StateSynchronizer是開源分布式流存儲平臺Pravega的核心組件。StateSynchronizer組件以stream為基礎,對外提供一致性狀態共享服務。StateSynchronizer允許一組進程同時讀寫同一共享狀態而不必擔心一致性問題。本文將從共享狀態和一致性的角度出發,詳細描述StateSynchronizer的整體架構、工作機制和實現細節。利用stream的天然特性,StateSynchronizer可以高效地確定出更新操作的全局順序,并且從邏輯上實現了對共享狀態的一致性更新與存儲。由于stream訪問的高效與輕量,StateSynchronizer特別適用于高并發(\u0026gt;= 10000 clients) 的場景,并在此場景下可以作為替代ZooKeeper和etcd的解決方案。
StateSynchronizer設計者之一Flavio是著名開源組件ZooKeeper的最早作者,他同時也是《ZooKeeper:分布式過程協同技術詳解》這本書的作者。
StateSynchronizer不僅是Pravega公共API的一部分,許多Pravega內部組件也大量依賴StateSynchronizer共享狀態,如ReaderGroup的元信息管理。并且我們可以基于StateSynchronizer實現更高級的一致性原語,例如跨stream的事務。
開源項目地址:https://github.com/pravega/pravega/tree/v0.4.0
1 背景簡介
1.1 什么是StateSynchronizer(狀態同步器)
Pravega [1]既可以被想象成是一組流存儲相關的原語,因為它是實現數據持久化的一種方式,Pravega也可以被想象成是一個消息訂閱-發布系統,因為通過使用reader,writer和ReaderGroup它可以自適應地進行消息傳遞。本文假設讀者已經熟悉Pravega的有關概念,否則可以參考相應的官方文檔 [2]和已發布的4篇專欄文章(見文末鏈接)。
Pravega實現了各種不同的構建模塊用以實現stream相關原語,StateSynchronizer [2]就是其中之一,目的在于協調分布式的環境中的各個進程^2。從功能上看,StateSynchronizer為一組進程提供可靠的共享的狀態存儲服務:允許多個客戶端同時讀取和更新同一共享狀態并保證一致性語義,同時提供數據的冗余和容錯。從實現上看,StateSynchronizer使用一個stream為集群中運行的多個進程提供了共享狀態的同步機制,這使得構建分布式應用變得更加簡單。使用StateSynchronizer,多個進程可以同時對同一個共享狀態進行讀取和修改,而不必擔心一致性問題 [3]。
StateSynchronizer的最大貢獻在于它提供了一種stream原生的一致性存儲方案。由于stream具有只允許追加(Append-Only)的特性,這使得大部分現有的存儲服務都無法很好地應用于stream存儲的場景。相比于傳統的狀態存儲方案,stream原生的存儲使得StateSynchronizer具有以下優點:
與常見的鍵值存儲(Key/Value Store)不同,StateSynchronizer支持任意抽象的共享狀態,而不僅僅局限于維護鍵值集合。
與常見的數據存儲不同,StateSynchronizer以增量的方式維護了共享狀態的整個變更歷史,而不僅僅是維護共享狀態的最新快照。這一特性不僅大大減少了網絡傳輸開銷,還使得客戶端可以隨時將共享狀態回滾到任意歷史時刻。
與常見的狀態存儲不同,StateSynchronizer的服務端既不存儲共享狀態本身也不負責對共享狀態進行修改,所有共享狀態的存儲和計算都只發生在客戶端本地。這一特性不僅節約了服務端的計算資源,還增加了狀態計算的靈活性,例如:除了基本的CAS(Compare-And-Swap)語義,還支持高隔離級別的復雜事務^3。
與現有的基于樂觀并發控制(Optimistic Concurrent Control, OCC) [4] [5]的存儲系統不同,StateSynchronizer可以不依賴多版本控制機制(Multi Version Concurrent Control, MVCC) [6] [7]。這意味著即使在極端高并發的場景下,狀態更新的提交也永遠不會因版本沖突而需要反復重試。
StateSynchronizer無意于也不可能在所有場景中替代傳統的分布式鍵值存儲組件,因為它的運行機制大量依賴stream的特性。但是,在具有stream原生存儲和較強一致性需求的場景下,StateSynchronizer可能是一種比其它傳統鍵值存儲服務更為高效的選擇。
1.2 “一致性”的不同語義
在不同的上下文環境中,“一致性”一詞往往有著不同的語義 [8] [9]。在分布式存儲和數據高可用(High Availability)相關的語境下,一致性通常指數據副本(Replica)的一致性 [8]:如何保證分布在不同機器上的數據副本內容不存在沖突,以及如何讓客戶端看起來就像在以原子的方式操作唯一的數據副本,即線性化(Linearizability) [10]。常見的分布式存儲組件往往依賴單一的Leader(主節點)確定出特定操作的全局順序,例如:ZooKeeper [11]和etcd [12]都要求所有的寫操作必須由Leader轉發給其它數據副本。數據副本的一致性是分布式系統的難點,但卻并不是一致性問題的全部。
