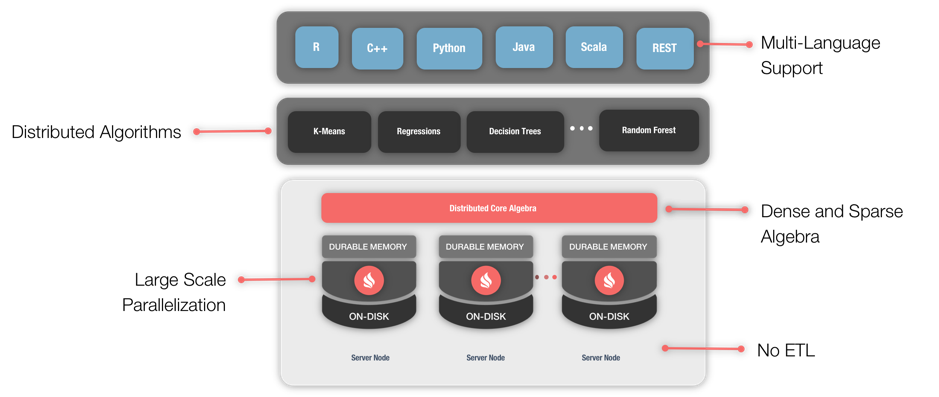 Ignite提供的機器學習能力,從設計上來說要求實用化,并且要求能夠直接在Ignite中建立預測模型,這就使得用戶在不需要進行昂貴的ETL或者數據轉換的前提下,獲得擴展性和性能的提升,下面稍微討論下細節。
Ignite提供的機器學習能力,從設計上來說要求實用化,并且要求能夠直接在Ignite中建立預測模型,這就使得用戶在不需要進行昂貴的ETL或者數據轉換的前提下,獲得擴展性和性能的提升,下面稍微討論下細節。
首先,在這之前,機器學習模型需要在不同的系統間進行訓練和部署,比如,數據需要移出Ignite,然后使用其他的工具進行訓練,最后再將模型重新部署進生產系統,這個方式有如下幾個缺點:
- 昂貴的ETL處理過程,尤其對于大規模數據集,數據集的大小,可能是GB級甚至是TB級;
- 如果要進行ETL,實際上使用的是數據的一個快照,在ETL之后,線上的生產系統數據,可能已經改變,從而使訓練系統使用的是過時的訓練數據;
其次,現在許多系統可能需要處理大量數據,這些數據通常超過單個服務器的容量。雖然分布式計算提供了一種解決方案,但是有些平臺不是為存儲和操作數據而設計的,可能只適合于訓練目的。因此,開發人員可能需要考慮在生產環境中部署更復雜的解決方案。
Ignite的機器學習能力有助于解決所有的這些問題,甚至更多:
- Ignite可以直接處理線上的生產數據,避免在不同系統間進行昂貴的ETL;
- 在數據的存儲和維護上,Ignite可以提供分布式的計算能力;
- Ignite實現的機器學習算法,針對分布式計算進行了優化,因此可以利用Ignite并置處理的優勢;
- Ignite可以作為流式數據的接收器,因此可以實時地進行機器學習;
- 機器學習通常是迭代式的處理,并且算法在執行過程中上下文可能發生變化,因此為了避免延遲以及丟失,Ignite支持容錯的分區化的數據集。
分區化的數據集
Ignite目前支持分區化的數據集,這是一個介于機器學習算法和底層的存儲和計算之間的抽象層,它為計算和緩存的備份使用了類似MapReduce的操作以支持容錯。
