? ? 一、問題發現篇
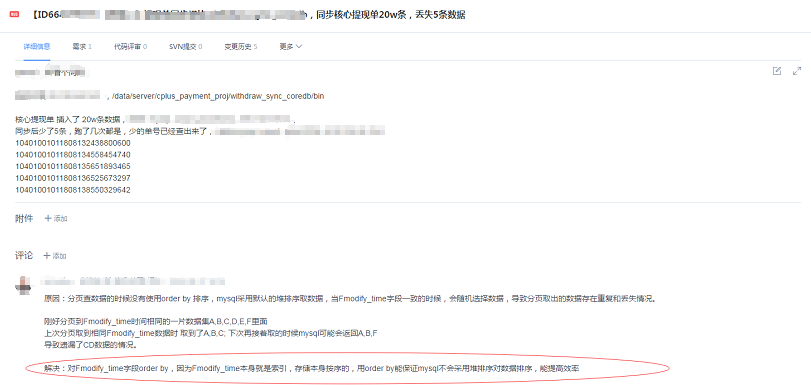
? ? ? ? 最近組內做了一次典型缺陷分享時,翻閱2018年的缺陷,找到了一個讓我覺得“有料”的bug(別的同事測試發現的),先大致簡單的描述下這個問題:
- ? 需要實現的功能:從一個DB庫同步某一段時間的數據到另一個DB庫(簡化后的需求)。
- ? 問題描述:一次同步20w條符合記錄的數據,程序同步完成后,丟數據5條。
- ? 問題定位:加載數據的sql,考慮到數據量大,使用了limit M,N的方法來分頁加載數據,大致如下:
? ? ? ? ? ? ? ? ? select ?* ?from test where Fmodify_time?>= '2018-12-12 05:00:00'and Fmodify_time <= '2018-12-12 05:01:00' limit 0,2; ? ? ??
? ? ? ? ? 開發哥哥定位問題產生的原因是因為20w的數據里,存在大量的Fmodify_time?值相同的記錄,由于未排序,導致這類數據服務器返回時會隨機選擇,從而導致分頁取出來的數據存在重復或者丟失的問題。然后解決的辦法就是,加上order by?Fmodify_time 就能滿足,因為Fmodify_time 是一個索引,索引排序是有序的。后面測試小哥用相同的數據驗證不丟數據,事情就告一段落了。
? ? ?
? ? ?二、問題驗證和解決篇
? ? ? ? ? 巧著,18年下半年花了2個月時間在學習mysql,在學習limit 分頁查找的官方文檔里有看到這么一段話:https://dev.mysql.com/doc/refman/5.7/en/limit-optimization.html
(1)如果在使用order by列中的多個行具有相同的值,則服務器可以按任何順序自由返回這些行,并且可能根據整體執行計劃的不同而不同。換句話說,這些行的排序順序相對于無序列是不確定的。(2)影響執行計劃的一個因素是 LIMIT,因此ORDER BY 使用和不使用查詢LIMIT可能會返回不同順序的行。如果確保使用和不使用相同的行順序很重要,請LIMIT在ORDER BY子句中包含其他列以使記錄具有確定性,
比如使用主鍵。 ? ? ? ? ? 那這么說,之前開發說通過order by 索引能使得結果返回有序就是有問題的了,帶著這個疑問和官方文檔的demo,結合實際的這個缺陷,做了個小驗證。
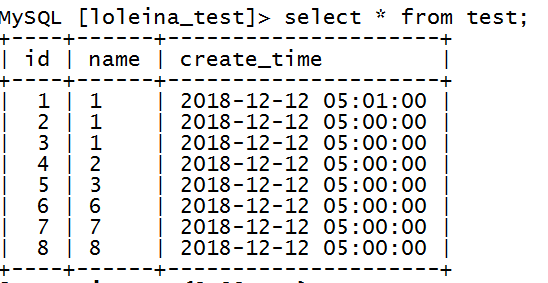
? ? ? ? ? (1)建表如下:? ? 主鍵:id,索引:create_time
CREATE TABLE `test` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(255) DEFAULT NULL,`create_time` timestamp NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`id`),KEY `index_time` (`create_time`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=latin1
? ? ? ? ? (2)插入數據如下:
?
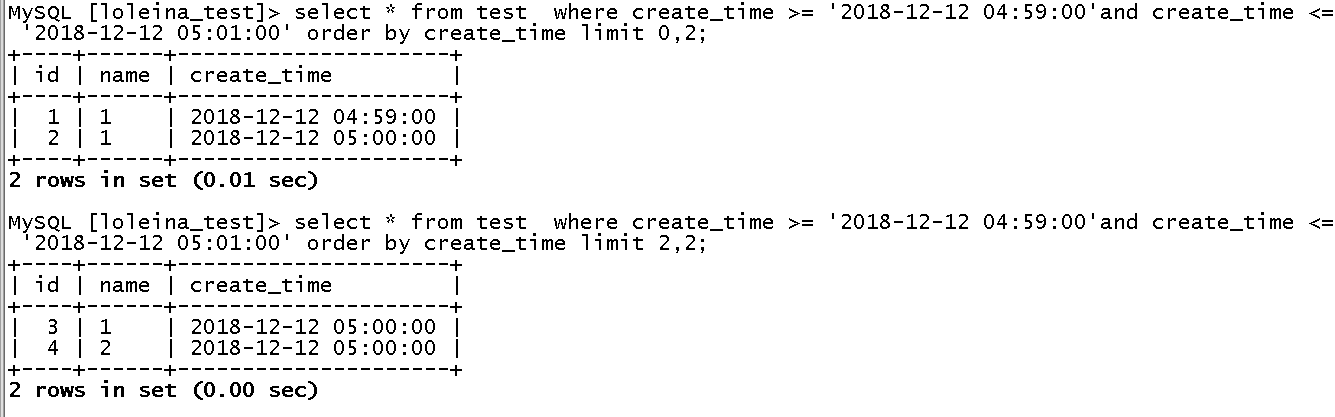
? ? ? ? (3)模擬分頁查找,不使用order by。結果如下:

? ? ? ? ?測試結果:丟數據id=1的記錄,id=7的數據重復導致。看來這個問題是真的存在的。那按照開發哥哥的解決方法加上order by?create_time就沒問題了?
? ? ? (4)模擬分頁查找,使用order by +?create_time(索引),如下:

? ? ? ? ? ? 測試結果:丟數據id=7的記錄,id=3的數據重復導致。看來加了索引排序,還是有問題的,開發哥哥的“解決方法”實際是不能解決問題的。
? ? ? ? ? (5)模擬分頁查找,使用order by +?create_time(索引)+ id(主鍵),如下:

? ? ? ? ?測試結果:未丟數據。
? ? ? ? 分頁查找limit M,N 的基本原理,就是服務器查找M+N條,然后返回從M條開始的后N條,導致上面問題出現的本質原因,還是mysql服務器查詢后的數據排序不穩定導致。同小節的官方文檔有說明當LIMIT row_count 和ORDER BY一起使用的時候,mysql不會對整個結果集排序,而是只對row_count 行的數據進行排序然后就返回。
If you combine LIMIT row_count with ORDER BY, MySQL stops sorting as soon as it has found the first row_count rows of the sorted result, rather than
sorting the entire result. If ordering is done by using an index, this is very fast. If a filesort must be done, all rows that match the query
without the LIMIT clause are selected, and most or all of them are sorted, before the firstrow_count are found. After the initial rows have been
found, MySQL does not sort any remainder of the result set.
? ? ? ? 三、未解之謎篇
? ? ? ? ?大致的原理已經理清了,但是還有幾個問題是沒想明白的:
? ? ? ? ?問題一: 如果構造測試數據的時,把id =1的記錄,時間2018-12-12 05:01:00?修改為2018-12-12 04:59:00,不加order by 都不會出現丟數據和重復數據的問題:

? ? ? ? ? ? ?這是為什么?數據的不同對結果是有影響的!!!那測試的時候數據要怎么構造呢?才能保證輸入的數據都是有代表的呢?這個現象背后的原理是什么呢?
??問題二:使用索引排序 order by+索引,是不穩定的?
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
?2019.01.28 問題跟進
問題二:使用索引排序 order by+索引,是不穩定的?
? ? ? ? ? ? ? 這個問題有“問題“,雖然order by 和 where 條件語句都是使用了index,但是并不確定所有的分頁查找的sql都是使用索引排序。比如:
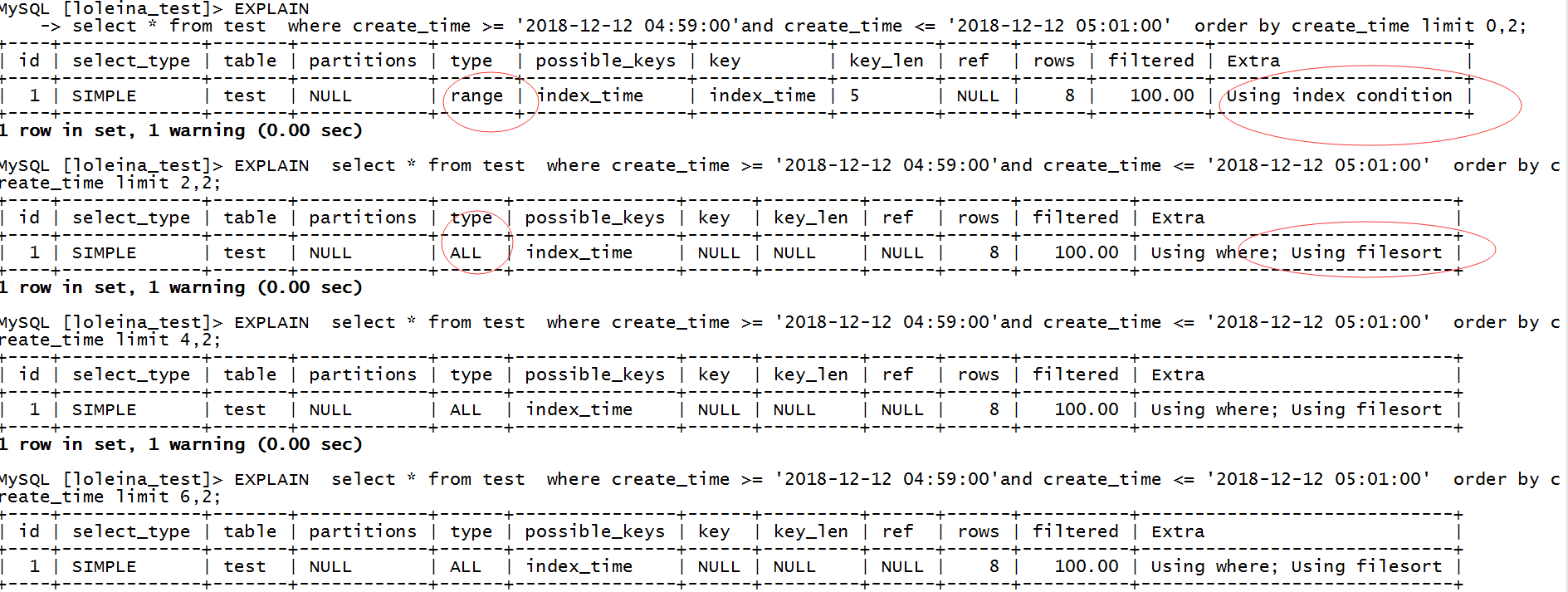
? ? ? ??從第二個sql開始,執行計劃就已經開始出現Using where; Using filesort ,跟之前第一條sql的執行計劃是完全不一樣的,?第二條sql之后就不能利用索引來避免排序,filesort并不意味著就是文件排序,其實也有可能是內存排序,這個主要由sort_buffer_size參數與結果集大小確定。MySQL內部實現排序主要有3種方式,常規排序,優化排序和優先隊列排序,主要涉及3種排序算法:快速排序、歸并排序和堆排序。
? ? ? ? 在學習其他文檔了解到,在5.5版本中沒有這個問題。產生這個現象的原因就是5.6針對limit M,N的語句采用了優先隊列,而優先隊列采用堆實現,使用的是堆排序算法,比如上述的例子order by create_time limit 4,2 limit 0,2 需要采用大小為2的大頂堆;limit 2,4需要采用大小為4的大頂堆。堆排序是非穩定的(對于相同的key值,無法保證排序后與排序前的位置一致),所以導致分頁重復的現象。而解決這個問題的有效方法就是可以在排序中加上唯一值,比如主鍵id。
? ? ? ?那為什么第一條執行sql的時候Extra =?Using index condition,不需要訪問表,直接拿數據呢? 后面sql執行全部都是Extra =?Using where; Using filesort ,估計就是跟sort_buffer_size參數有關
? ? ? ?學習參考文檔:《數據庫內核月報 - 2015 / 06》 鏈接:http://mysql.taobao.org/monthly/2015/06/04/
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?《MySQL排序原理》 https://blog.csdn.net/eagle89/article/details/81315981
?
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
?優化order by?方法:
?1 加大 max_length_for_sort_data 參數的設置
??在 MySQL 中,決定使用老式排序算法還是改進版排序算法是通過參數 max_length_for_ sort_data 來決定的。當所有返回字段的最大長度小于這個參數值時,MySQL 就會選擇改進后的排序算法,反之,則選擇老式的算法。所以,如果有充足的內存讓MySQL 存放須要返回的非排序字段,就可以加大這個參數的值來讓 MySQL 選擇使用改進版的排序算法。
2 去掉不必要的返回字段
??當內存不是很充裕時,不能簡單地通過強行加大上面的參數來強迫 MySQL 去使用改進版的排序算法,否則可能會造成 MySQL 不得不將數據分成很多段,然后進行排序,這樣可能會得不償失。此時就須要去掉不必要的返回字段,讓返回結果長度適應 max_length_for_sort_data 參數的限制。
3 增大 sort_buffer_size 參數設置
? 這個值如果過小的話,再加上你一次返回的條數過多,那么很可能就會分很多次進行排序,然后最后將每次的排序結果再串聯起來,這樣就會更慢,增大 sort_buffer_size 并不是為了讓 MySQL選擇改進版的排序算法,而是為了讓MySQL盡量減少在排序過程中對須要排序的數據進行分段,因為分段會造成 MySQL 不得不使用臨時表來進行交換排序。
但是這個值不是越大越好:
1 Sort_Buffer_Size 是一個connection級參數,在每個connection第一次需要使用這個buffer的時候,一次性分配設置的內存。
2 Sort_Buffer_Size 并不是越大越好,由于是connection級的參數,過大的設置+高并發可能會耗盡系統內存資源。
3 據說Sort_Buffer_Size 超過2M的時候,就會使用mmap() 而不是 malloc() 來進行內存分配,導致效率降低。
?
?
??

)
)





)



地址獲取文件流信息)






)