脫離數據副本,在應用層的語境下,一致性通常指數據滿足某種約束條件的不變性(Invariant)[13],即:指的是從應用程序特定的視角出發,保證多個進程無論以怎樣的順序對共享狀態進行修改,共享狀態始終處于一種“正確的狀態”,而這種正確性是由應用程序或業務自身定義的。例如,對于一個交易系統而言,無論同時有多少個交易在進行,所有賬戶的收入與支出總和始終都應該是平衡的;又如,多進程操作(讀/寫)一個共享的計數器時,無論各進程以怎樣的順序讀寫計數器,計數器的終值應該始終與所有進程順序依次讀寫計數器所得到的值相同。參考文獻 [8]將這種一致性歸類為“事務性的一致性(Transactional Consistency)”,而參考文獻 [9]則將此類一致性簡單稱為“涉及多對象和多操作的一致性”。應用層的數據一致性語義與數據副本的一致性語義完全不同,即使是一個滿足線性化的分布式系統,也需要考慮應用層的數據一致性問題^4。
1.3\tStateSynchronizer與現有的一致性存儲產品
目前常用的分布式鍵值存儲服務,例如ZooKeeper和etcd,都可以看作是一種對共享狀態進行存儲和維護的組件,即所有鍵值所組成的集合構成了當前的共享狀態。在數據副本層面,ZooKeeper和etcd都依賴共識(Consensus)算法提供一致性保證。ZooKeeper使用ZAB(ZooKeeper’s Atomic Broadcast)協議 [14]在各節點間對寫操作的提交順序達成共識。在廣播階段,ZAB協議的行為非常類似傳統的兩階段提交協議。etcd則使用Raft協議 [15]在所有節點上確定出唯一的寫操作序列。與ZAB協議不同,Raft協議每次可以確認出一段一致的提交序列,并且所有的提交動作都是隱式的。在應用層數據層面,ZooKeeper和etcd都使用基于多版本控制機制的樂觀并發控制提供最基礎的一致性保證。一方面,雖然多版本控制機制提供了基本的CAS語義,但是在極端的高并發場景下仍因競爭而存在性能問題。另一方面,僅僅依靠多版本控制機制無法提供更加復雜的一致性語義,例如事務。盡管在數據副本層面,ZooKeeper和etcd都提供很強的一致性語義,但對于應用層面的數據一致性卻還有很大的提升空間:ZooKeeper無法以原子的方式執行一組相關操作,而etcd的事務僅支持有限的簡單操作(簡單邏輯判斷,簡單狀態獲取,但不允許對同一個鍵進行多次寫操作)。
在應用層數據層面,ZooKeeper和etcd都使用多版本控制機制提供最基礎的一致性保證。例如,ZooKeeper的所有寫操作都支持樂觀并發控制:只有當目標節點的當前版本與期望版本相同時,寫操作才允許成功;而etcd則更進一步,還支持非常有限的簡單事務操作。一方面,雖然多版本控制機制提供了基本的CAS語義,但是在極端的高并發場景下仍因競爭而存在性能問題。另一方面,僅僅依靠多版本控制機制無法提供更加復雜的一致性語義,例如事務。盡管在數據副本層面,ZooKeeper和etcd都提供很強的一致性語義,但對于應用層面的數據一致性卻還有很大的提升空間:ZooKeeper無法以原子的方式執行一組相關操作,尤其是同時操縱多個鍵;而etcd的事務僅支持非常有限的簡單操作(簡單邏輯判斷,簡單狀態獲取,但不允許對同一個鍵進行多次寫操作)。為應用層數據提供比現有的分布式存儲組件更強的一致性語義(復雜事務)和更高的并發度是StateSynchronizer的主要目標,尤其是在stream原生場景下,因為傳統的以隨機訪問為主的存儲組件很難適配stream存儲的順序特性。得益于stream的自身特性,StateSynchronizer可以不依賴樂觀并發控制和CAS語義,這意味著不會出現版本沖突也無需重試,從而更加適用于高并發的場景(2.2.4小節)。在“無條件寫”模式下,StateSynchronizer的理論更新提交速度等價于stream的寫入速度。
與現有的絕大多數存儲服務不同,StateSynchronizer反轉了傳統的數據存儲模型(2.2.3小節):它并不存儲共享狀態本身,轉而存儲所有作用在共享狀態上的更新操作。一方面,這一反轉的數據模型直接抽象出了共享狀態,使得共享狀態不再局限于簡單的鍵值存儲,而可以推廣到任意需要一致性語義的狀態。另一方面,反轉數據存儲的同時還不可避免地反轉了數據相關的操作,使得原本大量的服務端狀態計算可以直接在客戶端本地完成(2.2.1小節)。這一特性不僅大大降低了服務端的資源消耗,同時也使得StateSynchronizer可以提供更靈活的更新操作和更強一致性語義:復雜事務。在StateSynchronizer的框架中,客戶端提交的所有更新操作都是以原子的方式順序執行的,并且所有更新操作的執行都發生在本地。從邏輯上看,每一個更新操作都等價于一個本地事務操作。這也意味著客戶端可以在更新操作中使用復雜的業務邏輯(幾乎是不受限的操作,只要操作本身的作用是確定性的)而無需擔心一致性問題。
2 實現細節
2.1\tStateSynchronizer的本質
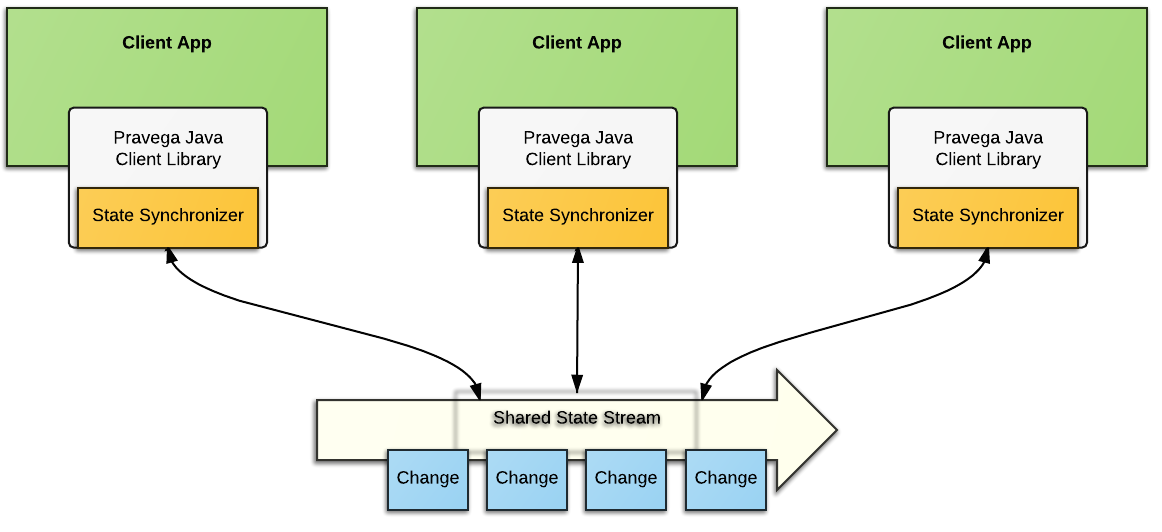
圖 1 StateSynchronizer的整體架構 [3] StateSynchronizer包括一個嵌入在應用里的客戶端和一個用于“存儲”共享狀態的stream。