在Ignite中,一個哈希算法會被應用于鍵值對(K-V)中的鍵部分,來確定值部分在集群中的存儲位置。值部分實際是存儲于分區中的,分區是原子化的。在圖2中,可以看到兩個節點的集群,有兩個分區(P1和P2): 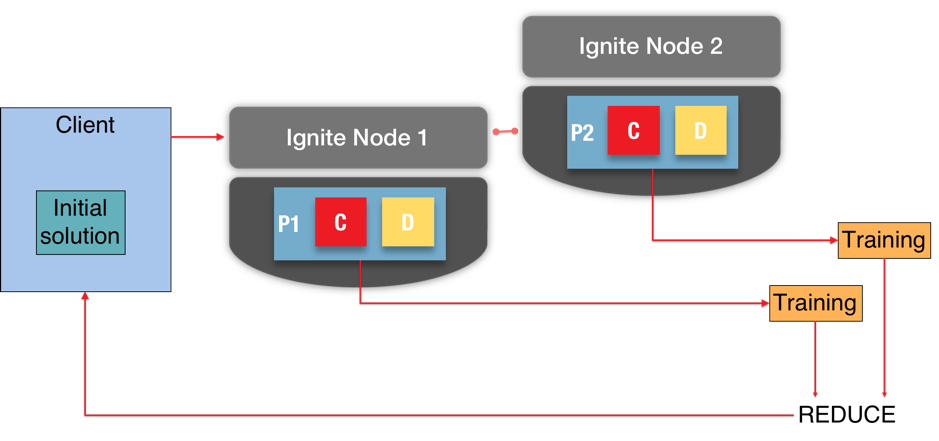 機器學習算法通常是迭代式的,并且需要上下文和數據,在圖2中,如每個分區中對應的C和D所示。
機器學習算法通常是迭代式的,并且需要上下文和數據,在圖2中,如每個分區中對應的C和D所示。
如果一個節點故障,Ignite會恢復分區和上下文,如圖3所示。比如,P1在節點2有一個備份(灰色所示),如果節點1故障,就可以從節點2恢復P1,數據可能從集群或者本地ETL(標記為D*)中恢復。 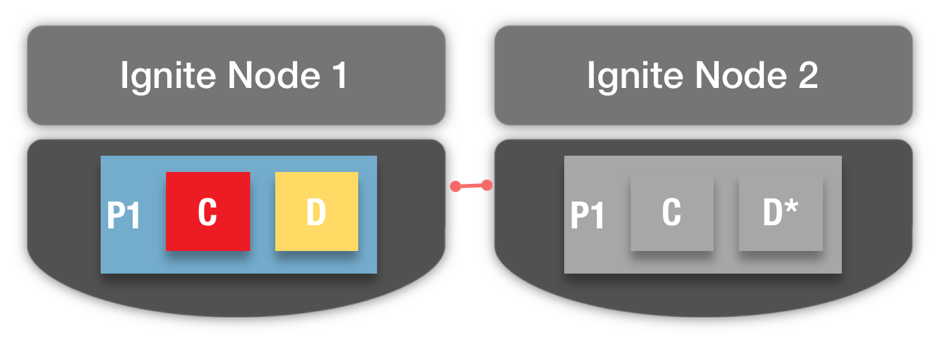
算法和適用領域
下面會看下Ignite支持的機器學習算法,下表會做個總結:
分類 | 回歸 | 聚類 | 預處理 | |
|---|---|---|---|---|
描述 | 根據一組訓練數據確定新的標的屬于哪一類 | 對因變量y和一個或多個自變量x之間的關系進行建模 | 對對象集進行分組,使得同一組內的對象和其他組中的每個對象相比具有更高的相似度 | 特征提取和規范化 |
適用領域 | 垃圾郵件檢測、圖像識別、信用評分、疾病識別 | 藥物反應,股票價格,超市收入 | 客戶細分、實驗結果分組、購物項目分組 | 對比如文本這樣的輸入數據進行轉換,以便用于機器學習算法,然后提取需要擬合的特征,對數據進行規范化 |
算法 | 支持向量機(SVM)、最近鄰、決策樹分類和神經網絡 | 線性回歸、決策樹回歸、最近鄰和神經網絡 | K均值 | 基于分區的數據集自定義預處理 |
機器學習庫還帶來了一組遺傳算法,其在這里有詳細描述。
總結
Ignite的最新版本提供了許多重要的特性和能力。分區化的數據集通過保存上下文,在節點故障時可以繼續處理機器學習算法。機器學習算法支持廣泛的使用案例,遺傳算法的加入也為復雜數據的處理提供了新的機會。



