從整體架構上看,StateSynchronizer是一個很典型的客戶端/服務器結構(如圖 1所示):它包括一個以庫的形式(當前版本僅支持Java)嵌入在應用中的客戶端,以及服務器端的一個對應stream。從概念上看,StateSynchronizer服務端負責以stream的形式“存儲”共享狀態。嚴格說來,stream存儲的是更新操作而不是共享狀態本身。2.2.3小節將對此進行更加深入的討論。
StateSynchronizer客戶端是一個輕量級的組件,它與所有其它的stream客戶端(例如reader和writer)并沒有本質上的不同:StateSynchronizer客戶端使用標準的stream API與服務器端的stream交互,并且服務器端也并不存在任何特定于StateSynchronizer的特性或實現。也就是說,StateSynchronizer客戶端具有其它stream客戶端共同的優點,高效。所有StateSynchronizer特定的行為都是在客戶端實現的,服務器端僅僅用于提供stream形式的存儲媒介。StateSynchronizer的客戶端還非常精巧,核心部分的實現不過數百行代碼 [16]。
2.2\tStateSynchronizer的工作機制
2.2.1\t維護本地共享狀態
從概念上說,每一個StateSynchronizer都對應一個共享狀態:所有的客戶端都可以并發地對這個共享狀態進行讀寫操作,并且保持一致性。這個共享狀態既可以很簡單(例如,它可以是一個基本的數值變量),也可以很復雜(例如,它也可以是一個任意復雜的數據結構)。但是,如果從物理實現角度上看,根本不存在這樣一個可以被共享訪問的狀態:每一個StateSynchronizer的客戶端都只在各自的本地維護著一個“共享”狀態的副本(Copy),除此以外沒有任何地方存儲這個狀態。所有的讀和寫(更新)操作都是直接作用在這個本地共享狀態副本上:讀操作直接返回本地共享狀態副本,而更新操作作用于本地共享狀態并生成新的共享狀態。
為了達到順序一致性 [8],所有共享狀態必須滿足全序(Total Order)關系 [17]。如果用符號“?”表示二元happens-before語義 [18],則任意N個狀態必須能夠確定出唯一全局順序,如下:
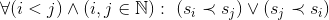 (1)
(1)
注意,happens-before關系必須滿足傳遞性,反自反性和反對稱性 [19]。
如果讀者閱讀過StateSynchronizer接口 [20]的實現類StateSynchronizerImpl,就會發現它有一個名為currentState的StateT類型的成員,并且StateT類型實現了Revisioned接口。這就是StateSynchronizer所維護的本地共享狀態副本。Revisioned接口僅有兩個成員方法:getScopedStreamName()用于獲取該狀態對應的stream的名字,getRevison()方法用于獲取該狀態對應的Revision(一個抽象的版本概念,也可以近似等價為Kafka的offset)。而Revision接口最終繼承了Comparable接口,允許任意兩個Revision進行比較,用于保證共享狀態的全序關系。感興趣的讀者可以繼續閱讀Revision接口的標準實現類RevisionImpl的compareTo()方法,就會發現Revision的比較實際上是基于Segment偏移量進行的。由于StateSynchronizer的底層stream僅包含一個segment,基于該segment的偏移量天然就是一個全序關系的良定義(well-defined)。
2.2.2\t更新操作的抽象模型
StateSynchronizer上的更新操作的實現是遞歸式的,也可以說是生成式的。StateSynchronizer的客戶端接受一個更新操作un ,將其成功持久化后(細節將在下文討論)應用于當前的本地共享狀態副本sn,從而生成新狀態sn+1 ,如下:
sn+1 = un(sn) (2)
從純數學的角度看,這是一個很典型的一階馬爾科夫模型/鏈(Markov Model) [21]:如果把n看作是離散的時間,那么sn就構成了系統狀態隨時間遷移(Transition)的一個有序序列,并且該系統在任意時間點的狀態sn+1只依賴前一時刻的狀態 sn ,并由當前更新un 確定,而與任何其它狀態無關。也可以這么理解,我們假設了狀態sn 已經包含了所有之前時刻的狀態信息。這就是所謂的馬爾科夫假設。為了啟動狀態遷移,我們規定系統必須具有一個起始狀態s0 ,而更新操作引起了隨后的狀態遷移。
如果從集群的視角看,有多個StateSynchronizer客戶端獨立同時運行并接受更新操作,而每個客戶端本地的共享狀態則分別經歷著基于馬爾科夫模型的狀態遷移。為保證每個StateSynchronizer客戶端的本地共享狀態都能夠收斂于相同的最終狀態,首先要求狀態遷移是確定性的(deterministic),也就是說,更新操作un 本身必須是確定性的(我們將在2.3.1小節深入討論更新操作與確定性問題)。從這個角度看,上述馬爾可夫鏈其實已經退化成一個普通狀態機。其次,所有的StateSynchronizer客戶端必須具有相同的起始狀態s0,并且以相同的順序應用更新un。整個集群的這種行為模式非常類似經典的復制狀態機(Replicated State Machine)模型 [22]。復制狀態機模型是一個應用廣泛的分布式模型,許多常見的全序廣播/原子廣播協議都是基于該模型進行的,如ZAB協議和Raft協議等。我們有意忽略了著名的Paxos協議 [23] [24],因為原生的Paxos協議并非用于解決全序廣播問題,盡管共識算法與全序廣播之間確實被證明存在等價關系 [25]。復制狀態機模型可以簡單描述如下:
在各自獨立的服務器節點上放置同一狀態機的實例;
接受客戶端請求,并轉譯成狀態機的輸入;
確定輸入的順序;
按已確定的順序在各個狀態機實例上執行輸入;
用狀態機的輸出回復客戶端;
監測各個狀態副本或者狀態機輸出可能出現的差異。
復制狀態機最核心也是最困難的部分是如何確定出一個輸入順序,以便讓每個狀態機實例都嚴格按照該順序執行狀態遷移,從而保證一致性。從整體架構上來說,ZAB協議和Raft協議都依賴單一的主節點確定輸入順序:所有的更新操作只能通過主節點進行,因此順序由主節點唯一確定。所不同的是,ZAB協議通過顯式的類兩階段提交方法保持廣播更新操作的原子性,而Raft協議甚至沒有顯式的提交過程,直接依賴計數的方法實現隱式提交。
在StateSynchronizer的場景下,狀態機實例即StateSynchronizer客戶端,輸入順序即更新操作的應用順序,執行狀態遷移即應用更新操作至本地共享狀態。StateSynchronizer使用完全不同的方式解決輸入順序的確定問題,使得StateSynchronizer不需要依賴任何主節點。從嚴格意義上說,StateSynchronizer并不負責維護數據副本,但是其本地共享狀態的維護和更新模型都與數據副本有著相似之處。我們將在下文詳細討論StateSynchronizer如何確定輸入順序以及和傳統模型的差別。
如果讀者仔細閱讀過StateSynchronizer的源代碼,就會發現StateSynchronizer接口內定義有一個名為UpdateGenerator的函數式接口。UpdateGenerator接口本質上是一個二元消費者:它接受兩個參數,其中一個是StateT類型的當前共享狀態,另一個是以List形式存在在更新操作(Update類型)列表,而列表內 的更新操作最終都將被持久化到相應的stream上。從概念上看,UpdateGenerator接口其實就是公式 2的等價實現。
2.2.3\t只存儲更新操作
在傳統的數據庫模型中,數據庫的服務器端負責維護一個全局的持久化的共享狀態,即數據庫中所有數據所組成的一個集合。多個獨立的客戶端同時向服務器端提交更新操作(事務),更新操作作用于共享狀態上引起狀態改變,而客戶端本地不存儲任何狀態。在這個模型中,服務器端的共享狀態無論從邏輯上看還是從物理上看,它都是共享的(這與StateSynchronizer的共享狀態有很大的不同):因為幾乎所有的數據庫系統都允許多個事務并發執行。從形式化的角度看,所謂“事務ui和uj是并發的”指的是它們既不滿足 ui ? uj 關系,也不滿足uj ? ui 關系,即ui 的作用對uj不完全可見,并且uj的作用對ui也不完全可見 [13]。可以不是很精確地將并發理解為:ui和uj之間無法確定順序。也可以從直覺上這樣理解:ui和uj的執行,在時間上存在重疊部分。并發直接導致了數據一致性問題。傳統數據庫模型解決并發問題的手段是設置事務的隔離級別 [26]:并發事務在不同的隔離級別下有著不同的可見性。
StateSynchronizer擯棄了傳統的數據庫模型,從一個完全不同的角度解決并發問題和狀態機輸入順序問題。其核心思想是,StateSynchronizer的服務器端只存儲(持久化)了更新操作本身而不是共享狀態,共享狀態由每個客戶端獨立維護,如2.2.1小節所述。由于StateSynchronizer架構中并不存在物理上的共享狀態,因此不會因為狀態共享而導致競爭,也不會因此產生并發問題。對于每一個StateSynchronizer的客戶端而言,所有的更新操作都是順序地作用于本地的共享狀態副本(物理上順序執行),這也不存在并發問題。但是,單憑這一點還不足以保證共享狀態的一致性,除非能夠保證唯一的更新操作應用順序。StateSynchronizer的服務器端用單segment的stream存儲了所有的更新操作:每一個更新操作作為一個event被持久化 ^5。Stream的最大特性就是只允許追加:所有的event寫入操作只允許在尾部進行(原子操作),并且一個event一旦寫入就不允許修改。這一特性不僅使得多個writer可以同時進行寫入并且保持一致性,還使得所有event的順序得以唯一確定,即每個event最終在Segment內的相對順序。所以,對于每一個StateSynchronizer客戶端來說,都能夠看見一個一致的有序的更新操作視圖。
細心的讀者可能還希望進一步了解服務器端的stream是如保持只允許追加的特性和一致性的。與Kafka的消息代理節點(Broker)直接用本地文件系統存儲stream數據的方法不同,Pravega的消息代理節點將數據的存儲完全交由一個抽象的存儲層代理,包括數據副本的維護。目前已經支持的具體存儲層實現包括:BookKeeper [27],HDFS [28],Extended S3 [29],NFS [30]等等。也就是說,數據副本的實現對消息代理節點來說是完全透明的。具體的segment分層存儲設計細節已經超出本文的討論范圍,感興趣的讀者可以自行閱讀Pravega的相關文檔 [31]。
StateSynchronizer的這種數據模型其實非常類似Change Data Capture(CDC) [32]和Event Sourcing [33]的設計模式:不存儲系統狀態,而是通過推導計算得出 [13]。以stream形式存在的更新操作其實可以看作是系統狀態的另一種視圖。從這一視圖出發,不僅能夠推導出系統的最終狀態,還可以得出系統在歷史任意時刻的狀態。
為了讓所有的更新操作本身都能被持久化到stream中,StateSynchronizer要求所有的更新操作都以類的形式實現,封裝好所有所需的狀態并且支持序列化/反序列化。這一點從StateSynchronizer的接口定義上也可以反映出來:創建一個StateSynchronizer實例必須提供兩個Serializer接口實例,分別用于對更新操作和起始狀態作序列化/反序列化,并且UpdateGenerator接口的定義要求所有更新操作必須實現Update接口。
2.2.4\t更新操作的寫入模式:條件寫與無條件寫
將更新操作本身持久化到相應的stream中是StateSynchronizer實現更新操作接口的重要步驟之一,因為只有這樣才能使所有的StateSynchronizer客戶端都看見一個全局唯一的更新操作序列。目前,StateSynchronizer支持以兩種不同的模式將更新操作持久化到stream端:條件寫模式(Conditionally Write)與無條件寫模式(Unconditionally Write)。這兩種更新模式分別有各自的適用場景。
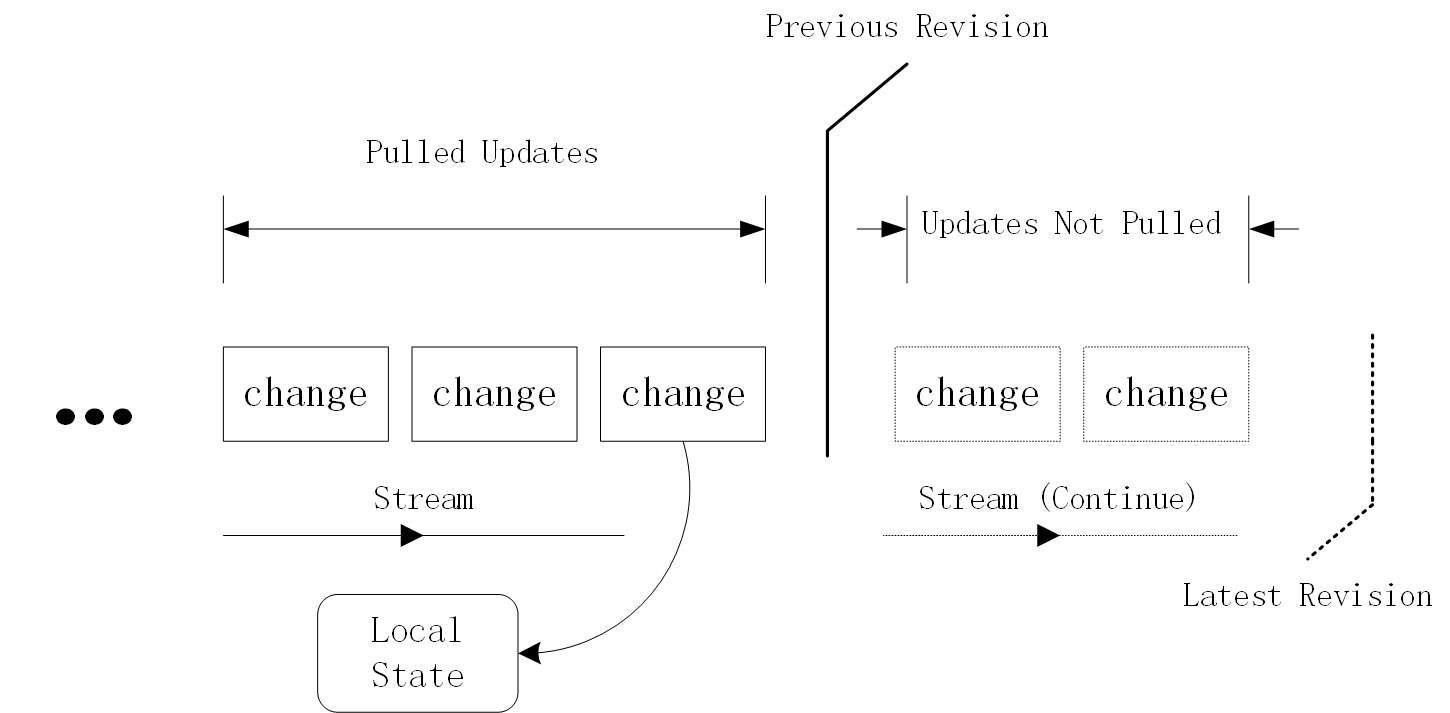
圖 2 條件寫示意圖 每個矩形框代表已經持久化到stream(右側為尾端)中的一個更新操作。實線框為已經累積到當前某個StateSynchronizer客戶端本地狀態的更新操作,而虛線框為尚未作用到本地狀態的更新操作,即:其它StateSynchronizer客戶端提交但尚未被當前StateSynchronizer客戶端拉取的更新操作。兩條豎線分隔符分別對應當前StateSynchronizer客戶端所見的Revision以及此時真正的最新Revision。只要存在虛線框所示的更新操作,或者說只要當前StateSynchronizer客戶端所見的Revision不是最新,那么條件寫操作就無法成功完成。
在條件寫模式下(參考StateSynchronizer接口上updateState()方法的實現),當StateSynchronizer客戶端嘗試把一個更新操作寫入stream內時需要首先檢查當前本地的共享狀態是否是對應stream上的最新狀態。如果是,則寫入成功,可以繼續將該更新操作作用于本地的共享狀態并更新為新狀態;如果不是,說明已經有其它的客戶端搶先往stream中寫入了其它更新操作,此時本地的共享狀態已經“過期”,本次寫入失敗,如圖 2所示。對于寫入失敗的情況,StateSynchronizer會自動嘗試從stream拉取所有缺失的更新,并將所有拉取到的更新順序作用于當前本地共享狀態以便將其更新到最新狀態,然后重試條件寫。這一“失敗-重試”的過程可能重復多次,直至寫入成功。從概念上看,條件寫表現出的行為與多線程編程中的CAS操作有著諸多相似之處。
如果讀者仔細思考條件寫的實現細節,不難得出如下的結論:檢查狀態是否過期與實際的stream寫入動作必須是一個整體的原子操作,否則將出現競爭條件。事實上,檢查狀態是否過期這一動作并不是在客戶端進行的,而是由stream的相關接口直接代理的,否則很難與發生在服務器端的寫入動作合并為一個原子操作。在閱讀過StateSynchronizer實現類StateSynchronizerImpl的源代碼之后,讀者會發現一個名為client的RevisionedStreamClient類型成員。RevisionedStreamClient是StateSynchronizer客戶端用來與后端stream交互的唯一入口,所有stream的讀寫操作都通過該接口進行,包括條件寫。RevisionedStreamClient接口上有一個名為writeConditionally()的方法(即條件寫的真正實現),允許在寫入一個event的同時指定一個Revision。正如其名字所暗示的那樣,Revision接口可以近似理解為stream的“版本”:每次成功的寫入操作都會導致對應stream的Revision發生變化,writeConditionally()方法甚至還直接返回該Revision以方便客戶端用作多版本并發控制。現在繼續討論writeConditionally()方法的行為,只有當stream的當前的實際Revision與指定的Revision相同時(即:從上次成功條件寫入到目前為止都沒有其它的成功寫入發生),真正的寫入動作才發生,否則寫入失敗。很明顯,這是一個典型的樂觀并發控制模式。
聰明的讀者甚至還可以從物理實現角度理解Revision。從2.2.1小節的討論中我們知道,Revision是基于segment內的偏移量實現的,而segment本質上就是一個無邊界的字節流。所謂stream的“版本”其實就是stream當前尾端的偏移量。由于stream只允許追加的特性,往指定偏移位置執行寫入操作時,只有當該偏移確實處于尾端時才能成功。圖 2中所標記的Revision既可以看作是當前本地共享狀態所對應的stream版本,也可以看作是當前StateSynchronizer客戶端所看見的stream尾部位置。從這個角度看,stream的特性和操作得到了統一。
由于條件寫的失敗-重試機制,在某些極端場景下(例如更新操作極度頻繁引起的激烈競爭),可能導致較多次數的重試。并且由于條件寫操作目前并未實現公平機制,理論上可能出現某個客戶端“饑餓”的情況。為應對這種場景,StateSynchronizer還提供了另一種持久化模式:無條件寫模式。在無條件寫模式下(參考StateSynchronizer接口上updateStateUnconditionally()方法的實現),StateSynchronizer客戶端往stream寫入更新操作時并不會要求比較Revision,而是無條件地將該更新操作寫入當前stream的實際尾端,并且在寫入成功后也不會更新本地的共享狀態。從實現上看,無條件寫模式下的更新動作其實就是一個簡單的stream追加動作。在服務和資源正常的情況下,stream的追加寫入總是能夠成功的。如果調用者希望得到更新操作作用后的共享狀態,則還需要手動拉取一次更新(參考StateSynchronizer接口上的fetchUpdates()方法)。由于更新操作的件寫入動作與拉取動作之間存在時間窗口,在這段時間內可能已經有其它的客戶端繼續寫入新的更新操作。因此,在拉取得到的更新操作序列上,并不能保證之前提交的更新操作是該序列上的最后一個元素。也就是說,在應用該更新操作之前和之后,可能有其它的更新操作已經作用或繼續作用在當前本地共享狀態上。相反,條件寫模式卻總是能保證所提交的更新一定是最后一個作用在當前本地共享狀態上的操作。根據具體應用場景的不同,這可能是個問題,也可能不是。例如,在無條件寫模式下,所有的更新操作現在都變得不可觀測了:假設你執行了一個無條件的更新操作,往一個共享的集合里面添加了一個元素。現在,哪怕你立刻進行集合遍歷,也不能保證你一定能夠找到剛剛添加的元素,因為可能存在其它客戶端提交的后續更新操作已經將剛剛添加的元素刪除了。這恐怕是一種與直覺相違背的行為表現。總之,與條件寫相比,無條件寫有著優異的并發性能,但是這一切都是有代價的,例如:犧牲了開發者的可理解性。
2.3\t其它問題
2.3.1\t更新操作與確定性
StateSynchronizer的更新操作模型(2.2.2小節)要求所有更新操作的實現必需是確定性的,因為所有的更新操作都會在每一個StateSynchronizer客戶端被重放。對于相同的輸入,如果更新操作本身不能夠產生確定性的結果,即使以完全相同的順序在每一個客戶端被執行,也會破壞共享狀態的最終一致性。根據實際業務場景的不同,這一要求可能是一個問題,也可能不是,例如:
不可以使用隨機函數。這一看似簡單的要求實際上限制了不少可能性,很多科學計算依賴隨機函數。
不可以使用絕大多數的本地狀態,例如:本地時間,本機硬件信息等。
引用任何外部系統的狀態都需要格外小心可能引入的不一致。例如,如果一個外部系統的狀態會隨時間變化,各個客戶端可能看到各不相同的外部狀態,因為同一個更新操作在每個客戶端被執行的時間點是不確定的。
除了保證更新操作的確定性之外,還需要特別注意更新操作的執行是否具有“副作用”,例如:引發全局狀態或外部系統狀態的改變。如果回答是肯定的,那么還需要特別注意這些引發狀態改變的動作接口是否具有冪等性 [34],因為同一個更新操作不僅會在每個客戶端被執行,即使在同一客戶端也可能被執行多次(2.2.4小節)。
2.3.2\t更新操作與更新丟失問題
有人擔心StateSynchronizer是否存在丟失更新問題 [6]。丟失更新問題一般在如下場景發生:兩個進程并發地對同一共享變量進行“讀取-修改-寫入”組合操作。如果這一組合操作不能夠被作為一個原子操作完成,那么后寫入的狀態有可能覆蓋另一個寫入操作的結果,導致其中一個修改結果(更新)“丟失”。如2.2.3小節所述,所有的更新操作都是在StateSynchronizer的客戶端本地順序執行的,因此不存在并發修改共享狀態的場景,也不會產生更新丟失問題。
雖然StateSynchronizer客戶端保證了以并發安全的方式執行所有更新操作,但是,一個不正確實現的更新操作仍有可能導致更新丟失問題。如果一個應用需要實現“讀取-修改-寫入”組合操作,唯一正確的做法是將所有的讀取,修改和寫入動作都封裝在同一個更新操作中,即按如下偽代碼所示實現更新操作un :
un:
\u0026gt; 讀取狀態sn;
\u0026gt; 執行修改;
\u0026gt; 生成并返回新狀態sn+1;
源代碼 1 用偽代碼表示的更新操作一般實現
一種常見的錯誤是在更新操作un外部進行“讀取狀態sn”和“執行修改”動作,并將新狀態sn+1直接封裝進更新操作un。另一種不那么直觀的錯誤是,盡管將“讀取”,“修改”和“寫入”動作都封裝進了同一個更新操作,但是在進行“讀取狀態sn”動作時有意或無意地使用了某種緩存機制,即并非每次都從StateSynchronizer獲取當前共享狀態sn。這兩種錯誤的實現都將導致很嚴重的丟失更新問題。2.2.4小節的相關討論解釋了其中的原因:由于條件寫操作可能失敗并重試多次,并且每次重試都意味著StateSynchronizer客戶端本地的共享狀態已經改變,任何緩存或者等價的行為都將導致實際的“執行修改”動作作用在一個已經過期的舊狀態上,從而導致丟失更新問題。
2.3.3\t更新操作的順序執行與性能
在每一個StateSynchronizer客戶端上,所有的更新操作都是順序執行并作用在本地共享狀態上的,正所謂“解決并發問題最簡單的辦法就是完全消除并發” [13]。有人擔心更新操作的順序執行是否會顯著降低系統性能。從目前已有的研究看,用單線程的方式執行所有事務是完全可行的 [35],并且在很多現有的數據庫實現中已經被采用,例如:VoltDB/H-Store [36],Redis [37],Datomic [38] [39]等。當然,這對事務本身以及數據集都有所要求 [13],例如:
每個事務必須足夠小,并且足夠快。
數據集的活躍部分必須足夠小,以便能夠全部載入物理內存。否則,頁面的頻繁換入和換出會引起大量的磁盤IO操作,導致事務頻繁阻塞。
寫操作的吞吐量必須足夠小,以便單CPU核心可以有足夠的能力處理。否則,CPU運算能力將成為瓶頸。
對于一個StateSynchronizer應用來說,無論是共享狀態還是更新操作的設計實現,都必須遵循上述要求。
2.3.4\t歷史重放與狀態壓縮
每一個StateSynchronizer客戶端在進行啟動后的首次更新操作時,都需要從對應的stream拉取所有的歷史更新操作,并重放這些操作以便得到當前最新的共享狀態。如果這是一個長時運行的共享狀態,那么stream內此時可能已經累積了相當數量的更新操作。拉取并重放所有這些更新操作可能需要消耗大量的時間與資源,造成首次更新性能低下。為了應對這種場景,StateSynchronizer還提供了所謂的狀態壓縮機制。狀態壓縮(compact)是一個特殊的StateSynchronizer接口方法,它允許將StateSynchronizer客戶端的本地共享狀作為一個新的起始狀態,用條件寫模式重新寫入stream^6,并且使用stream的mark機制標記該起始狀態的最新位置^7。StateSynchronizer客戶端每次拉取更新操作時,都會首先嘗試使用mark機制定位到最新的起始狀態并忽略所有之前的更新操作,從而避免了長時間的歷史重放。
如果首次更新操作的性能對于應用程序來說非常重要,那么開發者可以選擇周期性地進行狀態壓縮。那么首次更新操作所要拉取和應用的更新操作數量則不會多于一個周期內所累積的更新操作數量,這將大大提升首次更新操作的性能。
3\t總結
本文主要從狀態共享和一致性的角度出發,詳細描述了Pravega的狀態同步組件StateSynchronizer的工作機制和實現細節。StateSynchronizer支持分布式環境下的多進程同時讀寫共享狀態,并提供一致性保證。StateSynchronizer具有典型的客戶端/服務器架構,但是卻非常輕量和高效,因為服務器端僅僅用于提供存儲媒介。StateSynchronizer的核心工作機制可以歸納為兩個關鍵點:維護本地共享狀態和只存儲更新操作本身。StateSynchronizer利用stream的天然特性實現了更新操作的全局有序。StateSynchronizer還提供了條件寫和無條件寫兩種更新寫入模式,可以適用于并發度極高的場景。StateSynchronizer未來的工作可能集中在如何向開發者提供更加便捷易用的編程接口,以減輕開發者的負擔。
Pravega系列文章計劃
Pravega根據Apache 2.0許可證開源,0.4版本已于近日發布。我們歡迎對流式存儲感興趣的大咖們加入Pravega社區,與Pravega共同成長。本篇文章為Pravega系列第五篇,系列文章如下:
實時流處理(Streaming)統一批處理(Batch)的最后一塊拼圖:Pravega
開源Pravega架構解析:如何通過分層解決流存儲的三大挑戰?
Pravega應用實戰:為什么云原生特性對流存儲至關重要
“ToB” 產品必備特性: Pravega的動態彈性伸縮
高并發下新的分布式一致性解決方案(StateSynchronizer)
Pravega的僅一次語義及事務支持
與Apache Flink集成使用
作者簡介
蔡超前:華東理工大學計算機應用專業博士研究生,現就職于Dell EMC,6年搜索和分布式系統開發以及架構設計經驗,現從事流相關的設計與研發工作。
滕昱:現就職于Dell EMC非結構化數據存儲部門 (Unstructured Data Storage)團隊并擔任軟件開發總監。2007年加入Dell EMC以后一直專注于分布式存儲領域。參加并領導了中國研發團隊參與兩代Dell EMC對象存儲產品的研發工作并取得商業上成功。從 2017年開始,兼任Streaming存儲和實時計算系統的設計開發與領導工作。
參考文獻
[1] \t“Pravega,” Dell EMC, [Online]. Available: https://github.com/pravega/pravega.
[2] \t“Working with Pravega: State Synchronizer,” Dell EMC, [Online]. Available: https://github.com/pravega/pravega/blob/master/documentation/src/docs/state-synchronizer.md.
[3] \t“Pravega Concepts,” Dell EMC, [Online]. Available: https://github.com/pravega/pravega/blob/master/documentation/src/docs/pravega-concepts.md.
[4] \tH. T. Kung and J. T. Robinson, “On optimistic methods for concurrency control,” ACM Transactions on Database Systems, vol. 6, no. 2, pp. 213-226, 1981.
[5] \tP. A. Bernstein and N. Goodman, “Concurrency Control in Distributed Database Systems,” ACM Computing Surveys, vol. 13, no. 2, pp. 185-221, 1981.
[6] \t“Concurrency Control,” Wikipedia, [Online]. Available: https://en.wikipedia.org/wiki/Concurrency_control.
[7] \t“Multiversion Concurrency Control,” Wikipedia, [Online]. Available: https://en.wikipedia.org/wiki/Multiversion_concurrency_control.
[8] \tP. Viotti and M. Vukoli?, “Consistency in Non-Transactional Distributed Storage Systems,” ACM Computing Surveys (CSUR), vol. 49, no. 1, 2016.
[9] \tP. Bailis, A. Davidson, A. Fekete, A. Ghodsi, J. M. Hellerstein and I. Stoica, “Highly available transactions: virtues and limitations,” in Proceedings of the VLDB Endowment, 2013.
[10] \tM. P. Herlihy and J. M. Wing, “Linearizability: a correctness condition for concurrent objects,” ACM Transactions on Programming Languages and Systems (TOPLAS) , vol. 12, no. 3, pp. 463-492, 1990 .
[11] \t“Apache ZooKeeper,” [Online]. Available: https://zookeeper.apache.org/.
[12] \t“etcd (GitHub Repository),” [Online]. Available: https://github.com/etcd-io/etcd.
[13] \tM. Kleppmann, Designing Data-Intensive Applications, O’Reilly Media, 2017.
[14] \tF. P. Junqueira, B. C. Reed and M. Sera?ni, “Zab: High-performance broadcast for primary-backup systems,” In DSN, pp. 245-256, 2011.
[15] \tD. Ongaro and J. Ousterhout, “In search of an understandable consensus algorithm,” in Proceedings of the 2014 USENIX conference on USENIX Annual Technical Conference, Philadelphia, 2014.
[16] \t“StateSynchronizer Related Source Code in Pravega GitHub Repository,” Dell EMC, [Online]. Available: https://github.com/pravega/pravega/tree/master/client/src/main/java/io/pravega/client/state.
[17] \tM. Hazewinkel, Ed., Encyclopaedia of Mathematics (set), 1 ed., Springer Netherlands, 1994.
[18] \tL. Lamport, “Time, clocks, and the ordering of events in a distributed system,” Communications of the ACM, vol. 21, no. 7, pp. 558-565, 1978.
[19] \t“Happened-before,” Wikipedia, [Online]. Available: https://en.wikipedia.org/wiki/Happened-before.
[20] \t“StateSynchronizer Interface Definition (v0.4),” Dell EMC, [Online]. Available: https://github.com/pravega/pravega/blob/r0.4/client/src/main/java/io/pravega/client/state/StateSynchronizer.java.
[21] \tP. A. Gagniuc, Markov Chains: From Theory to Implementation and Experimentation, New Jersey: John Wiley \u0026amp; Sons, 2017.
[22] \tF. B. Schneider, “Implementing fault-tolerant services using the state machine approach: a tutorial,” ACM Computing Surveys, vol. 22, no. 4, pp. 299-319, 1990.
[23] \tL. Lamport, “The part-time parliament,” ACM Transactions on Computer Systems, vol. 16, no. 2, pp. 133-169, 1998.
[24] \tL. Lamport, “Paxos Made Simple,” SIGACT News, vol. 32, no. 4, pp. 51-58, 2001.
[25] \tX. Défago, A. Schiper and P. Urbán, “Total order broadcast and multicast algorithms: Taxonomy and survey,” ACM Computing Surveys, vol. 36, no. 4, pp. 372-421, 2004.
[26] \tH. Berenson, P. Bernstein, J. Gray, J. Melton, E. O’Neil and P. O’Neil, “A critique of ANSI SQL isolation levels,” in Proceedings of the 1995 ACM SIGMOD international conference on Management of data, San Jose, California, USA, 1995.
[27] \t“Apache BookKeeper,” [Online]. Available: https://bookkeeper.apache.org/.
[28] \t“Apache Hadoop,” [Online]. Available: https://hadoop.apache.org/.
[29] \t“Amazon S3,” Amazon, [Online]. Available: https://aws.amazon.com/s3/.
[30] \t“NFS version 4.2 (RFC 7862),” [Online]. Available: https://tools.ietf.org/html/rfc7862.
[31] \t“Pravega Segment Store Service (v0.4),” Dell EMC, [Online]. Available: https://github.com/pravega/pravega/blob/r0.4/documentation/src/docs/segment-store-service.md.
[32] \t“Change Data Capture,” Wikipedia, [Online]. Available: https://en.wikipedia.org/wiki/Change_data_capture.
[33] \tM. Fowler, “Event Sourcing,” 12 12 2005. [Online]. Available: https://martinfowler.com/eaaDev/EventSourcing.html.
[34] \t“Idempotence,” Wikipedia, [Online]. Available: https://en.wikipedia.org/wiki/Idempotence.
[35] \tM. Stonebraker, S. Madden and D. J. Abadi, “The End of an Architectural Era (It’s Time for a Complete Rewrite),” in Proceedings of the 33rd international conference on Very large data bases, Vienna, 2007.
[36] \tR. Kallman, H. Kimura and J. Natkins, “H-Store: A High-Performance, Distributed Main Memory Transaction Processing System,” Proceedings of the VLDB Endowment, vol. 1, no. 2, pp. 1496-1499, 2008.
[37] \t“Redis,” [Online]. Available: https://redis.io/.
[38] \tR. Hickey, “The Architecture of Datomic,” 2 11 2012. [Online]. Available: https://www.infoq.com/articles/Architecture-Datomic.
[39] \t“Datomic Cloud,” Cognitect, Inc., [Online]. Available: https://www.datomic.com/.
更多內容,請關注AI前線

![[51nod1773]A國的貿易](http://pic.xiahunao.cn/[51nod1773]A國的貿易)




)



)



)



)

